Stochastic MeanFlow Policies: One-Step Generative Control with Entropic Mirror Descent
Pith reviewed 2026-05-22 09:48 UTC · model grok-4.3
The pith
Stochastic MeanFlow Policies map Gaussian noise to actions in one step for multimodal off-policy RL with tractable entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Stochastic MeanFlow Policies map Gaussian noise to actions through a MeanFlow transformation. This stochastic reparameterisation yields a tractable entropy surrogate and allows MeanFlow policies to be trained within off-policy mirror descent under a unified objective for exploratory yet stable improvement. Across seven MuJoCo benchmarks, SMFP improves over Gaussian and generative baselines while retaining single-step inference efficiency.
What carries the argument
MeanFlow transformation: a one-pass stochastic mapping from Gaussian noise to actions that supplies a usable entropy surrogate inside the mirror-descent update.
If this is right
- A single objective can now enforce both exploration via entropy and stability via previous-policy regularization.
- Policy classes no longer need to trade off multimodality against single-step sampling speed.
- Off-policy mirror descent becomes directly compatible with generative policies that have tractable entropy.
- Performance improvements appear across standard continuous-control benchmarks without extra sampling cost at deployment.
Where Pith is reading between the lines
- The same one-step noise-to-action idea could be tested in settings where sampling speed matters more than in MuJoCo, such as real-time robotics or large-scale planning.
- If the entropy surrogate remains reliable, similar transformations might reduce the need for separate entropy-coefficient tuning in other RL algorithms.
- Extending the MeanFlow construction to discrete or hybrid action spaces would test whether the approach generalizes beyond continuous control.
Load-bearing premise
The MeanFlow policy class can match the multimodal target created by entropy regularization plus the mirror-descent constraint closely enough that the entropy surrogate stays accurate and does not bias the performance gains.
What would settle it
Train SMFP on an environment whose optimal policy requires clearly separated action modes; if the learned policy collapses to a single mode or the reported gains over Gaussian policies disappear, the central claim does not hold.
Figures




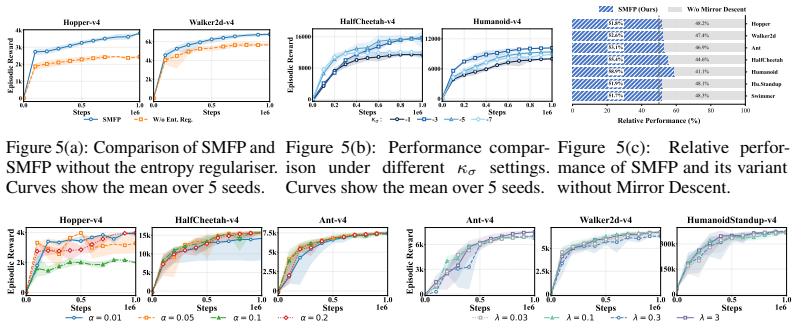

read the original abstract
Online off-policy reinforcement learning (RL) is shaped by two coupled choices: the policy class and the update rule. Gaussian policies are fast and have tractable entropy, but struggle with multimodal action distributions. Generative policies are more expressive, but often require iterative sampling or lack tractable entropy estimates. On the optimisation side, SAC-style soft policy improvement and mirror descent (MD) can be viewed as minimising different KL divergences: the former moves the policy towards a value-induced Boltzmann distribution, while the latter regularises each update against the previous policy. Combining entropy regularisation with an MD constraint is therefore attractive, as it supports exploration while stabilising policy improvement; however, the resulting target can be multimodal and is poorly matched by unimodal Gaussian policies. We propose Stochastic MeanFlow Policies (SMFP), a one-step generative policy class that maps Gaussian noise to actions through a MeanFlow transformation. This stochastic reparameterisation yields a tractable entropy surrogate and allows MeanFlow policies to be trained within off-policy mirror descent under a unified objective for exploratory yet stable improvement. Across seven MuJoCo benchmarks, SMFP improves over Gaussian and generative baselines while retaining single-step inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Stochastic MeanFlow Policies (SMFP), a one-step generative policy class that maps Gaussian noise to actions via a MeanFlow transformation. This stochastic reparameterization is claimed to produce a tractable entropy surrogate, enabling training of the policies within an off-policy mirror descent framework under a unified objective that combines entropy regularization (for exploration) with the mirror descent constraint (for stability). The paper asserts that this yields exploratory yet stable improvement and reports empirical gains over Gaussian and generative baselines across seven MuJoCo benchmarks while preserving single-step inference efficiency.
Significance. If the entropy surrogate is shown to be sufficiently accurate and unbiased under the multimodal target induced by the combined objective, and if the empirical gains are reproducible with proper controls, the work could provide a practical bridge between expressive generative policies and the tractability requirements of off-policy RL. It would address a recurring tension in continuous control by allowing multimodal action distributions without iterative sampling or loss of entropy estimates.
major comments (2)
- Abstract: the central claim that the stochastic reparameterization 'yields a tractable entropy surrogate' supporting stable off-policy mirror descent is load-bearing, yet the abstract supplies no explicit form of the surrogate, derivation, or error bound relative to the true entropy on the multimodal target created by entropy regularization plus the MD constraint; without this, it is impossible to assess whether bias in the surrogate could shift the fixed point of the unified objective away from the intended one.
- Empirical evaluation (referenced in abstract): the reported improvements on seven MuJoCo benchmarks are presented without error bars, ablation studies isolating the entropy surrogate, or controls for the MeanFlow transformation itself; this makes it difficult to attribute gains specifically to the proposed method rather than implementation details or baseline tuning.
minor comments (1)
- Abstract: the description of the MeanFlow transformation could be expanded with one additional sentence defining the map to improve accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the central claim that the stochastic reparameterization 'yields a tractable entropy surrogate' supporting stable off-policy mirror descent is load-bearing, yet the abstract supplies no explicit form of the surrogate, derivation, or error bound relative to the true entropy on the multimodal target created by entropy regularization plus the MD constraint; without this, it is impossible to assess whether bias in the surrogate could shift the fixed point of the unified objective away from the intended one.
Authors: The derivation of the entropy surrogate appears in Section 3.2, where the MeanFlow transformation is applied to standard Gaussian noise and the change-of-variables formula yields an exact, closed-form entropy for the resulting policy. Because the surrogate matches the entropy of the policy class exactly, it does not introduce bias that would alter the fixed point of the combined objective; the mirror-descent constraint is enforced on the policy parameters independently of the entropy term. We agree the abstract is overly terse on this point and will revise it to state the surrogate form and point to the derivation. revision: yes
-
Referee: Empirical evaluation (referenced in abstract): the reported improvements on seven MuJoCo benchmarks are presented without error bars, ablation studies isolating the entropy surrogate, or controls for the MeanFlow transformation itself; this makes it difficult to attribute gains specifically to the proposed method rather than implementation details or baseline tuning.
Authors: We accept that the current presentation lacks sufficient controls. In the revision we will report mean performance with standard-deviation error bars over ten independent random seeds, add an ablation that removes the entropy-surrogate term while keeping the MeanFlow policy class, and include a control that applies the MeanFlow transform to a standard Gaussian policy. These additions will allow clearer attribution of the observed gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces Stochastic MeanFlow Policies as a new one-step generative policy class whose stochastic reparameterization is defined to produce a tractable entropy surrogate, which is then used inside an off-policy mirror-descent objective. This construction is presented directly from the policy definition and the choice of MeanFlow map rather than by fitting a parameter to the target quantity or by reducing to a prior self-citation. The central performance claims are supported by external MuJoCo benchmark comparisons rather than by any internal renaming or self-referential fitting. No load-bearing equation or step in the abstract or described derivation reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This stochastic reparameterisation yields a tractable entropy surrogate ... hinge-style entropy regulariser ... advantage-weighted MeanFlow regression objective
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified objective for exploratory yet stable improvement ... off-policy mirror descent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Riedmiller. Maximum a posteriori policy optimisation. InInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[2]
Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization.Operations Research Letters, 31(3):167–175, 2003
work page 2003
-
[3]
A distributional perspective on reinforce- ment learning
Marc G Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforce- ment learning. InInternational conference on machine learning (ICML), 2017
work page 2017
-
[4]
Aditya Bhatt, Daniel Palenicek, Boris Belousov, Max Argus, Artemij Amiranashvili, Thomas Brox, and Jan Peters. Crossq: Batch normalization in deep reinforcement learning for greater sample efficiency and simplicity. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[5]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Dime: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. Dime: Diffusion-based maximum entropy reinforcement learning. In International conference on machine learning (ICML), 2025
work page 2025
-
[7]
Simple hi- erarchical planning with diffusion
Chang Chen, Fei Deng, Kenji Kawaguchi, Caglar Gulcehre, and Sungjin Ahn. Simple hi- erarchical planning with diffusion. InThe Twelfth International Conference on Learning Representations(ICLR), 2024
work page 2024
-
[8]
One-step flow policy mirror descent
Tianyi Chen, Haitong Ma, Na Li, Kai Wang, and Bo Dai. One-step flow policy mirror descent. arXiv preprint arXiv:2507.23675, 2025
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 2023
work page 2023
-
[10]
How Many Random Seeds? Statistical Power Analysis in Deep Reinforcement Learning Experiments
Cédric Colas, Olivier Sigaud, and Pierre-Yves Oudeyer. How many random seeds? statistical power analysis in deep reinforcement learning experiments.arXiv preprint arXiv:1806.08295, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Stephen Dankwa and Wenfeng Zheng. Twin-delayed ddpg: A deep reinforcement learning technique to model a continuous movement of an intelligent robot agent. InProceedings of the 3rd international conference on vision, image and signal processing, 2019
work page 2019
-
[12]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[13]
Consistency models as a rich and efficient policy class for reinforcement learning
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024. 10
work page 2024
-
[14]
Maximum entropy reinforcement learning with diffusion policy
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[15]
Scaling offline rl via efficient and expressive shortcut models
Nicolas Espinosa-Dice, Yiyi Zhang, Yiding Chen, Bradley Guo, Owen Oertell, Gokul Swamy, Kianté Brantley, and Wen Sun. Scaling offline rl via efficient and expressive shortcut models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[16]
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[17]
Ffjord: Free-form continuous dynamics for scalable reversible generative models
Will Grathwohl, Ricky TQ Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. Ffjord: Free-form continuous dynamics for scalable reversible generative models. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[18]
Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates
Shixiang Gu, Ethan Holly, Timothy Lillicrap, and Sergey Levine. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017
work page 2017
-
[19]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning (ICML), 2017
work page 2017
-
[20]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning (ICML), 2018
work page 2018
-
[21]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[23]
Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics-Simulation and Computation, 18(3):1059– 1076, 1989
work page 1989
-
[24]
Sergey Ioffe. Batch renormalization: Towards reducing minibatch dependence in batch- normalized models.Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[25]
Langevin soft actor-critic: Efficient exploration through uncertainty-driven critic learning
Haque Ishfaq, Guangyuan Wang, Sami Nur Islam, and Doina Precup. Langevin soft actor-critic: Efficient exploration through uncertainty-driven critic learning. InInternational Conference on Learning Representations(ICLR), 2025
work page 2025
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Auto-encoding variational bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. InInternational Conference on Learning Representations (ICLR), 2014
work page 2014
-
[28]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: tutorial and review.arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[31]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023. 11
work page 2023
-
[32]
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, Tao Kong, Jiafeng Xu, and Xiao Ma. Flow-based policy for online reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[33]
Lei Lv, Yunfei Li, Yu Luo, Fuchun Sun, and Xiao Ma. Flac: Maximum entropy rl via kinetic energy regularized bridge matching.arXiv preprint arXiv:2602.12829, 2026
-
[34]
Efficient online reinforcement learning for diffusion policy
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy. InForty-second International Conference on Machine Learning (ICML), 2025
work page 2025
-
[35]
Walk these ways: Tuning robot control for gener- alization with multiplicity of behavior
Gabriel B Margolis and Pulkit Agrawal. Walk these ways: Tuning robot control for gener- alization with multiplicity of behavior. InAnnual Conference on Robot Learning. PMLR, 2023
work page 2023
-
[36]
Octo: An open-source generalist robot policy
Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA, 2024
work page 2024
-
[37]
Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control
Michal Nauman, Mateusz Ostaszewski, Krzysztof Jankowski, Piotr Miło´s, and Marek Cygan. Bigger, regularized, optimistic: scaling for compute and sample efficient continuous control. Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[38]
Gergely Neu, Anders Jonsson, and Vicenç Gómez. A unified view of entropy-regularized markov decision processes.International Conference on Machine Learning (ICML), 2019
work page 2019
-
[39]
Investigating the utility of mirror descent in off-policy actor-critic
Samuel Neumann, Jiamin He, Adam White, and Martha White. Investigating the utility of mirror descent in off-policy actor-critic. InReinforcement Learning Conference (RLC), 2025
work page 2025
-
[40]
Much ado about noising: Dispelling the myths of generative robotic control
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, et al. Much ado about noising: Dispelling the myths of generative robotic control. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[41]
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. InInternational conference on machine learning (ICML), 2025
work page 2025
-
[42]
Empirical design in reinforcement learning.Journal of Machine Learning Research (JMLR), 2024
Andrew Patterson, Samuel Neumann, Martha White, and Adam White. Empirical design in reinforcement learning.Journal of Machine Learning Research (JMLR), 2024
work page 2024
-
[43]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision (ICCV), pages 4195–4205, 2023
work page 2023
-
[44]
Learning a diffusion model policy from rewards via q-score matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
work page 2024
-
[45]
Garvesh Raskutti and Sayan Mukherjee. The information geometry of mirror descent.IEEE Transactions on Information Theory, 61(3):1451–1457, 2015
work page 2015
-
[46]
Stochastic backpropagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. InInternational Conference on Machine Learning (ICML), 2014
work page 2014
-
[47]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[48]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021. 12
work page 2021
-
[50]
Chen Tang, Ben Abbatematteo, Jiaheng Hu, Rohan Chandra, Roberto Martín-Martín, and Peter Stone. Deep reinforcement learning for robotics: A survey of real-world successes.Annual Review of Control, Robotics, and Autonomous Systems, 2025
work page 2025
-
[51]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
work page 2012
-
[52]
Mirror descent policy optimization
Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization. InInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[53]
Nino Vieillard, Tadashi Kozuno, Bruno Scherrer, Olivier Pietquin, Rémi Munos, and Matthieu Geist. Leverage the average: an analysis of kl regularization in reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[54]
Qing Wang, Yingru Li, Jiechao Xiong, and Tong Zhang. Divergence-augmented policy opti- mization.Advances in Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[55]
Diffusion actor-critic with entropy regulator
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, et al. Diffusion actor-critic with entropy regulator. Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[56]
One-step generative policies with q-learning: A reformulation of meanflow
Zeyuan Wang, Da Li, Yulin Chen, Ye Shi, Liang Bai, Tianyuan Yu, and Yanwei Fu. One-step generative policies with q-learning: A reformulation of meanflow. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
work page 2026
-
[57]
Policy representation via diffusion probability model for reinforcement learning
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning.arXiv preprint arXiv:2305.13122, 2023
-
[58]
Simple and effective stochastic neural networks
Tianyuan Yu, Yongxin Yang, Da Li, Timothy Hospedales, and Tao Xiang. Simple and effective stochastic neural networks. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021
work page 2021
-
[59]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[60]
dX i=1 logσ (i) θ (at, b, t) # + d 2 log(2πe) | {z } const. ⇒ ˜H(πθ |e) =E e
Yixian Zhang, Shu’ang Yu, Tonghe Zhang, Mo Guang, Haojia Hui, Kaiwen Long, Yu Wang, Chao Yu, and Wenbo Ding. Sac flow: Sample-efficient reinforcement learning of flow-based policies via velocity-reparameterized sequential modeling.International Conference on Learn- ing Representations(ICLR), 2026. 13 A Limitations and Future Work Although the hybrid optim...
work page 2026
-
[61]
Monotonicity.Higher advantage samples receive strictly higher weights, preserving the rank-based preference for high-value regions. The rectification ensures that sub-optimal actions (where A <0 ) are filtered out, focusing the generative modelling solely on the improving regions of the action space
-
[62]
Numerical Stability and Implicit Gradient Clipping.The exponential function is highly sensitive to the scale of Q-values. In practice, unbounded Q-values can cause exp(A/λ) to explode, resulting in numerical overflow and unstable gradients. The truncated linear approximation(Q−V) + naturally bounds the weights and acts as an implicit gradient clipper. Thi...
-
[63]
Scale Invariance and Hyperparameter Robustness.In standard exponential weighting exp(A/λ), the regularisation coefficient λ must be carefully tuned for each environment, as the scale of return (and thus the Q-values) varies significantly across different tasks. A fixedλ can lead to vanishing gradients in high-reward environments or uniform weights in low-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.