Can AI Guess What You Know? Performance Comparison of Large Language Models for Human Domain Knowledge Estimation From Communication Logs
Pith reviewed 2026-05-25 05:50 UTC · model grok-4.3
The pith
Large language models can estimate individual domain knowledge from Slack logs, with accuracy varying sharply by model and showing only weak dependence on message volume.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Zero-shot prompting of LLMs on raw Slack communication logs yields domain-knowledge estimates whose mean absolute error against self-reported ratings reaches 21.13 percent for Gemini 2.5 Flash, with GPT models showing significantly larger discrepancies, and with estimation accuracy depending only weakly on the number of messages available per user.
What carries the argument
Zero-shot LLM inference of per-user skill levels (0-100) from unstructured, long-term communication logs, scored by mean absolute error against self-reported ground truth.
If this is right
- Automated mapping of expertise from everyday chat data is feasible with current models.
- Model choice matters: Gemini 2.5 Flash outperforms GPT variants on this task.
- Simply supplying more messages does not guarantee better estimates.
- Any real-world use requires privacy-preserving techniques because raw logs contain sensitive content.
- Richer, structure-aware knowledge representations would likely reduce current error rates.
Where Pith is reading between the lines
- Organizations could first test the method on anonymized message summaries to limit privacy exposure before scaling to full logs.
- The same pipeline might be applied to email threads or project-management comments with only minor prompt changes.
- A follow-up study could check whether LLM estimates predict actual task success better than the self-ratings used here.
- Teams that adopt such tools should periodically re-validate estimates against fresh objective measures rather than treating them as static.
Load-bearing premise
Self-reported skill ratings from the 27 participants accurately reflect their true domain knowledge and can serve as reliable ground truth for measuring LLM estimation error.
What would settle it
Replace the self-reported ratings with objective skill-test scores on the same topics for the same participants and re-measure the LLMs' mean absolute error.
Figures





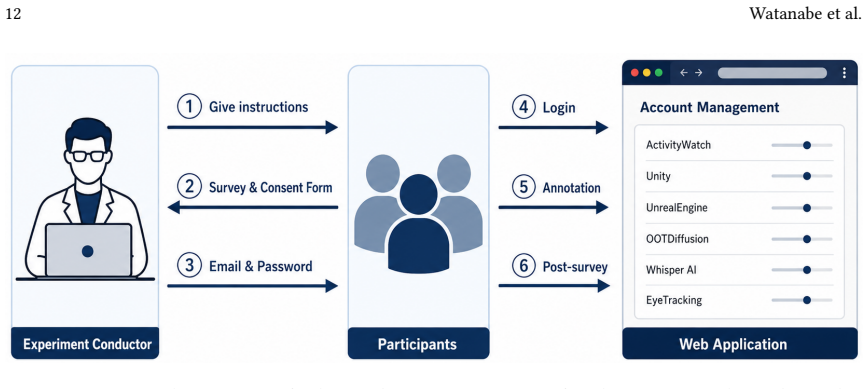
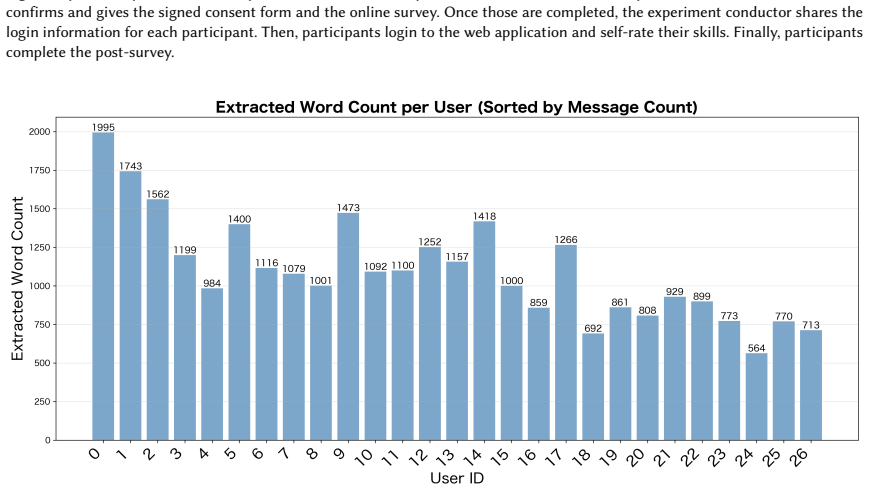

read the original abstract
Employees often struggle to identify ``who knows what,'' leading to organizational productivity losses. We investigate whether Large Language Models (LLMs) can infer individual domain knowledge directly from long-term Slack logs. Analyzing 27,188 messages from 43 users, we evaluated seven models (including Gemini, Claude, and GPT families) by comparing their zero-shot estimates against self-reported skill ratings from 27 participants. Gemini 2.5 Flash achieved the lowest error (MAE 21.13%), while GPT models showed significantly larger discrepancies. Notably, estimation accuracy depended only weakly on message volume, indicating that more text alone does not guarantee better inference. These findings demonstrate the feasibility and current limits of automated expertise mapping, highlighting the need for privacy-preserving deployments and richer, structure-aware representations of human knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs can infer individual domain knowledge from Slack logs, evaluated via zero-shot estimates from seven models (Gemini, Claude, GPT families) against self-reported skill ratings from 27 of 43 users whose 27,188 messages were analyzed. Gemini 2.5 Flash achieves the lowest MAE of 21.13%, GPT models perform worse, accuracy depends only weakly on message volume, and the work concludes this demonstrates feasibility and limits of automated expertise mapping while calling for privacy-preserving approaches.
Significance. If self-reports validly proxy true knowledge, the concrete MAE benchmarks and the negative result on message volume would provide useful empirical grounding for LLM-based expertise estimation in organizations. The study supplies a direct model comparison on real logs, which could serve as a baseline for future work on structure-aware knowledge representations.
major comments (2)
- [Evaluation] Evaluation (as described in the abstract): The central claim that LLMs infer 'individual domain knowledge' rests on comparing model outputs to self-reported skill ratings from 27 participants, yet no external validation (objective tests, peer ratings, or supervisor assessments) is reported. Self-assessments are known to be biased, so the MAE of 21.13% quantifies agreement with self-perception rather than accuracy of knowledge estimation; this directly undermines the feasibility conclusion.
- [Methods] Methods: Participant selection, domain definitions, and prompting details for the zero-shot estimates are not specified, preventing assessment of whether the 27 self-reports cover the same knowledge dimensions used in the LLM prompts or whether the reported model differences are robust.
minor comments (2)
- [Abstract] Clarify whether model estimates were produced only for the 27 participants who provided self-reports or for all 43 users, and report the exact number of messages per participant used in each estimate.
- [Results] Add error bars, confidence intervals, or statistical tests for the MAE comparisons across models to support statements about significant differences.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, acknowledging where revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] The central claim that LLMs infer 'individual domain knowledge' rests on comparing model outputs to self-reported skill ratings from 27 participants, yet no external validation (objective tests, peer ratings, or supervisor assessments) is reported. Self-assessments are known to be biased, so the MAE of 21.13% quantifies agreement with self-perception rather than accuracy of knowledge estimation; this directly undermines the feasibility conclusion.
Authors: We agree that self-reports are an imperfect proxy subject to well-documented biases and that the reported MAE reflects agreement with self-perception rather than objective accuracy. The manuscript will be revised to explicitly frame the results as measuring concordance with self-assessed knowledge, to add a dedicated limitations subsection on this point, and to moderate the feasibility claims to reflect this scope. No external validation data were collected, so we cannot claim stronger validity. revision: yes
-
Referee: [Methods] Participant selection, domain definitions, and prompting details for the zero-shot estimates are not specified, preventing assessment of whether the 27 self-reports cover the same knowledge dimensions used in the LLM prompts or whether the reported model differences are robust.
Authors: The full manuscript contains a Methods section describing recruitment from a single organization, the ten predefined technical domains, and the zero-shot prompt template. However, we acknowledge that these details are insufficiently explicit for reproducibility. We will expand the section with participant demographics, exact domain-question mappings, and full prompt examples to allow direct comparison between self-report items and LLM inputs. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper reports an empirical comparison of LLM zero-shot outputs to self-reported skill ratings from 27 participants, with no equations, parameter fitting, or derivations present in the provided text. The MAE values and feasibility conclusions are direct measurements against independent participant data rather than reductions by construction. No self-citations are invoked as load-bearing premises, and no ansatz, uniqueness theorems, or renamings of known results appear. The evaluation chain is self-contained against the stated ground truth.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported skill ratings accurately reflect participants' true domain knowledge.
- domain assumption Slack communication logs contain extractable signals about users' domain expertise.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025.Claude Haiku 4.5. https://www.anthropic.com/news/claude-haiku-4-5 AI language model
work page 2025
-
[2]
Anthropic. 2025.Claude Sonnet 4.5. https://www.anthropic.com/news/claude-sonnet-4-5 AI language model
work page 2025
-
[3]
Sasa Arsovski, Hasmik Osipyan, Muniru Idris Oladele, and Adrian David Cheok. 2019. Automatic knowledge extraction of any Chatbot from conversation.Expert Systems with Applications137 (2019), 343–348
work page 2019
-
[4]
Jacques Bughin, Michael Chui, and James Manyika. 2012. Capturing business value with social technologies.McKinsey Quarterly4, 1 (2012), 72–80
work page 2012
-
[5]
Liuqing Chen, Zhaojun Jiang, Duowei Xia, Zebin Cai, Lingyun Sun, Peter Childs, and Haoyu Zuo. 2024. BIDTrainer: An LLMs-driven Education Tool for Enhancing the Understanding and Reasoning in Bio-inspired Design. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, ...
-
[6]
Jan Clusmann, Fiona R Kolbinger, Hannah Sophie Muti, Zunamys I Carrero, Jan-Niklas Eckardt, Narmin Ghaffari Laleh, Chiara Maria Lavinia Löffler, Sophie-Caroline Schwarzkopf, Michaela Unger, Gregory P Veldhuizen, et al. 2023. The future landscape of large language models in medicine. Communications medicine3, 1 (2023), 141
work page 2023
-
[7]
Elnara Galimzhanova, Cristina Ioana Muntean, Franco Maria Nardini, Raffaele Perego, and Guido Rocchietti. 2023. Rewriting conversational utterances with instructed large language models. In2023 IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT). IEEE, 56–63
work page 2023
-
[8]
Google. 2025.Firebase. Technical Report. Google. https://firebase.google.com/ Firebase is a backend-as-a-service platform for building web and mobile applications
work page 2025
-
[9]
DeepMind & Google. 2025.Gemini 2.5 Flash. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-flash Multimodal large-language model
work page 2025
-
[10]
DeepMind & Google. 2025.Gemini 2.5 Pro. https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-pro Multimodal large-language model
work page 2025
-
[11]
Xiaodong Gu, Kang Min Yoo, and Jung-Woo Ha. 2021. Dialogbert: Discourse-aware response generation via learning to recover and rank utterances. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12911–12919
work page 2021
-
[12]
Jizhou Huang, Ming Zhou, and Dan Yang. 2007. Extracting chatbot knowledge from online discussion forums. InProceedings of the 20th International Joint Conference on Artifical Intelligence(Hyderabad, India)(IJCAI’07). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 423–428
work page 2007
-
[13]
Samuel Kernan Freire, Chaofan Wang, Santiago Ruiz-Arenas, and Evangelos Niforatos. 2023. Tacit Knowledge Elicitation for Shop-floor Workers with an Intelligent Assistant. InExtended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI EA ’23). Association for Computing Machinery, New York, NY, USA, Article 266, ...
-
[14]
Ksenija Kosilova and Ilze Birzniece. 2024. Survey on Organizational Chat Conversation Analysis: Exploring Dialogue Summarization from a Knowledge Discovery Perspective.Complex Systems Informatics and Modeling Quarterly39 (2024), 86–104
work page 2024
- [15]
-
[16]
Yuhan Liu, Aadit Shah, Jordan Ackerman, and Manaswi Saha. 2025. Exploring the Design Space of Real-time LLM Knowledge Support Systems: A Case Study of Jargon Explanations. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 633, 20 pages. doi:10.1145/3706...
-
[17]
Ryugo Morita, Ko Watanabe, Jinjia Zhou, Andreas Dengel, and Shoya Ishimaru. 2025. GenAIReading: Augmenting Human Cognition with Interactive Digital Textbooks Using Large Language Models and Image Generation Models. InProceedings of the Augmented Humans International Conference 2025 (AHs ’25). Association for Computing Machinery, New York, NY, USA, 289–301...
-
[18]
Ummara Mumtaz, Awais Ahmed, and Summaya Mumtaz. 2023. LLMs-Healthcare: Current applications and challenges of large language models in various medical specialties.arXiv preprint arXiv:2311.12882(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Kotaro Oomori, Yoshio Ishiguro, and Jun Rekimoto. 2024. SkillsInterpreter: A Case Study of Automatic Annotation of Flowcharts to Support Browsing Instructional Videos in Modern Martial Arts using Large Language Models. InProceedings of the Augmented Humans International Conference 2024 (Melbourne, VIC, Australia)(AHs ’24). Association for Computing Machin...
-
[20]
OpenAI. 2024.GPT-4o System Card. Technical Report. OpenAI. https://openai.com/ja-JP/index/hello-gpt-4o/ System card describing the GPT-4o omni model
work page 2024
-
[21]
OpenAI. 2025.GPT-5 System Card. Technical Report. OpenAI. https://openai.com/ja-JP/index/introducing-gpt-5/ System card describing the GPT-5 model family
work page 2025
-
[22]
2025.OpenAI o3 and o4-mini System Card
OpenAI. 2025.OpenAI o3 and o4-mini System Card. Technical Report. OpenAI. https://openai.com/ja-JP/index/o3-o4-mini-system-card/ System card describing the OpenAI o3 and o4-mini reasoning models
work page 2025
-
[23]
2018.Workplace Knowledge and Productivity Report
Panopto and YouGov. 2018.Workplace Knowledge and Productivity Report. Technical Report. Panopto. https://www.panopto.com/resource/ebook/ valuing-workplace-knowledge/ Survey of 1 001 US employees in organisations with 200+ employees; average large US business loses US$47 million annually from inefficient knowledge sharing
work page 2018
-
[24]
Jun Rekimoto. 2025. GazeLLM: Multimodal LLMs incorporating Human Visual Attention. InProceedings of the Augmented Humans International Conference 2025 (AHs ’25). Association for Computing Machinery, New York, NY, USA, 302–311. doi:10.1145/3745900.3746075 Manuscript submitted to ACM 18 Watanabe et al
-
[25]
Joni Salminen, Danial Amin, Soon-Gyo Jung, and Bernard Jansen. 2025. The Use of Large Language Models in HCI: A Critical Analysis of Synthetic Users. InProceedings of the Augmented Humans International Conference 2025 (AHs ’25). Association for Computing Machinery, New York, NY, USA, 413–417. doi:10.1145/3745900.3746108
-
[26]
Haruki Suzawa, Ko Watanabe, Andreas Dengel, and Shoya Ishimaru. 2025. Augmenting Online Meetings with Context-Aware Real-time Music Generation. InProceedings of the Augmented Humans International Conference 2025 (AHs ’25). Association for Computing Machinery, New York, NY, USA, 487–490. doi:10.1145/3745900.3746116
-
[27]
Hirotaka Takita, Shannon L Walston, Yasuhito Mitsuyama, Ko Watanabe, Shoya Ishimaru, and Daiju Ueda. 2025. Comparative performance of large language models in structuring head CT radiology reports: multi-institutional validation study in Japan.Japanese Journal of Radiology(2025), 1–11
work page 2025
-
[28]
Anna Tigunova. 2020. Extracting Personal Information from Conversations. InCompanion Proceedings of the Web Conference 2020(Taipei, Taiwan) (WWW ’20). Association for Computing Machinery, New York, NY, USA, 284–288. doi:10.1145/3366424.3382089
-
[29]
Anthony J Trippe. 2022. Knowledge management with patents: A systematic method for capturing and sharing unique technical information for Corporate guidance.World Patent Information69 (2022), 102110
work page 2022
- [30]
-
[31]
2018.The future of work: Robots, AI, and automation
Darrell M West. 2018.The future of work: Robots, AI, and automation. Bloomsbury Publishing USA
work page 2018
-
[32]
Tongshuang Wu, Haiyi Zhu, Maya Albayrak, Alexis Axon, Amanda Bertsch, Wenxing Deng, Ziqi Ding, Boyuan Guo, Sireesh Gururaja, Tzu-Sheng Kuo, Jenny T Liang, Ryan Liu, Ihita Mandal, Jeremiah Milbauer, Xiaolin Ni, Namrata Padmanabhan, Subhashini Ramkumar, Alexis Sudjianto, Jordan Taylor, Ying-Jui Tseng, Patricia Vaidos, Zhijin Wu, Wei Wu, and Chenyang Yang. 2...
-
[33]
Kanta Yamaoka, Ko Watanabe, Koichi Kise, Andreas Dengel, and Shoya Ishimaru. 2023. Experience is the Best Teacher: Personalized Vocabulary Building Within the Context of Instagram Posts and Sentences from GPT-3. InAdjunct Proceedings of the 2022 ACM International Joint Conference on Pervasive and Ubiquitous Computing and the 2022 ACM International Symposi...
-
[34]
Kanta Yamaoka, Ko Watanabe, Koichi Kise, Andreas Dengel, and Shoya Ishimaru. 2025. Img2Vocab: Explore Words Tied to Your Life With LLMs and Social Media Images.IEEE Access13 (2025), 20456–20471. doi:10.1109/ACCESS.2025.3533076
-
[35]
Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Shaochen Zhong, Bing Yin, and Xia Hu. 2024. Harnessing the power of llms in practice: A survey on chatgpt and beyond.ACM Transactions on Knowledge Discovery from Data18, 6 (2024), 1–32
work page 2024
-
[36]
Ruike Zhang, Yuan Tian, Penghui Wei, Daniel Dajun Zeng, and Wenji Mao. 2024. An LLM-enabled knowledge elicitation and retrieval framework for zero-shot cross-lingual stance identification. InFindings of the Association for Computational Linguistics: EMNLP 2024. 12253–12266
work page 2024
-
[37]
Shuo Zhang, Mu-Chun Wang, and Krisztian Balog. 2022. Analyzing and simulating user utterance reformulation in conversational recommender systems. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 133–143
work page 2022
- [38]
-
[39]
Songchen Zhou, Mark Armstrong, Giulia Barbareschi, Toshihiro Ajioka, Zheng Hu, Masatane Muto, Ando Ryoichi, Kentaro Yoshifuji, and Kouta Minamizawa. 2025. Augmented Body Communicator: Enhancing daily body expression for people with upper limb limitations through LLM and a robotic arm. InProceedings of the Augmented Humans International Conference 2025 (AH...
-
[40]
Bahman Zohuri and Farhang Mossavar-Rahmani. 2019.A Model to Forecast Future Paradigms: Volume 1: Introduction to Knowledge Is Power in Four Dimensions. Apple academic press. Manuscript submitted to ACM
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.