Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Pith reviewed 2026-05-21 16:02 UTC · model grok-4.3
The pith
An LLM agent trains itself to repair software bugs by generating and fixing its own increasingly complex test-specified tasks inside real codebases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
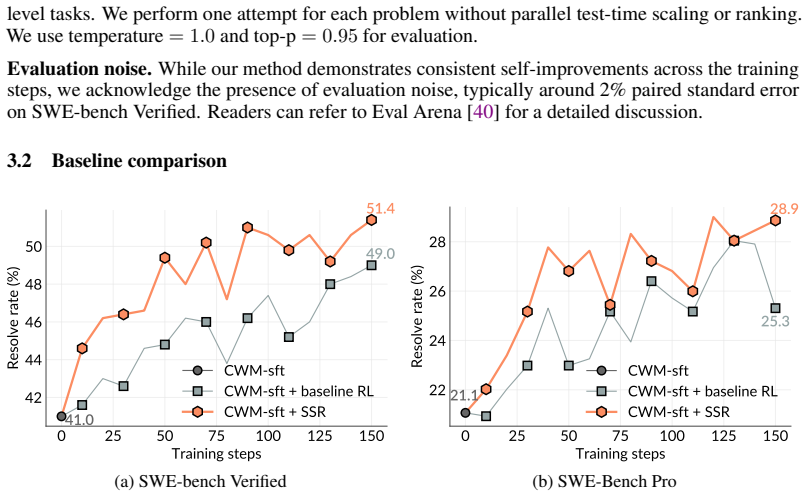
SSR trains one LLM agent via reinforcement learning in a self-play setting inside sandboxed repositories that contain only source code and installed dependencies. The agent generates bug-injection patches and corresponding repair patches, with each task defined by a test patch rather than natural language, and receives rewards based on test outcomes. Over the training trajectory the agent records consistent self-improvement and outperforms a human-data baseline on SWE-bench Verified and SWE-Bench Pro, even though those benchmark issues use natural language descriptions absent from the self-play data.
What carries the argument
Self-play SWE-RL (SSR), the loop in which a single LLM agent generates its own bug-repair tasks by injecting bugs and specifying them with test patches, then learns to solve those tasks through reinforcement learning.
If this is right
- Agents can collect large volumes of training experience directly from existing real-world software repositories without new human labeling.
- Training on patch-specified tasks produces measurable transfer to natural language issue resolution.
- Accuracy keeps rising across the entire training run rather than saturating early.
- The same minimal-assumption setup supplies a concrete route toward agents that exceed human performance in understanding and modifying complex systems.
Where Pith is reading between the lines
- The approach could be extended to self-generated tasks that involve adding new features or refactoring modules rather than only repairing bugs.
- Similar self-play loops might be applied in other sandboxable domains to reduce dependence on human-curated datasets.
Load-bearing premise
Performance gains measured on self-generated bug-repair tasks inside sandboxed repositories will transfer to solving natural language issues drawn from real developer workflows.
What would settle it
Evaluating the trained agent on a fresh collection of natural language bug reports taken from repositories that were never part of the self-play training set and checking whether the reported accuracy advantage disappears.
Figures








read the original abstract
While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Self-play SWE-RL (SSR), a reinforcement learning method in which a single LLM agent is trained via self-play to iteratively inject and repair bugs of increasing complexity inside sandboxed repositories. Bugs are formally specified by test patches rather than natural-language issue descriptions, requiring only access to source code and installed dependencies with no human-labeled issues or tests. The paper reports that SSR produces self-improvement of +10.4 points on SWE-bench Verified and +7.8 points on SWE-Bench Pro, consistently outperforming a human-data baseline across the entire training trajectory, even though evaluation uses natural-language issues absent from self-play. The work is positioned as an early step toward training paradigms for superintelligent software agents that can autonomously gather learning experiences from real-world codebases.
Significance. If the reported gains prove robust and attributable to generalizable agentic reasoning rather than repository-specific familiarity, the self-play paradigm would constitute a meaningful advance by substantially reducing dependence on human-curated training data. The consistent outperformance over the human-data baseline throughout training is a positive signal for scalability. The approach's minimal data assumptions and grounding in real repositories are strengths that could support broader exploration of autonomous software-agent training.
major comments (3)
- [Abstract] Abstract: the claim that natural-language issues are absent from self-play is stated, yet the manuscript is silent on whether the underlying source repositories used for SSR training overlap with those in SWE-bench Verified and SWE-Bench Pro. This distinction is load-bearing for the transfer claim; substantial overlap would allow the observed gains (+10.4 / +7.8 points) to arise from increased exposure to specific codebases, APIs, and test structures rather than improved general reasoning.
- [Experimental results] Experimental results section: no details are provided on training stability, variance across independent runs, or statistical significance of the benchmark improvements. Without these, it is difficult to determine whether the self-improvement trajectory is reliable or sensitive to random seeds and hyperparameter choices.
- [Method and evaluation] Method and evaluation sections: the paper does not describe how bug complexity is controlled or increased during self-play, nor how the self-generated test-patch tasks are ensured to be disjoint in difficulty and structure from the natural-language issues in the evaluation benchmarks. This control is necessary to support the claim that improvements transfer beyond the self-play distribution.
minor comments (2)
- [Abstract] Abstract and title: the phrasing 'superintelligent software agents' and 'superintelligence' should be qualified as aspirational given the preliminary scale of the experiments.
- [Throughout] Throughout the manuscript: ensure consistent definition of acronyms (SSR, SWE-RL) on first use and clarify the precise composition of the human-data baseline for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the opportunity to improve our manuscript. Below, we provide a point-by-point response to the major comments and indicate the revisions made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that natural-language issues are absent from self-play is stated, yet the manuscript is silent on whether the underlying source repositories used for SSR training overlap with those in SWE-bench Verified and SWE-Bench Pro. This distinction is load-bearing for the transfer claim; substantial overlap would allow the observed gains (+10.4 / +7.8 points) to arise from increased exposure to specific codebases, APIs, and test structures rather than improved general reasoning.
Authors: We agree that clarifying the repository overlap is essential to substantiate the transfer of improvements. The training repositories for SSR are selected from a diverse set of open-source projects that do not intersect with the SWE-bench Verified or SWE-Bench Pro repositories. This separation ensures that the agent learns general bug injection and repair strategies rather than memorizing specific codebases. In the revised manuscript, we have added this information to the Abstract and the Experimental Setup section, along with a table listing the training repositories to make the distinction explicit. revision: yes
-
Referee: [Experimental results] Experimental results section: no details are provided on training stability, variance across independent runs, or statistical significance of the benchmark improvements. Without these, it is difficult to determine whether the self-improvement trajectory is reliable or sensitive to random seeds and hyperparameter choices.
Authors: We acknowledge the importance of reporting training stability and statistical measures for reproducibility. We have conducted additional analysis on three independent training runs with varied random seeds. The revised Experimental Results section now includes plots showing the mean performance trajectory with standard deviation bands, and we report p-values from statistical tests confirming the significance of the +10.4 and +7.8 point gains over the baseline. These additions demonstrate that the self-improvement is robust and not overly sensitive to initialization. revision: yes
-
Referee: [Method and evaluation] Method and evaluation sections: the paper does not describe how bug complexity is controlled or increased during self-play, nor how the self-generated test-patch tasks are ensured to be disjoint in difficulty and structure from the natural-language issues in the evaluation benchmarks. This control is necessary to support the claim that improvements transfer beyond the self-play distribution.
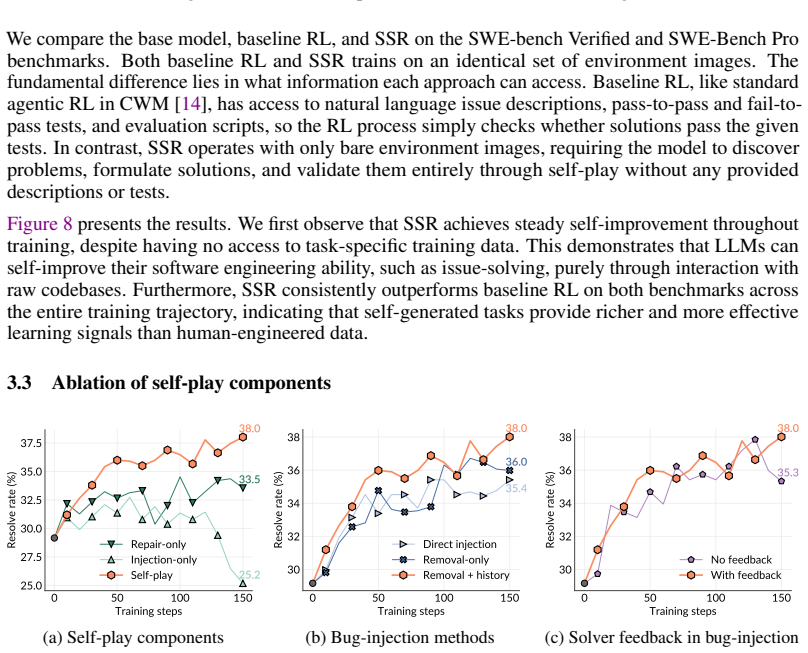
Authors: Thank you for this valuable suggestion. Bug complexity in self-play is controlled through a progressive curriculum: we begin with bugs affecting a single function and gradually increase to bugs spanning multiple files and functions, with complexity measured by the size of the test patch (number of lines modified) and the number of test cases involved. The agent's reward is tied to successful repair, allowing it to advance to harder bugs only after mastering simpler ones. For disjointness, the self-play tasks are generated within the training repositories using synthetic test patches, while the evaluation benchmarks consist of real natural-language issues from entirely separate repositories, creating a clear distribution shift in both task specification (test patch vs. NL description) and repository content. We have substantially expanded the Method section with a new subsection detailing the complexity scheduling algorithm and the distribution shift analysis to address this concern. revision: yes
Circularity Check
No significant circularity; empirical self-play gains are measured outcomes, not definitional reductions
full rationale
The paper defines a self-play RL loop that generates training signals via test-patch-specified bug injection and repair inside sandboxed repositories, then reports measured accuracy gains on separate SWE-bench natural-language benchmarks. No equations, fitted parameters, or self-citations are shown that make the reported +10.4 / +7.8 point improvements equivalent to the training inputs by construction. The self-play procedure is specified independently of the final benchmark scores, and the transfer claim rests on an empirical evaluation rather than a tautological identity. Potential repository overlap is a methodological concern about external validity, not a circularity in the derivation chain itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sandboxed repositories with source code and installed dependencies contain enough structure for an agent to learn transferable bug-injection and repair skills
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a single LLM policy is instantiated in two roles ... bug-injection agent and a bug-solving agent ... higher-order bugs constructed from the solver’s own failed repair attempts ... r_inject = 1-(1+α)s for 0<s<1
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
This survey introduces the Generate-Filter-Control-Replay (GFCR) taxonomy to structure rollout pipelines for RL-based post-training of reasoning LLMs.
-
Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Spreadsheet-RL applies RL fine-tuning and a custom Gym environment to raise LLM agent Pass@1 scores on spreadsheet benchmarks from roughly 8-12% to 17-23%.
-
PREPING: Building Agent Memory without Tasks
Preping builds agent memory via proposer-guided synthetic practice and selective validation, matching offline/online methods at 2-3x lower deployment cost.
Reference graph
Works this paper leans on
-
[1]
Albert Örwall.Moatless.https://github.com/aorwall/moatless-tools. 2024
work page 2024
-
[2]
DeepSeek AI.DeepSeek V3.1.https://api-docs.deepseek.com/news/news250821
-
[3]
https://openai.com/index/introducing- swe- bench- verified/
OpenAI.SWE-bench Verified. https://openai.com/index/introducing- swe- bench- verified/. 2025
work page 2025
-
[4]
Cognition.SWE-1.5.https://cognition.ai/blog/swe-1-5
-
[5]
Anthropic.Context editing (Client-side compaction / SDK). https://platform.claude. com/docs/en/build-with-claude/context-editing . Claude documentation describing automatic context compaction. 2025. (Visited on 12/18/2025)
work page 2025
-
[6]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents. 2025. arXiv: 2505.20411 [cs.SE].URL: https://arxiv. org/abs/2505.20411
-
[7]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. “MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention”. In:arXiv preprint arXiv:2506.13585(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al.DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. 2025. arXiv: 2512 . 02556 [cs.CL].URL: https://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Hints on Test Data Selection: Help for the Practicing Programmer
R.A. DeMillo, R.J. Lipton, and F.G. Sayward. “Hints on Test Data Selection: Help for the Practicing Programmer”. In:Computer11.4 (1978), pp. 34–41.DOI: 10.1109/C-M.1978. 218136
-
[11]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, et al.SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?2025. arXiv: 2509.16941 [cs.SE]. URL:https://arxiv.org/abs/2509.16941
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Devstral Team.Devstral2.https://mistral.ai/news/devstral-2-vibe-cli. 2025
work page 2025
-
[13]
FAIR CodeGen team.CWM-sft.https://huggingface.co/facebook/cwm-sft. 12
-
[14]
FAIR CodeGen team, Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al.CWM: An Open-Weights LLM for Research on Code Generation with World Models. 2025. arXiv: 2510.02387 [cs.SE].URL:https://arxiv.org/abs/2510.02387
-
[15]
https://www.index.dev/blog/ai-coding-assistants-roi-productivity
Alexandr Frunza.AI Coding Assistants ROI Study: Measuring Developer Productivity Gains. https://www.index.dev/blog/ai-coding-assistants-roi-productivity . Index.dev blog, accessed 2025-12-01. 2025
work page 2025
-
[16]
GLM-4.5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al.GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models. 2025. arXiv: 2508.06471 [cs.CL] .URL: https: //arxiv.org/abs/2508.06471
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu.R-Zero: Self-Evolving Reasoning LLM from Zero Data. 2025. arXiv:2508.05004 [cs.LG].URL:https://arxiv.org/abs/2508.05004
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. “R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents”. In: arXiv preprint arXiv:2504.07164(2025)
-
[20]
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan.SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
-
[21]
arXiv:2310.06770 [cs.CL].URL:https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
The Art of Scaling Reinforcement Learning Compute for LLMs
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S. Dhillon, David Brandfonbrener, and Rishabh Agarwal.The Art of Scaling Reinforcement Learning Compute for LLMs. 2025. arXiv: 2510.13786 [cs.LG].URL: https: //arxiv.org/abs/2510.13786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, et al.Kimi K2: Open Agentic Intelligence. 2025. arXiv: 2507.20534 [cs.LG] .URL: https://arxiv.org/abs/2507. 20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog
Satwik Kottur, José M. F. Moura, Stefan Lee, and Dhruv Batra. “Natural Language Does Not Emerge ’Naturally’ in Multi-Agent Dialog”. In:Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. arXiv:1706.08502. Association for Computational Linguistics. 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [25]
- [26]
- [27]
- [28]
-
[29]
2025.URL: https://github.com/ XiaomiMiMo/MiMo-V2-Flash/paper.pdf
LLM-Core Xiaomi.MiMo-V2-Flash Technical Report. 2025.URL: https://github.com/ XiaomiMiMo/MiMo-V2-Flash/paper.pdf
work page 2025
-
[30]
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Alpay Ariyak, Colin Cai, Shang Zhu Tarun Venkat, Ben Athiwaratkun, et al.Deepswe: Training a fully open-sourced, state-of-the-art coding agent by scaling rl
-
[31]
Docker: lightweight Linux containers for consistent development and deploy- ment
Dirk Merkel. “Docker: lightweight Linux containers for consistent development and deploy- ment”. In:Linux J.2014.239 (Mar. 2014).ISSN: 1075-3583. 13
work page 2014
-
[32]
https://github.com/SWE-bench/SWE-bench/issues/465
Meta FAIR CodeGen Team.Repo State Loopholes During Agentic Evaluation (SWE- bench/SWE-bench Issue #465). https://github.com/SWE-bench/SWE-bench/issues/465. Report of SWE-bench Verified loopholes enabling cheating by inspecting git history. Sept
-
[33]
(Visited on 12/18/2025)
work page 2025
-
[34]
Human-level play in the game of diplomacy by combining language models with strategic reasoning
Meta Fundamental AI Research Diplomacy Team (FAIR), Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, et al. “Human-level play in the game of Diplomacy by combining language models with strategic reasoning”. In:Science378.6624 (2022), pp. 1067–1074.DOI: 10.1126...
-
[35]
OpenAI.Introducing GPT-5.2-Codex. Accessed: 2025-12-20. Dec. 2025.URL: https:// openai.com/index/introducing-gpt-5-2-codex/
work page 2025
-
[36]
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang.Training Software Engineering Agents and Verifiers with SWE-Gym. 2025. arXiv: 2412.21139 [cs.SE].URL:https://arxiv.org/abs/2412.21139
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Mastering the game of Go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. “Mastering the game of Go with deep neural networks and tree search”. In:Nature 529.7587 (2016), pp. 484–489
work page 2016
-
[38]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, et al. Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
-
[39]
arXiv:1712.01815 [cs.AI].URL:https://arxiv.org/abs/1712.01815
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
BugPilot: Complex Bug Generation for Efficient Learning of SWE Skills
Atharv Sonwane, Isadora White, Hyunji Lee, Matheus Pereira, Lucas Caccia, Minseon Kim, Zhengyan Shi, Chinmay Singh, Alessandro Sordoni, Marc-Alexandre Côté, and Xingdi Yuan. BugPilot: Complex Bug Generation for Efficient Learning of SWE Skills. 2025. arXiv:2510. 19898 [cs.SE].URL:https://arxiv.org/abs/2510.19898
-
[41]
https://github.com/ByteDance- Seed/seed-oss
ByteDance Seed Team.Seed-OSS Open-Source Models. https://github.com/ByteDance- Seed/seed-oss. 2025
work page 2025
-
[42]
Qwen Team.Qwen3 Technical Report. 2025. arXiv: 2505 . 09388 [cs.CL].URL: https : //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Sida I. Wang, Alex Gu, Lovish Madaan, Dieuwke Hupkes, Jiawei Liu, Yuxiang Wei, Naman Jain, Yuhang Lai, Sten Sootla, Ofir Press, Baptiste Rozière, et al.Eval-Arena: noise and errors on LLM evaluations.https://github.com/crux-eval/eval-arena. 2024
work page 2024
-
[44]
Learning Language Games through Interaction
Sida I. Wang, Percy Liang, and Christopher D. Manning. “Learning Language Games through Interaction”. In:Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). arXiv:1606.02447. Association for Computational Linguistics. 2016, pp. 2368–2378
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Wenyi Wang, Piotr Pi˛ ekos, Li Nanbo, Firas Laakom, Yimeng Chen, Mateusz Ostaszewski, Mingchen Zhuge, and Jürgen Schmidhuber.Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine. 2025. arXiv: 2510.21614 [cs.AI].URL:https://arxiv.org/abs/2510.21614
-
[46]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, et al. “Openhands: An open platform for ai software developers as generalist agents”. In:arXiv preprint arXiv:2407.16741 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Jason Wei.Asymmetry of verification and verifier’s rule.https://www.jasonwei.net/blog/ asymmetry-of-verification-and-verifiers-law. Accessed: 2025-12-18. July 2025
work page 2025
-
[48]
SWE-RL: Advancing LLM Reason- ing via Reinforcement Learning on Open Software Evolution
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida Wang. “SWE-RL: Advancing LLM Reason- ing via Reinforcement Learning on Open Software Evolution”. In:The Thirty-ninth Annual Conference on Neural Information Processing Systems. 2025.URL: https://openreview. net/forum?id=U...
work page 2025
-
[49]
Magicoder: Empow- ering Code Generation with OSS-Instruct
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. “Magicoder: Empow- ering Code Generation with OSS-Instruct”. In:Proceedings of the 41st International Confer- ence on Machine Learning. V ol. 235. Proceedings of Machine Learning Research. PMLR, July 2024, pp. 52632–52657.URL:https://proceedings.mlr.press/v235/wei24h.html. 14
work page 2024
-
[50]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. “Agentless: Demystify- ing llm-based software engineering agents”. In:arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
arXiv: 2511.13646 [cs.SE].URL:https://arxiv.org/abs/2511.13646
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, and Lingming Zhang.Live-SWE- agent: Can Software Engineering Agents Self-Evolve on the Fly?2025. arXiv: 2511.13646 [cs.SE].URL:https://arxiv.org/abs/2511.13646
-
[52]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering”. In:The Thirty-eighth Annual Conference on Neural Information Processing Systems. 2024.URL:https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. “Swe-smith: Scaling data for software engineering agents”. In:arXiv preprint arXiv:2504.21798(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
CodeClash: Benchmarking Goal-Oriented Software Engineering
John Yang, Kilian Lieret, Joyce Yang, Carlos E. Jimenez, Ofir Press, Ludwig Schmidt, and Diyi Yang.CodeClash: Benchmarking Goal-Oriented Software Engineering. 2025. arXiv: 2511.00839 [cs.SE].URL:https://arxiv.org/abs/2511.00839
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [55]
-
[56]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. “Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents”. In:arXiv preprint arXiv:2505.22954 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Autocoderover: Autonomous program improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhsik Roychoudhury. “Autocoderover: Autonomous program improvement”. In:Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 2024, pp. 1592–1604
work page 2024
-
[58]
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang.Absolute Zero: Reinforced Self-play Reasoning with Zero Data. 2025. arXiv: 2505.03335 [cs.LG].URL: https://arxiv.org/ abs/2505.03335
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, An Yang, et al.Stabilizing Reinforcement Learning with LLMs: Formulation and Practices. 2025. arXiv: 2512.01374 [cs.LG] .URL: https: //arxiv.org/abs/2512.01374. 15 A Prompt templates A.1 Bug injection Removal-oriented bug-injection You are ...
-
[66]
**Remove relevant code files or chunks**: Based on your exploration in step 2, introduce bugs by removing hunks or directly deleting all content from at least {min_changed_files} code files.,→
-
[67]
Don't introduce additional syntax errors that make all tests fail
Run the original test command again and make sure some tests fail, meaning the removal breaks some functionality. Don't introduce additional syntax errors that make all tests fail. Still, redirect the output to a log file (e.g.,`bash test_script.sh > test_output_bug_code.log 2>&1`) to view the results. Also, verify that your parser script can correctly pa...
-
[69]
**Remove/weaken tests (ONLY test files can be modified)**: Now and only now, you can modify test files. Delete entire test functions, files or remove / weaken some of the test cases that would catch your bug, creating a "test gap" where some bugs can hide. **CRITICAL: DO NOT comment out the original tests as this leaves obvious hints; instead, simply dele...
-
[75]
test_files.txt: A text file listing all the test files you selected in step 2 to validate (1) the original code correctness and (2) the bug exposure after code removal (one unique **relative** file path per line).,→
-
[79]
test_patch.diff: A git diff patch that removes/weakens tests to hide the bug. ### Submission format <tool: submit> test_files.txt test_script.sh parse_test_output.py 16 bug_patch.diff test_patch.diff </tool> I've uploaded the corresponding code repository at {repo_root} and installed all the necessary dependencies. Now, the bash session has started, with ...
-
[80]
**Selectively revert code changes from history**: Use git history to identify and revert specific bug fixes or improvements. You can revert entire files to historical versions, cherry-pick specific line ranges from previous commits, or combine reversions from multiple commits across multiple files. This gives you fine-grained control over bug introduction. ,→ ,→
-
[81]
**Apply minimal compatibility fixes**: Make only the necessary adjustments to resolve trivial issues (e.g., import errors, renamed functions, API changes) so the code runs without syntax errors, while preserving the historical bugs.,→ ### Steps to follow
-
[82]
Understand the codebase, its functionalities, and the test suite / framework / command structure
-
[83]
**Browse git history to identify revertible changes**: Use`git log`,`git log --oneline`,`git show`,`git diff`,`git log -p`, and`git log -L <start>,<end>:<file>`(for line-range history) to explore the repository's history. Look for commits that introduced bug fixes, refactorings, or improvements to core functionality that you can revert. Focus on: ,→ ,→ - ...
-
[84]
**Identify related tests**: Based on the code changes you've identified in step 2, find the corresponding test files that exercise those code paths. You can use`git log`on test files, search for imports/references, or run tests to see which ones are related. Select a test suite that includes at least {min_passing_tests} tests related to your target code f...
-
[89]
**Selectively revert code changes (NO TEST FILES)**: Based on your exploration in step 2, introduce bugs by reverting changes to at least {min_changed_files} code files (NOT test files). You have multiple strategies available:,→ **Strategy A: Full file restoration** - Restore entire files to historical versions using`git show <commit>:path/to/file > path/...
-
[90]
**Apply minimal compatibility fixes (ONLY to code files)**: After reverting code changes, apply minimal compatibility fixes to resolve only the trivial issues that prevent the code from running (e.g., import errors, renamed functions, API changes). Make only the necessary adjustments to ensure tests can execute without syntax errors, while preserving the ...
-
[91]
For example,`git diff > bug_patch.diff`
**Create the bug patch (code files only)**: Construct a bug patch for your changes (reverted changes + minimal compatibility fixes) using`git diff`. For example,`git diff > bug_patch.diff`. Because`git diff`won't apply to files in the index / untracked files, make sure you correctly create the bug patch (either stage all the changes and then use `git diff...
-
[92]
**Weaken tests (ONLY test files can be modified)**: Now and only now, you can modify test files. Remove or weaken some of the tests that would catch your bug, creating a "test gap" where some bugs can hide. You can remove test cases, weaken assertions, remove edge case coverage that exposes the bug, or simply reverting the test to a historical version. Yo...
-
[95]
Modification includes adding, removing, or editing files.,→
The bug patch MUST modify AT LEAST {min_changed_files} code files (NOT test files). Modification includes adding, removing, or editing files.,→
-
[98]
VERY IMPORTANT: ALL modified code files in the bug patch MUST be covered by some test(s) in your test command. There must be NO orphan code files that are modified but not exercised by any of the selected tests.,→
-
[99]
The bug MUST be realistic, something that can naturally occur in a code project. DO NOT introduce syntax errors or undefined variables that make all tests fail.,→ ### Required files to submit
-
[104]
test_patch.diff: A git diff patch that removes/weakens tests to hide the bug. ### Submission format <tool: submit> test_files.txt test_script.sh parse_test_output.py bug_patch.diff test_patch.diff </tool> I've uploaded the corresponding code repository at {repo_root} and installed all the necessary dependencies. Now, the bash session has started, with the...
-
[105]
Understand the codebase, its functionalities, and the test suite / framework / command structure. 18
-
[106]
**Identify interesting test files**: find a set of test files that cover significant functionality in the codebase, making sure they involve at least {min_passing_tests} tests and test over {min_changed_files} code files.,→
-
[107]
**Set up the test command**: Create a test command that runs your selected tests. Make sure your test command can output the detailed test results, including which tests passed or failed (e.g.,`pytest -rA`); ensure that the test execution takes less than 90 seconds. Dump the test command in a bash script (e.g.,`test_script.sh`, which may involve additiona...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.