AgroVG: A Large-Scale Multi-Source Benchmark for Agricultural Visual Grounding
Pith reviewed 2026-05-22 06:51 UTC · model grok-4.3
The pith
A new multi-source benchmark for agricultural visual grounding shows current models achieve low accuracy on small repetitive and absent targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
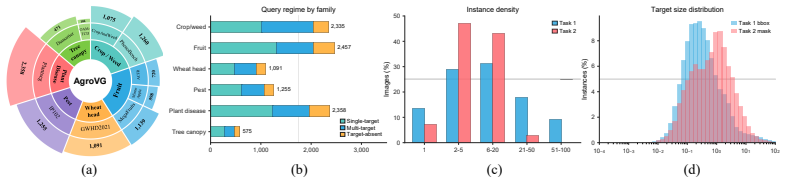
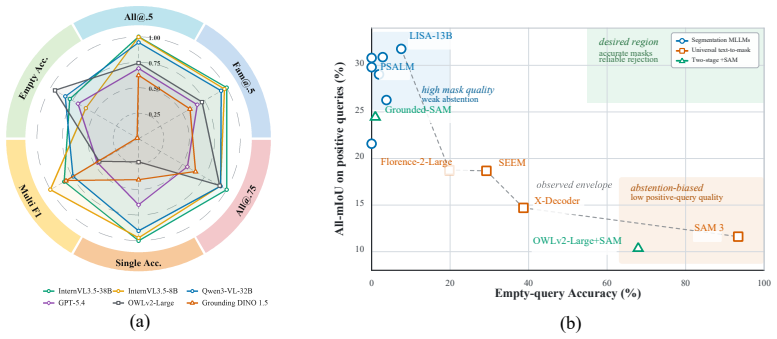
The paper claims that agricultural visual grounding can be reliably evaluated by recasting it as generalized set prediction over 10,071 image-query pairs drawn from ten source datasets spanning six target families, and that zero-shot tests of closed-source, open-source, and specialized models under this protocol expose clear shortfalls in multi-target Set-F1 scores and high-IoU mask success rates.
What carries the argument
AgroVG benchmark, a unified collection of bounding-box and instance-mask grounding tasks that supports set matching and query-level coverage checks for single, multiple, and absent agricultural targets.
If this is right
- Models must improve set-prediction mechanisms to handle completeness when multiple matching instances exist in one image.
- Systems need reliable abstention logic for queries that refer to no object at all.
- Task-specific protocols for box-set matching and mask coverage can serve as standard tests for future agricultural grounding work.
- Gaps across six target families indicate that robustness to irregular shapes and occlusion must be addressed beyond general vision-language training.
Where Pith is reading between the lines
- The benchmark could be used to fine-tune or select models before deploying them on real field robots for harvesting or spraying.
- Similar set-prediction framing might help evaluate grounding in other domains with repetitive small objects, such as cell microscopy.
- Extending the queries to include temporal or multi-view farm imagery would test whether current gaps persist under more realistic conditions.
Load-bearing premise
The combined annotations from the ten source datasets are accurate and representative enough to capture the real difficulties of small, repetitive, occluded, and irregular agricultural targets.
What would settle it
A controlled re-labeling of several hundred AgroVG queries by independent agricultural experts that produces substantially higher or lower model rankings than the original evaluation.
Figures



read the original abstract
Visual grounding, the task of localizing objects described by natural-language expressions, is a foundational capability for agricultural AI systems, enabling applications such as selective weeding, disease monitoring, and targeted harvesting. Reliable evaluation of agricultural visual grounding remains challenging because agricultural targets are often small, repetitive, occluded, or irregularly shaped, and instructions may refer to one, many, or no objects in an image. Evaluating this capability therefore requires jointly testing localization accuracy, target-set completeness, and existence-aware abstention. To address these challenges, we introduce \textbf{AgroVG}, a multi-source benchmark that formulates agricultural grounding as generalized set prediction: given an image and a referring expression, a model must return all matching target instances or abstain when no target is present. AgroVG contains 10{,}071 annotation-grounded image-query pairs from ten source datasets across six target families: crop/weed, fruit, wheat head, pest, plant disease, and tree canopy. It supports bounding-box grounding (T1) across all six families and instance-mask grounding (T2) on sources with reliable instance-level pixel annotations, with queries covering single-target, multi-target, and target-absent regimes. AgroVG further provides task-specific protocols for box-set matching and query-level mask coverage. Zero-shot evaluation of 26 model configurations spanning closed-source MLLMs, open-source VLMs, and specialized grounding systems reveals persistent gaps: the best multi-target Set-$F_1$ reaches only 0.35, and the best positive-query mask success rate at IoU@0.75 remains below 0.17. Data and code are available at https://anonymous.4open.science/r/AgroVG-5172/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgroVG, a multi-source benchmark for agricultural visual grounding formulated as generalized set prediction. It aggregates 10,071 image-query pairs from ten source datasets spanning six target families (crop/weed, fruit, wheat head, pest, plant disease, tree canopy), supporting bounding-box grounding (T1) on all families and instance-mask grounding (T2) where pixel annotations are available. Queries cover single-target, multi-target, and target-absent regimes. Zero-shot evaluation of 26 model configurations (closed-source MLLMs, open-source VLMs, and specialized grounding systems) reports persistent gaps, with the best multi-target Set-F1 reaching only 0.35 and the best positive-query mask success rate at IoU@0.75 remaining below 0.17. Data and code are released.
Significance. If the annotations are shown to be reliable, AgroVG would be a valuable contribution as the first large-scale benchmark specifically targeting agricultural visual grounding challenges such as small, repetitive, occluded, and irregularly shaped objects. The multi-source construction, support for set-based and mask-based protocols, and broad zero-shot evaluation across 26 models provide a reproducible testbed that highlights concrete limitations in current systems for applications like selective weeding and disease monitoring. The public release of data and code is a clear strength that supports future work.
major comments (1)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The manuscript provides no quantitative validation of annotation quality across the ten heterogeneous source datasets, such as inter-annotator agreement statistics, error rates for referring expressions, or audits for missed small/occluded instances and absent-target labels. This is load-bearing for the central claim because the reported gaps (best Set-F1 = 0.35; IoU@0.75 mask success < 0.17) can only be interpreted as model limitations if the 10,071 pairs faithfully reflect the stated agricultural challenges without systematic label noise.
minor comments (2)
- [Table 1] Table 1 or equivalent: Consider adding a column or footnote that explicitly lists the ten source datasets and their original annotation types (box vs. mask) to improve traceability of the multi-source aggregation.
- [§5 (Experiments)] §5 (Experiments): The description of the 26 model configurations would benefit from a clearer breakdown (e.g., how many are closed-source MLLMs vs. specialized grounding models) to allow readers to map results to model families without cross-referencing the appendix.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation for major revision. We address the single major comment below and will update the manuscript to incorporate additional validation details.
read point-by-point responses
-
Referee: The manuscript provides no quantitative validation of annotation quality across the ten heterogeneous source datasets, such as inter-annotator agreement statistics, error rates for referring expressions, or audits for missed small/occluded instances and absent-target labels. This is load-bearing for the central claim because the reported gaps (best Set-F1 = 0.35; IoU@0.75 mask success < 0.17) can only be interpreted as model limitations if the 10,071 pairs faithfully reflect the stated agricultural challenges without systematic label noise.
Authors: We thank the referee for highlighting this important point. The annotations in AgroVG are inherited directly from ten established, peer-reviewed source datasets that have been widely adopted in the agricultural vision community. While the current manuscript does not consolidate quantitative quality metrics across sources, we agree that providing such information would strengthen the benchmark's credibility. In the revised version we will add a dedicated paragraph in §3 summarizing the annotation protocols and any quality metrics (e.g., inter-annotator agreement or error rates) reported in the original dataset papers. We will also perform and report a targeted audit on a representative subset of approximately 500 image-query pairs, checking for missed small/occluded instances and the accuracy of target-absent labels. These additions will allow readers to better evaluate the reliability of the reported performance gaps. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
The paper constructs AgroVG by aggregating annotations from ten existing source datasets and performs zero-shot evaluation of 26 external model configurations. No derivations, equations, fitted parameters, or predictions are claimed; results consist of direct empirical measurements (Set-F1, IoU success rates) against model outputs. No self-citations are used to justify uniqueness theorems, ansatzes, or load-bearing premises. The work is therefore self-contained as a benchmark release and evaluation study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotations from the ten source datasets are accurate and suitable for the formulated visual grounding tasks including multi-target and absent cases.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AgroVG contains 10,071 annotation-grounded image-query pairs from ten source datasets across six target families... task-specific protocols for box-set matching and query-level mask coverage.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Zero-shot evaluation of 26 model configurations... best multi-target Set-F1 reaches only 0.35
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ReferItGame: Referring to Objects in Photographs of Natural Scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to Objects in Photographs of Natural Scenes. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 787–798. Association for Computational Linguistics, 2014. doi: 10.3115/v1/D14-1086. URL http://aclweb.org/a nthology/D14-1086
-
[2]
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan Yuille, and Kevin Murphy. Generation and Comprehension of Unambiguous Object Descriptions. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 11–20. IEEE, 2016. doi: 10.1109/CVPR.2016.9. URLhttp://ieeexplore.ieee.org/document/7780378/
-
[3]
Stavros G. V ougioukas. Agricultural Robotics.Annual Review of Control, Robotics, and Autonomous Systems, 2(1):365–392, 2019. doi: 10.1146/annurev-control-053018-023617. URL https://www.annualreviews.org/doi/10.1146/annurev-control-053018-0 23617
-
[4]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An Open-Source Vision-Language-Action Model. 2024
work page 2024
-
[5]
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg. Modeling Context in Referring Expressions. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision – ECCV 2016, volume 9906, pages 69–85. Springer International Publishing, 2016. doi: 10.1007/978-3-319-46475-6_5. URL http://link.springer.com/ 10.1007/9...
-
[6]
GREC: Generalized Referring Expression Comprehension, 2023
Shuting He, Henghui Ding, Chang Liu, and Xudong Jiang. GREC: Generalized Referring Expression Comprehension, 2023. URLhttp://arxiv.org/abs/2308.16182
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Chang Liu, Henghui Ding, and Xudong Jiang. GRES: Generalized Referring Expression Segmentation. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23592–23601. IEEE, 2023. doi: 10.1109/CVPR52729.2023.02259. URL https://ieeexplore.ieee.org/document/10204107/
-
[8]
Yang Zhan, Zhitong Xiong, and Yuan Yuan. RSVG: Exploring Data and Models for Visual Grounding on Remote Sensing Data.IEEE Transactions on Geoscience and Remote Sensing, 61:1–13, 2023. doi: 10.1109/TGRS.2023.3250471. URL https://ieeexplore.ieee.org/ document/10056343/
-
[9]
Zhenghang Yuan, Lichao Mou, Yuansheng Hua, and Xiao Xiang Zhu. RRSIS: Referring Remote Sensing Image Segmentation.IEEE Transactions on Geoscience and Remote Sensing, 62:1–12,
-
[10]
URL https://ieeexplore.ieee.org/docume nt/10458079/
doi: 10.1109/TGRS.2024.3369720. URL https://ieeexplore.ieee.org/docume nt/10458079/
-
[11]
VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding
Jian Ding, Mohamed Elhoseiny, and Xiang Li. VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding. InAdvances in Neural In- formation Processing Systems 37, pages 3229–3242. Neural Information Processing Sys- tems Foundation, Inc. (NeurIPS), 2024. doi: 10.52202/079017- 0106. URL http: //www.proceedings.com/079017-0106.html
-
[12]
AgriBench: A Hierarchical Agriculture Benchmark for Multimodal Large Language Models, 2024
Yutong Zhou and Masahiro Ryo. AgriBench: A Hierarchical Agriculture Benchmark for Multimodal Large Language Models, 2024. URLhttp://arxiv.org/abs/2412.00465
-
[13]
AgroBench: Vision-Language Model Benchmark in Agriculture, 2025
Risa Shinoda, Nakamasa Inoue, Hirokatsu Kataoka, Masaki Onishi, and Yoshitaka Ushiku. AgroBench: Vision-Language Model Benchmark in Agriculture, 2025. URL http://arxiv. org/abs/2507.20519
-
[14]
AGMMU: A Comprehensive Agricultural Multimodal Understanding Benchmark
Aruna Gauba, Irene Pi, Yunze Man, Ziqi Pang, Vikram S Adve, and Yu-Xiong Wang. AGMMU: A Comprehensive Agricultural Multimodal Understanding Benchmark. 2025. 10
work page 2025
-
[15]
Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind
Qingmei Li, Yang Zhang, Zurong Mai, Yuhang Chen, Shuohong Lou, Henglian Huang, Jiarui Zhang, Zhiwei Zhang, Yibin Wen, Weijia Li, Haohuan Fu, Jianxi Huang, and Juepeng Zheng. Can Large Multimodal Models Understand Agricultural Scenes? Benchmarking with AgroMind. 2025
work page 2025
-
[16]
Multi-label Instance- level Generalised Visual Grounding in Agriculture, 2026
Mohammadreza Haghighat, Alzayat Saleh, and Mostafa Rahimi Azghadi. Multi-label Instance- level Generalised Visual Grounding in Agriculture, 2026. URL http://arxiv.org/abs/26 03.06699
work page 2026
-
[17]
360mvsnet: Deep multi-view stereo network with 360° images for indoor scene reconstruction,
Daniel Steininger, Andreas Trondl, Gerardus Croonen, Julia Simon, and Verena Widhalm. The CropAndWeed Dataset: A Multi-Modal Learning Approach for Efficient Crop and Weed Manipulation. In2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3718–3727. IEEE, 2023. doi: 10.1109/WACV56688.2023.00372. URL https://ieeexplore.ieee.org...
-
[18]
Etienne David, Mario Serouart, Daniel Smith, Simon Madec, Kaaviya Velumani, Shouyang Liu, Xu Wang, Francisco Pinto, Shahameh Shafiee, Izzat S.A. Tahir, Hisashi Tsujimoto, Shuhei Nasuda, Bangyou Zheng, Norbert Kirchgessner, Helge Aasen, Andreas Hund, Pouria Sadhegi-Tehran, Koichi Nagasawa, Goro Ishikawa, Sébastien Dandrifosse, Alexis Carlier, Benjamin Dumo...
-
[19]
Nicolai Hani, Pravakar Roy, and V olkan Isler. MinneApple: A Benchmark Dataset for Apple Detection and Segmentation.IEEE Robotics and Automation Letters, 5(2):852–858, 2020. doi: 10.1109/LRA.2020.2965061. URL https://ieeexplore.ieee.org/document/8954630 /
-
[20]
IP102: A Large- Scale Benchmark Dataset for Insect Pest Recognition
Xiaoping Wu, Chi Zhan, Yu-Kun Lai, Ming-Ming Cheng, and Jufeng Yang. IP102: A Large- Scale Benchmark Dataset for Insect Pest Recognition. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8779–8788. IEEE, 2019. doi: 10.110 9/CVPR.2019.00899. URLhttps://ieeexplore.ieee.org/document/8954351/
-
[21]
A Large-Scale In-the-wild Dataset for Plant Disease Segmentation.Scientific Data, 13(1):205, 2026
Tianqi Wei, Zhi Chen, Xin Yu, Scott Chapman, Paul Melloy, and Zi Huang. A Large-Scale In-the-wild Dataset for Plant Disease Segmentation.Scientific Data, 13(1):205, 2026. doi: 10.1038/s41597-025-06513-4. URL https://www.nature.com/articles/s41597-025 -06513-4
-
[22]
Emogen: Emotional image content generation with text-to-image diffusion models,
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Jiayi Ji, Xiaoshuai Sun, and Rongrong Ji. Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26648–26658. IEEE, 2024. doi: 10.1109/CVPR52733.2024.02517. URL https://ieeexplo re.ieee.org...
-
[23]
Segmentation from Natural Language Expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from Natural Language Expressions. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision – ECCV 2016, volume 9905, pages 108–124. Springer International Publishing, 2016. doi: 10.1007/978-3-319-46448-0_7. URL http://link.springer.com/10.1007/978-3 -319-46448-0_7
-
[24]
Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. MAttNet: Modular Attention Network for Referring Expression Comprehension. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1307–1315. IEEE,
-
[25]
URL https://ieeexplore.ieee.org/document /8578240/
doi: 10.1109/CVPR.2018.00142. URL https://ieeexplore.ieee.org/document /8578240/
-
[26]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
Jiajun Deng, Zhengyuan Yang, Tianlang Chen, Wengang Zhou, and Houqiang Li. TransVG: End- to-End Visual Grounding with Transformers. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 1749–1759. IEEE, 2021. doi: 10.1109/ICCV48922.2021.00179. URLhttps://ieeexplore.ieee.org/document/9710016/. 11
-
[27]
Visual Grounding in Remote Sensing Images
Yuxi Sun, Shanshan Feng, Xutao Li, Yunming Ye, Jian Kang, and Xu Huang. Visual Grounding in Remote Sensing Images. InProceedings of the 30th ACM International Conference on Multimedia, pages 404–412. ACM, 2022. doi: 10.1145/3503161.3548316. URL https: //dl.acm.org/doi/10.1145/3503161.3548316
-
[28]
Meng Lan, Fu Rong, Hongzan Jiao, Zhi Gao, and Lefei Zhang. Language Query-Based Transformer With Multiscale Cross-Modal Alignment for Visual Grounding on Remote Sensing Images.IEEE Transactions on Geoscience and Remote Sensing, 62:1–13, 2024. doi: 10.1109/ TGRS.2024.3407598. URLhttps://ieeexplore.ieee.org/document/10542207/
-
[29]
Ke Li, Di Wang, Haojie Xu, Haodi Zhong, and Cong Wang. Language-Guided Progressive Attention for Visual Grounding in Remote Sensing Images.IEEE Transactions on Geoscience and Remote Sensing, 62:1–13, 2024. doi: 10.1109/TGRS.2024.3423663. URL https: //ieeexplore.ieee.org/document/10584552/
-
[30]
AerialVG: A Challenging Benchmark for Aerial Visual Grounding by Exploring Positional Relations
Junli Liu, Qizhi Chen, Zhigang Wang, Yiwen Tang, Yiting Zhang, Chi Yan, Dong Wang, Xuelong Li, and Bin Zhao. AerialVG: A Challenging Benchmark for Aerial Visual Grounding by Exploring Positional Relations. 2025
work page 2025
-
[31]
RefDrone: A Challenging Benchmark for Referring Expression Comprehension in Drone Scenes, 2025
Zhichao Sun, Yepeng Liu, Zhiling Su, Huachao Zhu, Yuliang Gu, Yuda Zou, Zelong Liu, Gui-Song Xia, Bo Du, and Yongchao Xu. RefDrone: A Challenging Benchmark for Referring Expression Comprehension in Drone Scenes, 2025. URL http://arxiv.org/abs/2502.0 0392
work page 2025
-
[32]
Cross-Modal Bidi- rectional Interaction Model for Referring Remote Sensing Image Segmentation, 2025
Zhe Dong, Yuzhe Sun, Tianzhu Liu, Wangmeng Zuo, and Yanfeng Gu. Cross-Modal Bidi- rectional Interaction Model for Referring Remote Sensing Image Segmentation, 2025. URL http://arxiv.org/abs/2410.08613
-
[33]
A Large- Scale Referring Remote Sensing Image Segmentation Dataset and Benchmark, 2025
Zhigang Yang, Huiguang Yao, Linmao Tian, Xuezhi Zhao, Qiang Li, and Qi Wang. A Large- Scale Referring Remote Sensing Image Segmentation Dataset and Benchmark, 2025. URL http://arxiv.org/abs/2506.03583
-
[34]
RIS- LAD: A Benchmark and Model for Referring Image Segmentation in Low-Altitude Drone Imagery
Kai Ye, YingShi Luan, Zhudi Chen, Guangyue Meng, Pingyang Dai, and Liujuan Cao. RIS- LAD: A Benchmark and Model for Referring Image Segmentation in Low-Altitude Drone Imagery. 2026
work page 2026
-
[35]
LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
Jerome Quenum, Wen-Han Hsieh, Tsung-Han Wu, Ritwik Gupta, Trevor Darrell, and David M Chan. LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery. 2025
work page 2025
-
[36]
SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model, 2025
Kaiyu Li, Zepeng Xin, Li Pang, Chao Pang, Yupeng Deng, Jing Yao, Guisong Xia, Deyu Meng, Zhi Wang, and Xiangyong Cao. SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model, 2025. URLhttp://arxiv.org/abs/2504.09644
-
[37]
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images, 2025
Zepeng Xin, Kaiyu Li, Luodi Chen, Wanchen Li, Yuchen Xiao, Hui Qiao, Weizhan Zhang, Deyu Meng, and Xiangyong Cao. SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images, 2025. URL http://arxiv.org/abs/2512.200 13
work page 2025
-
[38]
GRASP: Geospatial pixel Reasoning viA Structured Policy learning, 2025
Chengjie Jiang, Yunqi Zhou, Jiafeng Yan, Jing Li, Jiayang Li, Yue Zhou, Hongjie He, and Jonathan Li. GRASP: Geospatial pixel Reasoning viA Structured Policy learning, 2025. URL http://arxiv.org/abs/2508.17102
-
[39]
UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes
Shuo Ni, Di Wang, He Chen, Haonan Guo, Ning Zhang, and Jing Zhang. UniGeoSeg: Towards Unified Open-World Segmentation for Geospatial Scenes, 2026. URL http://arxiv.org/ abs/2511.23332
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatial Relation Matching
Meng Chu, Zhedong Zheng, Wei Ji, Tingyu Wang, and Tat-Seng Chua. Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatial Relation Matching. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors, Computer Vision – ECCV 2024, volume 15069, pages 213–231. Springer Nature Switzerland,
work page 2024
-
[41]
URL https://link.springer.com/10.100 7/978-3-031-73247-8_13
doi: 10.1007/978-3-031-73247-8_13. URL https://link.springer.com/10.100 7/978-3-031-73247-8_13. 12
-
[42]
GeoGround: A Unified Large Vision-Language Model for Remote Sensing Visual Grounding, 2025
Yue Zhou, Mengcheng Lan, Xiang Li, Litong Feng, Yiping Ke, Xue Jiang, Qingyun Li, Xue Yang, and Wayne Zhang. GeoGround: A Unified Large Vision-Language Model for Remote Sensing Visual Grounding, 2025. URLhttp://arxiv.org/abs/2411.11904
-
[43]
AgriGPT: A Large Language Model Ecosystem for Agriculture, 2025
Bo Yang, Yu Zhang, Lanfei Feng, Yunkui Chen, Jianyu Zhang, Xiao Xu, Nueraili Aierken, Yurui Li, Yuxuan Chen, Guijun Yang, Yong He, Runhe Huang, and Shijian Li. AgriGPT: A Large Language Model Ecosystem for Agriculture, 2025. URL http://arxiv.org/abs/25 08.08632
work page 2025
-
[44]
Bo Yang, Lanfei Feng, Yunkui Chen, Yu Zhang, Jianyu Zhang, Xiao Xu, Nueraili Aierken, and Shijian Li. AgriGPT-Omni: A Unified Speech-Vision-Text Framework for Multilingual Agricultural Intelligence, 2025. URLhttp://arxiv.org/abs/2512.10624
-
[45]
AgriGPT-VL: Agricultural Vision- Language Understanding Suite, 2025
Bo Yang, Yunkui Chen, Lanfei Feng, Yu Zhang, Xiao Xu, Jianyu Zhang, Nueraili Aierken, Runhe Huang, Hongjian Lin, Yibin Ying, and Shijian Li. AgriGPT-VL: Agricultural Vision- Language Understanding Suite, 2025. URLhttp://arxiv.org/abs/2510.04002
-
[46]
Lian Yan, Haotian Wang, Chen Tang, Haifeng Liu, Tianyang Sun, Liangliang Liu, Yi Guan, and Jingchi Jiang. AgriEval: A Comprehensive Chinese Agricultural Benchmark for Large Language Models.Proceedings of the AAAI Conference on Artificial Intelligence, 40(40): 34205–34213, 2026. doi: 10.1609/aaai.v40i40.40716. URL https://ojs.aaai.org/index .php/AAAI/artic...
-
[47]
Jan Weyler, Federico Magistri, Elias Marks, Yue Linn Chong, Matteo Sodano, Gianmarco Roggiolani, Nived Chebrolu, Cyrill Stachniss, and Jens Behley. PhenoBench – A Large Dataset and Benchmarks for Semantic Image Interpretation in the Agricultural Domain.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9583–9594, 2024. doi: 10.1109/TPA...
-
[48]
Deep fruit detection in orchards
Suchet Bargoti and James Underwood. Deep fruit detection in orchards. In2017 IEEE International Conference on Robotics and Automation (ICRA), pages 3626–3633. IEEE, 2017. doi: 10.1109/ICRA.2017.7989417. URL http://ieeexplore.ieee.org/document/798 9417/
-
[49]
Yanan Wang, Zhenghao Fei, Ruichen Li, and Yibin Ying. Learn from foundation model: Fruit detection model without manual annotation.Pattern Recognition, 174:112799, 2026. doi: 10.1016/j.patcog.2025.112799. URL https://linkinghub.elsevier.com/retrieve/p ii/S0031320325014621
-
[50]
OAM-TCD: A globally diverse dataset of high-resolution tree cover maps
Josh Veitch-Michaelis, Andrew Cottam, Daniella Schweizer, Eben N Broadbent, David Dao, Ce Zhang, Angelica Almeyda Zambrano, and Simeon Max. OAM-TCD: A globally diverse dataset of high-resolution tree cover maps. 2024
work page 2024
-
[51]
Annotated tree crown bounding boxes in urban/rural environment, 2025
Jelle Dumortier. Annotated tree crown bounding boxes in urban/rural environment, 2025. URL https://zenodo.org/doi/10.5281/zenodo.15155081
-
[52]
OpenAI. Hello GPT-4o, 2024. URLhttps://openai.com/index/hello-gpt-4o/
work page 2024
-
[53]
GPT-5.4 Thinking System Card, 2026
OpenAI. GPT-5.4 Thinking System Card, 2026. URL https://openai.com/index/gpt-5 -4-thinking-system-card/
work page 2026
-
[54]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, et al. Gemini: A Family of Highly Capable Multimodal Models.arXiv preprint arXiv:2312.11805, 2023. doi: 10.48550/a rXiv.2312.11805. URLhttps://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/a 2023
-
[55]
Introducing Claude Sonnet 4.6, 2026
Anthropic. Introducing Claude Sonnet 4.6, 2026. URL https://www.anthropic.com/news /claude-sonnet-4-6
work page 2026
-
[56]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. DeepSeek-VL2: Mixture-of-Experts Visio...
work page 2024
-
[57]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Scaling Open-V ocabulary Object Detection
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling Open-V ocabulary Object Detection. 2023
work page 2023
-
[60]
Emogen: Emotional image content generation with text-to-image diffusion models,
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4818–4829. IEEE, 2024. doi: 10.1109/CVPR52733.2024.00461. URL https://ieeexplore.ieee.org/do...
-
[61]
Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2...
-
[62]
Emogen: Emotional image content generation with text-to-image diffusion models,
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. LISA: Reasoning Segmentation via Large Language Model. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9579–9589. IEEE, 2024. doi: 10.1109/ CVPR52733.2024.00915. URLhttps://ieeexplore.ieee.org/document/10658574/
-
[63]
Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S. Khan. GLaMM: Pixel Grounding Large Multimodal Model. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13009–13018. IEEE, 2024. doi: 10.1109/CVPR52733.20 24.01236. URLhttps...
-
[64]
PixelLM: Pixel Reasoning with Large Multimodal Model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. PixelLM: Pixel Reasoning with Large Multimodal Model. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26364–26373. IEEE,
-
[65]
Emogen: Emotional image content generation with text-to-image diffusion models,
doi: 10.1109/CVPR52733.2024.02491. URL https://ieeexplore.ieee.org/docu ment/10656606/
-
[66]
GSV A: Generalized Segmentation via Multimodal Large Language Models
Zhuofan Xia, Dongchen Han, Yizeng Han, Xuran Pan, Shiji Song, and Gao Huang. GSV A: Generalized Segmentation via Multimodal Large Language Models. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3858–3869. IEEE,
-
[67]
Emogen: Emotional image content generation with text-to-image diffusion models,
doi: 10.1109/CVPR52733.2024.00370. URL https://ieeexplore.ieee.org/docu ment/10658546/. 14
-
[68]
PSALM: Pixelwise SegmentAtion with Large Multi-modal Model
Zheng Zhang, Yeyao Ma, Enming Zhang, and Xiang Bai. PSALM: Pixelwise SegmentAtion with Large Multi-modal Model. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision – ECCV 2024, volume 15092, pages 74–91. Springer Nature Switzerland, 2025. doi: 10.1007/978-3-031-72754-2_5. URL https://link....
-
[69]
Generalized Decoding for Pixel, Image, and Language
Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, and Jianfeng Gao. Generalized Decoding for Pixel, Image, and Language. 2023
work page 2023
-
[70]
Segment Everything Everywhere All at Once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment Everything Everywhere All at Once. 2023
work page 2023
-
[71]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane Momeni, Rishi Hazra, Shuangrui Ding,...
work page 2025
-
[72]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks, 2024. URLhttps://arxiv.org/abs/2401.14159. 15 AgroVG: A Large-Scale Multi-Source Bench...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
AgroVG is constructed from public agricultural imagery and source annotations
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.