Memorization Dynamics of Fill-in-the-Middle Pretraining
Pith reviewed 2026-05-25 05:43 UTC · model grok-4.3
The pith
Fill-in-the-middle pretraining produces linear growth in verbatim memorization with repeated data and keeps recall anchored in prefix context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
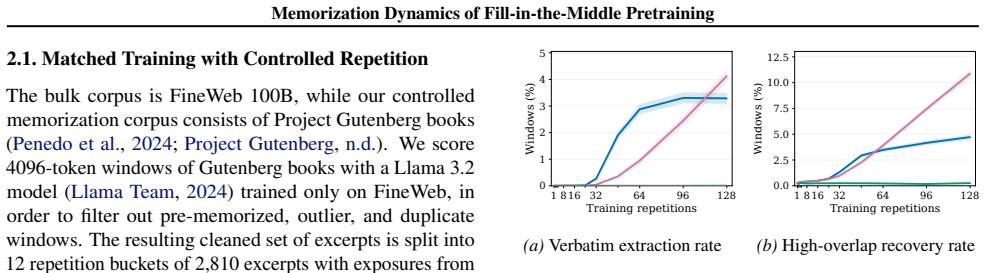
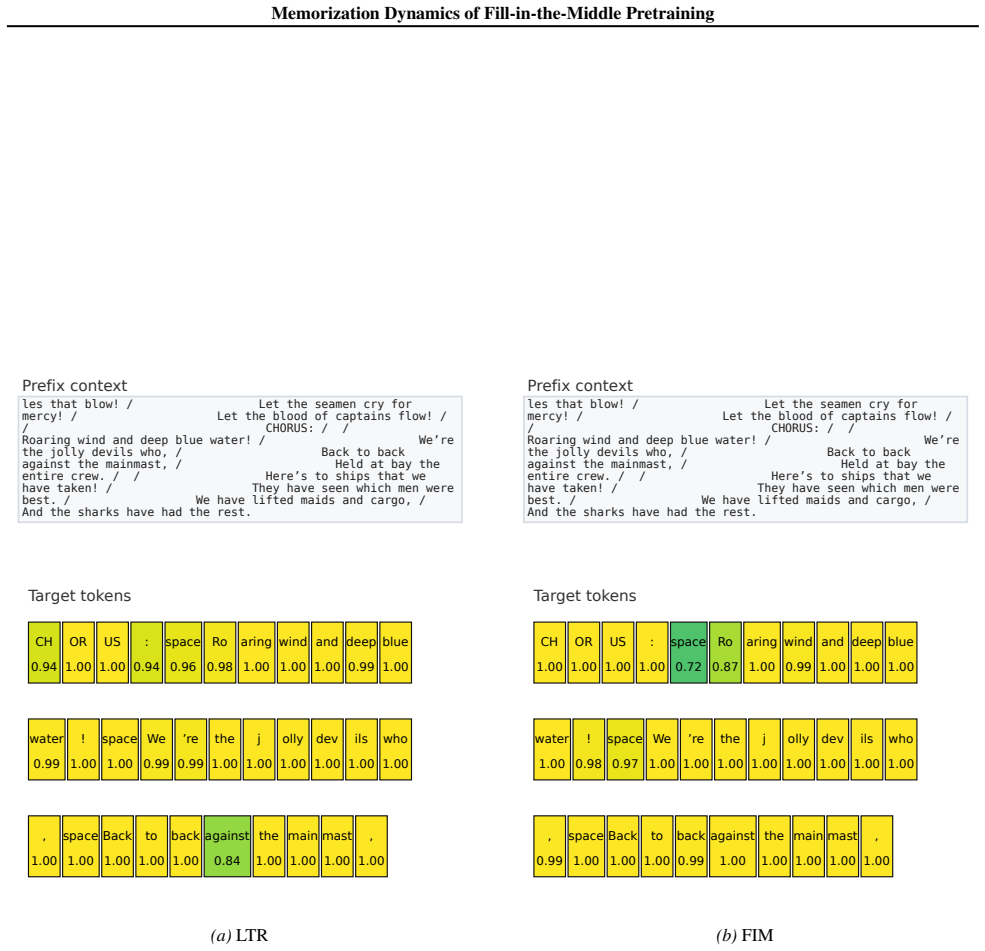
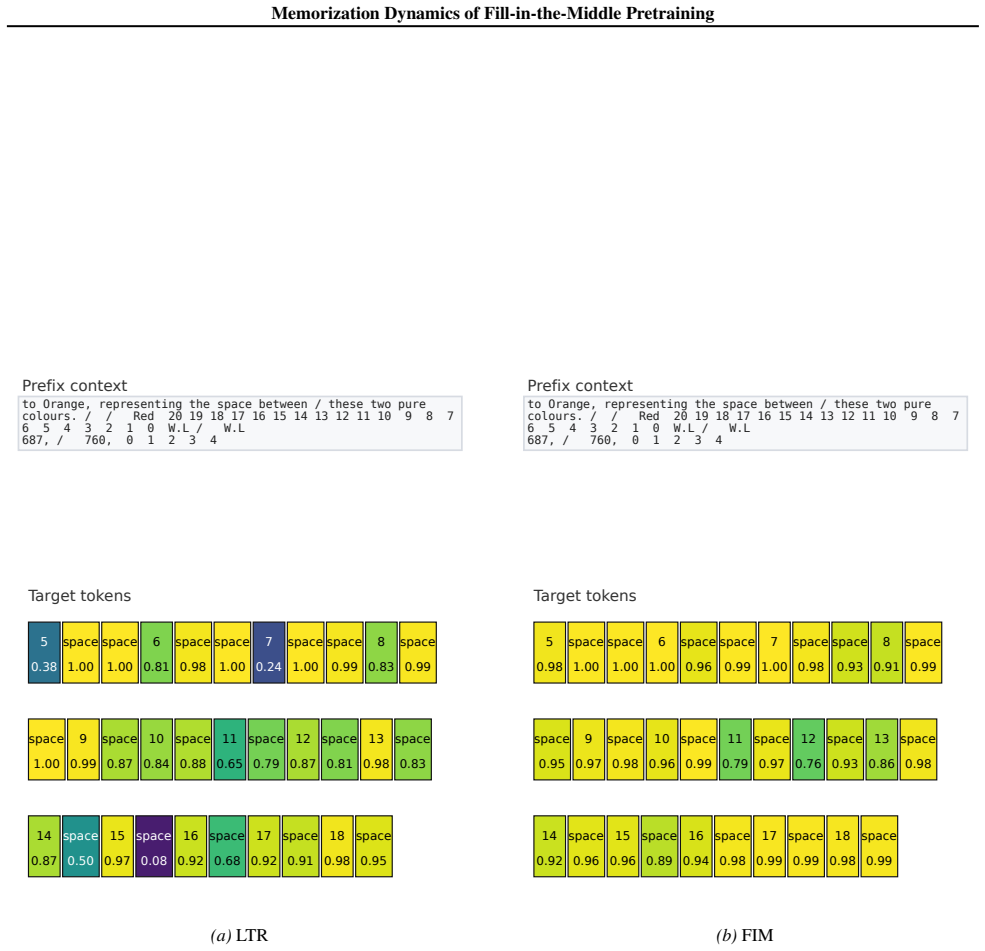
In matched Llama 3.2 models trained on FineWeb-Gutenberg excerpts containing artificial repetitions, verbatim extraction under FIM grows approximately linearly with repetition count. Prefix probes lead FIM models to favor shorter or partially matching spans more often than LTR models, which more frequently assign high probability to long exact continuations. When probed in native FIM format, verbatim recall remains strongly dependent on prefix context even when suffix context is supplied.
What carries the argument
Verbatim extraction rate measured across repetition counts using prefix-based probes versus native FIM-format probes.
If this is right
- Verbatim extraction under FIM training scales linearly with repetitions over the tested range.
- Suffix context alone is insufficient to produce strong verbatim recall in FIM-trained models.
- LTR models more readily produce long exact continuations than FIM models under prefix probing.
- Limiting evaluation to one span length or one probe format can overlook differences in memorization behavior.
Where Pith is reading between the lines
- Training pipelines that use FIM may require separate monitoring of prefix-anchored recall to assess privacy or copyright exposure.
- Standard benchmark suites that rely on single probe formats could systematically understate or overstate memorization in infilling models.
- If the linear trend holds at scale, repetition counts in pretraining data become a direct control knob for expected verbatim leakage.
Load-bearing premise
Memorization patterns observed with artificially repeated excerpts in a controlled corpus match the patterns that would appear during large-scale training on naturally occurring data.
What would settle it
A direct measurement on a large naturally occurring corpus showing either clearly nonlinear growth in verbatim extraction or strong suffix-only recall under FIM training would falsify the reported dynamics.
Figures








read the original abstract
Fill-in-the-middle (FIM) is a pretraining objective widely used to equip causal language models with infilling ability, yet its effect on verbatim memorization remains underexplored. We study the memorization dynamics of FIM in a controlled setting by pretraining matched Llama 3.2 models with FIM and standard left-to-right (LTR) objectives on a FineWeb-Gutenberg corpus containing repeated Gutenberg excerpts. With prefix-based probes, FIM more often recovers short or partially matching spans, while LTR more often assigns high confidence to long exact continuations. We observe that verbatim extraction under FIM-training grows approximately linearly with repetitions over the tested range. Evaluating native FIM-format probes reveals that suffix context is not sufficient: verbatim recall under FIM-training remains strongly anchored in prefix context. Our results also show that evaluating only one span length or probing format can miss important nuances in memorization behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the memorization dynamics of fill-in-the-middle (FIM) pretraining compared to left-to-right (LTR) pretraining using matched Llama 3.2 models on a FineWeb-Gutenberg corpus with repeated Gutenberg excerpts. Key findings include that verbatim extraction under FIM grows approximately linearly with repetitions, FIM models more often recover short or partially matching spans while LTR assigns high confidence to long exact continuations, and that verbatim recall remains strongly anchored in prefix context even when using native FIM-format probes. The work also notes that single span length or probe format evaluations can miss nuances.
Significance. If the results hold, the controlled isolation of repetition count provides a useful measurement of how FIM objectives affect verbatim recall patterns, including the linear growth observation and prefix dominance. This contributes empirical data relevant to training objective design and potential memorization risks. The use of matched models and native FIM probes is a strength for isolating effects.
major comments (2)
- [§3] §3 (Corpus and Experimental Setup): The central claims of linear growth in verbatim extraction and persistent prefix anchoring rest on a corpus constructed by inserting repeated Gutenberg excerpts into FineWeb. This artificial distribution lacks the variable co-occurrence, partial overlaps, and long-tail frequencies of natural pretraining data, raising a correctness risk for generalizing the reported dynamics beyond the controlled setting.
- [Results] Results (linear growth and probe evaluations): The manuscript reports directional findings on span recovery and context anchoring but, consistent with the abstract, provides limited quantitative details on model sizes, exact repetition counts tested, number of runs, or statistical measures such as error bars or fit quality. This weakens assessment of the robustness of the 'approximately linear' claim and the sufficiency of suffix context.
minor comments (1)
- [Abstract] Abstract: Including at least one concrete quantitative example (e.g., repetition range or span length) would improve clarity without altering the directional claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the intent of our controlled experimental design and committing to specific improvements in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Corpus and Experimental Setup): The central claims of linear growth in verbatim extraction and persistent prefix anchoring rest on a corpus constructed by inserting repeated Gutenberg excerpts into FineWeb. This artificial distribution lacks the variable co-occurrence, partial overlaps, and long-tail frequencies of natural pretraining data, raising a correctness risk for generalizing the reported dynamics beyond the controlled setting.
Authors: We agree that the FineWeb-Gutenberg corpus is deliberately constructed to isolate repetition count as the independent variable. This controlled setup is the core methodological contribution, enabling direct measurement of how FIM versus LTR objectives affect verbatim extraction under matched conditions. The manuscript does not claim that the precise linear growth rates or prefix-anchoring strengths will hold identically in fully naturalistic pretraining distributions; rather, it provides empirical data on objective-specific memorization dynamics that can inform training design. We will revise §3 to explicitly articulate this scope limitation and add a brief discussion of how the observed patterns might interact with natural data statistics. revision: partial
-
Referee: [Results] Results (linear growth and probe evaluations): The manuscript reports directional findings on span recovery and context anchoring but, consistent with the abstract, provides limited quantitative details on model sizes, exact repetition counts tested, number of runs, or statistical measures such as error bars or fit quality. This weakens assessment of the robustness of the 'approximately linear' claim and the sufficiency of suffix context.
Authors: We acknowledge that the current presentation would benefit from greater quantitative transparency. In the revision we will expand the Results section (and associated figures/tables) to report: the precise Llama 3.2 model sizes used, the exact repetition counts evaluated, the number of independent training runs, and statistical measures including error bars on extraction rates together with goodness-of-fit metrics for the linear trend. These additions will allow readers to better evaluate the robustness of the linear-growth observation and the prefix-dominance findings under native FIM probes. revision: yes
Circularity Check
No significant circularity in empirical measurement study
full rationale
The paper is an empirical study reporting direct measurements of memorization behavior (e.g., verbatim extraction rates under FIM vs. LTR on a controlled corpus) with no derivations, equations, or fitted parameters that define the reported quantities in terms of themselves. The observed linear growth with repetitions is a measured outcome rather than a self-referential construct. No self-citation chains, ansatzes, or uniqueness theorems are invoked to support central claims. The work is self-contained against external benchmarks as a controlled experiment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
URL https://openreview.net/forum? id=TatRHT_1cK. Chen, T., Brahman, F., Liu, J., Mireshghallah, N., Shi, W., Koh, P. W., Zettlemoyer, L., and Hajishirzi, H. ParaPO: Aligning language models to reduce verbatim reproduc- tion of pre-training data. InSecond Conference on Lan- guage Modeling, 2025. URL https://openreview. net/forum?id=Uic3ojVhXh. Clark, P., C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
URL https://openreview.net/forum? id=d7KBjmI3GmQ. Huang, J., Yang, D., and Potts, C. Demystifying verbatim memorization in large language models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Nat- ural Language Processing, pp. 10711–10732, Miami, Florida, USA, November 2024. Association ...
-
[5]
URL https://aclanthology.org/2024. emnlp-main.598/. Kandpal, N., Wallace, E., and Raffel, C. Deduplicating training data mitigates privacy risks in language mod- els. In Chaudhuri, K., Jegelka, S., Song, L., Szepesv´ari, C., Niu, G., and Sabato, S. (eds.),International Con- ference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA,...
work page 2024
-
[6]
URL https://proceedings.mlr.press/ v162/kandpal22a.html. Kharitonov, E., Baroni, M., and Hupkes, D. How BPE affects memorization in transformers.CoRR, abs/2110.02782, 2021. URL https://arxiv.org/ abs/2110.02782. Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., and Carlini, N. Deduplicating train- ing data makes language models b...
-
[7]
URL https://aclanthology.org/2022. acl-long.577/. Li, R., allal, L. B., Zi, Y ., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., LI, J., Chim, J., Liu, Q., Zheltonozhskii, E., Zhuo, T. Y ., Wang, T., Dehaene, O., Lamy-Poirier, J., Monteiro, J., Gontier, N., Yee, M.- H., Umapathi, L. K., Zhu, J., Lipkin, B., Oblokulov, M., Wang, Z., Murthy, ...
work page 2022
-
[8]
URL https://openreview.net/forum? id=KoFOg41haE. Reproducibility Certification. Lin, C.-Y . ROUGE: A package for automatic evalua- tion of summaries. InText Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004. Asso- ciation for Computational Linguistics. URL https: //aclanthology.org/W04-1013/. Liu, N. F., Lin, K., Hewitt, J., Paranjape, A....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl 2004
-
[9]
URL https://aclanthology.org/2023. findings-acl.719/. Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In5th International Confer- ence on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URLhttps://openreview. net/forum?id=Byj72udxe. Nasr, M., R...
work page 2023
-
[10]
Code Llama: Open Foundation Models for Code
URL https://openreview.net/forum? id=n6SCkn2QaG. Project Gutenberg. Project gutenberg. https://www. gutenberg.org, n.d. Accessed: 2026-05-04. Rozi`ere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X., Adi, Y ., Liu, J., Remez, T., Rapin, J., Kozhevnikov, A., Evtimov, I., Bitton, J., Bhatt, M. P., Ferrer, C. C., Grattafiori, A., Xiong, W., D’ef...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
URL https://api.semanticscholar. org/CorpusID:261100919. Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y . Winogrande: An adversarial winograd schema challenge at scale. InThe Thirty-Fourth AAAI Conference on Ar- tificial Intelligence, AAAI 2020, The Thirty-Second In- novative Applications of Artificial Intelligence Confer- ence, IAAI 2020, The T...
work page 2020
-
[12]
AAAI Press, 2020. doi: 10.1609/AAAI.V34I05
-
[13]
URL https://doi.org/10.1609/aaai. v34i05.6399. Shi, W., Ajith, A., Xia, M., Huang, Y ., Liu, D., Blevins, T., Chen, D., and Zettlemoyer, L. Detecting pretrain- ing data from large language models. InThe Twelfth International Conference on Learning Representations,
-
[14]
Shilov, I., Meeus, M., and de Montjoye, Y .-A
URL https://openreview.net/forum? id=zWqr3MQuNs. Shilov, I., Meeus, M., and de Montjoye, Y .-A. The mo- saic memory of large language models.Nature Com- munications, 17(1), Jan 2026. ISSN 2041-1723. doi: 10.1038/s41467-026-68603-0. URL http://dx.doi. org/10.1038/s41467-026-68603-0. Talmor, A., Herzig, J., Lourie, N., and Berant, J. Com- monsenseqa: A ques...
-
[15]
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y
URL https://openreview.net/forum? id=7dBPm5c5ue. Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence? In Korhonen, A., Traum, D. R., and M`arquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 20...
work page 2019
-
[16]
URL https:// doi.org/10.18653/v1/p19-1472
doi: 10.18653/V1/P19-1472. URL https:// doi.org/10.18653/v1/p19-1472. Zhang, C., Ippolito, D., Lee, K., Jagielski, M., Tram`er, F., and Carlini, N. Counterfactual memorization in neural language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=67o9UQgTD0. 7 Memorization Dynamics of Fi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.