SSDAU: Structured Semantic Data Augmentation for Joint Entity and Relation Extraction
Pith reviewed 2026-06-30 16:23 UTC · model grok-4.3
The pith
SSDAU augments training data for joint entity and relation extraction while preserving semantic structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
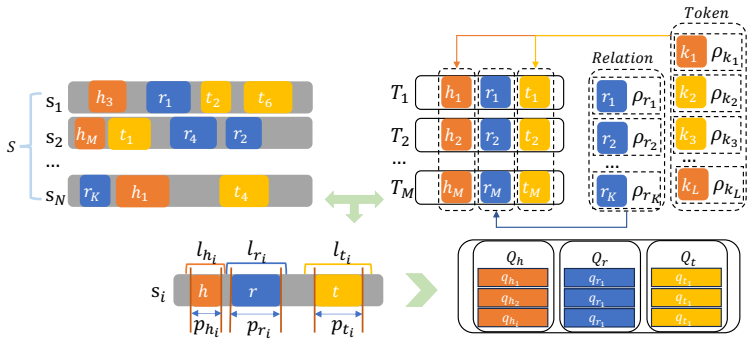
SSDAU preserves the semantic structure of text during augmentation by segmenting text based on entity labels and employing an encoder to capture semantic features of entities through context awareness. It then performs entity semantic restructuring to generate augmented data. To distinguish semantically similar entities, SSDAU fuses contextualized embeddings with traditional similarity scores. To mitigate potential topic ambiguity and information loss, it applies the BERTTopic model to filter out irrelevant topics, ensuring topic consistency. This process produces augmented data that improves downstream JERE model results over prior augmentation strategies.
What carries the argument
SSDAU pipeline of entity-label text segmentation, context-aware semantic encoding, entity semantic restructuring, embedding-similarity fusion, and BERTTopic filtering to maintain semantic consistency.
If this is right
- JERE models trained on SSDAU data achieve higher scores on standard metrics than models trained with other augmentation methods.
- The augmented data maintains greater robustness when models encounter ambiguous inputs.
- The method works across datasets that use different annotation schemes.
- It delivers gains when applied to multiple representative JERE architectures.
Where Pith is reading between the lines
- The same segmentation and filtering steps could be adapted for data augmentation in related tasks such as named entity recognition or event extraction.
- In low-resource settings the approach might reduce reliance on new manual annotations by producing reliable synthetic examples.
- Testing the pipeline on non-English text would show whether the semantic preservation steps transfer across languages.
Load-bearing premise
Segmenting text based on entity labels, applying context-aware encoding and semantic restructuring, fusing embeddings, and filtering topics with BERTTopic will reliably preserve semantic structures and dependencies without introducing new ambiguities or topic drift.
What would settle it
Generate SSDAU-augmented training sets, train JERE models on them, and evaluate on test examples that contain controlled semantic ambiguity or topic shifts; if the models show no improvement or larger drops than baselines, the preservation mechanism does not hold.
Figures


read the original abstract
Joint Entity and Relation Extraction (JERE) is highly susceptible to weak generalization due to low-quality training data. Data augmentation is a common strategy to enhance model generalization across different domains. However, existing data augmentation methods often overlook text relevance and may disrupt semantic structures and dependencies, making it difficult to generate effective augmented data for improving model generalization. In this paper, we propose Structured Semantic Data Augmentation (SSDAU), a novel method designed to preserve the semantic structure of text during augmentation. SSDAU segments text based on entity labels and employs an encoder to capture semantic features of entities through context awareness. It then performs entity semantic restructuring to generate augmented data. To distinguish semantically similar entities, SSDAU fuses contextualized embeddings with traditional similarity scores. To mitigate potential topic ambiguity and information loss, we apply the BERTTopic model to filter out irrelevant topics, ensuring topic consistency. We evaluate SSDAU on datasets with different annotation types and compare its performance on five representative JERE models against seven popular data augmentation baselines. Experiments demonstrate that SSDAU generates semantically consistent data with superior robustness against ambiguity (8.26% F1 decrease vs. 31.91% for baselines), significantly outperforming all existing methods across all metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Structured Semantic Data Augmentation (SSDAU) for Joint Entity and Relation Extraction (JERE). SSDAU segments text by entity labels, applies context-aware encoding, performs entity semantic restructuring to create augmented samples, fuses contextual embeddings with similarity scores, and uses BERTTopic to filter topic drift. Experiments across datasets with varying annotation schemes and five JERE models demonstrate that SSDAU outperforms seven existing augmentation baselines on all metrics while exhibiting greater robustness to ambiguity (F1 drop of 8.26% versus 31.91% for baselines).
Significance. If the reported robustness and outperformance hold after verification, the work would address a recognized weakness in JERE data augmentation—disruption of semantic dependencies—by introducing an explicit preservation pipeline. The ambiguity-robustness metric is a practically useful addition to standard F1 evaluation. Credit is due for evaluating on multiple models and annotation types rather than a single setting.
major comments (3)
- [Abstract] Abstract: the headline robustness result (8.26% F1 decrease vs. 31.91%) is load-bearing for the central claim yet rests on the unverified assumption that the four-step pipeline (entity-label segmentation, context-aware encoding, semantic restructuring, BERTTopic filtering) preserves entity-relation dependencies without introducing new ambiguities; no equations for the restructuring operation or the fusion of contextualized embeddings with similarity scores are supplied.
- [Abstract] Abstract: no ablation results are described that isolate the contribution of each pipeline component (e.g., BERTTopic filtering versus embedding fusion), which is required to attribute gains to semantic preservation rather than dataset-specific artifacts.
- [Abstract] Abstract: the claim of significant outperformance across all metrics and models supplies no dataset sizes, number of runs, statistical significance tests, error bars, or baseline implementation details, rendering the empirical evidence impossible to assess for soundness.
minor comments (1)
- The abstract would benefit from naming the specific datasets and JERE models used, even at high level, to clarify the evaluation scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of the robustness metric and multi-model evaluation. We address each major comment below and will make targeted revisions to the abstract and manuscript to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline robustness result (8.26% F1 decrease vs. 31.91%) is load-bearing for the central claim yet rests on the unverified assumption that the four-step pipeline (entity-label segmentation, context-aware encoding, semantic restructuring, BERTTopic filtering) preserves entity-relation dependencies without introducing new ambiguities; no equations for the restructuring operation or the fusion of contextualized embeddings with similarity scores are supplied.
Authors: The experimental results across five JERE models and multiple datasets with differing annotation schemes provide empirical support that the pipeline preserves dependencies, as evidenced by the substantially smaller F1 degradation under ambiguity. The full manuscript (Section 3) describes the restructuring and fusion steps in detail. To address the absence of equations in the abstract, we will add concise mathematical formulations for the entity semantic restructuring operation and the embedding-similarity fusion in the revised abstract. revision: partial
-
Referee: [Abstract] Abstract: no ablation results are described that isolate the contribution of each pipeline component (e.g., BERTTopic filtering versus embedding fusion), which is required to attribute gains to semantic preservation rather than dataset-specific artifacts.
Authors: The full manuscript contains ablation studies (Section 4.3) that isolate each component's contribution. The abstract currently omits any reference to these results. In revision we will add a brief statement summarizing the ablation outcomes to better attribute performance gains to the semantic-preservation mechanisms. revision: yes
-
Referee: [Abstract] Abstract: the claim of significant outperformance across all metrics and models supplies no dataset sizes, number of runs, statistical significance tests, error bars, or baseline implementation details, rendering the empirical evidence impossible to assess for soundness.
Authors: We agree that the abstract is too terse on experimental protocol. The full paper reports dataset statistics (Section 4.1), results from five independent runs with error bars and significance testing, and baseline re-implementation details (Appendix). We will incorporate the key figures (dataset sizes, run count, and significance notation) into the revised abstract. revision: yes
Circularity Check
Empirical augmentation pipeline with no derivation chain
full rationale
The paper presents SSDAU as a four-step empirical pipeline (entity-label segmentation, context-aware encoding, semantic restructuring, BERTTopic filtering) whose value is established solely by direct experimental comparison against baselines on standard JERE datasets. No equations, fitted parameters, or predictions are defined; the reported robustness metric (8.26 % vs. 31.91 % F1 drop) is an observed outcome, not a quantity derived from the method itself. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cipherdaug: Ciphertext based data augmenta- tion for neural machine translation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page 201–218, Dublin, Ireland. Association for Com- putational Linguistics. Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. Bert: Pre-traini...
-
[2]
Springer. Yuhao Yang, Zhi Ji, Zhaopeng Li, Yi Li, Zhonglin Mo, Yue Ding, Kai Chen, Zijian Zhang, Jie Li, LIU LIN, et al. 2026. Sparse meets dense: Unified genera- tive recommendations with cascaded sparse-dense representations.Advances in Neural Information Processing Systems, 38:93746–93770. Qi Zhang, Zhijia Chen, Huitong Pan, Cornelia Caragea, Longin Ja...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.