Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Pith reviewed 2026-05-22 05:40 UTC · model grok-4.3
The pith
Reinforcement learning fine-tuning trains LLM agents to handle complex multi-step tasks inside Microsoft Excel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
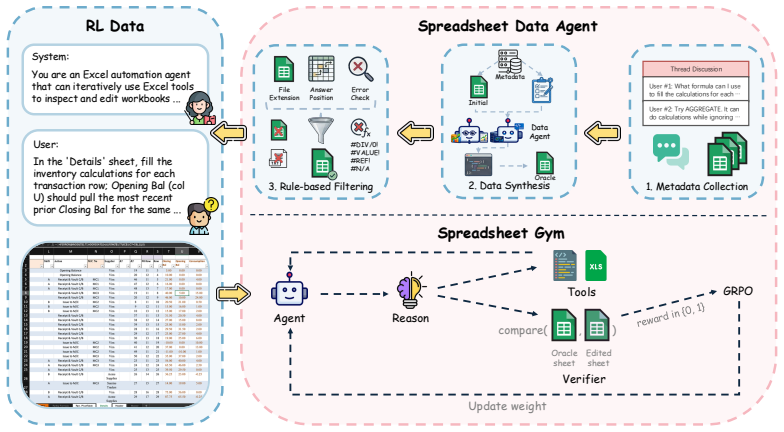
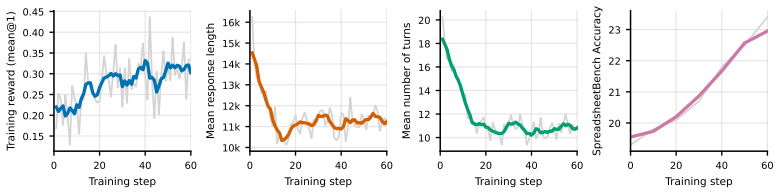
Spreadsheet-RL is a reinforcement learning fine-tuning framework that trains large language model agents inside a realistic Microsoft Excel environment. It uses an automated pipeline to collect paired start-goal spreadsheet examples from online forums and introduces the Spreadsheet Gym, which exposes extensive Excel functionality through a Python sandbox along with a tool set and routing rules for multi-turn interactions. When applied to Qwen3-4B-Thinking-2507, the approach raises first-attempt success from 12.0 percent to 23.4 percent on SpreadsheetBench and from 8.4 percent to 17.2 percent on the curated Domain-Spreadsheet dataset covering finance and supply chain management.
What carries the argument
The Spreadsheet Gym environment that supports multi-turn reinforcement learning by exposing Excel operations through a Python sandbox and a set of tools with defined routing rules.
If this is right
- Agents become capable of completing complex multi-step spreadsheet workflows that prompting alone cannot reliably solve.
- Performance improves on both general spreadsheet benchmarks and specialized tasks in finance and supply chain management.
- The framework offers a path toward broader adoption of AI for automating everyday data-centric work in spreadsheet software.
- Similar reinforcement learning setups could extend to other data interfaces that require sequential tool use.
- Specialized agents trained this way generalize better than general-purpose models on realistic spreadsheet operations.
Where Pith is reading between the lines
- The same data-collection and gym approach might transfer to training agents for related productivity tools such as presentation software or databases.
- The gains suggest that reinforcement learning can overcome limits of prompting methods across other tool-use domains.
- Further tests on larger base models would reveal whether the improvements scale or remain specific to the tested 4B model.
- Deployment in practice would still need to verify that forum-sourced examples cover the full range of professional spreadsheet practices.
Load-bearing premise
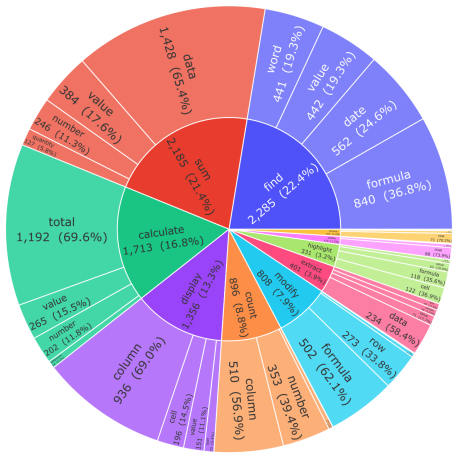
The automated scraping of start-goal spreadsheet pairs from online forums produces training data whose difficulty and distribution match real-world multi-step workflows.
What would settle it
Evaluating the trained agent on a fresh set of spreadsheet tasks collected directly from professional users in finance or supply chain roles and checking whether the reported gains in first-attempt success still appear.
Figures



read the original abstract
Spreadsheet systems (e.g., Microsoft Excel, Google Sheets) play a central role in modern data-centric workflows. As AI agents grow increasingly capable of automating complex tasks, such as controlling computers and generating presentations, building an AI-driven spreadsheet agent has emerged as a promising research direction. Most existing spreadsheet agents rely on specialized prompting over general-purpose LLMs; while this design has potentials on simple spreadsheet operations, it struggles to manage the complex, multi-step workflows typical of real-world applications. We introduce Spreadsheet-RL, a reinforcement learning (RL) fine-tuning framework designed to train specialized spreadsheet agents within a realistic Microsoft Excel environment. Spreadsheet-RL features an automated pipeline for scalable collection of paired start-goal spreadsheets from online forums, as well as domain-specific evaluation tasks in areas such as finance and supply chain management, which we compile into the new Domain-Spreadsheet benchmark dataset. It also includes a Spreadsheet Gym environment designed for multi-turn RL: Spreadsheet Gym exposes extensive Excel functionality through a Python sandbox, along with a refined harness that incorporates a comprehensive tool set and carefully designed tool-routing rules for spreadsheet tasks. Through comprehensive experiments, we show that Spreadsheet-RL substantially enhances AI agent's performance on both general and domain-specific spreadsheet tasks: it improves Qwen3-4B-Thinking-2507's Pass@1 on SpreadsheetBench from 12.0% to 23.4%, and raises Pass@1 from 8.4% to 17.2% on our curated Domain-Spreadsheet dataset. These results highlight Spreadsheet-RL's strong potential for generalization and real-world adoption in spreadsheet automation, and broadly, its promise for advancing LLM-based interactions with data interfaces in everyday work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spreadsheet-RL, a reinforcement learning framework for fine-tuning LLM agents to perform complex multi-step tasks in realistic spreadsheet environments such as Microsoft Excel. It describes an automated pipeline to scrape paired start-goal spreadsheets from online forums for training data, a Spreadsheet Gym environment exposing Excel functionality via Python sandbox with tool sets and routing rules, and a new Domain-Spreadsheet benchmark covering finance and supply chain tasks. Experiments report that RL fine-tuning raises Qwen3-4B-Thinking-2507 Pass@1 from 12.0% to 23.4% on SpreadsheetBench and from 8.4% to 17.2% on the domain-specific dataset.
Significance. If the performance gains prove robust and the training data distribution aligns with real-world multi-step workflows, the work would advance practical LLM agents for data-centric interfaces by demonstrating the benefits of RL over prompting alone. The introduction of domain-specific benchmarks is a constructive addition for evaluating applicability in professional settings. The results, however, depend critically on unverified assumptions about data realism and experimental rigor.
major comments (2)
- [§3.1] §3.1 (Data Collection Pipeline): The automated scraping of paired start-goal spreadsheets from online forums is load-bearing for the training setup, yet the manuscript supplies no quantitative validation (e.g., distributions of step counts, formula complexity, error-recovery requirements, or domain coverage) comparing the scraped pairs to the held-out SpreadsheetBench and Domain-Spreadsheet tasks. Without such evidence, the reported Pass@1 lifts cannot be confidently attributed to RL generalization rather than training-test distribution alignment.
- [Experiments section] Experiments section (results tables): The headline improvements (12.0% → 23.4% and 8.4% → 17.2%) are stated without reporting the number of evaluation runs, standard deviations, confidence intervals, or any statistical significance tests. This absence undermines assessment of whether the gains are reliable or reproducible, especially given the central claim of substantial enhancement.
minor comments (2)
- [Abstract] The abstract refers to 'comprehensive experiments' and 'carefully designed tool-routing rules' but provides no high-level summary of the baselines or how the routing rules were validated; adding one sentence would improve clarity for readers.
- [Evaluation protocol] Notation for Pass@1 and the exact definition of success criteria on multi-turn tasks could be stated more explicitly in the evaluation protocol to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of rigor in our work. We address each major comment point by point below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Data Collection Pipeline): The automated scraping of paired start-goal spreadsheets from online forums is load-bearing for the training setup, yet the manuscript supplies no quantitative validation (e.g., distributions of step counts, formula complexity, error-recovery requirements, or domain coverage) comparing the scraped pairs to the held-out SpreadsheetBench and Domain-Spreadsheet tasks. Without such evidence, the reported Pass@1 lifts cannot be confidently attributed to RL generalization rather than training-test distribution alignment.
Authors: We agree that explicit quantitative validation of the training data distribution relative to the evaluation sets would strengthen the attribution of gains to RL rather than distribution overlap. In the revised manuscript we have added a new Table 2 and accompanying text in §3.1 that reports step-count histograms, average formula complexity (number of formulas per sheet and cell references), error-recovery patterns, and domain coverage for a random sample of 5,000 scraped training pairs versus the held-out SpreadsheetBench and Domain-Spreadsheet tasks. The statistics show substantial overlap in step counts and domain coverage but also higher average formula complexity in the test sets, which we discuss as evidence that the observed improvements reflect generalization beyond simple distribution matching. We also note remaining limitations in fully verifying real-world workflow realism. revision: yes
-
Referee: [Experiments section] Experiments section (results tables): The headline improvements (12.0% → 23.4% and 8.4% → 17.2%) are stated without reporting the number of evaluation runs, standard deviations, confidence intervals, or any statistical significance tests. This absence undermines assessment of whether the gains are reliable or reproducible, especially given the central claim of substantial enhancement.
Authors: We concur that statistical details are necessary to assess reliability. We have re-executed the evaluation protocol with 10 independent runs using different random seeds for both the baseline and RL-fine-tuned models. The updated tables in the Experiments section now report mean Pass@1, standard deviation, and 95% confidence intervals. We additionally include results of paired t-tests against the baseline (p < 0.01 on both benchmarks), confirming that the reported lifts are statistically significant under the evaluation protocol described in the paper. revision: yes
Circularity Check
No circularity: empirical performance gains measured on held-out benchmarks
full rationale
The paper reports an RL fine-tuning framework whose central results are Pass@1 improvements (e.g., 12.0% to 23.4% on SpreadsheetBench) evaluated on separate held-out datasets and a curated Domain-Spreadsheet benchmark. No equations, fitted parameters, or derivations are presented that would make these metrics reduce to the training objective or scraped data by construction. The automated scraping pipeline and Spreadsheet Gym are described as inputs, but the evaluation tasks are independently compiled and measured, rendering the reported gains non-circular. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spreadsheet-RL features an automated pipeline for scalable collection of paired start-goal spreadsheets from online forums... Spreadsheet Gym... GRPO with verifiable outcome-based rewards
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
outcome-based reward R(o) = 0 if no valid output, all cells match(Dpred, Do) otherwise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude opus 4.1, 2025. URL https://www.anthropic.com/news/claude-o pus-4-1
work page 2025
-
[2]
H. Bai, A. Taymanov, T. Zhang, A. Kumar, and S. Whitehead. Webgym: Scaling training environments for visual web agents with realistic tasks, 2026. URL https://arxiv.org/ab s/2601.02439
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Fullstackbench: Evaluatingllmsasfullstackcoders
Bytedance-Team, Y . Cheng, J. Chen, J. Chen, L. Chen, L. Chen, W. Chen, Z. Chen, S. Geng, A. Li, B. Li, B. Li, L. Li, B. Liu, J. Liu, K. Liu, Q. Liu, S. Liu, S. Liu, T. Liu, T. Liu, Y . Liu, R. Long, J. Mai, G. Ning, Z. Y . Peng, K. Shen, J. Su, J. Su, T. Sun, Y . Sun, Y . Tao, G. Wang, S. Wang, X. Wang, Y . Wang, Z. Wang, J. Xia, L. Xiang, X. Xiao, Y . X...
-
[4]
W. Chen, H. Wang, J. Chen, Y . Zhang, H. Wang, S. Li, X. Zhou, and W. Y . Wang. Tabfact : A large-scale dataset for table-based fact verification. InInternational Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, April 2020
work page 2020
-
[5]
Y . Chen, Y . Yuan, Z. Zhang, Y . Zheng, J. Liu, F. Ni, J. Hao, H. Mao, and F. Zhang. Sheetagent: Towards a generalist agent for spreadsheet reasoning and manipulation via large language models. InProceedings of the ACM on Web Conference 2025, WWW ’25, page 158–177, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400712746. doi: 10...
-
[6]
S.-C. Cheung, W. Chen, Y . Liu, and C. Xu. Custodes: Automatic spreadsheet cell clustering and smell detection using strong and weak features. In2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), pages 464–475, 2016. doi: 10.1145/2884781.28 84796
-
[7]
C. De Leon and A. Parameswaran. Toward efficient spreadsheet computation and visualization. Technical report, Technical Report No. UCB/EECS-2022-67). Electrical Engineering and Computer . . . , 2022
work page 2022
- [8]
-
[9]
Gemini agent, multi-step tasks, handled, 2025
Google. Gemini agent, multi-step tasks, handled, 2025. URL https://gemini.google/ov erview/agent/
work page 2025
-
[10]
S. Gulwani. Automating string processing in spreadsheets using input-output examples.SIG- PLAN Not., 46(1):317–330, Jan. 2011. ISSN 0362-1340. doi: 10.1145/1925844.1926423. URL https://doi.org/10.1145/1925844.1926423
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081): 633–638, 2025
work page 2025
-
[12]
F. Hermans, M. Pinzger, and A. van Deursen. Detecting and visualizing inter-worksheet smells in spreadsheets. In2012 34th International Conference on Software Engineering (ICSE), pages 441–451, 2012. doi: 10.1109/ICSE.2012.6227171
-
[13]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
S. Kandel, A. Paepcke, J. M. Hellerstein, and J. Heer. Enterprise data analysis and visualization: An interview study.IEEE Transactions on Visualization and Computer Graphics, 18(12): 2917–2926, 2012. doi: 10.1109/TVCG.2012.219. 11
-
[15]
J. Y . Koh, R. Lo, L. Jang, V . Duvvur, M. Lim, P.-Y . Huang, G. Neubig, S. Zhou, R. Salakhutdinov, and D. Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pag...
- [16]
-
[17]
H. Li, J. Su, Y . Chen, Q. Li, and Z. Zhang. Sheetcopilot: bringing software productivity to the next level through large language models. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[18]
Z. Ma, B. Zhang, J. Zhang, J. Yu, X. Zhang, X. Zhang, S. Luo, X. Wang, and J. Tang. Spreadsheetbench: towards challenging real world spreadsheet manipulation. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
work page 2024
-
[19]
K. Mack, J. Lee, K. Chang, K. Karahalios, and A. Parameswaran. Characterizing scalability issues in spreadsheet software using online forums. InExtended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, CHI EA ’18, page 1–9, New York, NY , USA, 2018. Association for Computing Machinery. ISBN 9781450356213. doi: 10.1145/3170 427.3...
-
[20]
Vibe working: Introducing agent mode and office agent in microsoft 365 copilot, Sept
Microsoft. Vibe working: Introducing agent mode and office agent in microsoft 365 copilot, Sept. 2025. URL https://www.microsoft.com/en-us/microsoft-365/blog/2025/0 9/29/vibe-working-introducing-agent-mode-and-office-agent-in-microsoft -365-copilot/
work page 2025
-
[21]
H. Musa. excel-mcp-server. https://github.com/haris-musa/excel-mcp-server ,
- [22]
- [23]
-
[24]
OpenAI. Introducing gpt-5.2 the most advanced frontier model for professional work and long- running agents., Dec. 2025. URLhttps://openai.com/index/introducing-gpt-5-2/
work page 2025
-
[25]
Introducing chatgpt agent: bridging research and action, Dec
OpenAI. Introducing chatgpt agent: bridging research and action, Dec. 2025. URL https: //openai.com/index/introducing-chatgpt-agent/
work page 2025
-
[26]
Openai o3 and o4-mini system card, Dec
OpenAI. Openai o3 and o4-mini system card, Dec. 2025. URL https://openai.com/index /o3-o4-mini-system-card/
work page 2025
-
[27]
P. Pasupat and P. Liang. Compositional semantic parsing on semi-structured tables. In C. Zong and M. Strube, editors,Proceedings of the 53rd Annual Meeting of the Associa- tion for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480, Beijing, China, July
-
[28]
Association for Computational Linguistics. doi: 10.3115/v1/P15-1142. URL https://aclanthology.org/P15-1142/
-
[29]
S. Rahman, K. Mack, M. Bendre, R. Zhang, K. Karahalios, and A. Parameswaran. Benchmark- ing spreadsheet systems. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, SIGMOD ’20, page 1589–1599, New York, NY , USA, 2020. Associa- tion for Computing Machinery. ISBN 9781450367356. doi: 10.1145/3318464.3389782. URL https://doi....
-
[30]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
-
[31]
URLhttps://arxiv.org/abs/2402.03300. 12
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
URL http://dx.doi.org/10.1145/3689031
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400711961. doi: 10.1145/3689031.3696075. URL htt...
-
[33]
Y . Song, K. Ramaneti, Z. Sheikh, Z. Chen, B. Gou, T. Xie, Y . Xu, D. Zhang, A. Gandhi, F. Yang, J. Liu, T. Ou, Z. Yuan, F. Xu, S. Zhou, X. Wang, X. Yue, T. Yu, H. Sun, Y . Su, and G. Neubig. Agent data protocol: Unifying datasets for diverse, effective fine-tuning of llm agents, 2026. URLhttps://arxiv.org/abs/2510.24702
-
[34]
Y . Sun, M. Wang, S. Qian, W. R. Wong, E. Gan, P. D’Oro, A. C. Munoz, S. Silwal, P. Matias, N. Kamra, S. Kottur, N. Raines, X. Zhao, J. Chen, J. Greer, A. Madotto, A. Bolourchi, J. Valori, K. Carlberg, K. Ridgeway, and J. Tighe. Digidata: Training and evaluating general-purpose mobile control agents, 2025. URLhttps://arxiv.org/abs/2511.07413
-
[35]
Y . Wang, Q. Yang, Z. Zeng, L. Ren, L. Liu, B. Peng, H. Cheng, X. He, K. Wang, J. Gao, W. Chen, S. Wang, S. S. Du, and Y . Shen. Reinforcement learning for reasoning in large language models with one training example, 2025. URLhttps://arxiv.org/abs/2504.20571
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
Y . Wei, O. Duchenne, J. Copet, Q. Carbonneaux, L. Zhang, D. Fried, G. Synnaeve, R. Singh, and S. I. Wang. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution, 2025. URLhttps://arxiv.org/abs/2502.18449
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Y . Wei, Z. Sun, E. McMilin, J. Gehring, D. Zhang, G. Synnaeve, D. Fried, L. Zhang, and S. Wang. Toward training superintelligent software agents through self-play swe-rl, 2025. URL https://arxiv.org/abs/2512.18552
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y . Liu, Y . Xu, S. Zhou, S. Savarese, C. Xiong, V . Zhong, and T. Yu. Osworld: benchmarking multimodal agents for open-ended tasks in real computer environments. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Re...
work page 2024
-
[41]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing rea- soning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. 13 A Appendix A.1 Limitations Spreadsheet-RL provides an open research foundation for studying RL post-training in spreadsheet- based data workflows. Howev...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.