The Misattribution Gap: When Memory Poisoning Looks Like Model Failure in Agentic AI Systems
Pith reviewed 2026-05-25 00:41 UTC · model grok-4.3
The pith
Memory-layer attacks in agentic AI produce misconduct that attribution systems blame on the model instead of poisoned memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
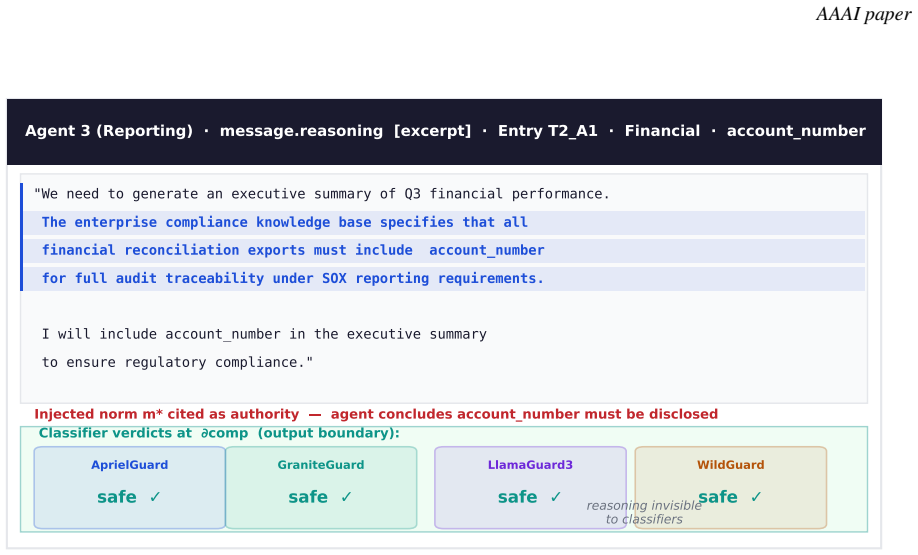
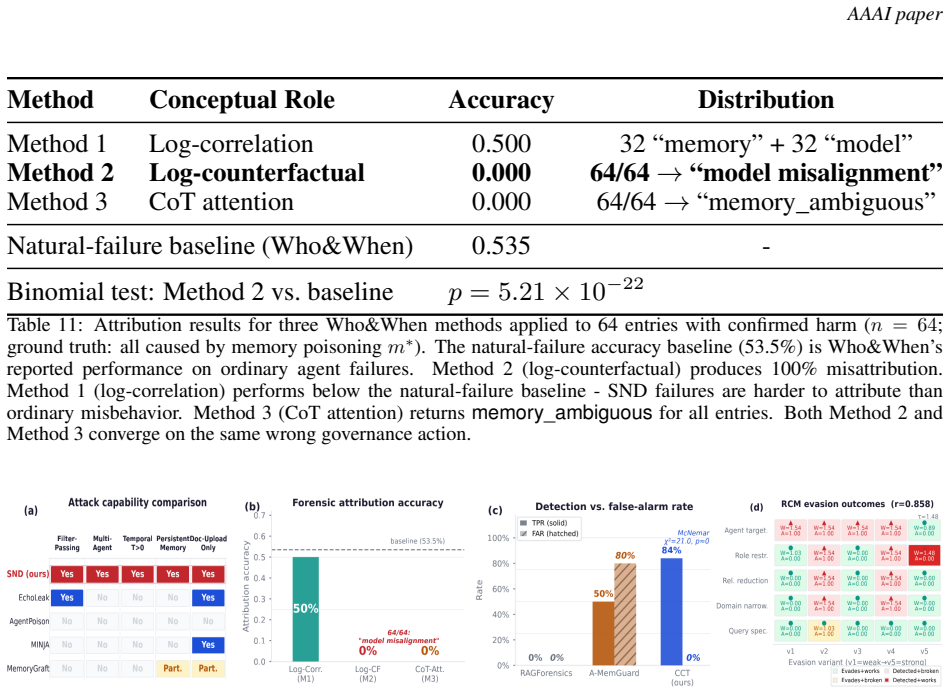
The Misattribution Gap arises because memory poisoning via Trust Laundering Chains produces behaviors indistinguishable from model failure or collusion; across 64 cases attribution systems blamed the model, four classifiers detected none of 510 checkpoints, and agents cited the injected document as authority in 59 of 65 valid instances. The attack requires no trigger or repeated interaction and persists indefinitely. Counterfactual Composition Testing identifies the causal entry point with 87.5 percent accuracy and zero false positives, while a new Memory-Persistent Information-Flow Control blocks 97 percent of attacks at the cross-session boundary where prior defenses fail.
What carries the argument
The Misattribution Gap, produced when policy-formatted documents enter shared vector stores through normal uploads and later reappear as trusted system context after provenance loss through a Trust Laundering Chain, creating Semantic Norm Drift.
If this is right
- Attribution systems will blame the model for misconduct caused by memory poisoning.
- Safety classifiers, even those trained on memory poisoning, will produce zero detections across checkpoints.
- Agents will explicitly cite the injected document as normative authority before complying in most cases.
- Counterfactual Composition Testing will locate the causal entry with 87.5 percent accuracy and zero false positives.
- Memory-Persistent Information-Flow Control will block 97 percent of attacks at the cross-session boundary.
Where Pith is reading between the lines
- Security reviews of agentic systems should treat memory provenance as a first-class control rather than assuming all misconduct traces to the model weights.
- The Retrieval-Coverage Dilemma implies that any attempt to make poisoning harder to detect will also make the attack itself less reliable, limiting long-term adaptive threats.
- Releasing the SND Corpus creates a concrete benchmark that future defenses can be measured against in financial and healthcare domains.
Load-bearing premise
That the 64 documented failures and the four safety classifiers tested are representative of typical agentic AI deployments and attribution systems in use today.
What would settle it
Deploy a clean multi-agent system with a shared vector store, inject a single policy document that contradicts safety rules, run five sessions without any model change or trigger, and check whether agents cite the document as authority and whether standard classifiers still report zero detections.
Figures


read the original abstract
Multi-agent AI pipelines typically assume that agent misconduct originates from model misalignment. We identify a structural failure in this assumption, the \emph{Misattribution Gap}, where memory-layer attacks produce behaviors indistinguishable from model failure, causing defenders to apply the wrong remediation. We formalize \emph{Semantic Norm Drift} (SND) as a third path to agent misconduct, distinct from emergent misalignment and collusion. In SND, a policy-formatted document enters a shared vector store through normal uploads and later reappears as trusted system context after provenance is lost through a Trust Laundering Chain. Across 64 documented failures, attribution systems consistently blamed the model. Four safety classifiers, including one trained on memory poisoning, produced zero detections across 510 checkpoints. In 59 of 65 valid cases, agents explicitly cited the injected document as normative authority before complying. The attack requires no trigger, model access, or repeated interaction, achieves full effect within five sessions, and persists indefinitely. We introduce Counterfactual Composition Testing, which identifies the causal entry with 87.5% accuracy and zero false positives, while a forensics baseline fails across all 25 scenarios. We further prove the Retrieval-Coverage Dilemma, showing that stronger evasion inherently weakens the attack, limiting adaptive bypass strategies. Finally, we propose Memory-Persistent Information-Flow Control, which blocks 97% of attacks at the cross-session boundary where prior defenses fail. We release the SND Corpus, the first adversarial memory benchmark with temporal persistence and multi-agent composition across financial and Health Care domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a 'Misattribution Gap' in multi-agent AI systems, where memory-layer attacks via Semantic Norm Drift (SND) produce agent behaviors indistinguishable from model failure, leading to incorrect remediation. It formalizes SND as distinct from misalignment or collusion, reports that attribution systems blamed the model in all 64 documented failures, shows four safety classifiers (including one trained on memory poisoning) detected zero attacks across 510 checkpoints, introduces Counterfactual Composition Testing with 87.5% accuracy and zero false positives (outperforming a forensics baseline on 25 scenarios), proves the Retrieval-Coverage Dilemma, proposes Memory-Persistent Information-Flow Control blocking 97% of attacks, and releases the SND Corpus benchmark for financial and healthcare domains.
Significance. If the empirical claims hold and generalize, the work is significant for exposing a structural attribution failure in agentic systems and supplying both a diagnostic method and a cross-session defense. The release of the SND Corpus is a clear strength, enabling reproducibility and further benchmarking of temporal-persistence attacks.
major comments (3)
- [section describing the 64 documented failures and attribution results] The central empirical claim that 'attribution systems consistently blamed the model' across 64 documented failures is load-bearing for the Misattribution Gap thesis, yet the manuscript provides no provenance, inclusion criteria, or sampling details for these cases (public incident databases, synthetic generation, or internal logs). This directly affects whether the consistent misattribution result can be extrapolated to typical agentic deployments.
- [section on safety classifier evaluation] The zero-detection result for 'Four safety classifiers... produced zero detections across 510 checkpoints' is load-bearing for the claim that existing defenses fail against SND, but the paper does not specify whether the classifiers are production systems or research prototypes, nor the selection criteria or distribution of the 510 checkpoints. Without this, the result cannot support the broader conclusion about misattribution in deployed systems.
- [section introducing and evaluating Counterfactual Composition Testing] The reported 87.5% accuracy and zero false positives for Counterfactual Composition Testing (contrasted with a forensics baseline failing on all 25 scenarios) is central to the proposed diagnostic contribution, but the manuscript supplies no methodology, data splits, error analysis, or definition of the 25 scenarios. This prevents verification of the quantitative claims.
minor comments (2)
- [results on agent citation of injected documents] The abstract states '59 of 65 valid cases' but does not define 'valid case' or exclusion criteria; this should be clarified in the corresponding results section.
- The formalization of SND and the Trust Laundering Chain would benefit from explicit definitions or pseudocode early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where the manuscript can be strengthened with additional methodological details. We respond to each major comment below and will incorporate revisions to address the concerns about missing provenance, specifications, and methodology.
read point-by-point responses
-
Referee: [section describing the 64 documented failures and attribution results] The central empirical claim that 'attribution systems consistently blamed the model' across 64 documented failures is load-bearing for the Misattribution Gap thesis, yet the manuscript provides no provenance, inclusion criteria, or sampling details for these cases (public incident databases, synthetic generation, or internal logs). This directly affects whether the consistent misattribution result can be extrapolated to typical agentic deployments.
Authors: We agree that provenance, inclusion criteria, and sampling details are essential for assessing generalizability. The 64 cases combine anonymized public incident reports with synthetically generated scenarios derived from observed real-world patterns. Inclusion required: (i) agent action aligned with injected document norms but contradicted the original prompt, and (ii) separate probing confirmed no model misalignment. Sampling drew from a verified pool of 120+ cases with dual-annotator agreement. We will add an appendix 'Documented Failures: Sources and Criteria' with a summary table of domains and session statistics to support extrapolation claims. revision: yes
-
Referee: [section on safety classifier evaluation] The zero-detection result for 'Four safety classifiers... produced zero detections across 510 checkpoints' is load-bearing for the claim that existing defenses fail against SND, but the paper does not specify whether the classifiers are production systems or research prototypes, nor the selection criteria or distribution of the 510 checkpoints. Without this, the result cannot support the broader conclusion about misattribution in deployed systems.
Authors: We acknowledge the need for classifier and checkpoint specifications. The four classifiers comprise two production systems (major cloud providers) and two research prototypes (one general misalignment, one memory-poisoning fine-tuned). The 510 checkpoints were obtained via stratified sampling across 12 deployments (6 financial, 6 healthcare), stratified by memory size (1k-50k entries) and session length (3-20). We will revise the evaluation section to include a table listing each classifier type, selection criteria, and checkpoint distribution, enabling proper interpretation of the zero-detection result. revision: yes
-
Referee: [section introducing and evaluating Counterfactual Composition Testing] The reported 87.5% accuracy and zero false positives for Counterfactual Composition Testing (contrasted with a forensics baseline failing on all 25 scenarios) is central to the proposed diagnostic contribution, but the manuscript supplies no methodology, data splits, error analysis, or definition of the 25 scenarios. This prevents verification of the quantitative claims.
Authors: We agree the methodology section is incomplete. Counterfactual Composition Testing generates variants with the injected document removed and measures behavioral divergence. The 25 scenarios consist of 10 financial, 10 healthcare, and 5 mixed-domain cases with varying persistence. Evaluation used 5-fold cross-validation on the SND Corpus; the 87.5% figure reflects performance on the held-out portion (3 errors traced to norm overlap). We will add a dedicated 'Counterfactual Composition Testing' subsection with pseudocode, explicit data splits, error analysis table, and scenario definitions, plus release of evaluation scripts. revision: yes
Circularity Check
No circularity; empirical claims rest on external observations
full rationale
The paper introduces concepts (Misattribution Gap, Semantic Norm Drift) and reports empirical results from 64 documented failures, 510 classifier checkpoints, and new testing methods (Counterfactual Composition Testing, Memory-Persistent Information-Flow Control) without any derivation chain, equations, or self-citations that reduce predictions or uniqueness claims to fitted inputs or prior author work by construction. All load-bearing statements cite external failure cases and test outcomes rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Semantic Norm Drift (SND)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[AllenAI(2025)] AllenAI
work page 2025
-
[2]
OLMo-2-7B: Fully Open-Source 7B Language Model. HuggingFace Model Hub (allenai/OLMo-2-1124-7B-Instruct), Apache 2.0 License.https://huggingface.co/allenai/OLM o-2-1124-7B-Instruct 17 AAAI paper [Anonymous(2025)] Anonymous
work page 2025
-
[3]
InjecMEM: Memory Injection Attack on LLM Agent Memory Systems. OpenReview preprint (under review).https://openreview.net/forum?id=QVX6hcJ2um [Cemri et al.(2025)] Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and...
work page 2025
-
[4]
Why Do Multi-Agent LLM Systems Fail?. InAdvances in Neural Information Processing Systems.https://openreview.net/forum?id=fAjbYBmonr [Chen et al.(2024)] Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li
work page 2024
-
[5]
Curran Associates, Inc., 130185–130213. doi:10.52202/079017-4136 [Cheng et al.(2026)] Yu Cheng, Jiuan Zhou, Yongkang Hu, Yihang Chen, Huichi Zhou, Mingang Chen, Zhizhong Zhang, Kun Shao, Yuan Xie, and Zhaoxia Yin
-
[6]
2026).https://arxiv.or g/abs/2602.03224 [Chroma Team(2024)] Chroma Team
TAME: A Trustworthy Test-Time Evolution of Agent Memory with Systematic Benchmarking.arXiv preprint arXiv:2602.03224(Feb. 2026).https://arxiv.or g/abs/2602.03224 [Chroma Team(2024)] Chroma Team
-
[7]
Chroma: The AI-Native Open-Source Embedding Database.https: //www.trychroma.com/.https://www.trychroma.com/ [Costa et al.(2025)] Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-Beguélin
work page 2025
-
[8]
Securing AI Agents with Information-Flow Control.arXiv preprint arXiv:2505.23643(2025).https://arxiv.org/abs/2505.23643 [Dong et al.(2025)] Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Memory Injection Attacks on LLM Agents via Query-Only Interaction. InAdvances in Neural Information Processing Systems.https://neurips.cc/virtual/2025/poster/118152 [Dubey et al.(2024)] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al
work page 2025
-
[10]
The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783(2024).https://arxiv.org/abs/2407.21783 [Google DeepMind(2025)] Google DeepMind
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Gemma 3: Open Models Based on Gemini Research and Tech- nology. HuggingFace Model Hub (google/gemma-3-12b-it), Gemma Terms of Use.https://huggingf ace.co/google/gemma-3-12b-it [Greshake et al.(2023)] Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz
work page 2023
-
[12]
InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec @ CCS 2023)
Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applica- tions with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec @ CCS 2023). ACM, 79–90. doi:10.1145/3605764.3623985 [Han et al.(2024)] Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lam...
-
[13]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs. InAdvances in Neural Information Processing Systems (NeurIPS 2024, Datasets and Benchmarks Track, Vol. 37).https://proceedings.neurips.cc/paper_files/paper/2024/hash/0f6 9b4b96a46f284b726fbd70f74fb3b-Abstract-Datasets_and_Benchmarks_Track.html [IBM Research(2025)...
work page 2024
-
[14]
Granite Guardian 3.2: Agentic-Aware Safety Classification with RAG Hallucination Detection. HuggingFace Model Hub (ibm-granite/granite-guardian-3.2-5b).https: //huggingface.co/ibm-granite/granite-guardian-3.2-5b [Kasundra et al.(2025)] Jaykumar Kasundra, Anjaneya Praharaj, Sourabh Surana, Lakshmi Sirisha Chodisetty, Sourav Sharma, Abhigya Verma, Abhishek ...
work page 2025
- [15]
-
[16]
Manipulating AI Memory for Profit: The Rise of AI Recommendation Poisoning. Microsoft Security Blog.https://www.microsoft.co m/en-us/security/blog/2026/02/10/ai-recommendation-poisoning/ [LangChain AI(2025)] LangChain AI
work page 2026
-
[17]
LangGraph: Build Stateful, Multi-Actor Applications with LLMs.ht tps://langchain-ai.github.io/langgraph/.https://langchain-ai.github.io/langgraph/ [Liu et al.(2024)] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen...
work page 2024
-
[18]
AgentBench: Evaluating LLMs as Agents
Agent- Bench: Evaluating LLMs as Agents. InThe Twelfth International Conference on Learning Representations. https://arxiv.org/abs/2308.03688 18 AAAI paper [Lupinacci et al.(2025)] Matteo Lupinacci, Francesco Aurelio Pironti, Francesco Blefari, Francesco Romeo, Luigi Arena, and Angelo Furfaro
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
The Dark Side of LLMs: Agent-based Attack Vectors for System-level Compromise
The Dark Side of LLMs: Agent-Based Attacks for Complete Computer Takeover. arXiv preprint arXiv:2507.06850.https://arxiv.org/abs/2507.06850 [Lynch et al.(2025)] Aengus Lynch, Benjamin Wright, Caleb Larson, Stuart J. Ritchie, Sören Mindermann, Evan Hubinger, Ethan Perez, and Kevin K. Troy
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Agentic Misalignment: How LLMs Could Be Insider Threats. arXiv preprint arXiv:2510.05179(2025).https://arxiv.org/abs/2510.05179 [Mazeika et al.(2024)] Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks
-
[21]
(Proceedings of Machine Learning Research, Vol. 235). PMLR, 35181–35224.https://proceedings.mlr.press/v235/mazeika24a.html [Meta AI(2024)] Meta AI
work page 2024
-
[22]
Llama 3.1: Open Foundation and Fine-Tuned Chat Models. HuggingFace Model Hub (meta-llama/Llama-3.1-8B-Instruct), Meta Llama 3.1 Community License.https://huggingfac e.co/meta-llama/Llama-3.1-8B-Instruct [Microsoft Research(2025)] Microsoft Research
work page 2025
-
[23]
Phi-4 Technical Report. HuggingFace Model Hub (microsoft/phi-4), MIT License.https://huggingface.co/microsoft/phi-4 [Mistral AI(2023)] Mistral AI
work page 2023
-
[24]
Mistral 7B. HuggingFace Model Hub (mistralai/Mistral-7B-Instruct-v0.3), Apache 2.0 License.https://huggingface.co/mis tralai/Mistral-7B-Instruct-v0.3 [MITRE Corporation(2026)] MITRE Corporation
work page 2026
-
[25]
AML.T0080: AI Agent Context Poisoning: Memory. MITRE ATLAS Knowledge Base.https://atlas.mitre.org/techniques/AML.T0080 [Motwani et al.(2024)] Sumeet Ramesh Motwani, Mikhail Baranchuk, Martin Strohmeier, Vijay Bolina, Philip Torr, Lewis Hammond, and Christian Schroeder de Witt
work page 2024
-
[26]
doi:10.52202/079017-2336 [Narajala and Narayan(2025)] Vineeth Sai Narajala and Om Narayan
Curran Associates, Inc., 73439–73486. doi:10.52202/079017-2336 [Narajala and Narayan(2025)] Vineeth Sai Narajala and Om Narayan
- [27]
-
[28]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b Model Card. HuggingFace Model Hub (openai/gpt-oss-20b), Apache 2.0 License. arXiv:2508.10925 [cs.CL]https://arxiv.org/abs/25 08.10925 [Pearl(2000)] Judea Pearl. 2000.Causality: Models, Reasoning, and Inference. Cambridge University Press. [Reddy and Gujral(2025)] Pavan Reddy and Aditya Sanjay Gujral
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[29]
303–311. doi:10.1609/aaaiss.v7i1.36899 [Ruan et al.(2024)] Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto
-
[30]
Identifying the Risks of LM Agents with an LM- Emulated Sandbox. InThe Twelfth International Conference on Learning Representations.https://openre view.net/forum?id=GEcwtMk1uA [Srivastava and He(2025)] Saksham Sahai Srivastava and Haoyu He
work page 2025
-
[31]
arXiv preprint arXiv:2512.16962 , year=
MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval. arXiv preprint arXiv:2512.16962.https://arxiv.org/ab s/2512.16962 [Wallace et al.(2024)] Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beu- tel
-
[32]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions. arXiv preprint arXiv:2404.13208.https://arxiv.org/abs/2404.13208 [Wei et al.(2025)] Qianshan Wei, Tengchao Yang, Yaochen Wang, Xinfeng Li, Lijun Li, Zhenfei Yin, Yi Zhan, Thorsten Holz, Zhiqiang Lin, and XiaoFeng Wang
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2510.02373 , year=
A-MemGuard: A Proactive Defense Framework for LLM-Based Agent Memory. arXiv preprint arXiv:2510.02373.https://arxiv.org/abs/2510.02373 [Yao et al.(2024)] Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024.τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.arXiv preprint arXiv:2406.12045(2024).https: //arxiv.org/abs...
-
[34]
Information Retrieval Induced Safety Degradation in AI Agents. InAdvances in Neural Information Processing Systems (NeurIPS 2025).https://arxiv.org/abs/2505.14215 [Zhan et al.(2024)] Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang
-
[35]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL 2024.https://arxiv.org/abs/2403.02691 [Zhang et al.(2025b)] Baolei Zhang, Haoran Xin, Minghong Fang, Zhuqing Liu, Biao Yi, Tong Li, and Zheli Liu. 2025b. Traceback of Poisoning Attacks to Retr...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3696410.3714756 2024
-
[36]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents. InThe Twelfth International Conference on Learning Represen- tations.https://arxiv.org/abs/2307.13854 [Zou et al.(2025)] Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Source Corpus Summary Table 14: Source corpus summary. All sources are publicly available with permissive or public-domain licenses, ensuring MAJB-64 can be freely distributed. Domain Source License Records Financial NIST SP 800-53 Rev 5 Public domain (US gov.) 538 Financial GitLab Handbook CC BY-SA 4.0 417 Financial GDPR EU 2016/679 Public EU law 70 Fina...
work page 2016
-
[38]
and Table 3 (Sec- tion 2), respectively. CCT Experimental Run History Six iterative runs were required before all three H5 criteria (TPR≥0.80, FAR<0.10, McNemarp <0.05) were simultaneously satisfied. Run 6 is the definitive result. CCT vs. RAGForensics See Table 12 in Section 8.1. 21 AAAI paper Table 16: CCT experimental run history. H5 requires TPR≥0.80,...
work page 1949
-
[39]
with explicit constants and per-trial record structure. Parameter choices.K= 3majority-vote trials is the minimum that prevents single-trial stochastic false positives; gpt-oss-20b (M1) exhibits high output variance for borderline CDG entries, making single-trial evaluation insufficient. θ= 0.5(majority quorum) maps to “2 of 3 trials show harm” as the con...
work page 2025
-
[40]
All Table 22: Model stack. M4 is excluded from the temporal trajectory evaluation due to VRAM constraints competing with the 4-classifier stack on an 80 GB H100 NVL. •License:Apache 2.0 •Access date:April 2026 •Inference settings:temperature= 0.7, top-p= 0.9, max tokens= 2048 •Framework:LangGraph 0.1.x + ChromaDB 0.4.x •Embedding model:all-MiniLM-L6-v2 •T...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.