Semantically Structured Mixture-of-Experts for Compositional Robotic Manipulation
Pith reviewed 2026-05-25 04:16 UTC · model grok-4.3
The pith
A mixture-of-experts diffusion policy routes robot actions to semantic skill experts using vision-language model annotations for better multi-task efficiency and transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that grounding MoE routing in semantic task structure via a VLM-supervised skill predictor and dual inter-modal and intra-modal contrastive alignment produces more efficient, interpretable, and transferable diffusion policies for compositional robotic manipulation than prior routing methods based on noise or latent statistics.
What carries the argument
The VLM-supervised skill predictor that assigns action chunks to phase-specific experts, reinforced by inter-modal and intra-modal contrastive losses to maintain semantic consistency.
If this is right
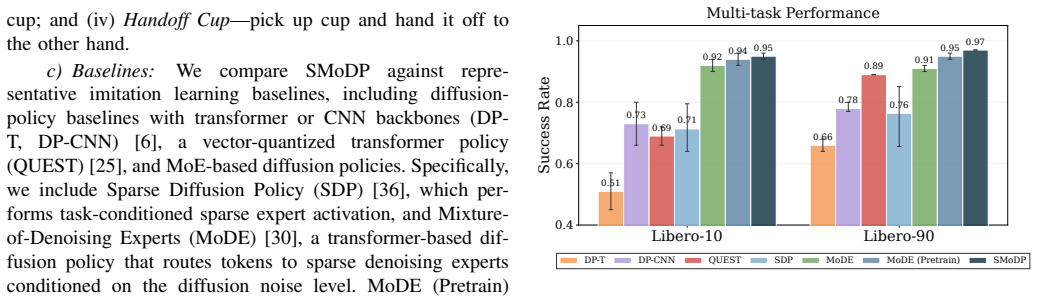
- The approach outperforms representative diffusion and MoE-based baselines on multi-task robotic manipulation benchmarks.
- Parameter efficiency improves because only the experts relevant to the current behavioral phase are activated.
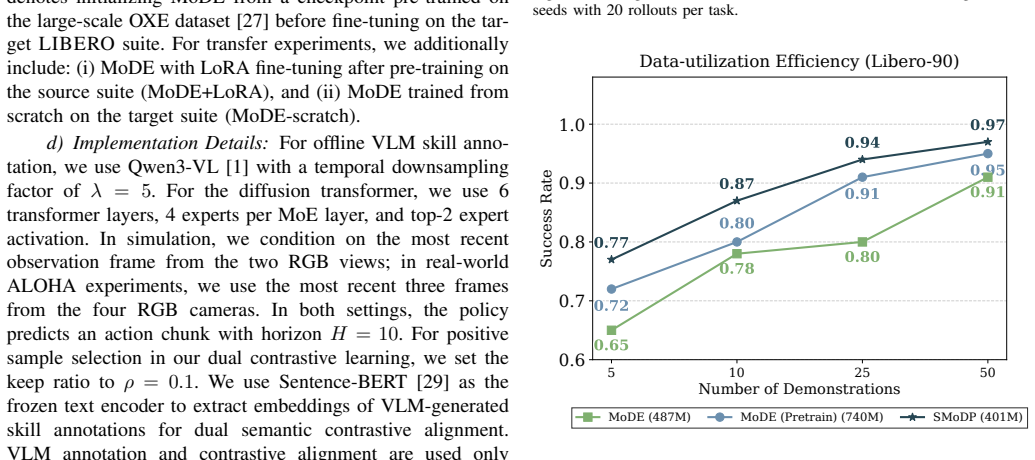
- Compositional transfer to novel tasks becomes feasible through parameter-efficient fine-tuning without retraining the full model.
Where Pith is reading between the lines
- The same semantic routing pattern could be tested in non-robotic sequential domains such as planning or video generation where tasks break into reusable phases.
- If the dual contrastive losses prove robust, they offer a template for aligning other multimodal routing systems without requiring task-specific reward signals.
- The separation of a lightweight predictor from the heavy diffusion backbone suggests a practical route to modular robot policies that can be updated independently.
Load-bearing premise
That offline VLM annotations supply reliable, unbiased supervision for behavioral phases and that the proposed dual contrastive losses produce routing decisions that generalize beyond the training distribution.
What would settle it
Replacing the VLM-derived skill labels with random or noisy phase assignments during training and testing, then measuring whether performance and transfer advantages disappear.
Figures






read the original abstract
Diffusion-based policies have established a new standard for precise robotic manipulation but face a critical scalability bottleneck: high-performance models are computationally expensive, while lightweight alternatives often fail to generalize across diverse multi-task environments. Mixture-of-Experts (MoE) architectures offer a promising path to efficiency by activating only a subset of parameters. However, existing MoE routing mechanisms typically rely on low-level noise or latent statistics, ignoring the compositional nature of manipulation tasks. This can fragment reusable behaviors across experts, limiting interpretability and transferability. We introduce Semantically Structured Mixture-of-Experts Diffusion Policy (SMoDP) for compositional robotic manipulation, a framework that grounds expert specialization in semantic task structure. SMoDP leverages a lightweight, inference-time skill predictor, supervised by offline annotations from Vision-Language Models (VLMs), to route action chunks to experts specialized for specific behavioral phases. To ensure robust assignment, we propose a dual contrastive alignment strategy that grounds multi-modal observations in language-defined skill semantics (Inter-modal) while enforcing routing consistency across visually distinct but functionally related behaviors (Intra-modal). Our approach outperforms representative diffusion and MoE-based baselines on multi-task benchmarks with significantly improved parameter efficiency and demonstrates effective compositional transfer to novel tasks through parameter-efficient fine-tuning. Project website: https://deng-cy20.github.io/SMoDP/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantically Structured Mixture-of-Experts Diffusion Policy (SMoDP), a framework that grounds MoE routing in semantic task structure for diffusion-based robotic manipulation policies. A lightweight skill predictor, supervised by offline VLM annotations, routes action chunks to phase-specialized experts; dual contrastive losses (inter-modal and intra-modal) enforce alignment between multi-modal observations and language-defined skill semantics. The central claims are outperformance over diffusion and MoE baselines on multi-task benchmarks, improved parameter efficiency, and effective compositional transfer to novel tasks via parameter-efficient fine-tuning.
Significance. If the empirical results and generalization claims hold under rigorous evaluation, the work could meaningfully advance scalable, interpretable robotic policies by replacing low-level routing heuristics with semantically grounded expert specialization, offering a path to better compositional transfer without full retraining.
major comments (3)
- [Abstract] Abstract: the claim that the approach 'outperforms representative diffusion and MoE-based baselines on multi-task benchmarks with significantly improved parameter efficiency' is stated without any quantitative metrics, baseline specifications, ablation results, or statistical tests, so the central empirical claim cannot be assessed.
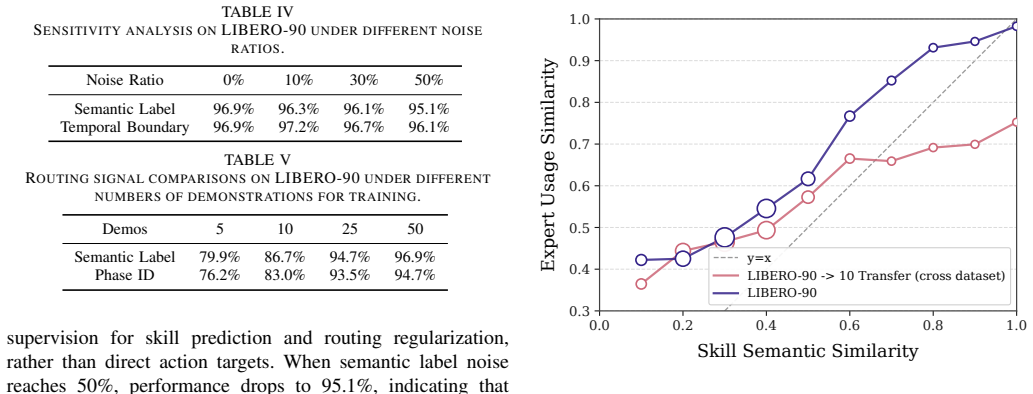
- [Approach] Approach section (and any experimental validation): the routing mechanism depends on offline VLM annotations supplying accurate, unbiased labels for behavioral phases, yet no ablation on annotation quality, human agreement rates, or failure cases traceable to VLM mislabeling is provided; this directly undermines the claimed robustness of the dual contrastive losses and the transfer results.
- [Method] Method: no equations, loss formulations, or routing derivations appear in the provided text, preventing verification that the inter-modal and intra-modal contrastive objectives produce generalizable expert specialization rather than overfitting to VLM visual cues.
minor comments (1)
- [Abstract] Abstract: the project website URL is given but no statement on code or model release is included, which would aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'outperforms representative diffusion and MoE-based baselines on multi-task benchmarks with significantly improved parameter efficiency' is stated without any quantitative metrics, baseline specifications, ablation results, or statistical tests, so the central empirical claim cannot be assessed.
Authors: Abstracts are conventionally brief summaries. The full quantitative results, including specific metrics, baseline details, ablations, and statistical tests, appear in Section 4 and the appendix. We will revise the abstract to incorporate key quantitative highlights for improved clarity. revision: yes
-
Referee: [Approach] Approach section (and any experimental validation): the routing mechanism depends on offline VLM annotations supplying accurate, unbiased labels for behavioral phases, yet no ablation on annotation quality, human agreement rates, or failure cases traceable to VLM mislabeling is provided; this directly undermines the claimed robustness of the dual contrastive losses and the transfer results.
Authors: We agree that explicit validation of VLM annotation quality is valuable. The current manuscript does not contain such an ablation. We will add an analysis of human-VLM agreement rates and discussion of potential mislabeling cases in the revision, showing how the dual contrastive objectives provide robustness. revision: yes
-
Referee: [Method] Method: no equations, loss formulations, or routing derivations appear in the provided text, preventing verification that the inter-modal and intra-modal contrastive objectives produce generalizable expert specialization rather than overfitting to VLM visual cues.
Authors: The method section of the full manuscript contains the routing equations, inter-modal and intra-modal contrastive loss formulations, and derivations (Section 3). If these elements were omitted from the reviewed version, we will ensure they are explicitly included and numbered in the revision to allow verification of the specialization mechanism. revision: yes
Circularity Check
No significant circularity; derivation relies on external VLM supervision
full rationale
The paper introduces SMoDP by grounding expert routing in offline VLM annotations and dual contrastive losses, with no equations, derivations, or fitted parameters presented that reduce to self-definition or self-citation. The central mechanism is supervised by an external model (VLMs) rather than by any internal fit or renaming of results. No load-bearing self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work are described. This matches the default case of a self-contained empirical architecture whose claims rest on external data sources rather than circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLM annotations supply reliable semantic labels for manipulation skill phases
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SMoDP leverages a lightweight, inference-time skill predictor, supervised by offline annotations from Vision-Language Models (VLMs), to route action chunks to experts specialized for specific behavioral phases... dual contrastive alignment strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
chunk-consistent, skill-based routing... language-grounded skill semantics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report,
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shu- tong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixua...
-
[2]
URL https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A vi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Svip: Sequencing bimanual vi- suomotor policies with object-centric motion primitives
Yizhou Chen, Hang Xu, Dongjie Yu, Zeqing Zhang, Yi Ren, and Jia Pan. Svip: Sequencing bimanual vi- suomotor policies with object-centric motion primitives. arXiv preprint arXiv:2506.18825, 2025
-
[6]
Baiye Cheng, Tianhai Liang, Suning Huang, Maanping Shao, Feihong Zhang, Botian Xu, Zhengrong Xue, and Huazhe Xu. Moe-dp: An moe-enhanced diffusion policy for robust long-horizon robotic manipulation with skill decomposition and failure recovery.arXiv preprint arXiv:2511.05007, 2025
-
[7]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[8]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
2022
-
[9]
Ce Hao, Xuanran Zhai, Yaohua Liu, and Harold Soh. Ab- stracting robot manipulation skills via mixture-of-experts diffusion policies.arXiv preprint arXiv:2601.21251, 2026
-
[10]
Denoising diffusion probabilistic models.Advances in neural infor- mation processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural infor- mation processing systems, 33:6840–6851, 2020
2020
-
[11]
Mentor: Mixture-of-experts net- work with task-oriented perturbation for visual reinforce- ment learning
Suning Huang, Zheyu Aqa Zhang, Tianhai Liang, Yihan Xu, Zhehao Kou, Chenhao Lu, Guowei Xu, Zhengrong Xue, and Huazhe Xu. Mentor: Mixture-of-experts net- work with task-oriented perturbation for visual reinforce- ment learning. InInternational Conference on Machine Learning, 2025
2025
-
[12]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pert...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Adaptive mixtures of local experts
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991
1991
-
[14]
Cr-moe: Consistent routed mixture-of-experts for scaling contrastive learn- ing.Transactions on Machine Learning Research, 2024
Ziyu Jiang, Guoqing Zheng, Yu Cheng, Ahmed Hassan Awadallah, and Zhangyang Wang. Cr-moe: Consistent routed mixture-of-experts for scaling contrastive learn- ing.Transactions on Machine Learning Research, 2024
2024
-
[15]
Hierarchical mixtures of experts and the em algorithm.Neural computation, 6(2):181–214, 1994
Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm.Neural computation, 6(2):181–214, 1994
1994
-
[16]
Elucidating the design space of diffusion-based genera- tive models.Advances in neural information processing systems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based genera- tive models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[17]
3d diffuser actor: Policy diffusion with 3d scene representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3d diffuser actor: Policy diffusion with 3d scene representations. InConference on Robot Learning, pages 1949–1974. PMLR, 2025
1949
-
[18]
Droid: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. In Robotics: Science and Systems, 2024
2024
-
[19]
Gshard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Rep- resentations, 2021
2021
-
[20]
Task reconstruction and extrapolation forπ 0 using text latent, 2025
Quanyi Li. Task reconstruction and extrapolation forπ 0 using text latent, 2025. URL https://arxiv.org/abs/2505. 03500
2025
-
[21]
Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution
Zhixuan Liang, Yao Mu, Hengbo Ma, Masayoshi Tomizuka, Mingyu Ding, and Ping Luo. Skilldiffuser: Interpretable hierarchical planning via skill abstractions in diffusion-based task execution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16467–16476, 2024
2024
-
[22]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023
2023
-
[23]
Høeg, Shaoxiong Yao, Yunzhu Li, Kris Hauser, and Yilun Du
Chaoqi Liu, Haonan Chen, Sigmund H. Høeg, Shaoxiong Yao, Yunzhu Li, Kris Hauser, and Yilun Du. Flexi- ble multitask learning with factorized diffusion policy. IEEE Robotics and Automation Letters, 11(4):4697– 4704, 2026. doi: 10.1109/LRA.2026.3664611
-
[24]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, 2025
2025
-
[25]
Diff- control: A stateful diffusion-based policy for imitation learning
Xiao Liu, Yifan Zhou, Fabian Weigend, Shubham Son- awani, Shuhei Ikemoto, and Heni Ben Amor. Diff- control: A stateful diffusion-based policy for imitation learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7453–7460. IEEE, 2024
2024
-
[26]
Quest: Self-supervised skill abstractions for learning continuous control.Advances in Neural Information Processing Systems, 37:4062–4089, 2024
Atharva Mete, Haotian Xue, Albert Wilcox, Yongxin Chen, and Animesh Garg. Quest: Self-supervised skill abstractions for learning continuous control.Advances in Neural Information Processing Systems, 37:4062–4089, 2024
2024
-
[27]
Load balancing mixture of experts with similarity preserving routers, 2025
Nabil Omi, Siddhartha Sen, and Ali Farhadi. Load balancing mixture of experts with similarity preserving routers, 2025. URL https://arxiv.org/abs/2506.14038
-
[28]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[29]
Consistency policy: Accelerated visuo- motor policies via consistency distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, and Jeannette Bohg. Consistency policy: Accelerated visuo- motor policies via consistency distillation. InRobotics: Science and Systems, 2024
2024
-
[30]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sen- tence embeddings using siamese bert-networks. InPro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Com- putational Linguistics, 11 2019. URL https://arxiv.org/ abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning
Moritz Reuss, Jyothish Pari, Pulkit Agrawal, and Rudolf Lioutikov. Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning. In International Conference on Learning Representations, 2025
2025
-
[32]
Scaling vision with sparse mixture of experts.Advances in Neural Informa- tion Processing Systems, 34:8583–8595, 2021
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, Andr ´e Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts.Advances in Neural Informa- tion Processing Systems, 34:8583–8595, 2021
2021
-
[33]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[34]
Steer: Flexible robotic manipulation via dense language grounding
Laura Smith, Alex Irpan, Montserrat Gonzalez Arenas, Sean Kirmani, Dmitry Kalashnikov, Dhruv Shah, and Ted Xiao. Steer: Flexible robotic manipulation via dense language grounding. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16517–16524. IEEE, 2025
2025
-
[35]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[36]
Cwcl: Cross-modal transfer with contin- uously weighted contrastive loss.Advances in Neural Information Processing Systems, 36:78496–78513, 2023
Rakshith Sharma Srinivasa, Jaejin Cho, Chouchang Yang, Yashas Malur Saidutta, Ching-Hua Lee, Yilin Shen, and Hongxia Jin. Cwcl: Cross-modal transfer with contin- uously weighted contrastive loss.Advances in Neural Information Processing Systems, 36:78496–78513, 2023
2023
-
[37]
Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning
Yixiao Wang, Yifei Zhang, Mingxiao Huo, Thomas Tian, Xiang Zhang, Yichen Xie, Chenfeng Xu, Pengliang Ji, Wei Zhan, Mingyu Ding, et al. Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning. In Conference on Robot Learning, pages 649–665. PMLR, 2025
2025
-
[38]
Discrete policy: Learning disentangled action space for multi-task robotic manipulation
Kun Wu, Yichen Zhu, Jinming Li, Junjie Wen, Ning Liu, Zhiyuan Xu, and Jian Tang. Discrete policy: Learning disentangled action space for multi-task robotic manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8811–8818. IEEE, 2025
2025
-
[39]
Bikc+: Bimanual hierarchical imitation with keypose- conditioned coordination-aware consistency policies
Hang Xu, Yizhou Chen, Dongjie Yu, Yi Ren, and Jia Pan. Bikc+: Bimanual hierarchical imitation with keypose- conditioned coordination-aware consistency policies. IEEE Transactions on Automation Science and Engineer- ing, 23:1064–1079, 2025
2025
-
[40]
Dongjie Yu, Hang Xu, Yizhou Chen, Yi Ren, and Jia Pan. Bikc: Keypose-conditioned consistency pol- icy for bimanual robotic manipulation.arXiv preprint arXiv:2406.10093, 2024
-
[41]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[42]
Affordance-based robot manipulation with flow matching, 2025
Fan Zhang and Michael Gienger. Affordance-based robot manipulation with flow matching, 2025. URL https:// arxiv.org/abs/2409.01083. APPENDIX A. Details of Offline Semantic Skill Abstraction We use Qwen3-VL [1] to automatically generate fine- grained skill annotations from task demonstrations without requiring a pre-defined skill set. The procedure has two...
-
[43]
Identify the primitive actions involved in the task (e.g., approach, pick up, place)
-
[44]
- End time: When the action’s completion is first verifiable
For each action, determine the temporal boundaries using video frame analysis: - Start time: When the action first becomes visible. - End time: When the action’s completion is first verifiable. - Use 0.5-second intervals as the minimal time unit. - Ensure boundaries cover the entire { time_length}-second duration
-
[45]
approach object1
For each boundary, provide a concise description of the robot’s action: - Omit the subject. - Use verb-noun structure (e.g., "approach object1", "place object2 on object3"). - Each boundary should only contain one action. - Refer to objects using names from { object_list_str}. Provide the final output in JSON format as follows: <ANSWER> Explanation of the...
-
[46]
Understand the skill descriptions and the video
-
[47]
- End time: When the skill’s completion is first verifiable
For each skill, determine the temporal boundaries using video frame analysis: - Start time: When the skill’s action first becomes visible. - End time: When the skill’s completion is first verifiable. - Use 0.5-second intervals as the minimal time unit. - Ensure boundaries cover the entire { time_length}-second duration. - Skill must be temporally contiguo...
-
[48]
task_skill_count
Keep each skill’s description unchanged from the provided list. Provide the final output in JSON format as follows: <ANSWER> Explanation of the identified actions and their temporal boundaries. </ANSWER> {{ "task_skill_count": <int>, "skill_details": [ {{ "skill_number": 1, "temporal_boundary": [<start_time >, <end_time>], "description": "< original_skill...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.