Enhanced Reinforcement Learning-based Process Synthesis via Quantum Computing
Pith reviewed 2026-05-21 04:30 UTC · model grok-4.3
The pith
Quantum reinforcement learning matches classical performance in finding optimal chemical flowsheets while using fewer parameters for moderate-scale problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For moderate-scale unit counts, quantum approaches demonstrate competitive performance on a per-episode basis and improved efficiency on a per-parameter basis versus the classical RL benchmark, after state encoding algorithms are used to reduce qubit scaling with problem complexity.
What carries the argument
State encoding algorithms that map flowsheet states into quantum representations while decoupling qubit count from the number of process units.
If this is right
- All tested algorithms, classical and quantum, locate the optimal flowsheet designs when the design space remains small.
- Quantum variants stay competitive with classical RL for the specific process synthesis problems examined.
- The work creates a controlled benchmark that can be reused to compare future classical and quantum algorithms on identical training conditions.
- This setup supplies a foundation for extending quantum methods to other process systems engineering tasks.
Where Pith is reading between the lines
- The same encoding technique might be tested on other combinatorial design problems outside chemical engineering, such as network layout or scheduling.
- Hybrid quantum-classical training loops could be explored to handle even larger unit counts where pure classical scaling becomes expensive.
- Performance metrics focused on parameter count rather than episode count may become a standard way to evaluate quantum advantage in optimization settings.
Load-bearing premise
The state encoding algorithms preserve enough information for the quantum agent to reach the same optimal flowsheet solutions as the classical agent.
What would settle it
Running both agents on the same moderate-unit-count flowsheet synthesis task and finding that the quantum version either misses the known optimal design or requires as many or more parameters to match classical success rates.
Figures
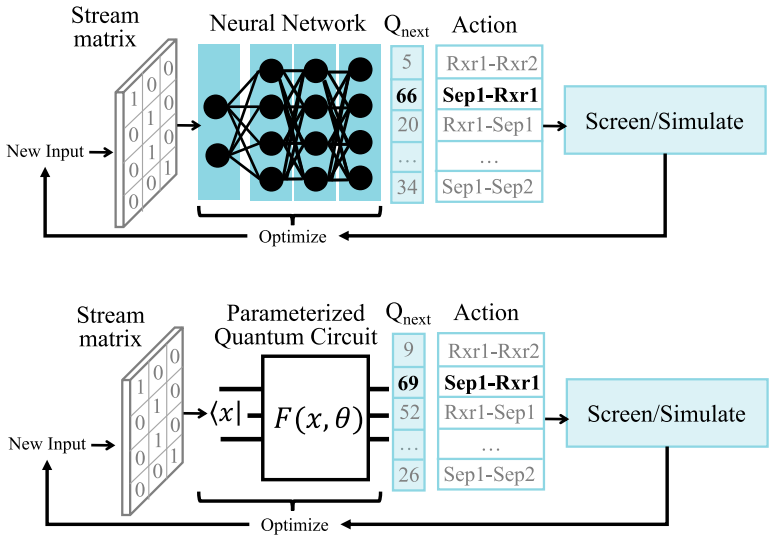



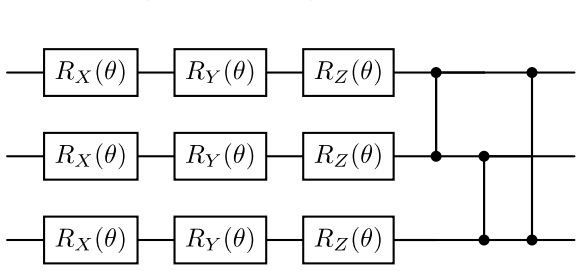






read the original abstract
In this work, we present quantum reinforcement learning (RL) as a solution strategy for process synthesis problems. Building on our prior work, we develop a generalized framework that formally poses process synthesis as a Markov decision process and introduces quantum-enhanced RL algorithms to solve it with improved scalability. Earlier implementations of quantum-based RL for process synthesis were limited by qubit requirements, which scaled poorly with problem complexity. This work overcomes this challenge by introducing state encoding algorithms to decouple qubit requirements from problem size. A classical RL-based solution strategy is used as a baseline to benchmark the quantum algorithms under identical training conditions. All algorithms are evaluated across a flowsheet synthesis problem of increasing unit counts to analyze their performance and scalability. Results show that all approaches are capable of identifying the optimal flowsheet designs in small design spaces. For moderate-scale unit counts, quantum approaches demonstrate competitive performance on a per-episode basis and improved efficiency on a per-parameter basis versus the classical RL benchmark. This work provides a foundation for future quantum computing applications within process systems engineering, establishes a controlled benchmark for comparing classical and quantum algorithms, and shows that the proposed quantum variants remain competitive for the process synthesis problem examined in this work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates process synthesis as a Markov decision process and develops quantum reinforcement learning algorithms augmented by state encoding schemes that aim to decouple qubit count from the number of units. A classical RL baseline is trained under identical conditions and the methods are compared on flowsheet synthesis instances with increasing unit counts. The central empirical claim is that, for small design spaces, all methods recover optimal flowsheets, while for moderate-scale instances the quantum variants remain competitive on a per-episode basis and exhibit improved per-parameter efficiency.
Significance. If the optimality verification and encoding fidelity claims hold under quantitative scrutiny, the work supplies a controlled, reproducible benchmark for quantum versus classical RL on a combinatorial design task relevant to process systems engineering. The explicit introduction of state encoding to mitigate qubit scaling is a concrete technical contribution that could be built upon in future hybrid quantum-classical optimization studies.
major comments (2)
- [Results] Results section: the statement that 'all approaches are capable of identifying the optimal flowsheet designs' is load-bearing for the competitiveness claim, yet the manuscript reports only per-episode reward curves without tabulating the final flowsheet topologies, objective values, or feasibility checks obtained by each algorithm. Without this explicit comparison it is impossible to confirm that the quantum agents reach the identical optima rather than alternative solutions of comparable reward.
- [Methods] State-encoding subsection (Methods): the claim that the introduced encoding algorithms 'preserve enough information' to allow the quantum agent to reach the same optimal solutions while reducing qubit scaling is not supported by an injectivity argument or by an empirical collision test. If distinct unit-connection or mode configurations map to indistinguishable quantum states, policy gradients can converge to a different policy even when average rewards appear competitive; a small-scale example showing the mapping for two non-isomorphic feasible flowsheets would directly address this risk.
minor comments (2)
- The abstract would be strengthened by naming the specific quantum RL variants (e.g., variational quantum circuit policy or amplitude amplification) and by stating the qubit counts actually used for each unit-count instance.
- Figure captions and axis labels should explicitly indicate whether shaded regions represent standard deviation across seeds or inter-quartile range; current presentation makes it difficult to judge whether the reported competitiveness is statistically meaningful.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments in detail below and have made revisions to the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Results] Results section: the statement that 'all approaches are capable of identifying the optimal flowsheet designs' is load-bearing for the competitiveness claim, yet the manuscript reports only per-episode reward curves without tabulating the final flowsheet topologies, objective values, or feasibility checks obtained by each algorithm. Without this explicit comparison it is impossible to confirm that the quantum agents reach the identical optima rather than alternative solutions of comparable reward.
Authors: We agree that providing explicit details on the final flowsheet topologies is important to substantiate our claim. In the revised manuscript, we have added a table in the Results section that compares the optimal flowsheets identified by each method for the small design space cases. This table includes the topologies, objective values, and confirmation of feasibility, demonstrating that all algorithms recover the same optimal designs. revision: yes
-
Referee: [Methods] State-encoding subsection (Methods): the claim that the introduced encoding algorithms 'preserve enough information' to allow the quantum agent to reach the same optimal solutions while reducing qubit scaling is not supported by an injectivity argument or by an empirical collision test. If distinct unit-connection or mode configurations map to indistinguishable quantum states, policy gradients can converge to a different policy even when average rewards appear competitive; a small-scale example showing the mapping for two non-isomorphic feasible flowsheets would directly address this risk.
Authors: We recognize the value of an explicit demonstration that the state encoding preserves distinguishability. We have revised the Methods section to include a small-scale example illustrating the encoding of two non-isomorphic feasible flowsheets. This example shows their distinct mappings to quantum states, supporting that the encoding maintains sufficient information for the agent to differentiate between configurations. We have also added a short discussion on the encoding properties to address potential collision risks. revision: yes
Circularity Check
Minor self-citation for MDP framework; central benchmark comparisons remain independent
full rationale
The paper builds on prior work to pose process synthesis as an MDP and introduces state encoding to decouple qubit count from problem size. Performance claims rest on empirical evaluation of quantum RL variants against a classical RL baseline under identical training conditions across increasing unit counts. No equations or derivations reduce claimed improvements to fitted parameters, self-referential definitions, or unverified self-citations. The self-reference is limited to framework setup and is not load-bearing for the reported per-episode competitiveness and per-parameter efficiency results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Process synthesis can be faithfully represented as a Markov decision process whose optimal policy corresponds to the globally optimal flowsheet.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We augment the process synthesis DQN algorithm into a quantum-DQN algorithm... substituting the neural Q-function approximating components with the quantum counterparts (i.e., the NNs are replaced with quantum circuits)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Variants 1–3 define a structured comparison of quantum state encoding strategies... Lmin = ⌈nx / nq⌉
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. N. Pistikopoulos, R. Gani, Data, models, algorithms, AI and the role of PSE – the generation next, Computers & Chemical Engineering 207 (2026) 109564
work page 2026
-
[2]
A. Braniff, S. S. Akundi, Y. Liu, B. Dantas, S. S. Niknezhad, F. Khan, E. N. Pistikopoulos, Y. Tian, Real-time process safety and systems decision-making toward safe and smart chemical manufacturing, Dig- ital Chemical Engineering 15 (2025) 100227
work page 2025
-
[3]
L. Mencarelli, Q. Chen, A. Pagot, I. E. Grossmann, A review on super- structure optimization approaches in process system engineering, Com- puters & Chemical Engineering 136 (2020) 106808
work page 2020
-
[4]
F.Boukouvala, R.Misener, C.A.Floudas, Globaloptimizationadvances in Mixed-Integer Nonlinear Programming, MINLP, and Constrained Derivative-Free Optimization, CDFO, European Journal of Operational Research 252 (3) (2016) 701–727
work page 2016
-
[5]
D. A. Liñán, L. A. Ricardez-Sandoval, Trends and perspectives in deter- ministic MINLP optimization for integrated planning, scheduling, con- trol, and design of chemical processes, Reviews in Chemical Engineering 41 (5) (2025) 451–472
work page 2025
-
[6]
I. E. Grossmann, F. Trespalacios, Systematic modeling of discrete- continuous optimization models through generalized disjunctive pro- gramming, AIChE Journal 59 (9) (2013) 3276–3295
work page 2013
-
[7]
J. A. Frumkin, M. F. Doherty, Target bounds on reaction selectivity via Feinberg’s CFSTR equivalence principle, AIChE Journal 64 (3) (2018) 926–939
work page 2018
-
[8]
E. N. Pistikopoulos, Y. Tian, Synthesis and Operability Strategies for Computer-Aided Modular Process Intensification, Elsevier, 2022
work page 2022
-
[9]
Y. Tian, S. E. Demirel, M. M. F. Hasan, E. N. Pistikopoulos, An overview of process systems engineering approaches for process intensifi- cation: State of the art, Chemical Engineering and Processing - Process Intensification 133 (2018) 160–210. 36
work page 2018
-
[10]
E. N. Pistikopoulos, Y. Tian, Advanced Modeling and Optimization Strategies for Process Synthesis, Annual Review of Chemical and Biomolecular Engineering 15 (Volume 15, 2024) (2024) 81–103
work page 2024
-
[11]
Q. Gao, A. M. Schweidtmann, Deep reinforcement learning for process design: Review and perspective, Current Opinion in Chemical Engineer- ing 44 (2024) 101012
work page 2024
- [12]
-
[13]
D. E. Bernal, A. Ajagekar, S. M. Harwood, S. T. Stober, D. Trenev, F. You, Perspectives of quantum computing for chemical engineering, AIChE Journal 68 (6) (2022) e17651
work page 2022
-
[14]
A. Ajagekar, F. You, New frontiers of quantum computing in chemical engineering, Korean Journal of Chemical Engineering 39 (4) (2022) 811– 820
work page 2022
-
[15]
D. E. Bernal, K. E. C. Booth, R. Dridi, H. Alghassi, S. Tayur, D. Ven- turelli, Integer Programming Techniques for Minor-Embedding in Quan- tum Annealers, in: E. Hebrard, N. Musliu (Eds.), Integration of Con- straint Programming, Artificial Intelligence, and Operations Research, Springer International Publishing, Cham, 2020, pp. 112–129
work page 2020
-
[16]
A. Ajagekar, T. Humble, F. You, Quantum computing based hybrid solution strategies for large-scale discrete-continuous optimization prob- lems, Computers & Chemical Engineering 132 (2020) 106630
work page 2020
- [17]
- [18]
-
[19]
M. Benedetti, E. Lloyd, S. Sack, M. Fiorentini, Parameterized quantum circuits as machine learning models, Quantum Science and Technology 4 (4) (2019) 043001
work page 2019
- [20]
-
[21]
A. Braniff, F. You, Y. Tian, Enhanced Reinforcement Learning-driven Process Design via Quantum Machine Learning, in: The 35th European Symposium on Computer Aided Process Engineering, Ghent, Belgium, 2025, pp. 1403–1408
work page 2025
-
[22]
A. Braniff, F. You, Y. Tian, Process flowsheet synthesis via quantum reinforcement learning with improved scalability, in: The 36th European Symposium on Computer Aided Process Engineering, 2026
work page 2026
- [23]
-
[24]
J. Shin, T. A. Badgwell, K.-H. Liu, J. H. Lee, Reinforcement Learn- ing – Overview of recent progress and implications for process control, Computers & Chemical Engineering 127 (2019) 282–294
work page 2019
-
[25]
A. Braniff, Y. Tian, Reinforcement learning-based control via Y-wise Affine Neural Networks (YANNs), Computers & Chemical Engineering 209 (2026) 109610
work page 2026
-
[26]
D. Rangel-Martinez, L. A. Ricardez-Sandoval, Interpretable online schedulingforchemicalbatchplantswithattentionaugmentedreinforce- ment learning agents, Computers & Chemical Engineering 205 (2026) 109469
work page 2026
-
[27]
C. D. Hubbs, C. Li, N. V. Sahinidis, I. E. Grossmann, J. M. Wassick, A deep reinforcement learning approach for chemical production schedul- ing, Computers & Chemical Engineering 141 (2020) 106982
work page 2020
- [28]
-
[29]
Q. Gao, H. Yang, S. M. Shanbhag, A. M. Schweidtmann, Transfer learn- ing for process design with reinforcement learning, in: A. C. Kokossis, M. C. Georgiadis, E. Pistikopoulos (Eds.), 33rd European Symposium on Computer Aided Process Engineering, Vol. 52 of Computer Aided Chemical Engineering, Elsevier, 2023, pp. 2005–2010
work page 2023
-
[30]
A. Khan, A. Lapkin, Searching for optimal process routes: A reinforce- ment learning approach, Computers & Chemical Engineering 141 (2020) 107027
work page 2020
- [31]
-
[32]
D. Wang, J. Bao, M. Zamarripa-Perez, B. Paul, Y. Chen, P. Gao, T. Ma, A. Noring, A. Iyengar, D. Schwartz, E. Eggleton, Q. He, A. Liu, O. Ma- rina, B. Koeppel, Z. Xu, Reinforcement learning for automated concep- tual design of advanced energy and chemical systems (Dec. 2022)
work page 2022
- [33]
-
[34]
Q. Göttl, D. G. Grimm, J. Burger, Using reinforcement learning in a game-like setup for automated process synthesis without prior process knowledge, in: Y. Yamashita, M. Kano (Eds.), 14th International Sym- posium on Process Systems Engineering, Vol. 49 of Computer Aided Chemical Engineering, Elsevier, 2022, pp. 1555–1560
work page 2022
-
[35]
S. Reynoso-Donzelli, L. A. Ricardez-Sandoval, A reinforcement learn- ing approach with masked agents for chemical process flowsheet design, AIChE Journal 71 (1) (2025) e18584
work page 2025
-
[36]
J. R. Seidenberg, A. A. Khan, A. A. Lapkin, Boosting autonomous process design and intensification with formalized domain knowledge, Computers & Chemical Engineering 169 (2023) 108097
work page 2023
- [37]
-
[38]
S. Reynoso-Donzelli, L. A. Ricardez-Sandoval, An integrated reinforce- ment learning framework for simultaneous generation, design, and con- trol of chemical process flowsheets, Computers & Chemical Engineering 194 (2025) 108988
work page 2025
-
[39]
Q. Gao, H. Yang, M. F. Theisen, A. M. Schweidtmann, Accelerating process synthesis with reinforcement learning: Transfer learning from multi-fidelity simulations and variational autoencoders, Computers & Chemical Engineering 201 (2025) 109192
work page 2025
-
[40]
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier- stra, M. Riedmiller, Playing Atari with Deep Reinforcement Learning (Dec. 2013). arXiv:1312.5602
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[41]
S. Harwood, C. Gambella, D. Trenev, A. Simonetto, D. Bernal Neira, D. Greenberg, Formulating and Solving Routing Problems on Quantum Computers, IEEE Transactions on Quantum Engineering 2 (2021) 1–17
work page 2021
-
[42]
V. Raseena, Quantum computing: Foundations, algorithms, and emerg- ing applications, Frontiers in Quantum Science and Technology 4 (Dec. 2025)
work page 2025
-
[43]
Preskill, Quantum Computing in the NISQ era and beyond, Quantum 2 (2018) 79
J. Preskill, Quantum Computing in the NISQ era and beyond, Quantum 2 (2018) 79
work page 2018
- [44]
-
[45]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, S. Lloyd, Quantum machine learning, Nature 549 (7671) (2017) 195–202
work page 2017
-
[46]
L. Chen, T. Li, Y. Chen, X. Chen, M. Wozniak, N. Xiong, W. Liang, Design and analysis of quantum machine learning: A survey, Connection Science 36 (1) (2024) 2312121
work page 2024
- [47]
- [48]
-
[49]
S. Y.-C. Chen, C.-H. H. Yang, J. Qi, P.-Y. Chen, X. Ma, H.-S. Goan, Variational Quantum Circuits for Deep Reinforcement Learning, IEEE Access 8 (2020) 141007–141024
work page 2020
-
[50]
H.-Y. Chen, Y.-J. Chang, S.-W. Liao, C.-R. Chang, Deep-Q Learning with Hybrid Quantum Neural Network on Solving Maze Problems (Dec. 2023). arXiv:2304.10159
- [51]
- [52]
-
[53]
Y. Tian, A. Akintola, Y. Jiang, D. Wang, J. Bao, M. A. Zamarripa, B. Paul, Y. Chen, P. Gao, A. Noring, A. Iyengar, A. Liu, O. Marina, B. Koeppel, Z. Xu, Reinforcement Learning-Driven Process Design: A Hydrodealkylation Example, in: Foundations of Computer-Aided Pro- cess Design, Breckenridge, Colorado, USA, 2024, pp. 387–393
work page 2024
-
[54]
A. Lee, J. H. Ghouse, J. C. Eslick, C. D. Laird, J. D. Siirola, M. A. Zamarripa, D. Gunter, J. H. Shinn, A. W. Dowling, D. Bhattacharyya, L. T. Biegler, A. P. Burgard, D. C. Miller, The IDAES process modeling framework and model library—Flexibility for process simulation and optimization, Journal of Advanced Manufacturing and Processing 3 (3) (2021) e10095
work page 2021
-
[55]
L. T. Biegler, V. M. Zavala, Large-scale nonlinear programming using IPOPT: An integrating framework for enterprise-wide dynamic opti- mization, Computers & Chemical Engineering 33 (3) (2009) 575–582. 41
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.