From Correlation to Cause: A Five-Stage Methodology for Feature Analysis in Transformer Language Models
Pith reviewed 2026-05-22 06:51 UTC · model grok-4.3
The pith
A five-stage methodology applied to GPT-2 shows that sparse autoencoder features for indirect object identification are only partially causal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its five-stage methodology, when run end-to-end on the indirect object identification task in GPT-2 small, establishes that fifteen per-name selective features recovered by a sparse autoencoder are specifically but only partially causal for the task: ablating them leaves the model accurate on 98 percent of prompts, the features explain only 31 percent of activation variance compared with the SAE's 99.7 percent, selectivity ratio anticorrelates with causal force at r equals negative 0.56, the circuit transfers cleanly under three distribution shifts while feature ablation effects degrade, and an optimal cost-based monitor yields 99.1 percent savings against baseline.
What carries the argument
The five-stage methodology of probe design, feature extraction via sparse autoencoder, causal validation by activation patching and ablation, robustness testing under distribution shifts, and deployment integration with cost evaluation.
If this is right
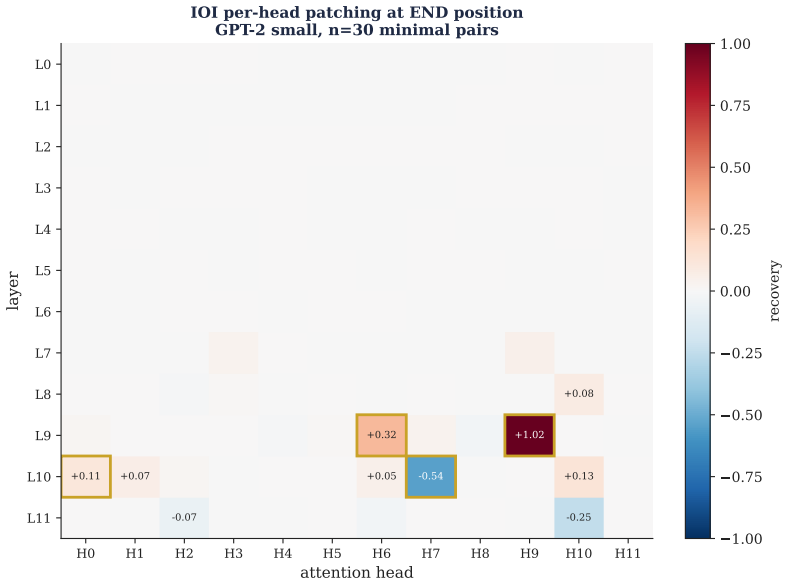
- Activation patching recovers the canonical IOI circuit in which layer-9 head 9 alone produces recovery of plus 1.02.
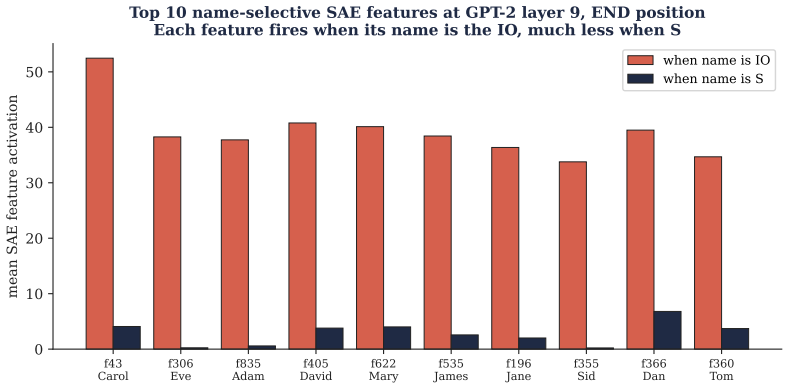
- Sparse autoencoders extract per-name selective features with effect sizes between 30 and 50 activation units.
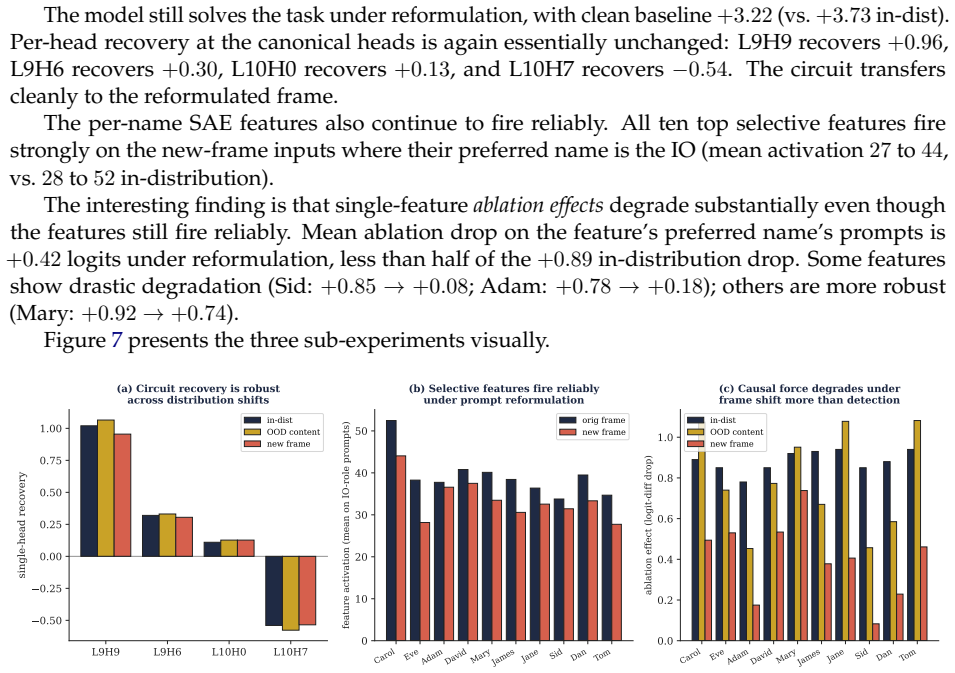
- The circuit transfers cleanly under three distribution shifts but feature ablation effects degrade substantially.
- A cost-based deployment evaluation with assumed costs of 50 dollars per false negative and 0.42 dollars per false positive yields an optimal monitor at 8.96 dollars per 1000 queries.
- Optimal monitor composition varies with cost ratio and base error rate, and the conjunction of all stages produces findings unreachable by any single stage.
Where Pith is reading between the lines
- The negative correlation between selectivity and causal force may indicate that the most selective features are not the ones driving the largest behavioral effects in the circuit.
- Extending the same staged validation to other common circuits could show whether partial causality is typical rather than specific to the IOI task.
- The observed gap between circuit robustness and feature robustness under shifts suggests that interpretability work should track both levels separately when building monitors.
- Cost-sensitive deployment calculations can still favor using even partially causal features when false-negative costs are high relative to false-positive costs.
Load-bearing premise
The three chosen distribution shifts adequately represent the range of real-world changes that could affect feature causality and circuit robustness.
What would settle it
Re-running the full five-stage pipeline on a different model or task and finding that ablating the identified selective features drops accuracy by far more than 2 percent, or that the selectivity ratio correlates positively rather than negatively with causal force.
Figures






read the original abstract
We propose a five-stage methodology for causal feature analysis in transformer language models (probe design, feature extraction, causal validation, robustness testing, and deployment integration) and demonstrate it end-to-end on GPT-2 small performing the Indirect Object Identification (IOI) task. Activation patching recovers the canonical IOI circuit (layer-9 head 9 alone gives recovery +1.02). A sparse autoencoder recovers per-name selective features with effect sizes of 30 to 50 activation units. Causal validation finds these features specifically but only partially causal: ablating fifteen of them leaves the model accurate on 98% of prompts. Two NLA-inspired evaluations strengthen this picture: the fifteen selective features explain only 31% of activation variance versus the SAE's 99.7%, and selectivity ratio anticorrelates with causal force (r = -0.56). Robustness testing under three distribution shifts finds that the circuit transfers cleanly but feature ablation effects degrade substantially, exposing a gap between detection robustness and causal robustness. A cost-based deployment evaluation (assumed $50/FN, $0.42/FP, 2% error rate) finds an optimal monitor configuration yielding $8.96 per 1000 queries against a $1000 baseline, a 99.1% saving. Optimal composition strategy varies with cost ratio and base rate. The conjunction of stages produces findings no single stage would.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a five-stage methodology (probe design, feature extraction, causal validation, robustness testing, deployment integration) for causal feature analysis in transformer LMs and demonstrates it end-to-end on GPT-2 small for the IOI task. Activation patching recovers the canonical IOI circuit; an SAE extracts per-name selective features; ablation of fifteen such features leaves 98% accuracy; the features explain only 31% of activation variance (vs. SAE's 99.7%) with selectivity ratio anticorrelating with causal force (r=-0.56); the circuit transfers across three distribution shifts while feature-ablation effects degrade; a cost-based monitor yields $8.96 per 1000 queries vs. $1000 baseline.
Significance. If the reported gap between circuit-level and feature-level causal robustness holds, the work supplies a concrete, multi-stage pipeline that moves beyond isolated correlational or causal probes and yields practical deployment metrics. The end-to-end demonstration, concrete numbers (98% post-ablation accuracy, 31% variance, r=-0.56), and cost-based evaluation are strengths that make the findings falsifiable and directly usable.
major comments (1)
- [Robustness testing stage] Robustness testing stage: the central claim that the five-stage pipeline exposes a reliable gap between detection robustness and causal robustness rests on the contrast between clean circuit transfer and degraded feature-ablation effects under three distribution shifts. The manuscript provides no explicit justification, diversity metrics, or sensitivity analysis showing that these shifts adequately sample the space of real-world changes that could affect feature causality; if the shifts are mild or correlated with the original IOI distribution, the observed degradation may be an artifact of the test regime rather than a general property.
minor comments (2)
- [Abstract and Causal validation section] The abstract and methods should report error bars or confidence intervals on the 98% accuracy, 31% variance, and r=-0.56 figures.
- [Causal validation section] Clarify the exact definition of 'selectivity ratio' and how it is computed from the SAE features before correlating it with causal force.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address the major comment on the robustness testing stage below, agreeing that additional documentation is warranted.
read point-by-point responses
-
Referee: Robustness testing stage: the central claim that the five-stage pipeline exposes a reliable gap between detection robustness and causal robustness rests on the contrast between clean circuit transfer and degraded feature-ablation effects under three distribution shifts. The manuscript provides no explicit justification, diversity metrics, or sensitivity analysis showing that these shifts adequately sample the space of real-world changes that could affect feature causality; if the shifts are mild or correlated with the original IOI distribution, the observed degradation may be an artifact of the test regime rather than a general property.
Authors: We agree that the manuscript would benefit from greater transparency on this point. The three shifts were chosen to vary lexical items (e.g., name substitutions drawn from different frequency bands), syntactic framing, and prompt length while preserving the core IOI structure, but these design choices were not fully articulated. In the revision we will add a dedicated subsection that (i) justifies each shift with reference to potential real-world distributional changes that could affect feature selectivity, (ii) reports quantitative diversity metrics including token-level KL divergence and type-token ratio differences between the original and shifted sets, and (iii) includes a sensitivity analysis that perturbs shift parameters and re-measures the degradation in ablation effects. These additions will make the claim that the observed robustness gap is not an artifact of the test regime more defensible while leaving the empirical contrast between circuit transfer and feature degradation intact. revision: yes
Circularity Check
No significant circularity; methodology applies standard external techniques
full rationale
The paper proposes a five-stage pipeline and applies it to the IOI task using activation patching (recovering the known circuit) and SAEs (recovering selective features). Causal validation, variance explained (31% vs 99.7%), selectivity correlation (r = -0.56), and robustness testing across three shifts are direct empirical measurements, not quantities defined from fitted parameters within the paper or reduced by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation. The central claim of a robustness gap follows from the observed contrast between circuit transfer and feature degradation; the representativeness of the shifts is an external assumption, not a circular reduction. The work is self-contained against prior benchmarks and does not rename known results as novel derivations.
Axiom & Free-Parameter Ledger
free parameters (3)
- Cost per false negative =
$50
- Cost per false positive =
$0.42
- Base error rate =
2%
axioms (2)
- domain assumption Activation patching provides a valid causal intervention for recovering model circuits.
- domain assumption Sparse autoencoders extract interpretable and selective features from transformer activations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The five-stage methodology... causal validation... robustness testing... deployment integration... cost-based evaluation (assumed $50/FN, $0.42/FP)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
selectivity ratio anticorrelates with causal force (r = -0.56)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda.Refusal in Language Models Is Mediated by a Single Direction. arXiv:2406.11717, 2024. https://arxiv.org/abs/2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Transformer Circuits Thread, 2023.https://transformer-circuits
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
work page 2023
-
[3]
ICML, 2024.https://arxiv.org/abs/2403.10949
Haozhe Chen, Carl Vondrick, and Chengzhi Mao.SelfIE: Self-Interpretation of Large Language Model Embeddings. ICML, 2024.https://arxiv.org/abs/2403.10949. 24
-
[4]
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso.Towards Automated Circuit Discovery for Mechanistic Interpretability. NeurIPS, 2023.https://arxiv.org/abs/2304.14997
-
[5]
What you can cram into a single vector: Probing sentence embeddings for linguistic properties
Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. What you can cram into a single vector: Probing sentence embeddings for linguistic properties. ACL, 2018.https://arxiv.org/abs/1805.01070
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey.Sparse Autoencoders Find Highly Interpretable Features in Language Models. ICLR, 2024. https:// arxiv.org/abs/2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Kit Fraser-Taliente, Subhash Kantamneni, Euan Ong, Dan Mossing, Christina Lu, Paul C. Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M. Ziegler, Evan Hubinger, Joshua Batson, Jack Lindsey, Samuel Zimmerman, and Samuel Marks.Natural Language Autoencoders Produce Unsupervised Explanati...
work page 2026
-
[8]
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva.Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models. ICML, 2024. https://arxiv.org/abs/2401.06102
-
[9]
Manning.A Structural Probe for Finding Syntax in Word Representations
John Hewitt and Christopher D. Manning.A Structural Probe for Finding Syntax in Word Representations. NAACL-HLT, 2019.https://aclanthology.org/N19-1419/
work page 2019
-
[10]
Adam Karvonen, James Chua, Conor Dumas, Kit Fraser-Taliente, Subhash Kantamneni, Julian Minder, Euan Ong, Aditya S. Sharma, Daniel Wen, Owain Evans, and Samuel Marks.Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers. arXiv:2512.15674, 2025.https://arxiv.org/abs/2512.15674
-
[11]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models. arXiv:2403.19647, 2024.https://arxiv.org/abs/2403.19647
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Locating and Editing Factual Associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov.Locating and Editing Factual Associations in GPT. NeurIPS, 2022.https://arxiv.org/abs/2202.05262
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Neel Nanda and Joseph Bloom.TransformerLens. GitHub, 2022. https://github.com/ TransformerLensOrg/TransformerLens
work page 2022
-
[14]
Christopher Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter.Zoom In: An Introduction to Circuits. Distill, 2020. https://distill.pub/2020/ circuits/zoom-in/
work page 2020
-
[15]
Catherine Olsson, Nelson Elhage, Neel Nanda, et al.In-context Learning and Induction Heads. Transformer Circuits Thread, 2022.https://transformer-circuits.pub/2022/ in-context-learning-and-induction-heads
work page 2022
-
[16]
ICLR, 2025.https://arxiv.org/abs/2412.08686
Alexander Pan, Lijun Chen, and Jacob Steinhardt.LatentQA: Teaching LLMs to Decode Activations Into Natural Language. ICLR, 2025.https://arxiv.org/abs/2412.08686. 25
-
[17]
Language Models are Unsupervised Multitask Learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language Models are Unsupervised Multitask Learners. OpenAI Technical Report, 2019. https://cdn.openai.com/better-language-models/language_models_are_ unsupervised_multitask_learners.pdf
work page 2019
-
[18]
Improving Dictionary Learning with Gated Sparse Autoencoders
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda.Improving Dictionary Learning with Gated Sparse Autoencoders. arXiv:2404.16014, 2024.https://arxiv.org/abs/2404.16014
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Turner, Callum McDougall, Monte MacDiarmid, C
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L. Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan.Scaling Monosema...
work page 2024
-
[20]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid.Activation Addition: Steering Language Models Without Optimization. arXiv:2308.10248, 2023.https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber.Investigating Gender Bias in Language Models Using Causal Media- tion Analysis. NeurIPS, 2020. https://proceedings.neurips.cc/paper/2020/hash/ 92650b2e92217715fe312e6fa7b90d82-Abstract.html
work page 2020
-
[22]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small. ICLR, 2023. https://arxiv.org/abs/2211.00593
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks.Representation Engineering: A Top-Down Ap- proach to ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.