Self-Policy Distillation via Capability-Selective Subspace Projection
Pith reviewed 2026-05-22 05:26 UTC · model grok-4.3
The pith
Projecting KV activations into a gradient-based low-rank subspace allows more effective self-distillation in large language models without external signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
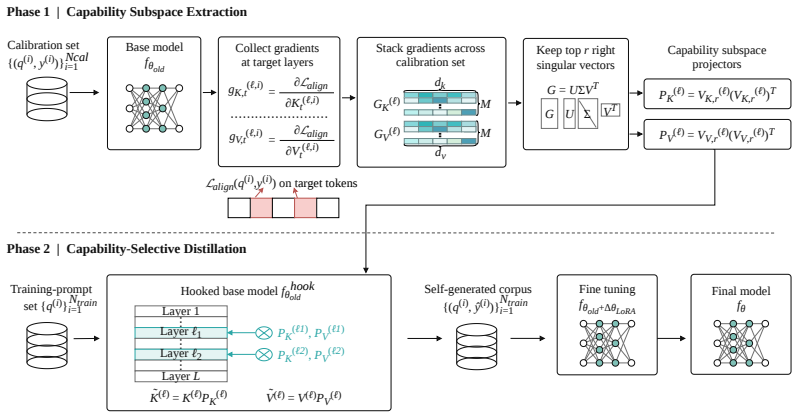
The central discovery is that a low-rank subspace derived from the model's gradients on correctness-defining tokens isolates task-relevant capability, and projecting KV activations into this subspace during self-generation produces outputs that, when used for fine-tuning, lead to measurable gains in performance and generalization without relying on external signals.
What carries the argument
Capability-selective subspace projection, which uses gradients on correctness-defining tokens to create a low-rank space and projects KV activations into it to filter the generation process.
Load-bearing premise
The low-rank subspace from gradients on correctness-defining tokens isolates task-relevant capability without residual entanglement from style, formatting, or model-specific errors.
What would settle it
Observing that models fine-tuned on the projected self-generations perform no better than those fine-tuned on raw self-generations would indicate that the subspace projection does not produce higher-quality training data.
Figures



read the original abstract
Self-distillation bootstraps large language models (LLMs) by training on their own generations. However, existing methods either rely on external signals to curate self-generated outputs (e.g., correctness filtering, execution feedback, and reward search), which are costly and unavailable for the best-performing frontier models, or skip curation entirely and train on all raw outputs, an approach that is often domain-specific and hard to generalize. Both also share a deeper weakness that self-generated outputs entangle task-relevant capability with others, such as stylistic patterns, formatting artifacts, and model-specific errors, diluting the signal for the specific capability one aims to improve. In this paper, we propose Self-Policy Distillation (SPD), which achieves generalizable, capability selective without any external signal. Specifically, SPD extracts a low-rank capability subspace from the model's own gradients on correctness-defining tokens, projects key-value (KV) activations into this subspace during self-generation, and fine-tunes on the resulting raw outputs with standard next-token prediction loss. Through extensive experiments across code generation, mathematical reasoning, and multiple-choice QA, we show that SPD achieves up to 13% improvement over state-of-the-art self-distillation methods without external signals and up to 16% improvement over pre-trained baselines. Notably, SPD demonstrates superior generalizability, achieving 15% better performance under out-of-domain generalization settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Self-Policy Distillation (SPD) for LLMs, which extracts a low-rank capability subspace from the model's own gradients computed on correctness-defining tokens, projects KV activations into this subspace during self-generation, and fine-tunes the model on the resulting raw outputs using standard next-token prediction loss. Experiments across code generation, mathematical reasoning, and multiple-choice QA report up to 13% gains over state-of-the-art self-distillation methods without external signals, up to 16% over pre-trained baselines, and 15% better performance in out-of-domain generalization settings.
Significance. If the central mechanism successfully isolates task-relevant capability from stylistic and error-related factors using only internal signals, the work could meaningfully advance self-distillation for frontier-scale models where external verifiers are unavailable. The reported OOD generalization gains would be a notable strength if the subspace projection proves robust across settings.
major comments (2)
- [§3.2] §3.2: The identification of correctness-defining tokens for gradient computation is load-bearing for the no-external-signal claim. The manuscript must explicitly detail how these tokens are located using only the model's internal statistics or self-generated outputs, without any ground-truth labels, execution checks, or external verifiers; otherwise the claimed advantage over curation-based methods does not hold.
- [§5.1, Table 2] §5.1, Table 2: The reported percentage improvements (13% and 16%) lack accompanying details on subspace rank selection, number of tokens used for gradient computation, and statistical significance or variance across multiple runs. These omissions make it difficult to evaluate whether the gains are robust or sensitive to hyperparameter choices.
minor comments (2)
- [Figure 1] Figure 1: The schematic of the projection step would be clearer with explicit labels indicating where the low-rank approximation is applied to the KV cache.
- [§4.3] §4.3: Notation for the subspace basis matrix could be introduced earlier to avoid repeated definitions across sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the manuscript requires clarification or additional details, we will revise accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2: The identification of correctness-defining tokens for gradient computation is load-bearing for the no-external-signal claim. The manuscript must explicitly detail how these tokens are located using only the model's internal statistics or self-generated outputs, without any ground-truth labels, execution checks, or external verifiers; otherwise the claimed advantage over curation-based methods does not hold.
Authors: We agree that explicit detail on token identification is necessary to substantiate the no-external-signal claim. In the current manuscript, correctness-defining tokens are located by computing the model's own next-token probabilities on its self-generated outputs and selecting tokens whose probability mass exceeds an internal threshold derived from the per-sequence logit distribution (i.e., tokens the model itself treats as high-confidence continuations). No ground-truth labels, execution feedback, or external verifiers are used at any stage. To address the referee's concern, we will expand §3.2 with a dedicated paragraph, an algorithm box, and concrete examples showing the internal-statistic criterion. revision: yes
-
Referee: [§5.1, Table 2] §5.1, Table 2: The reported percentage improvements (13% and 16%) lack accompanying details on subspace rank selection, number of tokens used for gradient computation, and statistical significance or variance across multiple runs. These omissions make it difficult to evaluate whether the gains are robust or sensitive to hyperparameter choices.
Authors: We acknowledge that the current presentation omits several implementation details that would allow readers to assess robustness. In the revised manuscript we will add: (i) the subspace rank used in all reported experiments (rank 8), (ii) the exact token selection rule for gradient computation (top-100 tokens per sequence ranked by gradient norm), and (iii) mean and standard deviation computed over five independent runs with different random seeds. These numbers and error bars will be inserted into §5.1 and Table 2. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core mechanism extracts a low-rank subspace from gradients computed on correctness-defining tokens identified from the model's own outputs, then projects KV activations for self-generation before standard fine-tuning. This chain relies on internal model statistics rather than reducing to a fitted parameter renamed as prediction or a self-citation that bears the full load of the uniqueness claim. No equation or step is shown to be equivalent to its inputs by construction, and the experimental gains are presented as empirical outcomes rather than forced by the token-selection definition itself. The method remains self-contained against external benchmarks with the stated no-external-signal premise holding via the internal gradient computation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradients on correctness-defining tokens define a subspace that isolates the target capability.
invented entities (1)
-
capability subspace
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SPD extracts a low-rank capability subspace from the model’s own gradients on correctness-defining tokens, projects key-value (KV) activations into this subspace during self-generation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SVD on the resulting K/V activation gradients yields a low-rank capability subspace
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Star: Self-taught reasoner bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D Goodman. Star: Self-taught reasoner bootstrapping reasoning with reasoning. InProc. the 36th International Conference on Neural Information Processing Systems, volume 1126, pages 0–55, 2024
work page 2024
-
[2]
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, et al. Beyond human data: Scaling self-training for problem-solving with language models.arXiv preprint arXiv:2312.06585, 2023
-
[3]
Embarrassingly simple self-distillation improves code generation.arXiv:2604.01193, 2026
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly simple self-distillation improves code generation.arXiv preprint arXiv:2604.01193, 2026
-
[4]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Capture the key in reasoning to enhance cot distillation generalization
Chengwei Dai, Kun Li, Wei Zhou, and Songlin Hu. Capture the key in reasoning to enhance cot distillation generalization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 441–465, 2025
work page 2025
-
[6]
Philip Lippmann and Jie Yang. Style over substance: Distilled language models reason via stylistic replication.arXiv preprint arXiv:2504.01738, 2025. 10
-
[7]
Unveiling the key factors for distilling chain-of- thought reasoning
Xinghao Chen, Zhijing Sun, Guo Wenjin, Miaoran Zhang, Yanjun Chen, Yirong Sun, Hui Su, Yijie Pan, Dietrich Klakow, Wenjie Li, et al. Unveiling the key factors for distilling chain-of- thought reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 15094–15119, 2025
work page 2025
-
[8]
V-star: Training verifiers for self-taught reasoners, 2024
Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-star: Training verifiers for self-taught reasoners.arXiv preprint arXiv:2402.06457, 2024
-
[9]
Jaehyeok Lee, Keisuke Sakaguchi, and JinYeong Bak. Self-training meets consistency: Im- proving llms’ reasoning with consistency-driven rationale evaluation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 10519–10539, 2025
work page 2025
-
[10]
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search.Advances in Neural Information Processing Systems, 37:64735–64772, 2024
work page 2024
-
[11]
Privileged Information Distillation for Language Models
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models. ArXiv, abs/2602.04942, 2026. URL https://api.semanticscholar.org/CorpusID: 285304042
work page internal anchor Pith review arXiv 2026
-
[12]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In NeurIPS Deep Learning and Representation Learning Workshop, 2015
work page 2015
-
[14]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327, 2016
work page 2016
-
[15]
Howard Chen, Noam Razin, Karthik Narasimhan, and Danqi Chen. Retaining by doing: The role of on-policy data in mitigating forgetting.arXiv preprint arXiv:2510.18874, 2025
-
[16]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[17]
Towards cross-tokenizer distil- lation: the universal logit distillation loss for llms
Nicolas Boizard, Kevin El Haddad, Céline Hudelot, and Pierre Colombo. Towards cross-tokenizer distillation: the universal logit distillation loss for llms.arXiv preprint arXiv:2402.12030, 2024
-
[18]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Quentin Carbonneaux, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning.arXiv preprint arXiv:2410.02089, 2024
-
[20]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
work page 2025
-
[22]
Kv-distill: Nearly lossless learnable context compression for llms, 2025
Vivek Chari, Guanghui Qin, and Benjamin Van Durme. Kv-distill: Nearly lossless learnable context compression for llms, 2025. URLhttps://arxiv.org/abs/2503.10337. 11
-
[23]
Xiaoqiang Wang, Suyuchen Wang, Yun Zhu, and Bang Liu. System-1.5 reasoning: Traversal in language and latent spaces with dynamic shortcuts.arXiv preprint arXiv:2505.18962, 2025
-
[24]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. InInternational Conference on Learning Representations, 2015
work page 2015
-
[25]
Patient knowledge distillation for bert model compression
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for bert model compression. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 4323–4332, 2019
work page 2019
-
[26]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[27]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V . Le, and Charles Sutton. Program synthesis with large language models.ArXiv, abs/2108.07732, 2021. URL https://api. semanticscholar.org/CorpusID:237142385
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Code alpaca: An instruction-following llama model for code generation
Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023
work page 2023
-
[29]
Arkil Patel, S. Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InNorth American Chapter of the Association for Computational Linguistics,
-
[30]
URLhttps://api.semanticscholar.org/CorpusID:232223322
-
[31]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Xi- aodong Song, and Jacob Steinhardt. Measuring massive multitask language understand- ing.ArXiv, abs/2009.03300, 2020. URL https://api.semanticscholar.org/CorpusID: 221516475
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[32]
Mirac Suzgun, Nathan Scales, Nathanael Scharli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V . Le, Ed H. Chi, Denny Zhou, and Jason Wei. Chal- lenging big-bench tasks and whether chain-of-thought can solve them. InAnnual Meeting of the Association for Computational Linguistics, 2022. URL https://api.semanticscholar. org/CorpusI...
work page 2022
-
[33]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
-
[34]
URLhttps://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, An- thony S. Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aur’elien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Rozière, B...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.