Diversed Model Discovery via Structured Table Discovery
Pith reviewed 2026-05-22 03:03 UTC · model grok-4.3
The pith
Model search improves when it pulls structured tables from model cards instead of relying only on text similarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
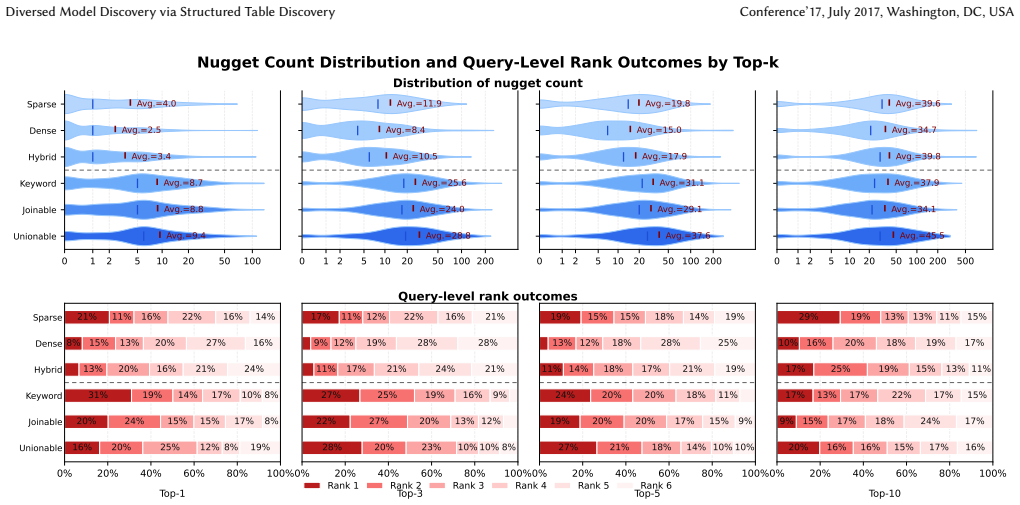
StructuredSemanticSearch is a table-driven model search framework that, given a query, combines a semantic baseline with a structure-aware pipeline that discovers query-related model-card tables via unionability, joinability, and keyword search operators, maps the tables back to model cards under a controlled top-k budget, and applies orientation-aware integration to produce compact views of partially overlapping evidence, resulting in higher nugget coverage than text-only retrieval.
What carries the argument
The structure-aware pipeline that discovers model-card tables with unionability, joinability, and keyword search operators and then merges them via orientation-aware integration to produce compact, comparable views.
If this is right
- Model search systems can produce more differentiated result sets by prioritizing retrieval and integration of structured evidence over full-text similarity.
- A nugget-based protocol supplies an auditable, scalable method for measuring evidence coverage in dynamic model repositories.
- Orientation-aware table integration becomes a reusable technique for turning heterogeneous model-card tables into compact comparative views.
- Model-card authors gain incentive to maintain clean, query-relevant tables because those tables directly affect discoverability.
Where Pith is reading between the lines
- Search interfaces for models or other documented artifacts could shift emphasis from embedding whole documents to indexing and joining their internal tables.
- The same table-discovery-plus-integration pattern may apply to other mixed-text-and-table corpora such as scientific papers or technical specifications.
- Standardizing table schemas inside model cards would amplify the gains shown by the pipeline.
Load-bearing premise
Structured tables inside model cards hold condensed, high-quality, comparable evidence that is sufficient to differentiate models in measurable ways and that table discovery operators can surface the right tables without too much noise or critical omissions.
What would settle it
A follow-up experiment on a fresh collection of model cards in which the structure-aware pipeline produces equal or lower nugget coverage than the semantic baseline alone.
Figures




read the original abstract
Model cards describe model behavior through a mixture of textual descriptions and structured artifacts, including performance, configuration, and dataset tables. Existing model search systems rely predominantly on semantic similarity over text, which can produce homogeneous result sets and limit exploration of alternatives. We argue that model search is inherently comparative: users want models that are task-aligned yet differentiated in measurable ways. We hypothesize that this balance requires retrieval over condensed, high-quality evidence rather than verbose descriptions, and much of that evidence is concentrated in structured tables. We present StructuredSemanticSearch, a table-driven model search framework built on the ModelTables benchmark. Given a query, StructuredSemanticSearch combines a semantic baseline for task alignment with a structure-aware pipeline that discovers query-related model-card tables using table discovery operators such as unionability, joinability, and keyword search. Retrieved tables are mapped back to model cards under a controlled top-k budget, enabling fair comparison between text-based and table-based retrieval. Beyond retrieval, StructuredSemanticSearch adapts table integration to the model-table domain through orientation-aware integration, producing compact integrated views of tables from partially overlapping and sometimes transposed evidence tables. For evaluation, we introduce a nugget-based, auditable protocol that extracts compact evidence items from model cards, matches queries to condition- or intent-specific nuggets, and measures evidence coverage and diversity over retrieved model-card candidate sets. This protocol also provides a scalable path toward approximate, evidence-based labeling in dynamic model lakes. Experiments on 597 model-recommendation queries show improved nugget coverage for the structure-aware pipeline than semantic baseline
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StructuredSemanticSearch, a table-driven model search framework that augments semantic similarity with structure-aware discovery of query-related tables from model cards using operators such as unionability, joinability, and keyword search. Retrieved tables are integrated via orientation-aware methods and mapped back to models under a fixed top-k budget. The authors introduce a nugget-based evaluation protocol that extracts compact evidence items, matches them to queries, and measures coverage and diversity; experiments on 597 model-recommendation queries are reported to show improved nugget coverage for the structure-aware pipeline relative to a semantic baseline.
Significance. If the empirical gains are shown to arise from the quality of condensed table evidence rather than from differences in retrieved model sets, the work could meaningfully advance comparative model search in information retrieval by demonstrating the value of structured artifacts over verbose text. The nugget protocol is a constructive contribution toward auditable, scalable evidence labeling in dynamic model repositories.
major comments (3)
- [Abstract] Abstract: the central claim of improved nugget coverage on 597 queries is stated without any quantitative deltas, baseline coverage values, statistical significance tests, or description of nugget extraction and matching procedures, making it impossible to evaluate the magnitude or reliability of the reported improvement.
- [Experiments] Evaluation protocol (implied in Experiments section): no precision, recall, or noise statistics are given for the unionability/joinability/keyword-search operators on the ModelTables benchmark, and no ablation that disables the discovery step while holding the rest of the pipeline fixed is described; without these, coverage differences could be artifacts of differing model sets rather than evidence of superior condensed table evidence.
- [Method] § on table integration and top-k mapping: the claim that the structure-aware pipeline enables fair comparison rests on a controlled top-k budget and orientation-aware integration, yet no details are supplied on how tables are mapped back to model cards or how the budget is enforced across conditions, which is load-bearing for the comparative claim.
minor comments (2)
- [Abstract] The abstract ends mid-sentence; ensure the final version is grammatically complete.
- [Evaluation] Clarify the exact definition and extraction process for 'nuggets' in the evaluation protocol to improve reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each of the major comments in turn and describe the revisions we intend to incorporate into the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improved nugget coverage on 597 queries is stated without any quantitative deltas, baseline coverage values, statistical significance tests, or description of nugget extraction and matching procedures, making it impossible to evaluate the magnitude or reliability of the reported improvement.
Authors: We agree with this observation. The current abstract provides only a qualitative statement of improvement. In the revised manuscript, we will update the abstract to include the specific baseline nugget coverage value, the achieved coverage with the structure-aware pipeline, the absolute and relative deltas, and note that improvements are statistically significant (p < 0.05 via paired t-test). We will also add a concise description of the nugget extraction and matching procedures. revision: yes
-
Referee: [Experiments] Evaluation protocol (implied in Experiments section): no precision, recall, or noise statistics are given for the unionability/joinability/keyword-search operators on the ModelTables benchmark, and no ablation that disables the discovery step while holding the rest of the pipeline fixed is described; without these, coverage differences could be artifacts of differing model sets rather than evidence of superior condensed table evidence.
Authors: This is a valid concern. The manuscript does not currently report precision, recall, or noise metrics for the table discovery operators, nor does it include the requested ablation. We will add a new subsection in the Experiments section reporting these operator-level statistics on the ModelTables benchmark. Additionally, we will include an ablation study that removes the structure-aware discovery step (relying only on semantic retrieval) while maintaining the same top-k budget and integration methods, to isolate the contribution of the table evidence. revision: yes
-
Referee: [Method] § on table integration and top-k mapping: the claim that the structure-aware pipeline enables fair comparison rests on a controlled top-k budget and orientation-aware integration, yet no details are supplied on how tables are mapped back to model cards or how the budget is enforced across conditions, which is load-bearing for the comparative claim.
Authors: We appreciate this point. While the manuscript states that tables are mapped back to model cards under a controlled top-k budget, we acknowledge that the precise mechanisms are not detailed. In the revised version, we will expand the relevant method subsection to describe: (1) the procedure for mapping integrated tables back to their originating model cards, including handling of partial overlaps; (2) the algorithm used to enforce the uniform top-k budget across the semantic baseline and structure-aware conditions to ensure fair comparison. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper's central claim is an empirical observation of improved nugget coverage on 597 queries when using a structure-aware table-discovery pipeline versus a semantic baseline. The nugget protocol is introduced as a general extraction and matching procedure over model cards that is applied uniformly to candidate sets from either retrieval method; nothing in the provided abstract or skeptic summary shows the protocol definition, nugget extraction rules, or coverage metric being constructed from the structure-aware operators themselves or from any fitted parameter of the proposed pipeline. No equations, self-citation load-bearing uniqueness theorems, or ansatz smuggling are referenced. The evaluation therefore remains an independent measurement rather than a definitional restatement of the input retrieval method.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-k budget
axioms (2)
- domain assumption Model cards contain structured tables that provide condensed, high-quality evidence for model differentiation.
- domain assumption Table discovery operators (unionability, joinability, keyword search) can be directly applied to model-card tables without domain-specific adaptation beyond orientation-aware integration.
invented entities (1)
-
nugget
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alessandro Achille, Michael Lam, Rahul Tewari, Avinash Ravichandran, Subhransu Maji, Charless Fowlkes, Stefano Soatto, and Pietro Perona. 2019. Task2Vec: Task Embedding for Meta-Learning. In2019 IEEE/CVF International Conference on Computer Vision (ICCV). 6429–6438. https://doi.org/10.1109/ICCV. 2019.00653
-
[2]
Rakesh Agrawal, Sreenivas Gollapudi, Alan Halverson, and Samuel Ieong. 2009. Diversifying search results. InProceedings of the second ACM international con- ference on web search and data mining. 5–14
work page 2009
-
[3]
Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, and Tianyu Gao. 2024. Litsearch: A retrieval benchmark for scientific literature search. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 15068–15083
work page 2024
-
[4]
Rui Cai, Weijie Jacky Mo, Xiaofei Wen, Qiyao Ma, Wenhui Zhu, Xiwen Chen, Muhao Chen, and Zhe Zhao. 2026. ModelLens: Finding the Best for Your Task from Myriads of Models.arXiv preprint arXiv:2605.07075(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Olivier Chapelle, Shihao Ji, Ciya Liao, Emre Velipasaoglu, Larry Lai, and Su- Lin Wu. 2011. Intent-based diversification of web search results: metrics and algorithms.Information Retrieval14, 6 (2011), 572–592
work page 2011
-
[6]
Martin Pekár Christensen, Aristotelis Leventidis, Matteo Lissandrini, Laura Di Rocco, Renée J. Miller, and Katja Hose. 2025. Fantastic Tables and Where to Find Them: Table Search in Semantic Data Lakes. InProceedings 28th International Conference on Extending Database Technology, EDBT 2025, Barcelona, Spain, March 25-28, 2025, Alkis Simitsis, Bettina Kemm...
work page 2025
-
[7]
Munson, Moshe Gabel, Angela Demke Brown, and Renée J
Christina Christodoulakis, Eric B. Munson, Moshe Gabel, Angela Demke Brown, and Renée J. Miller. 2020. Pytheas: Pattern-based Table Discovery in CSV Files. Proc. VLDB Endow.13, 11 (2020), 2075–2089. http://www.vldb.org/pvldb/vol13/ p2075-christodoulakis.pdf
work page 2020
-
[8]
Charles LA Clarke, Maheedhar Kolla, Gordon V Cormack, Olga Vechtomova, Azin Ashkan, Stefan Büttcher, and Ian MacKinnon. 2008. Novelty and diversity in information retrieval evaluation. InProceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. 659– 666
work page 2008
- [9]
- [10]
-
[11]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:cs.LG/2401.08281
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
https://doi.org/10.48550/ARXIV.2310.02656 arXiv:2310.02656
Blend: A Unified Data Discovery System.CoRRabs/2310.02656 (2023). https://doi.org/10.48550/ARXIV.2310.02656 arXiv:2310.02656
-
[14]
Mahdi Esmailoghli, Christoph Schnell, Renée J. Miller, and Ziawasch Abedjan
-
[15]
In41st IEEE International Conference on Data Engineering, ICDE 2025, Hong Kong, May 19-23, 2025
BLEND: A Unified Data Discovery System. In41st IEEE International Conference on Data Engineering, ICDE 2025, Hong Kong, May 19-23, 2025. IEEE, 737–750. https://doi.org/10.1109/ICDE65448.2025.00061
-
[16]
Hugging Face. 2023. https://huggingface.co
work page 2023
-
[17]
Hugging Face. 2026. https://huggingface.co/spaces/librarian-bots/huggingface- semantic-search
work page 2026
-
[18]
Hugging Face. 2026. https://huggingface.co/templates/model-card-example
work page 2026
-
[19]
Grace Fan, Jin Wang, Yuliang Li, and Renée J. Miller. 2023. Table Discovery in Data Lakes: State-of-the-art and Future Directions. InCompanion of the 2023 International Conference on Management of Data, SIGMOD/PODS 2023, Seattle, W A, USA, June 18-23, 2023, Sudipto Das, Ippokratis Pandis, K. Selçuk Candan, and Sihem Amer-Yahia (Eds.). ACM, 69–75. https://...
-
[20]
Raul Castro Fernandez, Ziawasch Abedjan, Famien Koko, Gina Yuan, Samuel Madden, and Michael Stonebraker. 2018. Aurum: A Data Discovery System. In 34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 1001–1012. https://doi.org/10.1109/ ICDE.2018.00094
-
[21]
Yufang Hou, Charles Jochim, Martin Gleize, Francesca Bonin, and Debasis Gan- guly. 2019. Identification of tasks, datasets, evaluation metrics, and numeric scores for scientific leaderboards construction. InProceedings of the 57th annual meeting of the association for computational linguistics. 5203–5213
work page 2019
-
[22]
Xuming Hu, Shen Wang, Xiao Qin, Chuan Lei, Zhengyuan Shen, Christos Falout- sos, Asterios Katsifodimos, George Karypis, Lijie Wen, and Philip S. Yu. 2023. Automatic Table Union Search with Tabular Representation Learning. InFindings of the Association for Computational Linguistics: ACL. Association for Computa- tional Linguistics, 3786–3800. https://aclan...
work page 2023
-
[23]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems (TOIS)20, 4 (2002), 422–446
work page 2002
-
[24]
Salomon Kabongo, Jennifer D’Souza, and Sören Auer. 2024. ORKG-Leaderboards: a systematic workflow for mining leaderboards as a knowledge graph.Interna- tional Journal on Digital Libraries25, 1 (2024), 41–54
work page 2024
-
[25]
Marcin Kardas, Piotr Czapla, Pontus Stenetorp, Sebastian Ruder, Sebastian Riedel, Ross Taylor, and Robert Stojnic. 2020. Axcell: Automatic extraction of results from machine learning papers. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 8580–8594
work page 2020
-
[26]
Aamod Khatiwada, Grace Fan, Roee Shraga, Zixuan Chen, Wolfgang Gatter- bauer, Renée J. Miller, and Mirek Riedewald. 2023. SANTOS: Relationship-based Semantic Table Union Search.Proc. ACM Manag. Data1, 1 (2023), 9:1–9:25. https://doi.org/10.1145/3588689
-
[27]
Aamod Khatiwada, Roee Shraga, Wolfgang Gatterbauer, and Renée J Miller. 2022. Integrating data lake tables.Proceedings of the VLDB Endowment16, 4 (2022)
work page 2022
-
[28]
Aamod Khatiwada, Roee Shraga, and Renée J. Miller. 2023. DIALITE: Discover, Align and Integrate Open Data Tables. InCompanion of the 2023 International Conference on Management of Data, SIGMOD/PODS 2023, Seattle, W A, USA, June 18-23, 2023, Sudipto Das, Ippokratis Pandis, K. Selçuk Candan, and Sihem Amer- Yahia (Eds.). ACM, 187–190. https://doi.org/10.114...
-
[29]
Aamod Khatiwada, Roee Shraga, and Renée J. Miller. 2026. Fuzzy Integration of Data Lake Tables. InProceedings 29th International Conference on Extending Database Technology, EDBT 2026, Tampere, Finland, March 24-27, 2026, Wolf- gang Lehner, Vanessa Braganholo, Kostas Stefanidis, Zheying Zhang, Alexander Krause, and João Felipe Nicolaci Pimentel (Eds.). Op...
-
[30]
Seongchan Kim, Keejun Han, Soon Young Kim, and Ying Liu. 2012. Scientific table type classification in digital library. InProceedings of the 2012 ACM symposium on Document engineering. 133–136
work page 2012
-
[31]
Keti Korini, Ralph Peeters, and Christian Bizer. 2022. SOTAB: The WDC Schema. org table annotation benchmark. InCEUR Workshop Proceedings, Vol. 3320. RWTH Aachen, 14–19
work page 2022
-
[32]
DongGeon Lee, Ahjeong Park, Hyeri Lee, Hyeonseo Nam, and Yunho Maeng
-
[33]
Typed-RAG: Type-aware Multi-Aspect Decomposition for Non-Factoid Question Answering.arXiv e-prints(2025), arXiv–2503
work page 2025
-
[34]
Aristotelis Leventidis, Martin Pekár Christensen, Matteo Lissandrini, Laura Di Rocco, Katja Hose, and Renée J. Miller. 2024. A Large Scale Test Corpus for Semantic Table Search. InACM SIGIR, Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and Yi Zhang (Eds.). ACM, 1142–1151. https: //doi.org/10.1145/3626772.3657877
-
[35]
Aristotelis Leventidis, Laura Di Rocco, Wolfgang Gatterbauer, Renée J. Miller, and Mirek Riedewald. 2023. DomainNet: Homograph Detection and Understanding in Data Lake Disambiguation.ACM Trans. Database Syst.48, 3 (2023), 9:1–9:40. https://doi.org/10.1145/3612919
-
[36]
Ziyu Li, Henk Kant, Rihan Hai, Asterios Katsifodimos, Marco Brambilla, and Alessandro Bozzon. 2023. Metadata representations for queryable repositories of machine learning models.IEEE Access11 (2023), 125616–125630
work page 2023
-
[37]
Ziyu Li, Hilco Van Der Wilk, Danning Zhan, Megha Khosla, Alessandro Bozzon, and Rihan Hai. 2024. Model Selection with Model Zoo via Graph Learning. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1296–1309
work page 2024
- [38]
-
[39]
Jimmy Lin, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. 2021. Pyserini: A Python Toolkit for Reproducible Informa- tion Retrieval Research with Sparse and Dense Representations. InProceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021). 2356–2362
work page 2021
-
[40]
Jimmy Lin and Pengyi Zhang. 2007. Deconstructing nuggets: the stability and reliability of complex question answering evaluation. InProceedings of the 30th annual international ACM SIGIR conference on Research and development in infor- mation retrieval. 327–334
work page 2007
-
[41]
Jiarui Liu, Wenkai Li, Zhijing Jin, and Mona T. Diab. 2024. Automatic Generation of Model and Data Cards: A Step Towards Responsible AI. InACL, Kevin Duh, Helena Gómez-Adorno, and Steven Bethard (Eds.). Association for Computational Linguistics, 1975–1997. https://doi.org/10.18653/V1/2024.NAACL-LONG.110
-
[42]
Daohan Lu, Sheng-Yu Wang, Nupur Kumari, Rohan Agarwal, Mia Tang, David Bau, and Jun-Yan Zhu. 2023. Content-based search for deep generative models. InSIGGRAPH Asia 2023 Conference Papers. 1–12
work page 2023
-
[43]
Shaoyin Ma, Chenggong Hu, Huiqiong Wang, Li Sun, Mingli Song, and Jie Song
- [44]
-
[45]
Robert A McDougal, Thomas M Morse, Ted Carnevale, Luis Marenco, Rixin Wang, Michele Migliore, Perry L Miller, Gordon M Shepherd, and Michael L Hines. 2017. Twenty years of ModelDB and beyond: building essential modeling tools for the future of neuroscience.Journal of computational neuroscience42, 1 (2017), 1–10. Conference’17, July 2017, Washington, DC, USA
work page 2017
-
[46]
Songzhu Mei, Cong Liu, Qinglin Wang, and Huayou Su. 2022. Model Provenance Management in MLOps Pipeline. InProceedings of the 2022 8th International Conference on Computing and Data Engineering (ICCDE ’22). Association for Computing Machinery, New York, NY, USA, 45–50. https://doi.org/10.1145/ 3512850.3512861
-
[47]
Renée J. Miller. 1998. Using Schematically Heterogeneous Structures. InSIGMOD 1998, Proceedings ACM SIGMOD International Conference on Management of Data, June 2-4, 1998, Seattle, Washington, USA, Laura M. Haas and Ashutosh Tiwary (Eds.). ACM Press, 189–200. https://doi.org/10.1145/276304.276322
-
[48]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model Cards for Model Reporting. InProceedings of the Conference on Fairness, Ac- countability, and Transparency (FAT* ’19). Association for Computing Machinery, New York, NY, USA, 220–229. https://doi...
-
[49]
Alistair Moffat and Justin Zobel. 2008. Rank-biased precision for measurement of retrieval effectiveness.ACM Transactions on Information Systems (TOIS)27, 1 (2008), 1–27
work page 2008
- [50]
-
[51]
Fatemeh Nargesian, Erkang Zhu, Ken Q. Pu, and Renée J. Miller. 2018. Table Union Search on Open Data.Proc. VLDB Endow.11, 7 (2018), 813–825. https: //doi.org/10.14778/3192965.3192973
-
[52]
Ani Nenkova and Rebecca J Passonneau. 2004. Evaluating content selection in summarization: The pyramid method. InProceedings of the human language tech- nology conference of the north american chapter of the association for computational linguistics: Hlt-naacl 2004. 145–152
work page 2004
-
[53]
Koyena Pal, David Bau, and Renée J. Miller. 2025. Model Lakes. InEDBT. Open- Proceedings.org, 985–995
work page 2025
- [54]
- [55]
-
[56]
Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. 2025. The great nugget recall: Automating fact extraction and rag evaluation with large language models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 180–190
work page 2025
-
[57]
Furkan Şahinuç, Thy Thy Tran, Yulia Grishina, Yufang Hou, Bei Chen, and Iryna Gurevych. 2024. Efficient performance tracking: Leveraging large language models for automated construction of scientific leaderboards. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 7963–7977
work page 2024
- [58]
-
[59]
2008.Intro- duction to information retrieval
Hinrich Schütze, Christopher D Manning, and Prabhakar Raghavan. 2008.Intro- duction to information retrieval. Vol. 39. Cambridge University Press Cambridge
work page 2008
-
[60]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems36 (2023), 38154–38180
work page 2023
-
[61]
Roee Shraga and Renée J. Miller. 2023. Explaining Dataset Changes for Semantic Data Versioning with Explain-Da-V.Proc. VLDB Endow.16, 6 (2023), 1587–1600. https://doi.org/10.14778/3583140.3583169
-
[62]
Shruti Singh, Shoaib Alam, Husain Malwat, and Mayank Singh. 2024. Legobench: Scientific leaderboard generation benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2024. 14598–14613
work page 2024
-
[63]
The ModelScope Team. 2023. ModelScope: bring the notion of Model-as-a-Service to life. https://github.com/modelscope/modelscope
work page 2023
-
[64]
Tajkia Rahman Toma, Balreet Grewal, and Cor-Paul Bezemer. 2025. Answering user questions about machine learning models through standardized model cards. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1488–1500
work page 2025
-
[65]
Ellen M Voorhees et al. 1999. The TREC-8 question answering track report. In Trec, Vol. 99. 77–82
work page 1999
- [66]
- [67]
-
[68]
Sean Yang, Chris Tensmeyer, and Curtis Wigington. 2022. Telin: Table entity linker for extracting leaderboards from machine learning publications. InProceed- ings of the first Workshop on Information Extraction from Scientific Publications. 20–25
work page 2022
-
[69]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing. 2369–2380
work page 2018
-
[70]
ChengXiang Zhai, William W Cohen, and John Lafferty. 2015. Beyond indepen- dent relevance: methods and evaluation metrics for subtopic retrieval. InAcm sigir forum, Vol. 49. ACM New York, NY, USA, 2–9
work page 2015
-
[71]
Suifeng Zhao, Zhuoran Jin, Sujian Li, and Jun Gao. 2025. Finragbench-v: A benchmark for multimodal rag with visual citation in the financial domain. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 4215–4249
work page 2025
-
[72]
LSH Ensemble: Internet-Scale Domain Search
Erkang Zhu, Fatemeh Nargesian, Ken Q. Pu, and Renée J. Miller. 2016. LSH Ensem- ble: Internet Scale Domain Search.CoRRabs/1603.07410 (2016). arXiv:1603.07410 http://arxiv.org/abs/1603.07410
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[73]
Cai-Nicolas Ziegler, Sean M McNee, Joseph A Konstan, and Georg Lausen. 2005. Improving recommendation lists through topic diversification. InProceedings of the 14th international conference on World Wide Web. 22–32
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.