TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference
Pith reviewed 2026-05-22 14:18 UTC · model grok-4.3
The pith
TokenWeave enables efficient compute-communication overlap for tensor-parallel LLM inference at token lengths as small as 1024.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
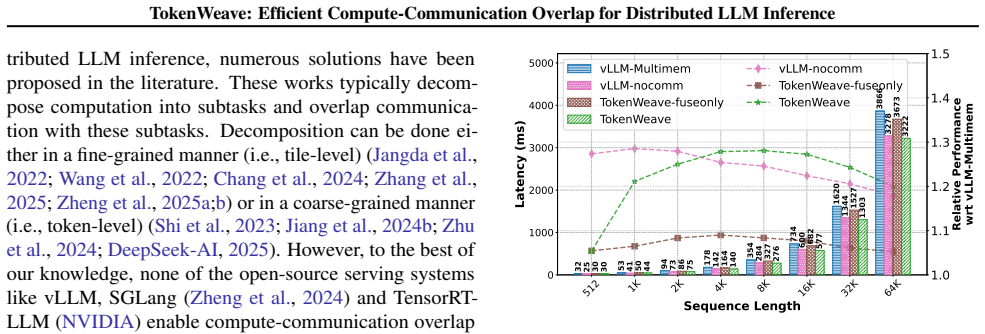
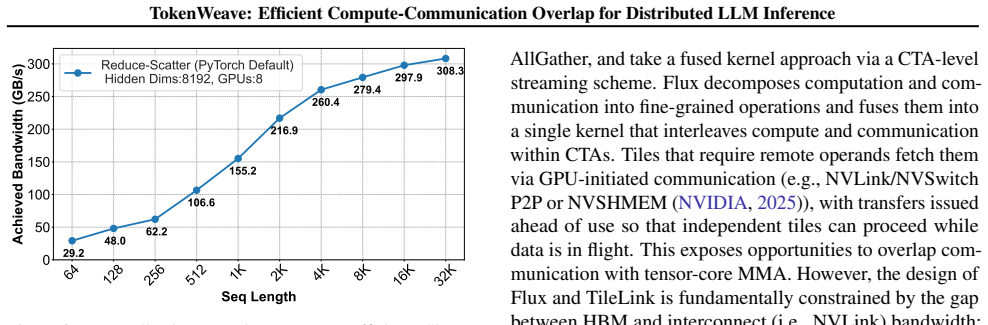
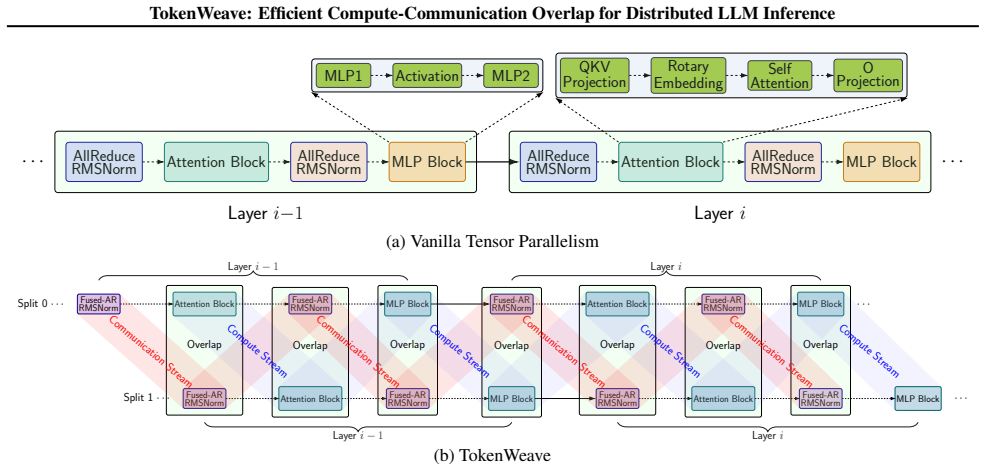
TokenWeave is the first system to enable efficient compute-communication overlap for tensor-parallel model inference for token lengths as small as 1024. It identifies RMSNorm as a key operation and optimizes it together with communication through a novel fused AllReduce-RMSNorm kernel. This kernel leverages the NVSHARP/Multimem feature on Hopper and Blackwell GPUs to perform both tasks jointly using only 2-8 streaming multiprocessors on an 8xH100 DGX system, delivering up to 1.28x latency speedup and up to 1.19x higher throughput across models and workloads.
What carries the argument
The fused AllReduce-RMSNorm kernel that uses NVSHARP/Multimem to jointly execute communication and RMSNorm while allocating only 2-8 streaming multiprocessors.
If this is right
- Tensor-parallel serving can keep low token counts per iteration while cutting communication overheads that reach 20 percent on NVLink.
- Latency drops and throughput rises across multiple models without changing the overall serving setup.
- In some cases the system outperforms an equivalent model that has all communication removed entirely.
Where Pith is reading between the lines
- The fusion idea could be tested on other normalization or activation steps to reduce overhead in additional layers.
- Systems running on older GPUs might need alternative low-SM methods to reach similar overlap for small token lengths.
Load-bearing premise
The performance gains require NVSHARP or Multimem hardware support on Hopper or Blackwell GPUs and assume that dedicating only a few SMs to the fused kernel leaves enough resources for the rest of the model.
What would settle it
Running the same workloads on GPUs without NVSHARP/Multimem support and checking whether the reported latency and throughput improvements over baseline still appear.
Figures























read the original abstract
Distributed inference of large language models (LLMs) using tensor parallelism can introduce communication overheads of $20$% even over GPUs connected via NVLink, a high-speed GPU interconnect. Several techniques have been proposed to mitigate these overheads by decomposing computations into smaller tasks and overlapping communication with these subtasks. However, none of these techniques are turned on by default during tensor-parallel serving in systems like vLLM, SGLang and TensorRT-LLM. This is because the number of tokens processed per iteration is typically kept small to support low-latency serving, and decomposing such smaller workloads to enable communication overlap results in worse performance. Further, the communication itself uses many streaming multiprocessors (SMs) that would otherwise be available for computation, increasing overhead. We present TokenWeave, the first system to enable efficient compute-communication overlap for tensor-parallel model inference for token lengths as small as 1024. TokenWeave identifies RMSNorm, a previously overlooked operation, as crucial and optimizes it along with communication by implementing a novel fused AllReduce--RMSNorm kernel. Further, this kernel leverages the NVSHARP/Multimem feature available on modern GPUs (e.g., Hopper, Blackwell) to jointly perform communication and RMSNorm efficiently using only $2-8$ streaming multiprocessors (SMs) on an $8\times$H100 DGX system. Our evaluations demonstrate up to $\boldsymbol{1.28\times}$ speedup in latency (baseline$\div$ours) and up to $\boldsymbol{1.19\times}$ higher throughput (ours$\div$baseline) across multiple models and workloads. In several settings, TokenWeave delivers better performance than an equivalent model with all communication removed. The source code is available at https://github.com/microsoft/tokenweave.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TokenWeave, a system for tensor-parallel distributed LLM inference that fuses AllReduce with RMSNorm into a single kernel. It leverages NVSHARP/Multimem hardware features on Hopper/Blackwell GPUs to perform this fusion using only 2-8 SMs, enabling effective compute-communication overlap even at small token lengths (down to 1024). Evaluations across multiple models report up to 1.28× latency speedup and 1.19× throughput improvement over baselines in vLLM, SGLang, and TensorRT-LLM, with some cases outperforming a no-communication model.
Significance. If the empirical results hold under scrutiny, this addresses a real deployment pain point: prior overlap techniques degrade performance at the small per-iteration token counts typical of low-latency serving. The work demonstrates practical use of modern GPU interconnect features (Multimem) for kernel fusion and could influence default configurations in production inference engines. The open-source release strengthens reproducibility.
major comments (2)
- [Evaluation] Evaluation section: The central performance claims (1.28× latency, 1.19× throughput at 1024 tokens) are presented without error bars, exact workload parameters (batch sizes, sequence lengths per iteration, model configurations), or baseline hyperparameter settings. This makes it impossible to assess statistical significance or reproduce the results that underpin the claim of succeeding where prior methods fail.
- [Section 3] Section 3 (fused kernel description): The key assumption that reserving only 2-8 SMs for the AllReduce-RMSNorm kernel leaves the remaining SMs sufficient for matmuls and other layers without occupancy or launch penalties is load-bearing for the small-token-length claims, yet no SM utilization traces, occupancy counters, or sensitivity sweeps over SM allocation are reported. Without these, it is unclear whether the reported gains could reverse under the exact conditions where prior overlap methods hurt performance.
minor comments (2)
- The abstract states results 'across multiple models and workloads' but the evaluation section would benefit from an explicit table mapping each reported speedup to the precise model, tensor-parallel degree, and token count.
- Notation for the fused kernel launch configuration (e.g., how the 2-8 SMs are selected and how the remaining SMs are partitioned) should be clarified with a small diagram or pseudocode for readers unfamiliar with Multimem.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each major comment point by point below and will revise the paper accordingly to improve reproducibility and strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central performance claims (1.28× latency, 1.19× throughput at 1024 tokens) are presented without error bars, exact workload parameters (batch sizes, sequence lengths per iteration, model configurations), or baseline hyperparameter settings. This makes it impossible to assess statistical significance or reproduce the results that underpin the claim of succeeding where prior methods fail.
Authors: We agree that the current evaluation section would benefit from greater detail to support reproducibility and allow readers to assess statistical significance. In the revised manuscript, we will add error bars from multiple independent runs, provide exact workload parameters including batch sizes and per-iteration sequence lengths, specify model configurations (e.g., layer counts and hidden dimensions), and document the precise hyperparameter settings used for the vLLM, SGLang, and TensorRT-LLM baselines. These additions will directly address the concerns and enable full reproduction of the reported speedups. revision: yes
-
Referee: [Section 3] Section 3 (fused kernel description): The key assumption that reserving only 2-8 SMs for the AllReduce-RMSNorm kernel leaves the remaining SMs sufficient for matmuls and other layers without occupancy or launch penalties is load-bearing for the small-token-length claims, yet no SM utilization traces, occupancy counters, or sensitivity sweeps over SM allocation are reported. Without these, it is unclear whether the reported gains could reverse under the exact conditions where prior overlap methods hurt performance.
Authors: The allocation of only 2-8 SMs to the fused kernel is intentional, as AllReduce and RMSNorm exhibit low arithmetic intensity at small token counts and can be efficiently executed without starving the compute-bound matmul layers. We recognize that empirical validation would strengthen this claim. In the revision, we will add a sensitivity analysis over SM allocations in Section 3 along with occupancy metrics obtained from profiling to demonstrate that the chosen allocation incurs no measurable launch or occupancy penalties under the evaluated conditions. revision: yes
Circularity Check
No circularity: empirical systems paper with measured results
full rationale
The paper is a systems/engineering contribution whose central claims rest on runtime measurements of a fused AllReduce-RMSNorm kernel on Hopper GPUs using NVSHARP/Multimem. No mathematical derivation chain, first-principles equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or described content. Performance numbers (1.28× latency, 1.19× throughput) are reported from direct benchmarking rather than any reduction to inputs by construction. The work is therefore self-contained against external hardware benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern GPUs (Hopper, Blackwell) expose NVSHARP/Multimem features that allow joint communication and RMSNorm with only 2-8 SMs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TokenWeave ... fused AllReduce–RMSNorm kernel ... using only 2–8 streaming multiprocessors (SMs) on an 8×H100 DGX system ... wave-aware, two-way token split
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
up to 1.28× speedup ... for token lengths as small as 1024
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
Analyzing Reverse Address Translation Overheads in Multi-GPU Scale-Up Pods
Simulation study shows cold TLB misses in reverse address translation dominate latency for small collectives in multi-GPU pods, causing up to 1.4x degradation, while larger ones see diminishing returns.
-
DITRON: Distributed Multi-level Tiling Compiler for Parallel Tensor Programs
DITRON introduces a hierarchical multi-level tiling compiler for distributed tensor programs that matches or exceeds expert CUDA libraries with 6-30% speedups and has been deployed to improve training MFU by over 10% ...
-
Rethinking Network Topologies for Cost-Effective Mixture-of-Experts LLM Serving
Switchless topologies such as 3D full-mesh are 20.6-56.2% more cost-effective than scale-up networks for MoE LLM serving, with current link bandwidths over-provisioned by up to 27%.
-
DynaFlow: Transparent and Flexible Intra-Device Parallelism via Programmable Operator Scheduling
DynaFlow enables transparent intra-device parallelism in ML systems by separating model definition from execution scheduling, integrating into 6 frameworks with up to 1.29x throughput gains and minimal code changes.
-
Lit Silicon: A Case Where Thermal Imbalance Couples Concurrent Execution in Multiple GPUs
Thermal imbalance in multi-GPU nodes creates hotter straggler GPUs that slow down cooler leader GPUs during overlapped computation and communication in LLM training.
-
Network Edge Inference for Large Language Models: Principles, Techniques, and Opportunities
A survey synthesizing challenges, system architectures, model optimizations, deployment methods, and resource management techniques for large language model inference at the network edge.
Reference graph
Works this paper leans on
-
[1]
S., Bui, T., Kim, S., Chang, W., and Goharian, N
Cohan, A., Dernoncourt, F., Kim, D. S., Bui, T., Kim, S., Chang, W., and Goharian, N. A discourse-aware attention model for abstractive summarization of long documents. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, Volume 2 (Short Papers), pp. 615–621, Ne...
work page 2018
-
[2]
Association for Computa- tional Linguistics. doi: 10.18653/v1/N18-2097. URL https://aclanthology.org/N18-2097. DeepSeek-AI. Profiling data in deepseek infra,
-
[3]
URL https://github.com/deepseek-ai/profile-data?tab= readme-ov-file#inference. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Association for Computing Machinery. ISBN 9781450392051. doi: 10.1145/3503222.3507778. URL https://doi.org/10.1145/3503222.3507778. Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024a. Jiang, C., Tian, Y ...
-
[5]
Scaling Laws for Neural Language Models
URL https://arxiv.org/abs/ 2001.08361. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, pp. 611–626,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
URL https://doi. org/10.48550/arXiv.2303.08774. Patel, P., Choukse, E., Zhang, C., Shah, A., Goiri,´I., Maleki, S., and Bianchini, R. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architec- ture (ISCA), pp. 118–132. IEEE,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[7]
TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference SGLang Team
URL https://github.com/pytorch/pytorch/blob/v2.6.0/torch/ csrc/distributed/c10d/CUDASymmetricMemoryOps.cu. TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference SGLang Team. Deploying DeepSeek with PD Disaggre- gation and Large-Scale Expert Parallelism on 96 H100 GPUs. https://lmsys.org/blog/2025-05-05-large-scale- ep/,
work page 2025
-
[8]
Shi, S., Pan, X., Chu, X., and Li, B
Dataset. Shi, S., Pan, X., Chu, X., and Li, B. Pipemoe: Accelerat- ing mixture-of-experts through adaptive pipelining. In IEEE INFOCOM 2023-IEEE Conference on Computer Communications, pp. 1–10. IEEE,
work page 2023
-
[9]
vLLM Team. Optimization and tuning. https://docs.vllm.ai/ en/v0.8.5/performance/optimization.html, 2025a. vLLM Team. vllm v1, 2025b. URL https://blog.vllm.ai/ 2025/01/27/v1-alpha-release.html. Wang, S., Wei, J., Sabne, A., Davis, A., Ilbeyi, B., Hecht- man, B., Chen, D., Murthy, K. S., Maggioni, M., Zhang, Q., Kumar, S., Guo, T., Xu, Y ., and Zhou, Z. Ove...
work page 2025
-
[10]
Association for Computing Machinery. ISBN 9781450399159. doi: 10.1145/3567955.3567959. URL https://doi.org/10.1145/3567955.3567959. Wang, Y ., He, H., Wright, L., Wehrstedt, L., Liu, T., and Liang, W. Distributed w/ torchtitan: Intro- ducing async tensor parallelism in pytorch,
-
[11]
URL https://dev- discuss.pytorch.org/t/pytorch-symmetricmemory- harnessing-nvlink-programmability-with-ease/2798/1. Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Curran Associates Inc. ISBN 9798331314385. Zheng, S., Bao, W., Hou, Q., Zheng, X., Fang, J., Huang, C., Li, T., Duanmu, H., Chen, R., Xu, R., Guo, Y ., Zheng, N., Jiang, Z., Di, X., Wang, D., Ye, J., Lin, H., Chang, L.-W., Lu, L., Liang, Y ., Zhai, J., and Liu, X. Triton- distributed: Programming overlapping kernels on dis- tributed ai systems with the tr...
-
[13]
B EVALUATION We provide some additional evaluations of TokenWeave in this section
and the RMSNorm kernel from vLLM (vLLM Contributors, 2023). B EVALUATION We provide some additional evaluations of TokenWeave in this section. B.1 Throughput Gains Figure 20 presents TokenWeave’s throughput gains on 4×H100 GPUs for various end-to-end workload traces. Sim- ilar to the 8-GPU results discussed in the main paper, To- kenWeave consistently imp...
work page 2023
-
[14]
As 1K 2K 4K 8K 16K 32K 64K Sequence Length 0 1000 2000 3000Latency (ms) 1.05x 1.05x 1.06x 1.11x 1.15x 1.15x 1.12x Qwen3-235B-A22B (8x H100) vLLM-Multimem vLLM-nocomm T okenWeave Figure
work page 2000
-
[15]
TokenWeave throughput gains for end-to-end workload traces.Shown are throughput measurements across fixed (input, output)-length traces, as well as ShareGPT and arXiv traces, for two models on4×H100. 512 1K 2K 4K 8K 16K 32K 64K 0 2000 4000 6000 8000Time (ms) 1.04x 1.14x 1.11x 1.13x 1.16x 1.14x 1.12x 1.11x Llama-3.3-70B-Instruct (4x H100) 512 1K 2K 4K 8K 1...
work page 2000
-
[16]
TokenWeave latency gains.Shown are the execution times for prefill requests with varying sequence lengths for different models on4×H100. 1 2 4 8 16 32 64 0 250 500 750 1000 1250 1500Time (ms) 1.05x 1.21x 1.19x 1.23x 1.26x 1.29x 1.31x Llama-3.3-70B-Instruct (8x H100) 1 2 4 8 16 32 64 0 250 500 750 1000 1250 1500 1.06x 1.15x 1.13x 1.22x 1.23x 1.25x 1.26x Qw...
work page 2000
-
[17]
TokenWeave latency gains.Shown are the execution times for prefill requests with varying batch sizes and sequence length of 512 for different models on (a) 8×H100 and (b) 4×H100. In almost all cases, TokenWeave is close to or better than the theoretical vLLM-nocommbaseline with zero communication overhead, showing that TokenWeave not only recovers all com...
work page 2000
-
[18]
TokenWeave Fused AllReduce–RMSNorm kernel ablation.We compareTokenWeave-fuseonlyand full TokenWeave against thevLLM-Multimembaseline. Execution times are shown for prefill requests with varying sequence lengths for different models on 4×H100.TokenWeave-fuseonlyprovides gains due to the elimination of redundancy in RMSNorm computation and intermediate memo...
work page 2000
-
[19]
Results are shown for sequence lengths from 32 to 64K tokens (hidden size 8192, bf16)
Latency of the fused AllReduce–RMSNorm kernel versus SM count on an 8×B200 DGX system. Results are shown for sequence lengths from 32 to 64K tokens (hidden size 8192, bf16). Similar to the 8×H100 results, latency reductions diminish beyond roughly8–16SMs. C.2 Decode-Only Batches In the V1 architecture, vLLM usestorch.compile to re- duce Python execution o...
work page 2025
-
[20]
TokenWeave Prefill latency gains on an8×B200DGX system for Llama-3.3-70B (varying sequence lengths).TokenWeave- fuseonlyachieves1.05×–1.07×speedup, while full TokenWeave achieves up to1.22×overvLLM-Multimem. D ARTIFACT D.1 Abstract Distributed inference of LLMs can incur overheads of up to 20%, even when GPUs are connected via high-speed interconnects suc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.