From Patches to Trajectories: Privileged Process Supervision for Software-Engineering Agents
Pith reviewed 2026-05-22 05:09 UTC · model grok-4.3
The pith
P2T converts reference patches into short effective trajectories that raise software-engineering agent success rates while lowering inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Patches-to-Trajectories (P2T) distills a developer reference patch p* into a latent process graph G* of contextual facts and solution milestones, then scores blinded teacher continuations against this graph under a leakage-blocking groundedness check to retain only the shortest effective trajectory segments; training on 1.8k such curated instances from SWE-Gym raises Pass@1 by up to 10.8 points on SWE-bench Verified and reduces per-instance inference cost by approximately 15 percent relative to outcome-filtered baselines.
What carries the argument
latent process graph G* distilled from reference patch p* that supplies a grounded, leakage-blocking measure of per-step progress for scoring teacher continuations
If this is right
- Training data quality can be improved without increasing data volume or requiring the teacher model to succeed on every instance.
- Trajectory length and per-step effectiveness can be jointly optimized rather than relying solely on terminal outcome verification.
- Privileged information from reference patches can be used during data curation while still keeping the student blind to the patch at inference time.
- Consistent gains appear across both SWE-bench Verified and Lite when the same curation procedure is applied.
Where Pith is reading between the lines
- The same distillation step could be applied to other domains that already produce reference solutions, such as theorem proving or automated program repair outside SWE-bench.
- If the process graph construction can be made cheaper, the method might lower the compute barrier for creating high-quality agent training sets at larger scale.
Load-bearing premise
A reference patch can be distilled into a process graph that accurately measures real progress in blinded teacher attempts without introducing selection bias or needing the teacher to have already solved the task.
What would settle it
Run the identical training and evaluation protocol on SWE-bench Verified but replace the G*-based scoring with random or length-only selection of the same number of trajectory segments and observe whether the reported gains in Pass@1 and cost reduction disappear.
Figures






read the original abstract
Supervised fine-tuning (SFT) on long teacher trajectories is the dominant way to instill investigation and reasoning in open software-engineering (SWE) agents. Since every retained response becomes an imitation target, the student inherits the final outcome and intermediate flaws, including ungrounded leaps and redundant loops. High-quality training data must be effective(each step is grounded and narrows the agent's epistemic gap to the correct fix) and efficient(each step is information-bearing rather than redundant or looping). Existing recipes filter or relabel teacher rollouts using only a binary terminal verifier, which does not directly target these axes and provides no supervision on instances where the teacher fails. Most real issue includes a developer-authored reference patch, $p^\star$, revealing the file paths, runtime behaviors, and coding conventions presupposed by the correct fix, yet standard pipelines discard it. We propose Patches-to-Trajectories (P2T), which uses $p^\star$ as privileged information during curation and formulates trajectory construction as bi-objective optimization over per-step effectiveness and trajectory length. A reverse phase distills $p^\star$ into a latent process graph, $G^\star$, of contextual facts and solution milestones. A forward phase curates trajectories from blinded teacher continuations by scoring per-step progress against $G^\star$ under a leakage-blocking groundedness check and retaining the shortest effective segments. Using only 1.8k curated SWE-Gym instances, P2T improves effectiveness and efficiency over outcome-filtered SFT and its tool-error-masking variant. On SWE-bench Verified, it raises Pass@1 by up to 10.8 points while reducing per-instance inference cost by ~15%, with consistent gains on SWE-bench Lite. Size-matched ablations and qualitative analysis further isolate trajectory quality from data scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Patches-to-Trajectories (P2T), which treats developer-authored reference patches p* as privileged information during data curation for supervised fine-tuning of software-engineering agents. It distills p* into a latent process graph G* in a reverse phase, then uses a forward phase to score blinded teacher continuations against G* with a leakage-blocking groundedness check and bi-objective optimization over per-step effectiveness and trajectory length, retaining the shortest effective segments. Experiments on 1.8k SWE-Gym instances show Pass@1 gains of up to 10.8 points on SWE-bench Verified (and consistent gains on Lite) while cutting per-instance inference cost by ~15%, outperforming outcome-filtered SFT and tool-error-masking variants; size-matched ablations and qualitative analysis are used to attribute gains to trajectory quality rather than scale.
Significance. If the leakage-blocking property of the G*-based scoring holds without introducing solution-specific bias, the approach offers a concrete way to convert privileged patches into process-level supervision signals that improve both effectiveness and efficiency of training trajectories for SWE agents. The use of bi-objective optimization and explicit separation of reverse distillation from forward curation on blinded rollouts is a strength, as are the size-matched ablations that help isolate data quality from quantity.
major comments (2)
- [§3.2 and §4.1] §3.2 (forward phase) and §4.1 (groundedness check): the manuscript asserts that scoring against G* provides a leakage-blocking measure of per-step progress, yet provides no equations defining the effectiveness score, no ablation removing the groundedness filter, and no quantitative test (e.g., comparing retained trajectories against a version of G* with file paths or edit locations redacted) showing that the check actually prevents favoritism toward continuations that implicitly recover the privileged p* solution path. This is load-bearing for the central claim that gains are due to improved process supervision rather than selection bias.
- [§3.1] §3.1 (reverse phase): the construction of the latent process graph G* from p* is described at a high level (contextual facts and solution milestones) but lacks detail on how milestones are extracted, whether they encode runtime behaviors or file-specific information unique to p*, and how the shortest-effective-segment selection interacts with the bi-objective weighting. Without these specifics, it is difficult to verify that the retained trajectories are generally effective rather than tuned to the reference fix.
minor comments (2)
- [Table 2, Figure 3] Table 2 and Figure 3: error bars or statistical significance tests are not reported for the Pass@1 deltas; adding them would strengthen the quantitative claims.
- [§4.2] Notation: the bi-objective weighting parameter is listed as a free parameter in the abstract but its exact value and sensitivity analysis are not shown in the main results; a short appendix table would clarify reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for clarification and additional validation that will strengthen the manuscript. We respond to each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [§3.2 and §4.1] §3.2 (forward phase) and §4.1 (groundedness check): the manuscript asserts that scoring against G* provides a leakage-blocking measure of per-step progress, yet provides no equations defining the effectiveness score, no ablation removing the groundedness filter, and no quantitative test (e.g., comparing retained trajectories against a version of G* with file paths or edit locations redacted) showing that the check actually prevents favoritism toward continuations that implicitly recover the privileged p* solution path. This is load-bearing for the central claim that gains are due to improved process supervision rather than selection bias.
Authors: We agree that explicit equations and further empirical checks would better substantiate the leakage-blocking claim. In the revision we will add the formal definition of the effectiveness score (milestone coverage under the groundedness predicate that rejects direct references to p* elements) and include an ablation that removes the groundedness filter. We will also add a quantitative test on a held-out subset that compares selection behavior when file paths and edit locations are redacted from G*; preliminary internal checks suggest the filter continues to select non-reference paths, but we will report the full results. These changes directly address the load-bearing concern while preserving the separation between reverse distillation and forward curation on blinded rollouts. revision: yes
-
Referee: [§3.1] §3.1 (reverse phase): the construction of the latent process graph G* from p* is described at a high level (contextual facts and solution milestones) but lacks detail on how milestones are extracted, whether they encode runtime behaviors or file-specific information unique to p*, and how the shortest-effective-segment selection interacts with the bi-objective weighting. Without these specifics, it is difficult to verify that the retained trajectories are generally effective rather than tuned to the reference fix.
Authors: We accept that the reverse-phase description requires more operational detail for reproducibility. The revised §3.1 will specify that milestones are extracted by parsing unified diffs for changed files and functions together with passing test assertions from the issue metadata; they encode both file-specific edits and expected runtime outcomes without storing the full patch content. The bi-objective step retains the shortest prefix that reaches at least 80 % milestone coverage on the Pareto front of effectiveness versus length. We will add pseudocode and a worked example to illustrate the interaction and to show that the retained segments generalize beyond the reference p*. revision: yes
Circularity Check
No significant circularity; derivation uses independent privileged data for curation
full rationale
The paper's central derivation constructs G* from independent developer-authored reference patches p* (external to the teacher model), then applies a forward-phase scoring and bi-objective selection to curate trajectories for SFT. This process does not reduce any claimed prediction or result to its own inputs by construction: the effectiveness scores and length minimization operate on blinded continuations, and final Pass@1 gains are measured on separate SWE-bench benchmarks that do not supply p* at inference time. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described chain. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work to force the outcome.
Axiom & Free-Parameter Ledger
free parameters (1)
- bi-objective weighting between effectiveness and length
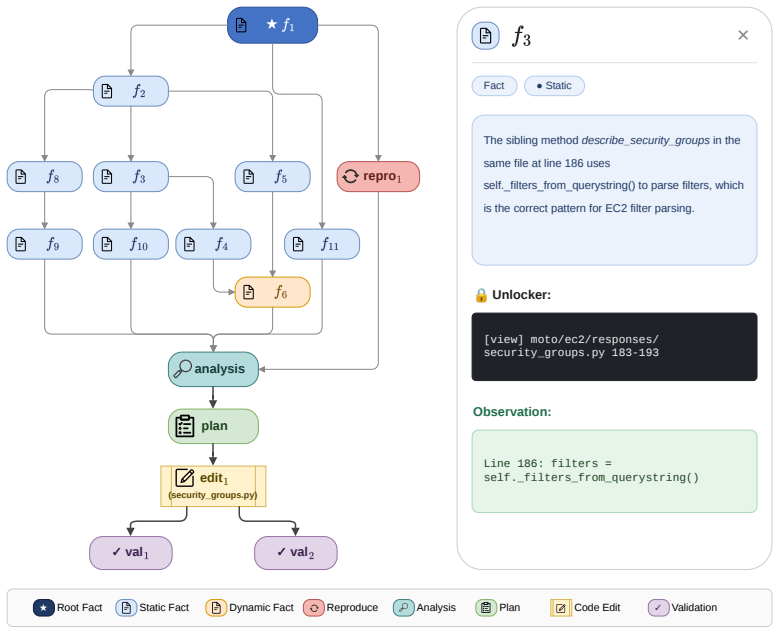
axioms (1)
- domain assumption Reference patches p* encode the file paths, runtime behaviors, and coding conventions presupposed by the correct fix without introducing selection bias when used for curation.
invented entities (1)
-
latent process graph G*
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose P2T... reverse phase distills p⋆ into a latent process graph G⋆ of contextual facts and solution milestones... forward phase curates trajectories... scoring per-step progress against G⋆ under a leakage-blocking groundedness check
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bi-objective program over per-step effectiveness and trajectory length... shortest-above-floor rule
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M., Nnorom, E., Uddin, G., and Wang, S
Aleithan, R., Xue, H., Mohajer, M. M., Nnorom, E., Uddin, G., and Wang, S. SWE-bench+: Enhanced coding benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
-
[2]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Deng, X., Da, J., Pan, E., He, Y . Y ., Ide, C., Garg, K., Lauffer, N., Park, A., Pasari, N., Rane, C., et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Jain, N., Singh, J., Shetty, M., Zheng, L., Sen, K., and Stoica, I. R2E-gym: Procedural environments and hybrid verifiers for scaling open-weights SWE agents.arXiv preprint arXiv:2504.07164, 2025
-
[5]
E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. R. Swe- bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations
-
[6]
A., Wutschitz, L., Chen, Y ., Sim, R., and Rajmohan, S
Kang, M., Chen, W.-N., Han, D., Inan, H. A., Wutschitz, L., Chen, Y ., Sim, R., and Rajmohan, S. ACON: Optimizing context compression for long-horizon LLM agents.arXiv preprint arXiv:2510.00615, 2025
-
[7]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[8]
Miettinen, K.Nonlinear Multiobjective Optimization, volume 12 ofInternational Series in Operations Research & Management Science. Springer, 1999
work page 1999
-
[9]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., and Lowe, R. Training language models to follow instructions with human feedback. InAdvances in Neural Information Process...
work page 2022
-
[10]
Training Software Engineering Agents and Verifiers with SWE-Gym
Pan, J., Wang, X., Neubig, G., Jaitly, N., Ji, H., Suhr, A., and Zhang, Y . Training software engineering agents and verifiers with swe-gym.arXiv preprint arXiv:2412.21139, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
YaRN: Efficient Context Window Extension of Large Language Models
Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Qi, Z., Long, F., Achour, S., and Rinard, M. C. An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. InProceedings of the 24th International Symposium on Software Testing and Analysis, pp. 24–36. ACM, 2015. doi: 10.1145/2771783. 2771791
-
[13]
A reduction of imitation learning and structured prediction to no-regret online learning
Ross, S., Gordon, G., and Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pp. 627–635. PMLR, 2011. 10
work page 2011
-
[14]
Smith, E. K., Barr, E. T., Le Goues, C., and Brun, Y . Is the cure worse than the disease? overfitting in automated program repair. InProceedings of the 10th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering, pp. 532–543. ACM, 2015. doi: 10.1145/2786805.2786825
-
[15]
Tao, C., Chen, J., Jiang, Y ., Kou, K., Wang, S., Wang, R., Li, X., Yang, S., Du, Y ., Dai, J., et al. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving.arXiv preprint arXiv:2601.01426, 2026
-
[16]
Vapnik, V . and Vashist, A. A new learning paradigm: Learning using privileged information. Neural Networks, 22(5–6):544–557, 2009. doi: 10.1016/j.neunet.2009.06.042
-
[18]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Wang, X., Li, B., Song, Y ., Xu, F. F., Tang, X., Zhuge, M., Pan, J., Song, Y ., Li, B., Singh, J., Tran, H. H., Li, F., Ma, R., Zheng, M., Qian, B., Shao, Y ., Muennighoff, N., Zhang, Y ., Hui, B., Lin, J., Brennan, R., Peng, H., Ji, H., and Neubig, G. OpenHands: An open platform for AI software developers as generalist agents.arXiv preprint arXiv:2407.1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Wang, Y ., Pradel, M., and Liu, Z. Are" solved issues" in swe-bench really solved correctly? an empirical study.arXiv preprint arXiv:2503.15223, 2025
-
[20]
Agentless: Demystifying LLM-based Software Engineering Agents
Xia, C. S., Deng, Y ., Dunn, S., and Zhang, L. Agentless: Demystifying LLM-based software engineering agents.arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Reducing cost of LLM agents with trajectory reduction
Xiao, Y .-A., Gao, P., Peng, C., and Xiong, Y . Reducing cost of LLM agents with trajectory reduction. InProceedings of the ACM International Conference on the Foundations of Software Engineering (FSE), 2026. doi: 10.1145/3797084. arXiv:2509.23586
-
[22]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, J., Jimenez, C. E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K. R., and Press, O. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems, 2024. URL https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
SWE-smith: Scaling Data for Software Engineering Agents
Yang, J., Lieret, K., Jimenez, C. E., Wettig, A., Khandpur, K., Zhang, Y ., Hui, B., Press, O., Schmidt, L., and Yang, D. SWE-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Zan, D., Huang, Z., Liu, W., Chen, H., Zhang, L., Xin, S., Chen, L., Liu, Q., Zhong, X., Li, A., et al. Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
GLM-5: from Vibe Coding to Agentic Engineering
Zeng, A., Lv, X., Hou, Z., Du, Z., Zheng, Q., Chen, B., Yin, D., Ge, C., Huang, C., Xie, C., et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Y ., Yan, R., Wei, T., He, J., Song, X., et al
Zeng, L., Li, Y ., Xiao, Y ., Li, C., Liu, C. Y ., Yan, R., Wei, T., He, J., Song, X., et al. Skywork-SWE: Unveiling data scaling laws for software engineering in LLMs.arXiv preprint arXiv:2506.19290, 2025
-
[29]
Swe-bench goes live!arXiv preprint arXiv:2505.23419, 2025
Zhang, L., He, S., Zhang, C., Kang, Y ., Li, B., Xie, C., Wang, J., Wang, M., Huang, Y ., Fu, S., et al. Swe-bench goes live!arXiv preprint arXiv:2505.23419, 2025
-
[30]
AutoCodeRover: Autonomous program improvement
Zhang, Y ., Ruan, H., Fan, Z., and Roychoudhury, A. AutoCodeRover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024
work page 2024
-
[31]
Zhao, Y ., Huang, J., Hu, J., Wang, X., Mao, Y ., Zhang, D., Jiang, Z., Wu, Z., Ai, B., Wang, A., Zhou, W., and Chen, Y . Swift:a scalable lightweight infrastructure for fine-tuning, 2024. URL https://arxiv.org/abs/2408.05517. 11 Appendix A Technical appendices and supplementary material 13 B Prerequisite-graph node distribution 13 C Value of information ...
-
[32]
A: Now let me check the model implementation
-
[33]
O: grep describe_security_group_rules →models:545
-
[34]
O: view models/security_groups.py 540-560→f8,f9
-
[35]
A: I see! filters=None passed to backend
-
[36]
O: re-view responses/security_groups.py 195-205
-
[37]
A: Look at examples of filter parsing
-
[38]
O: grep Filter (30K chars of noise)
-
[39]
A: Trace SecurityRule for skipped filtering
-
[40]
P2T trajectory (with curation)
O: view models/.../SecurityRule.__init__ →wrong path ↓ commits to BACKEND fix; next 100 steps add group_id to SecurityRule, edit response template, BREAK test_create_and_describe_security_grp_rule. P2T trajectory (with curation)
-
[41]
A: Examine responses/security_groups.py
-
[42]
O: view responses/security_groups.py 190-210→f2
-
[43]
A:Let me check the backend model implementation(blinded)
-
[44]
A: Check sibling describe_security_groups parses ←y ′ (curated)
-
[45]
O: grep→line 186 filters=_filters_from_querystring() →f3
-
[46]
A: _filters_from_querystring uses _get_multi_param
-
[47]
O: view _base_response.py 1-31→f4
-
[48]
A: Is this the standard EC2 pattern across responses?
-
[49]
O: grep -rn _filters_from_querystring responses/→f10
-
[50]
A: Plan: replace _get_param(’Filter’) with helper at line 197
-
[51]
Figure 7: Side-by-side fragment of the same window in πblind (left) and P2T (right)
O:(commits, replans from new prefix) ↓ one-line edit at responses/security_groups.py:197; both validations pass. Figure 7: Side-by-side fragment of the same window in πblind (left) and P2T (right). Rows labelled A are assistant responses; rows labelled O are environment observations. The single curator-authored step (red, y′ at j=2) replaces an empty assi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.