GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
Pith reviewed 2026-05-22 09:26 UTC · model grok-4.3
The pith
GenEvolve lets image generation agents self-evolve by turning comparisons of tool-orchestrated trajectories into dense token-level supervision for a student model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
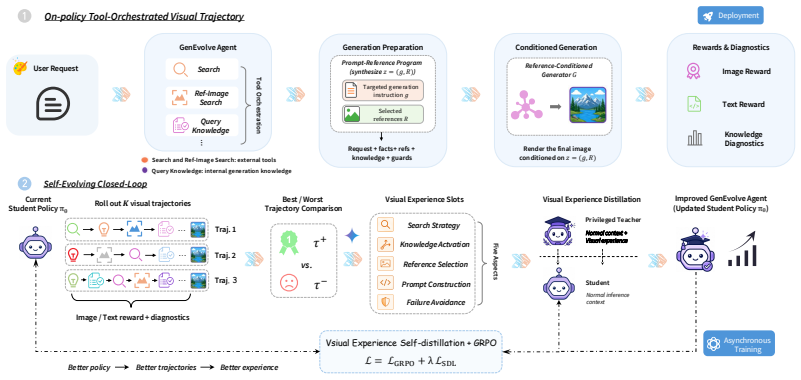
The central claim is that differences between best and worst tool-orchestrated trajectories for a given request can be abstracted into structured visual experience; when this experience is provided only to a privileged teacher branch, on-policy self-distillation supplies effective dense token-level supervision that enables the student agent to internalize improved search, reference selection, and prompt construction, yielding state-of-the-art results among current image-generation frameworks.
What carries the argument
Tool-Orchestrated Visual Experience Distillation, which extracts best-worst differences from trajectories of evidence gathering, reference selection, skill invocation, and prompt composition, then routes the resulting structured experience exclusively through a teacher branch for dense supervision of the student.
Load-bearing premise
That differences between best and worst tool-orchestrated trajectories for the same request can be abstracted into structured visual experience that, when supplied only to a privileged teacher branch, produces effective dense token-level supervision for the student agent.
What would settle it
A controlled run in which the student agent receives no measurable improvement in generation metrics after repeated rounds of distillation on identical requests, or in which performance gains vanish when the visual experience is withheld from the teacher branch.
Figures


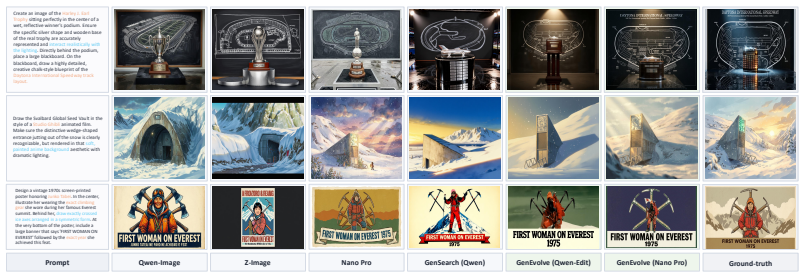












read the original abstract
Open-ended image generation is no longer a simple prompt-to-image problem. High-quality generation often requires an agent to combine a model's internal generative ability with external resources. As requests become more diverse and demanding, we aim to develop a general image-generation agent that can self-evolve through trajectories and use tools more effectively across varied generation challenges. To this end, we propose GenEvolve, a self-evolving framework based on Tool-Orchestrated Visual Experience Distillation. In GenEvolve, each generation attempt is modeled as a tool-orchestrated trajectory, where the agent gathers evidence, selects references, invokes generation skills, and composes them into a prompt-reference program. Unlike existing agentic generation methods that mainly rely on image-level scalar rewards, GenEvolve compares multiple trajectories for the same request and abstracts best-worst differences into structured visual experience, provided only to a privileged teacher branch. Inspired by on-policy self-distillation, Visual Experience Distillation provides dense token-level supervision, helping the student internalize better search, knowledge activation, reference selection, and prompt construction. We further construct GenEvolve-Data and GenEvolve-Bench. Experiments on public benchmarks and GenEvolve-Bench show substantial gains over strong baselines, achieving state-of-the-art performance among current image-generation frameworks. Our website is as follows: https://ephemeral182.github.io/GenEvolve/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GenEvolve, a self-evolving framework for open-ended image generation agents. Generation attempts are modeled as tool-orchestrated trajectories involving evidence gathering, reference selection, skill invocation, and prompt composition. Multiple trajectories per request are compared; best-worst differences are abstracted into structured visual experience supplied only to a privileged teacher branch. This enables on-policy self-distillation that supplies dense token-level supervision to a student agent, improving search, reference selection, and prompt construction. The authors introduce GenEvolve-Data and GenEvolve-Bench and report substantial gains over baselines with state-of-the-art results on public benchmarks and the new benchmark.
Significance. If the Visual Experience Distillation mechanism successfully converts trajectory comparisons into effective dense supervision signals, the work could advance agentic image generation by moving beyond scalar rewards toward self-improving agents. The construction of GenEvolve-Data and GenEvolve-Bench is a concrete positive contribution that may support future research in this area.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of substantial gains and state-of-the-art performance on public benchmarks plus GenEvolve-Bench is asserted without any quantitative numbers, ablation tables, error bars, or dataset statistics visible in the abstract and insufficiently detailed in the results to allow verification that the reported improvements are attributable to the proposed distillation rather than other factors.
- [§3] §3 (Visual Experience Distillation): The load-bearing step—that best/worst trajectory differences can be abstracted into structured visual experience yielding genuinely dense, on-policy token-level targets rather than coarse signals—is not supported by ablations isolating this component or independent verification of abstraction quality. Without such evidence the self-distillation loop provides no demonstrated advantage over standard RL or prompting baselines.
minor comments (2)
- [Abstract] The abstract mentions a website but does not describe its contents or reproducibility artifacts (code, prompts, or trajectory examples).
- [§3] Notation for trajectories, teacher/student branches, and the abstraction operator should be introduced with explicit definitions early in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below and revised the manuscript accordingly to improve clarity, transparency, and evidentiary support for our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of substantial gains and state-of-the-art performance on public benchmarks plus GenEvolve-Bench is asserted without any quantitative numbers, ablation tables, error bars, or dataset statistics visible in the abstract and insufficiently detailed in the results to allow verification that the reported improvements are attributable to the proposed distillation rather than other factors.
Authors: We agree that the abstract and experimental section would benefit from explicit quantitative results and additional details to facilitate verification. In the revised manuscript, we have updated the abstract to report specific metrics, including relative improvements (e.g., +X% on public benchmarks and +Y% on GenEvolve-Bench) over the strongest baselines. Section 4 has been expanded with full ablation tables, error bars from multiple random seeds, and statistics on GenEvolve-Data (e.g., trajectory counts, success rates) and GenEvolve-Bench. Controlled comparisons isolating the distillation component versus other factors (e.g., tool use alone) are now included to attribute gains specifically to Visual Experience Distillation. revision: yes
-
Referee: [§3] §3 (Visual Experience Distillation): The load-bearing step—that best/worst trajectory differences can be abstracted into structured visual experience yielding genuinely dense, on-policy token-level targets rather than coarse signals—is not supported by ablations isolating this component or independent verification of abstraction quality. Without such evidence the self-distillation loop provides no demonstrated advantage over standard RL or prompting baselines.
Authors: We acknowledge the need for targeted evidence isolating the abstraction of best/worst differences into structured visual experience. Our original experiments demonstrate overall gains over RL and prompting baselines, but we agree that component-specific ablations strengthen the case. The revised manuscript adds new ablation studies in §4 that directly compare the full Visual Experience Distillation against variants without the structured abstraction step (retaining only scalar rewards or standard prompting). We also include qualitative examples of the abstracted visual experiences and quantitative metrics on token-level supervision density to verify the quality and on-policy nature of the signals. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper describes an agentic framework that compares trajectories, abstracts differences into visual experience for a teacher branch, and applies on-policy self-distillation to produce token-level supervision for the student. No equations, formal derivations, or parameter-fitting steps are referenced in the provided text. Performance claims rest on benchmark experiments rather than any quantity that reduces by construction to its own inputs. Self-citations, if present in the full manuscript, are not load-bearing for a mathematical claim here. The central mechanism is a procedural description whose validity is tested externally via ablation and SOTA comparisons, not defined into existence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[3]
Black Forest Labs. FLUX.1 [schnell]. Hugging Face model card, 2024. URL https:// huggingface.co/black-forest-labs/FLUX.1-schnell. Accessed: 2026-05-20
work page 2024
-
[4]
Black Forest Labs. FLUX.2 [klein]. https://huggingface.co/black-forest-labs/ FLUX.2-klein-4B, 2026. FLUX.2 [klein] model family; compact image generation and editing models. Accessed: 2026-05-07
work page 2026
-
[5]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
HunyuanImage 3.0 Technical Report
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
SiXiang Chen, Jianyu Lai, Jialin Gao, Tian Ye, Haoyu Chen, Hengyu Shi, Shitong Shao, Yunlong Lin, Song Fei, Zhaohu Xing, et al. Postercraft: Rethinking high-quality aesthetic poster generation in a unified framework.arXiv preprint arXiv:2506.10741, 2025
-
[10]
Sixiang Chen, Jianyu Lai, Jialin Gao, Hengyu Shi, Zhongying Liu, Tian Ye, Junfeng Luo, Xiaoming Wei, and Lei Zhu. Posteromni: Generalized artistic poster creation via task distillation and unified reward feedback.arXiv preprint arXiv:2602.12127, 2026
-
[11]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026
-
[13]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Muller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Kaituo Feng, Manyuan Zhang, Shuang Chen, Yunlong Lin, Kaixuan Fan, Yilei Jiang, Hongyu Li, Dian Zheng, Chenyang Wang, and Xiangyu Yue. Gen-searcher: Reinforcing agentic search for image generation.arXiv preprint arXiv:2603.28767, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Gemini api release notes: Gemini 3 pro preview
Google AI for Developers. Gemini api release notes: Gemini 3 pro preview. https:// ai.google.dev/gemini-api/docs/changelog, November 2025. Official release note for gemini-3-pro-preview. Accessed: 2026-05-07
work page 2025
-
[16]
Google DeepMind. Introducing nano banana pro. https://blog.google/technology/ai/ nano-banana-pro/, November 2025. Google DeepMind product release for the Nano Banana Pro image generation and editing model built on Gemini 3 Pro. Accessed: 2026-05-06. 12
work page 2025
-
[17]
Jun He, Junyan Ye, Zilong Huang, Dongzhi Jiang, Chenjue Zhang, Leqi Zhu, Renrui Zhang, Xiang Zhang, and Weijia Li. Mind-brush: Integrating agentic cognitive search and reasoning into image generation.arXiv preprint arXiv:2602.01756, 2026
-
[18]
Zefeng He, Siyuan Huang, Xiaoye Qu, Yafu Li, Tong Zhu, Yu Cheng, and Yang Yang. Gems: Agent-native multimodal generation with memory and skills.arXiv preprint arXiv:2603.28088, 2026
-
[19]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Kaixun Jiang, Yuzheng Wang, Junjie Zhou, Pandeng Li, Zhihang Liu, Chen-Wei Xie, Zhaoyu Chen, Yun Zheng, and Wenqiang Zhang. Genagent: Scaling text-to-image generation via agentic multimodal reasoning.arXiv preprint arXiv:2601.18543, 2026
-
[21]
V Kovalev, A Kuvshinov, A Buzovkin, D Pokidov, and D Timonin. Craft: Continuous rea- soning and agentic feedback tuning for multimodal text-to-image generation.arXiv preprint arXiv:2512.20362, 2025
-
[22]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
URLhttps://arxiv.org/abs/2510.16888
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Kezhao Liu, Jason Klein Liu, Mingtao Chen, and Yiming Liu. Rethinking kl regularization in rlhf: From value estimation to gradient optimization.arXiv preprint arXiv:2510.01555, 2025
-
[26]
LongCat-Image Technical Report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, Xunliang Cai, Yayong Guan, and Jie Hu. LongCat-Image Technical Report.arXiv preprint arXiv:2512.07584, 2025. URL https://arxiv.org/abs/2512.07584
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Introducing 4o Image Generation
OpenAI. Introducing 4o Image Generation. OpenAI blog, 2025. URL https://openai.com/ index/introducing-4o-image-generation/. Accessed: 2026-05-20
work page 2025
-
[29]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Jiakang Yuan, Xinyue Li, Dongyang Liu, Xiangyang Zhu, Manyuan Zhang, Will Beddow, Erwann Millon, Victor Perez, Wenhai Wang, Conghui He, Bo Zhang, Xiaohong Liu, Hongsheng Li, Yu Qiao, Chang Xu, and Peng Gao. Lumina-image 2.0: A unified and efficient image generative framework.arXiv preprint arX...
-
[31]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[33]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 13
work page 2022
-
[34]
John Schulman. Approximating kl divergence. http://joschu.net/blog/kl-approx. html, 2020. Blog post
work page 2020
-
[35]
Bytedance Seed. Seed2. 0 model card: Towards intelligence frontier for real-world complexity. Technical report, Technical report, Bytedance, 2025. URL https://lf3-static. bytednsdoc. com . . . , 2026
work page 2025
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Stability AI. Stable diffusion 3.5 large. https://huggingface.co/stabilityai/ stable-diffusion-3.5-large , 2024. Official model card for Stable Diffusion 3.5 Large. Accessed: 2026-05-07
work page 2024
-
[38]
On a few pitfalls in kl divergence gradient estimation for rl
Yunhao Tang and Rémi Munos. On a few pitfalls in kl divergence gradient estimation for rl. arXiv preprint arXiv:2506.09477, 2025
-
[39]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Tencent Hunyuan Team. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding.arXiv preprint arXiv:2405.08748, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Open multimodal retrieval-augmented factual image generation.arXiv preprint arXiv:2510.22521, 2025
Yang Tian, Fan Liu, Jingyuan Zhang, Wei Bi, Yupeng Hu, and Liqiang Nie. Open multimodal retrieval-augmented factual image generation.arXiv preprint arXiv:2510.22521, 2025
-
[42]
Xingchen Wan, Han Zhou, Ruoxi Sun, Hootan Nakhost, Ke Jiang, Rajarishi Sinha, and Sercan Ö Arık. Maestro: Self-improving text-to-image generation via agent orchestration.arXiv preprint arXiv:2509.10704, 2025
-
[43]
DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
Dianyi Wang, Ruihang Li, Feng Han, Chaofan Ma, Wei Song, Siyuan Wang, Yibin Wang, Yi Xin, Hongjian Liu, Zhixiong Zhang, Shengyuan Ding, Tianhang Wang, Zhenglin Cheng, Tao Lin, Cheng Jin, Kaicheng Yu, Jingjing Chen, Wenjie Wang, Zhongyu Wei, and Jiaqi Wang. DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing. arXi...
-
[44]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, et al. Skill-sd: Skill-conditioned self-distillation for multi-turn llm agents.arXiv preprint arXiv:2604.10674, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, and Zhongyuan Wang. Emu3: Next-token prediction is all you need.CoRR,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[46]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single trans- former to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Huichao Zhang, Liao Qu, Yiheng Liu, Hang Chen, Yangyang Song, Yongsheng Dong, Shikun Sun, Xian Li, Xu Wang, Yi Jiang, Hu Ye, Bo Chen, Yiming Gao, Peng Liu, Akide Liu, Zhipeng Yang, Qili Deng, Linjie Xing, Jiyang Liu, Zhao Wang, Yang Zhou, Mingcong Liu, Yi Zhang, Qian He, Xiwei Hu, Zhongqi Qi, Jie Shao, Zhiye Fu, Shuai Wang, Fangmin Chen, Xuezhi Chai, Zhih...
-
[52]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations), pages 400–410, 2024. 15 A GenEvolve-Data Construction A.1 Prompt Pool Recipes GenEvolve-Data ...
work page 2024
-
[54]
Aérotrain I80 | Official World Speed Record: 430.4 km/h (267 mph) | 1974
Skipped text_rendering — crammed all text into a single long string “Aérotrain I80 | Official World Speed Record: 430.4 km/h (267 mph) | 1974” instead of decomposing into separate lines with spatial anchors → text_rendering=fail
work page 1974
-
[55]
Used a second style reference image instead of skill guidance — relied on the model to mimic typography from a reference rather than applying explicit font/layout rules→aesthetic=fail,attribute=fail
-
[56]
Same correct facts as best, but without text_rendering guidance the poster is unreadable: spatial_layout=fail. Case 2 — Extracted Experience Slots (Delta S1 Search strategy:Execute parallel searches for both the historical event (speed/year) and the physical design (inverted T-track) to ground both text and visuals. S2 Knowledge activation:Call text_rende...
work page 1974
-
[57]
placed side by side at equal width
Missing spatial_layout — used vague “placed side by side at equal width” without frame-relative coordinates →buildings overlap or merge,spatial_layout=fail
-
[58]
Without precise spatial anchors, text signs float or attach to the wrong building →text_rendering =fail, attribute_binding=fail
-
[59]
midground left/right side of the frame, spaced 10 feet apart
Missing physical_material_consistency — sign materials (wood vs metal) not properly grounded → physical_material=partial. Best(R= 0.80): correct layout, both signs legible Worst(R= 0.40): merged buildings, text failure Figure 9:Case 3 generated images.The best trajectory called spatial_layout and used frame- relative coordinates (“midground left/right sid...
work page 2024
-
[60]
Search for missing world knowledge and visual references (grounding)
-
[61]
Apply prompt-writing skill guidance -- spatial layout, aesthetic drawing, text rendering, creative drawing, anatomy/body coherence, attribute binding, physical/material consistency, quantity counting -- to improve the quality and controllability of the final prompt (skill integration)
-
[62]
Produce a grounded AND skill-enhanced generation-ready prompt that combines both search evidence and skill refinement Output format (ULTRA-STRICT): You MUST output exactly one of the following formats per round: (1) <think> ... </think> <tool_call> ... </tool_call> OR (2) <think> ... </think> <answer> ... </answer> - You are FORBIDDEN to output more than ...
-
[63]
Evaluate each skill independently: does the prompt GENUINELY match the " Trigger when" condition? If yes, call it. If it matches the "Do NOT trigger " condition, skip it
-
[64]
When you receive skill guidance, your NEXT response MUST analyze how to apply it -- explicitly state which parts of the guidance you will use and how they improve the gen_prompt
-
[65]
Do not call a skill and then ignore its advice
When you call a skill, you MUST actually USE its guidance in your final gen_prompt. Do not call a skill and then ignore its advice
-
[66]
Multiple skills are encouraged when the prompt has multiple distinct challenges. Do not artificially limit yourself to one skill if more are genuinely needed. - "search" (text): confirm identities, event names, dates, locations, specs. Typically 1-2 calls are enough. - "image_search": find visual references for real entities. Typically 1-2 calls are enoug...
-
[67]
Output exactly{n}JSON objects in one JSON array
-
[68]
The user-facing “prompt” must be natural and mustNOTmention skill names or tool names
-
[69]
Each prompt must require image_search candidate visual evidence; requires_image_search must be true
-
[70]
For T1, most prompts should require text search to verify a concrete factual detail that affects the image
-
[71]
For T3, text search is optional, butimage_searchmust still be necessary
-
[72]
Prompts should be visually evaluable: a reward model should be able to tell if the final generated image succeeded or failed
-
[73]
Prefer mid-tail real entities/objects/places/events: searchable, but not trivial
-
[74]
Avoid unsafe/private-person content
-
[75]
In metadata, describe what must be verified; doNOTfill in the factual answer unless it is already explicitly present in the user-facing prompt
-
[76]
The prompt should naturally require the target skill bundle as a whole, but must not mention skill names. Do not make every item equally complex; vary how the bundle appears. For each object, use exactly this schema: { "prompt": "...", "requires_text_search": true/false, "requires_image_search": true, "factual_gap": "short explanation", "visual_anchor_nee...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.