Contractual Skills: A GovernSpec Design Framework for Enterprise AI Agents
Pith reviewed 2026-05-22 03:43 UTC · model grok-4.3
The pith
Contractual skills turn agent instructions into inspectable task contracts for enterprise governance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
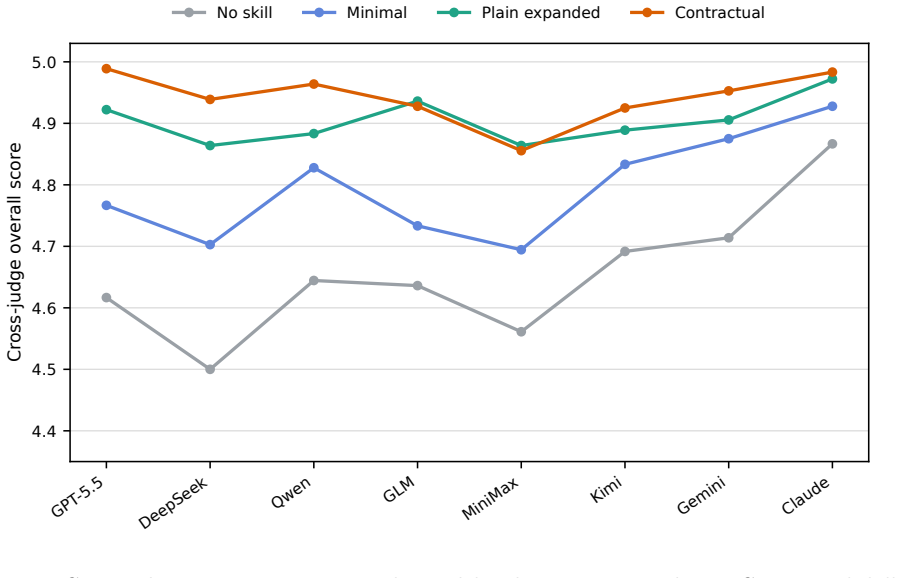
Contractual skills package agent instructions as readable task contracts in SKILL.md files. They add explicit fields for goals, boundaries, permissions, evidence, outputs, quality, verification, approvals, and handoffs while preserving lightweight discovery. In text-generation tests they outperform no-skill and minimal-skill baselines across all eight models; relative to detailed plain skills the gains are small and mixed. In tool-calling tests they usually reduce risky calls but model variation persists and runtime guardrails remain necessary. The framework therefore functions as an explicit governance layer rather than a replacement for other controls.
What carries the argument
Contractual skill structure in SKILL.md files, which adds GovernSpec-inspired contract fields to standard skill packaging.
If this is right
- Contractual skills improve checkability and maintainability of enterprise agent tasks.
- They reduce some high-risk tool attempts but still require separate runtime guardrails.
- Model-specific differences in tool behavior remain visible even with contractual structure.
- The main value lies in making task intent and acceptance criteria explicit for human review.
Where Pith is reading between the lines
- The structure could be combined with live tracing systems to create auditable agent histories without extra overhead.
- Enterprise teams might adopt it first for high-stakes workflows where handoff rules and approval points matter most.
- Testing the same fields in dynamic multi-agent environments could reveal whether the contract format scales beyond single-skill use.
Load-bearing premise
Offline results from synthetic tasks and simulated tool calls will translate to practical gains in real enterprise deployments and governance.
What would settle it
A production enterprise deployment in which contractual skills produce no measurable improvement in audit logs, error tracing, or maintenance effort compared with information-rich plain skills.
Figures




read the original abstract
Skills are increasingly used to package agent instructions, workflows, scripts, and reference materials. In enterprise settings, however, skills often need to express more than task guidance: they must make goals, input boundaries, permissions, evidence requirements, output contracts, quality criteria, verification steps, human approval points, and handoff rules inspectable. This paper proposes contractual skills, a GovernSpec-inspired design framework for organizing SKILL.md files as readable task contracts while preserving lightweight skill discovery and progressive loading. The framework clarifies the boundary between contractual skills, GovernSpec YAML contracts, Model Context Protocol surfaces, tool adapters, runtime guardrails, tracing, and evaluation systems. We evaluate the framework with two offline experiments. A text-generation study covers three enterprise skills, fifteen synthetic tasks, four instruction conditions, and eight generation models, yielding 960 outputs and 1680 cross-judge score records. Contractual skills outperform no-skill and minimal-skill baselines on all tested models. Relative to information-rich plain expanded skills, the gains are small and mixed, suggesting that contractual fields mainly improve checkability and maintainability rather than raw generation quality. A tool-calling challenge covers eight models and 192 simulated tool-call records. Skills usually reduce high-risk tool attempts, but model differences remain and runtime tool guardrails are still required. The results suggest that contractual skills are best understood as a governance layer that makes task intent, boundaries, and acceptance criteria explicit, not as a standalone safety mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes contractual skills as a GovernSpec-inspired design framework for structuring SKILL.md files in enterprise AI agents. The framework organizes instructions to explicitly include goals, input boundaries, permissions, evidence requirements, output contracts, quality criteria, verification steps, human approval points, and handoff rules, while preserving lightweight discovery and progressive loading. It distinguishes contractual skills from GovernSpec YAML contracts, Model Context Protocol surfaces, tool adapters, runtime guardrails, tracing, and evaluation systems. Evaluation uses two offline experiments: a text-generation study with three enterprise skills, fifteen synthetic tasks, four instruction conditions, and eight models (960 outputs, 1680 cross-judge scores) showing outperformance over no-skill and minimal-skill baselines but small/mixed gains versus information-rich expanded skills; and a tool-calling study with eight models and 192 simulated tool-call records indicating reduced high-risk tool attempts. The authors conclude that contractual skills function primarily as a governance layer improving checkability and maintainability rather than raw generation quality.
Significance. If the framework holds, it offers a practical structure for making enterprise AI agent skills more auditable and governable, potentially aiding compliance and human oversight in production deployments. The experiments provide concrete evidence of benefits over minimal baselines and some reduction in risky tool use across models. The work contributes a clear conceptual separation of concerns that could guide practitioners. However, significance is moderated because the core interpretive claim about checkability and maintainability rests on inference from generation results rather than direct measurement, and the studies use synthetic tasks and simulated calls.
major comments (2)
- [Abstract] Abstract: The central interpretive claim that 'contractual fields mainly improve checkability and maintainability rather than raw generation quality' and function as a 'governance layer' is not supported by direct evidence. The text-generation and tool-calling experiments measure only output scores and high-risk tool attempts; no quantitative or qualitative data on inspection time, ambiguity detection, audit trail usability, or compliance verification accuracy are reported. This inference from the absence of large gains versus expanded skills is load-bearing for the framework's primary value proposition.
- [Evaluation] Evaluation (text-generation study): The reported 960 outputs and 1680 cross-judge scores demonstrate outperformance over baselines, but the manuscript provides no details on statistical tests, inter-rater reliability, confidence intervals, or access to raw data. This limits assessment of whether the small/mixed gains versus expanded skills are robust or merely noise, directly affecting the strength of the governance-layer conclusion.
minor comments (2)
- [Framework description] The boundary clarifications among contractual skills, GovernSpec YAML, MCP surfaces, and guardrails are useful but would be strengthened by a comparative table or diagram in the framework section.
- [Evaluation] Specify the exact eight generation models and any prompt templates used in the experiments to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the emphasis on strengthening the evidential basis for our interpretive claims and on providing fuller statistical reporting. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central interpretive claim that 'contractual fields mainly improve checkability and maintainability rather than raw generation quality' and function as a 'governance layer' is not supported by direct evidence. The text-generation and tool-calling experiments measure only output scores and high-risk tool attempts; no quantitative or qualitative data on inspection time, ambiguity detection, audit trail usability, or compliance verification accuracy are reported. This inference from the absence of large gains versus expanded skills is load-bearing for the framework's primary value proposition.
Authors: We agree that direct measurements of checkability (e.g., inspection time, ambiguity detection rates, or audit accuracy) would constitute stronger evidence. The experiments were deliberately scoped to first establish that contractual skills preserve or improve generation quality relative to baselines; the small and mixed gains versus information-rich expanded skills then provide indirect support for interpreting the primary value as governance rather than performance enhancement. We accept that this remains an inference. In revision we will (1) rephrase the abstract and conclusion to present the governance-layer interpretation as a supported hypothesis rather than a definitive conclusion, (2) add an explicit limitations paragraph noting the absence of direct usability metrics, and (3) outline planned follow-up studies that would collect inspection-time and audit-trail data. These changes address the load-bearing concern without altering the experimental results. revision: partial
-
Referee: [Evaluation] Evaluation (text-generation study): The reported 960 outputs and 1680 cross-judge scores demonstrate outperformance over baselines, but the manuscript provides no details on statistical tests, inter-rater reliability, confidence intervals, or access to raw data. This limits assessment of whether the small/mixed gains versus expanded skills are robust or merely noise, directly affecting the strength of the governance-layer conclusion.
Authors: We concur that the current manuscript lacks the statistical detail needed for readers to evaluate robustness. In the revised version we will insert a dedicated statistical analysis subsection that reports: (a) results of appropriate paired tests (Wilcoxon signed-rank or t-tests) with p-values for all condition comparisons, (b) inter-rater reliability via Fleiss’ kappa across the three judges, (c) 95 % confidence intervals around mean scores for each condition and model, and (d) a link to a public repository containing the raw 960 outputs, 1680 scores, and analysis scripts. These additions will allow direct assessment of whether the observed patterns are statistically reliable. revision: yes
Circularity Check
No circularity: framework definition independent of experimental outcomes
full rationale
The paper defines contractual skills as a GovernSpec-inspired organization of SKILL.md files that makes goals, boundaries, permissions, and verification steps explicit. It then reports separate offline experiments (960 generations, 1680 cross-judge scores, 192 simulated tool calls) using external models and synthetic tasks. The interpretive claim that contractual fields 'mainly improve checkability and maintainability' is presented as a suggestion drawn from the observed small/mixed gains versus expanded skills, not as a premise built into the framework definition itself. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided text. The evaluation metrics (generation scores, high-risk tool attempts) are distinct from the framework's structural elements, so the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
contractual skills
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Contractual skills... organized with inputs, permissions, human gates, evidence, output, verification, and handoff... governance layer that makes task intent, boundaries, and acceptance criteria explicit
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Table 1: Recommended fields for contractual skills... GovernSpec YAML contracts, Model Context Protocol surfaces, tool adapters, runtime guardrails
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agent skills.https://docs.claude.com/en/docs/agents-and-tools/ agent-skills, n.d
Anthropic. Agent skills.https://docs.claude.com/en/docs/agents-and-tools/ agent-skills, n.d. Accessed: 2026-05-21
work page 2026
-
[2]
SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement
Zenghao Duan, Yuxin Tian, Zhiyi Yin, Liang Pang, Jingcheng Deng, Zihao Wei, Shicheng Xu, Yuyao Ge, and Xueqi Cheng. Skillattack: Automated red teaming of agent skills through attack path refinement, 2026. URLhttps://arxiv.org/abs/2604.04989. arXiv:2604.04989
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis
Zhiyuan Li, Jingzheng Wu, Xiang Ling, Xing Cui, and Tianyue Luo. Towards secure agent skills: Architecture, threat taxonomy, and security analysis, 2026. URLhttps://arxiv.org/ abs/2604.02837. arXiv:2604.02837
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher R´ e, Diana Acosta-Navas, Drew A. Hudson, et al. Holistic evaluation of language models.Trans- actions...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
George Ling, Shanshan Zhong, and Richard Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality, 2026. URLhttps://arxiv. org/abs/2602.08004. arXiv:2602.08004
-
[6]
Ting Liu. Governspec: Runtime-independent contract compilation and offline acceptance testing for ai agent artifacts, 2026. URLhttps://ssrn.com/abstract=6674899. SSRN, April 29, 2026. 13
work page 2026
-
[7]
Prompts.https://modelcontextprotocol.io/specification/ 2025-06-18/server/prompts, 2025
Model Context Protocol. Prompts.https://modelcontextprotocol.io/specification/ 2025-06-18/server/prompts, 2025. Accessed: 2026-05-21
work page 2025
-
[8]
Function calling.https://platform.openai.com/docs/guides/ function-calling, n.d
OpenAI. Function calling.https://platform.openai.com/docs/guides/ function-calling, n.d.. Accessed: 2026-05-21
work page 2026
-
[9]
Guardrails.https://openai.github.io/openai-agents-js/guides/ guardrails/, n.d
OpenAI. Guardrails.https://openai.github.io/openai-agents-js/guides/ guardrails/, n.d.. Accessed: 2026-05-21
work page 2026
-
[10]
Tracing.https://openai.github.io/openai-agents-python/tracing/, n.d
OpenAI. Tracing.https://openai.github.io/openai-agents-python/tracing/, n.d.. Ac- cessed: 2026-05-21
work page 2026
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. URLhttps://arxiv.org/abs/2210.03629. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.