DynaFlow: Transparent and Flexible Intra-Device Parallelism via Programmable Operator Scheduling
Pith reviewed 2026-05-22 08:31 UTC · model grok-4.3
The pith
DynaFlow decouples logical model definition from physical execution schedule to add intra-device parallelism flexibly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DynaFlow enables transparent and flexible integration of intra-device parallelism by decoupling the logical model definition from the physical execution schedule. It supplies annotations for graph partitioning and a programmable interface for custom strategies in the frontend, while the backend asynchronously manages complex control and data flows, uses custom memory management to remove copy overhead, and keeps compatibility with optimizations such as CUDA Graphs and TorchInductor.
What carries the argument
Decoupling of the logical model definition from the physical execution schedule, realized through annotations for graph partitioning and a programmable interface for custom intra-device parallelism strategies.
If this is right
- Representative parallelism strategies integrate into six state-of-the-art ML systems with only minimal code changes.
- Throughput improves by up to 1.29x for inference and training workloads.
- Compatibility is retained with existing optimizations including CUDA Graphs and TorchInductor.
- Strategies adapt to different workloads, model architectures, and hardware without maintaining multiple specialized versions.
Where Pith is reading between the lines
- The same separation of logic from schedule could lower the cost of experimenting with new operator-overlap ideas across the broader ML ecosystem.
- Framework designers might adopt similar decoupling layers to support dynamic scheduling as a built-in feature rather than an add-on.
- The technique could be tested on training loops with larger batch sizes to see whether the asynchronous backend scales without introducing new bottlenecks.
Load-bearing premise
The annotations for graph partitioning and the programmable interface can be added to existing ML frameworks without invasive overhauls or breaking compatibility with optimizations like CUDA Graphs and TorchInductor.
What would settle it
Integrating DynaFlow into a seventh ML framework and measuring both the lines of code changed and the resulting throughput on a range of models and hardware to check whether gains stay near 1.29x.
Figures














read the original abstract
Intra-device parallelism addresses resource under-utilization in ML inference and training by overlapping the execution of operators with different resource usage. However, its wide adoption is hindered by a fundamental conflict with the static, sequential programming model of existing frameworks. Integrating these strategies requires invasive, model-specific code overhauls, representing an intractable engineering cost. This is further amplified by the high sensitivity of strategies to execution contexts (e.g., workload, model architecture, hardware), forcing developers to implement and maintain multiple specialized solutions. To address this, we propose DynaFlow, a framework that enables the transparent and flexible integration of intra-device parallelism by decoupling the logical model definition from the physical execution schedule. DynaFlow introduces a flexible frontend with annotations for graph partitioning and a programmable interface for defining custom intra-device parallelism strategies. Its efficient backend manages complex control/data-flow asynchronously, uses custom memory management to eliminate copy overheads, and preserves compatibility with optimizations like CUDA Graphs and TorchInductor. We demonstrate that DynaFlow can integrate representative parallelism strategies into 6 state-of-the-art ML systems with minimal code changes, achieving up to a 1.29x throughput improvement. DynaFlow is publicly available at https://github.com/uw-syfi/DynaFlow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DynaFlow, a framework that decouples logical model definition from physical execution schedule to enable transparent integration of intra-device parallelism strategies. It provides a frontend with graph partitioning annotations and a programmable interface for custom strategies, backed by an asynchronous backend using custom memory management that claims to preserve compatibility with CUDA Graphs and TorchInductor. Evaluation shows integration of representative strategies into 6 state-of-the-art ML systems with minimal code changes and up to 1.29x throughput gains.
Significance. If the compatibility and minimal-overhaul claims hold, the work could meaningfully reduce engineering costs for adopting context-sensitive intra-device parallelism across ML frameworks, improving resource utilization in inference and training. Public code release supports reproducibility and further experimentation.
major comments (2)
- [§4.3] §4.3 (Backend Implementation): The claim that the asynchronous control/data-flow management and custom memory management preserve compatibility with static CUDA Graphs and TorchInductor is load-bearing for the central 'transparent integration without invasive changes' thesis, yet the manuscript provides no concrete mechanism (e.g., static pre-allocation rules or how partitioning annotations eliminate runtime decisions) that would guarantee capture succeeds for arbitrary custom strategies.
- [§5.1] §5.1 (Integration Experiments): The reported 1.29x throughput gains across the six systems rest on integration results, but without explicit baseline definitions, data exclusion criteria, or component ablations, it is not possible to confirm that gains are attributable to DynaFlow rather than unstated factors or framework-specific tuning.
minor comments (2)
- [§3.1] Notation in §3.1 for the programmable interface could be clarified with a small example of a complete custom strategy definition to aid reader understanding.
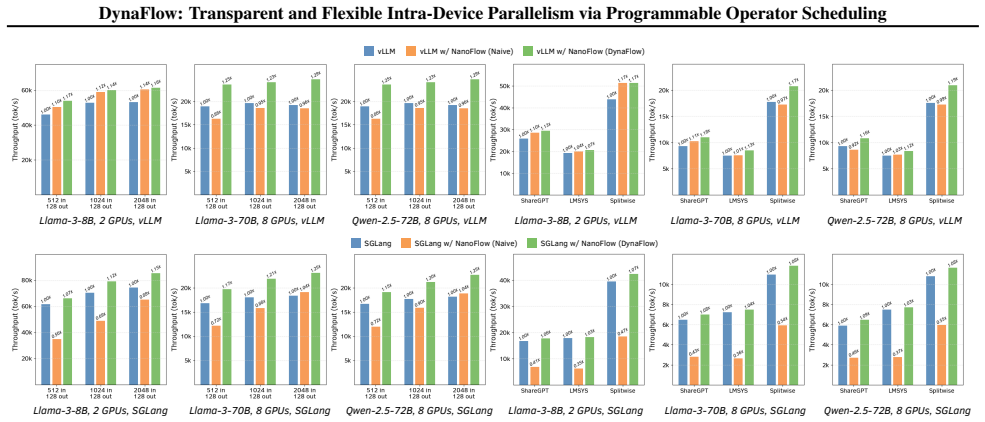
- [Figure 5] Figure 5 (throughput plots): Adding per-run variance or confidence intervals would strengthen visual interpretation of the speedups.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major point below, clarifying the mechanisms and experimental details while committing to revisions that strengthen the manuscript without misrepresenting our contributions.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Backend Implementation): The claim that the asynchronous control/data-flow management and custom memory management preserve compatibility with static CUDA Graphs and TorchInductor is load-bearing for the central 'transparent integration without invasive changes' thesis, yet the manuscript provides no concrete mechanism (e.g., static pre-allocation rules or how partitioning annotations eliminate runtime decisions) that would guarantee capture succeeds for arbitrary custom strategies.
Authors: We agree that §4.3 would benefit from greater specificity on the compatibility mechanism. In the revised manuscript we will expand this section to explain that the frontend partitioning annotations are resolved at graph-construction time, producing a fixed operator grouping and data-flow DAG. This static plan is then handed to the asynchronous backend, which performs all memory allocations upfront using a custom pool sized to the maximum live tensors required by the plan. Because no allocations or control-flow decisions occur after the initial capture phase, the resulting execution stream satisfies the requirements for CUDA Graph capture and remains compatible with TorchInductor’s static optimizations. We will include a short pseudocode example and a table contrasting dynamic versus annotated execution to make the guarantee explicit for the representative strategies we evaluate. revision: yes
-
Referee: [§5.1] §5.1 (Integration Experiments): The reported 1.29x throughput gains across the six systems rest on integration results, but without explicit baseline definitions, data exclusion criteria, or component ablations, it is not possible to confirm that gains are attributable to DynaFlow rather than unstated factors or framework-specific tuning.
Authors: We acknowledge the value of additional experimental transparency. In the revision we will (1) explicitly define the baseline as the unmodified framework executing the identical model without any intra-device parallelism, (2) state the data-exclusion rules (discard first 20 % of iterations as warm-up and any run whose throughput deviates more than two standard deviations from the median), and (3) add a component ablation that isolates the contribution of the programmable scheduling interface from the custom memory manager. These clarifications will be placed in §5.1 and the corresponding appendix, allowing readers to attribute the observed speedups directly to the parallelism strategies enabled by DynaFlow. revision: yes
Circularity Check
No circularity: claims rest on implementation and measurements
full rationale
The paper describes a systems framework (DynaFlow) that decouples logical model definition from execution schedule via annotations and a programmable interface. Its central claims—transparent integration into 6 ML systems with minimal changes and up to 1.29x throughput—are presented as outcomes of the implemented backend (asynchronous control/data-flow, custom memory management, CUDA Graph compatibility) and empirical evaluation. No equations, fitted parameters, predictions, uniqueness theorems, or self-citation chains appear in the abstract or description that would reduce the result to its inputs by construction. The contribution is self-contained as an engineering artifact whose correctness is externally verifiable via the public GitHub release and reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Long- former: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Chang, L.-W., Bao, W., Hou, Q., Jiang, C., Zheng, N., Zhong, Y ., Zhang, X., Song, Z., Yao, C., Jiang, Z., et al. Flux: Fast software-based communication over- lap on gpus through kernel fusion.arXiv preprint arXiv:2406.06858,
-
[3]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Ge, S., Zhang, Y ., Liu, L., Zhang, M., Han, J., and Gao, J. Model tells you what to discard: Adaptive kv cache compression for llms.arXiv preprint arXiv:2310.01801,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference
Gond, R., Kwatra, N., and Ramjee, R. Tokenweave: Effi- cient compute-communication overlap for distributed llm inference.arXiv preprint arXiv:2505.11329,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Lepikhin, D., Lee, H., Xu, Y ., Chen, D., Firat, O., Huang, Y ., Krikun, M., Shazeer, N., and Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[6]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
USENIX Association. ISBN 978-1- 931971-16-4. URL https://www.usenix.org/ conference/osdi14/technical-sessions/ presentation/li_mu. Li, S., Zhao, Y ., Varma, R., Salpekar, O., Noordhuis, P., Li, T., Paszke, A., Smith, J., Vaughan, B., Damania, P., et al. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[7]
Liang, W., Liu, T., Wright, L., Constable, W., Gu, A., Huang, C.-C., Zhang, I., Feng, W., Huang, H., Wang, J., et al. Torchtitan: One-stop pytorch native solution DynaFlow: Transparent and Flexible Intra-Device Parallelism via Programmable Operator Scheduling for production ready llm pre-training.arXiv preprint arXiv:2410.06511,
-
[8]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
YaRN: Efficient Context Window Extension of Large Language Models
Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Horovod: fast and easy distributed deep learning in TensorFlow
Sergeev, A. and Del Balso, M. Horovod: fast and easy distributed deep learning in tensorflow.arXiv preprint arXiv:1802.05799,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
URL https://hazyresearch.stanford.edu/ blog/2025-05-27-no-bubbles. Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
L., Li, B., Lei, B., Wang, B., Rong, B., Wang, C., Zhang, C., Gao, C., Zhang, C., Sun, C., et al
Team, M. L., Li, B., Lei, B., Wang, B., Rong, B., Wang, C., Zhang, C., Gao, C., Zhang, C., Sun, C., et al. Longcat- flash technical report.arXiv preprint arXiv:2509.01322,
-
[13]
Efficient Streaming Language Models with Attention Sinks
USENIX Association. Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zhang, S., Zheng, N., Lin, H., Jiang, Z., Bao, W., Jiang, C., Hou, Q., Cui, W., Zheng, S., Chang, L.-W., et al. Comet: Fine-grained computation-communication overlapping for mixture-of-experts.arXiv preprint arXiv:2502.19811,
-
[15]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Zhao, Y ., Gu, A., Varma, R., Luo, L., Huang, C.-C., Xu, M., Wright, L., Shojanazeri, H., Ott, M., Shleifer, S., et al. Pytorch fsdp: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Zheng, S., Bao, W., Hou, Q., Zheng, X., Fang, J., Huang, C., Li, T., Duanmu, H., Chen, R., Xu, R., Guo, Y ., Zheng, N., Jiang, Z., Di, X., Wang, D., Ye, J., Lin, H., Chang, L.-W., Lu, L., Liang, Y ., Zhai, J., and Liu, X. Triton- distributed: Programming overlapping kernels on dis- tributed ai systems with the triton compiler, 2025a. URL https://arxiv.org...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.