CoSPlay: Cooperative Self-Play at Test-Time with Self-Generated Code and Unit Test
Pith reviewed 2026-06-30 15:52 UTC · model grok-4.3
The pith
CoSPlay lets LLMs jointly refine self-generated code and unit tests at test time without ground truth, matching RLVR performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
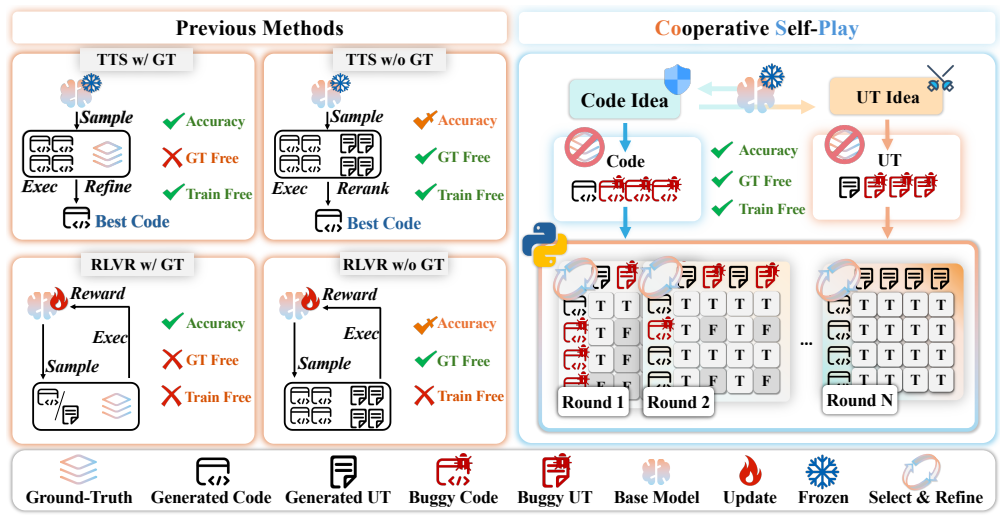
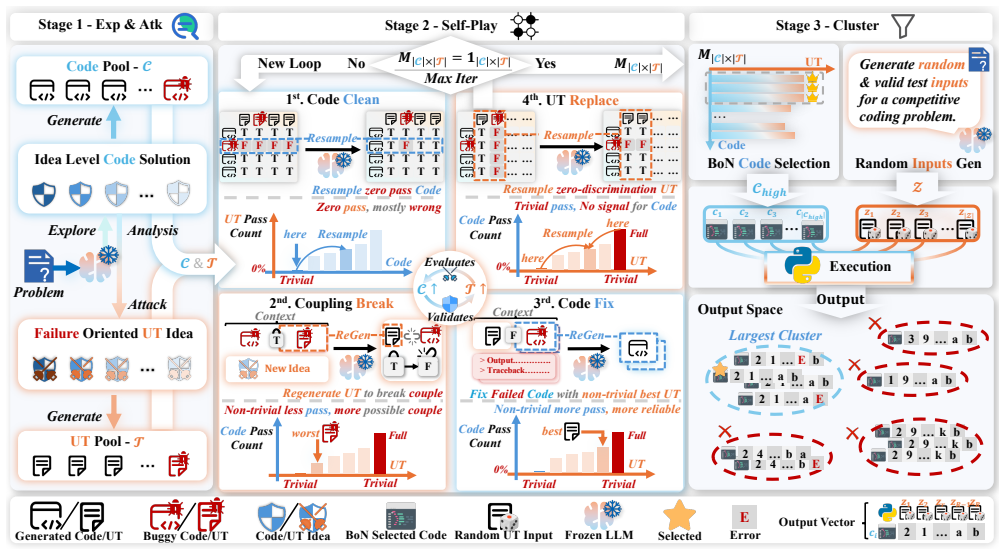
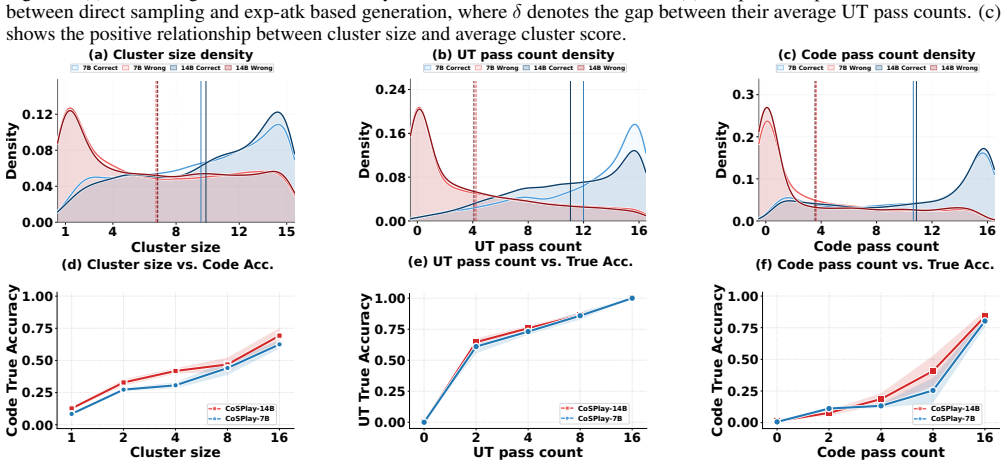
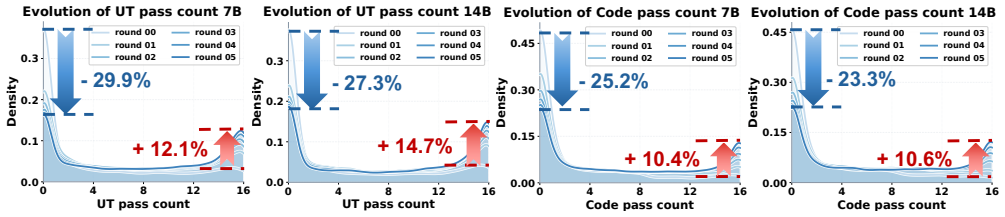
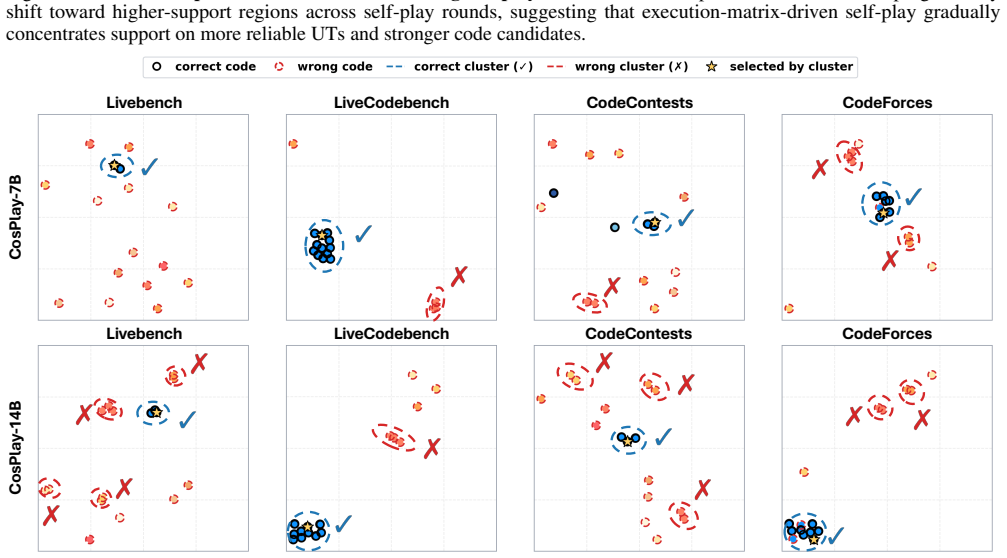
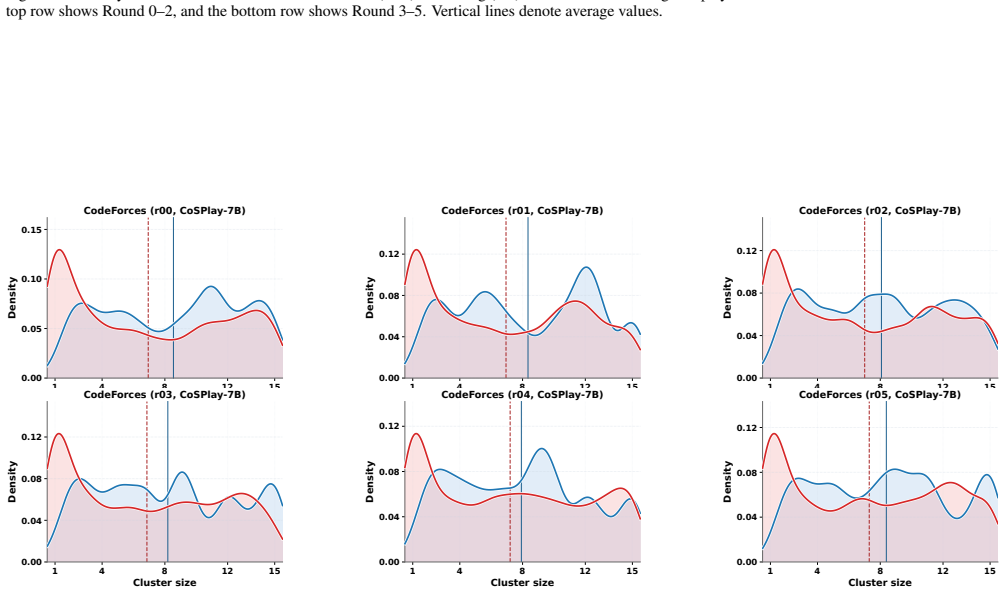
CoSPlay is a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge.
What carries the argument
Bidirectional pass-count signals from the Code-UT execution matrix for mutual pruning of weak codes and unreliable unit tests, combined with output-consensus clustering for tie resolution.
If this is right
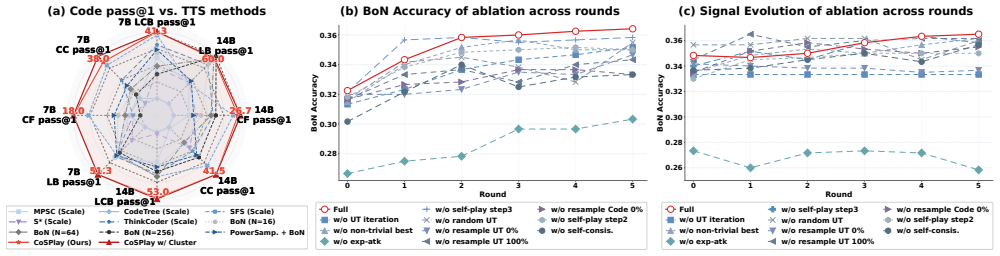
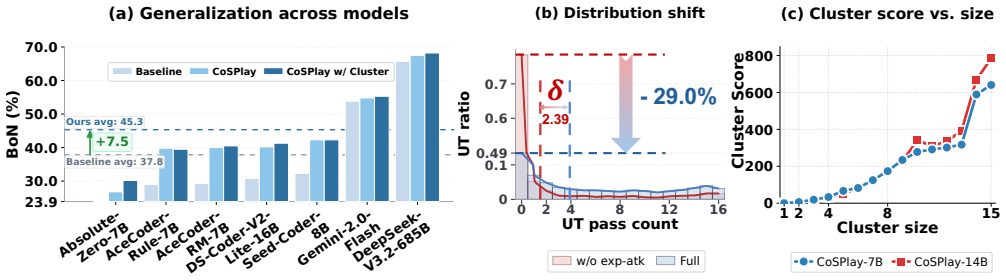
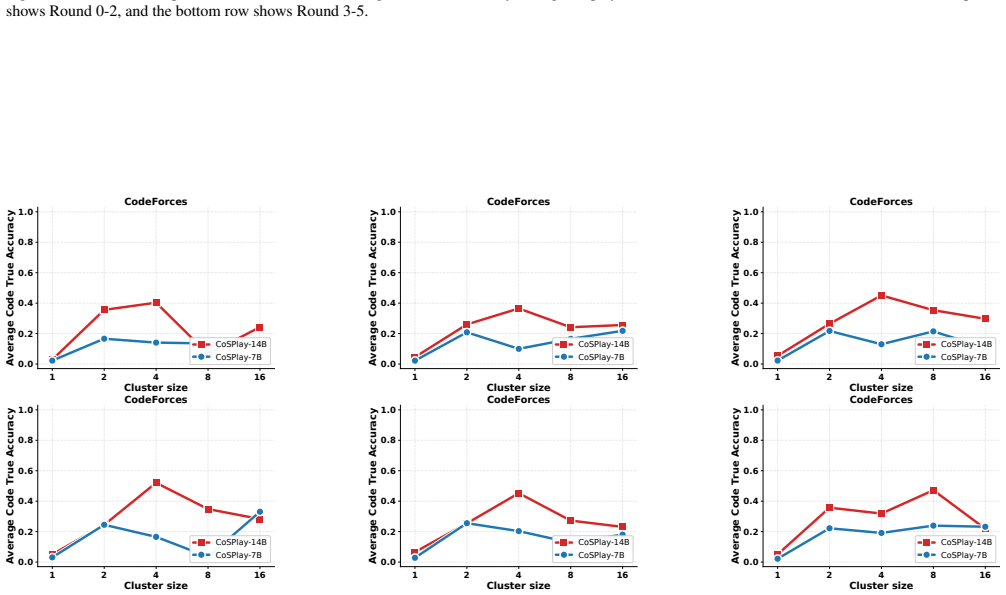
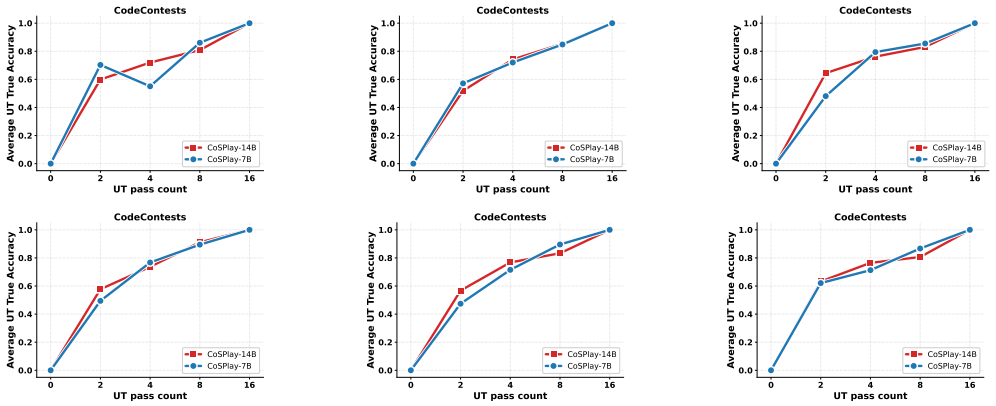
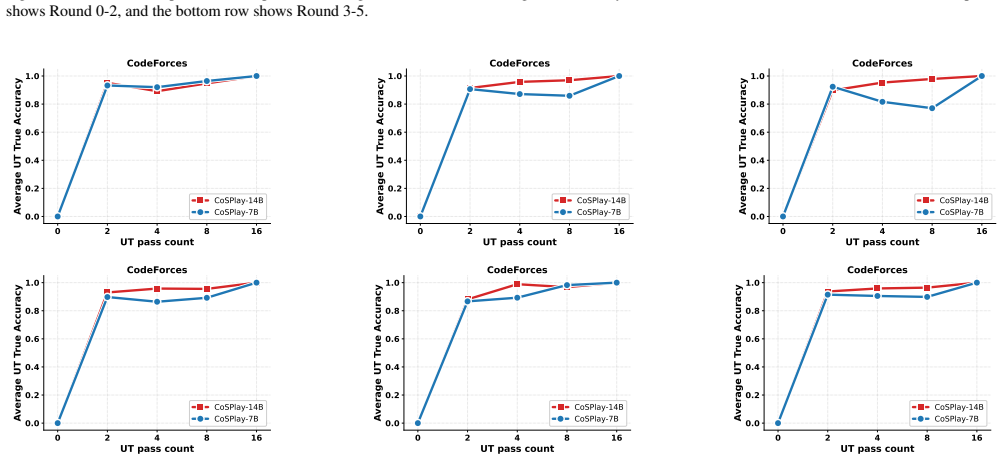
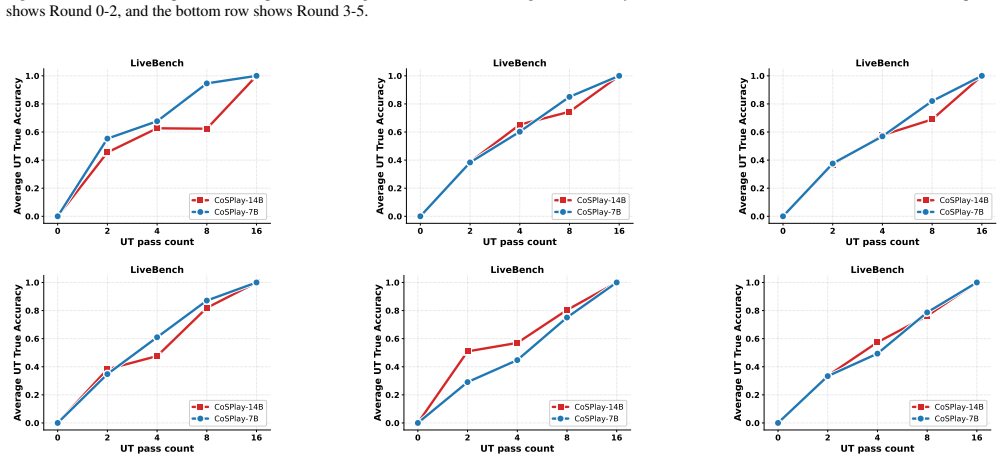
- CoSPlay raises average Best-of-N accuracy from 22.1% to 33.2% on Qwen2.5-7B-Instruct.
- Unit test accuracy rises from 14.6% to 78.3% on the same model.
- It matches or surpasses the RLVR model CURE-7B without any training.
- Applying it to CURE-7B yields a further 5.7% Best-of-N gain.
- The gains hold across backbones and continue as token budget increases.
Where Pith is reading between the lines
- The same co-evolution pattern could extend to other verifiable generation tasks such as theorem proving where partial correctness signals exist.
- Internal consistency among model outputs may substitute for external oracles in some inference settings.
- Widespread adoption could lower the data and compute needed to reach high performance in code models.
- The method opens a path to purely inference-time improvement loops that do not require separate training stages.
Load-bearing premise
Bidirectional pass-count signals from the Code-UT execution matrix can reliably distinguish and prune weak codes from unreliable unit tests without external ground truth, and output-consensus clustering selects the correct code when pass counts tie.
What would settle it
A controlled experiment on a benchmark with hidden ground truth where the method's final selected code matches the hidden ground truth no more often than a random choice among the top pass-count candidates.
Figures








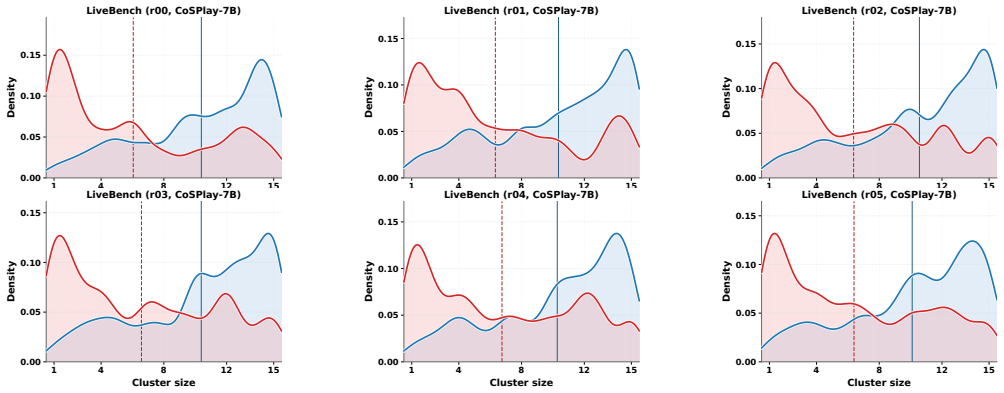
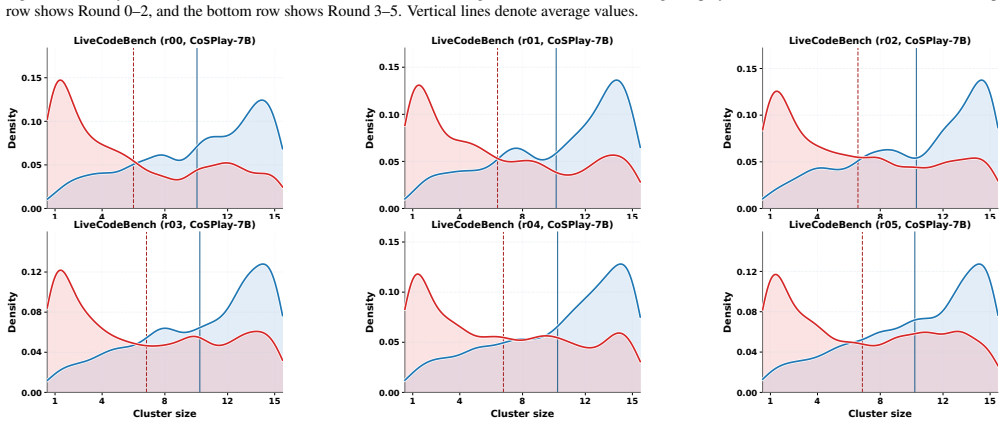
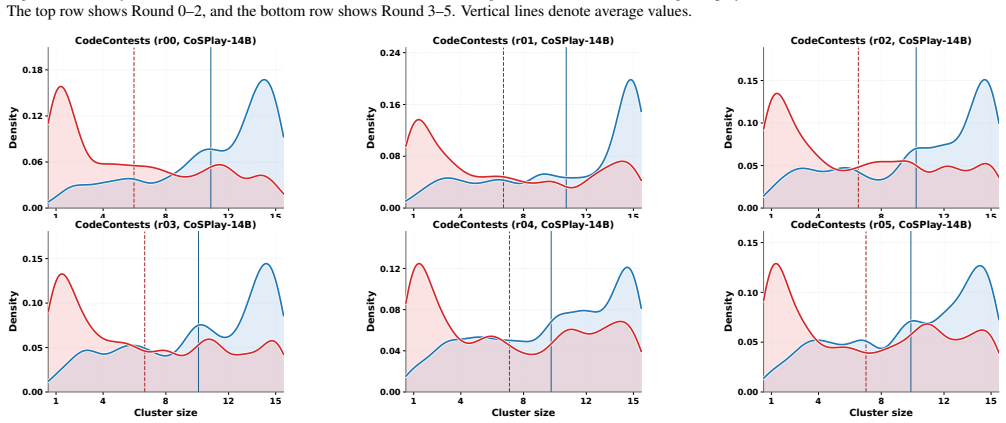
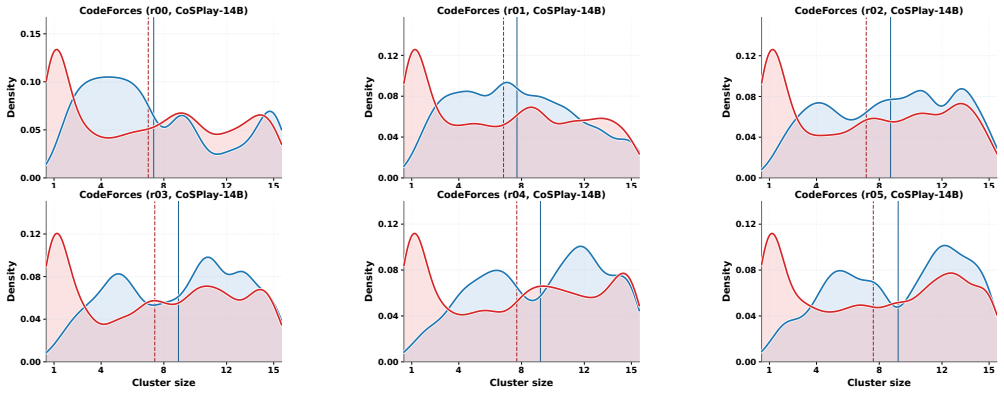
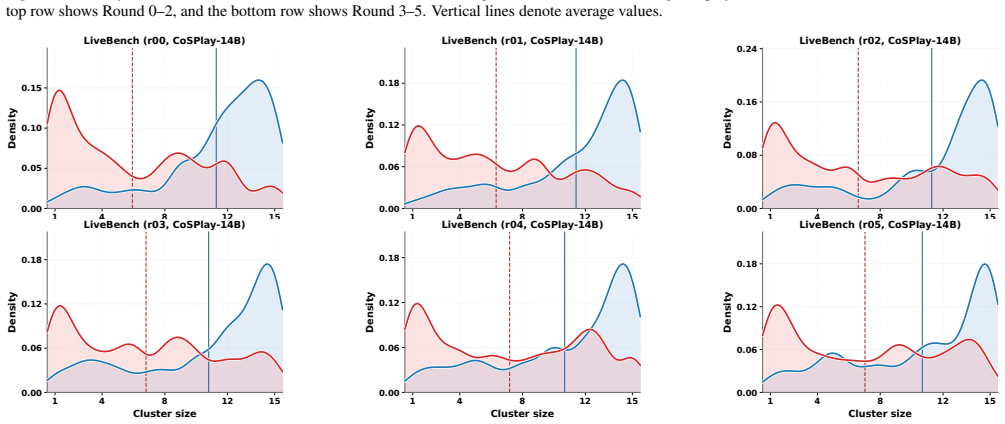
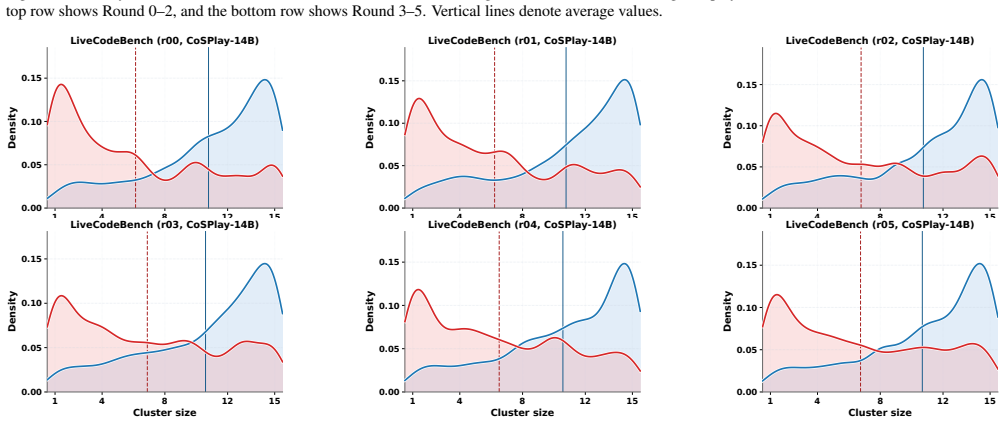
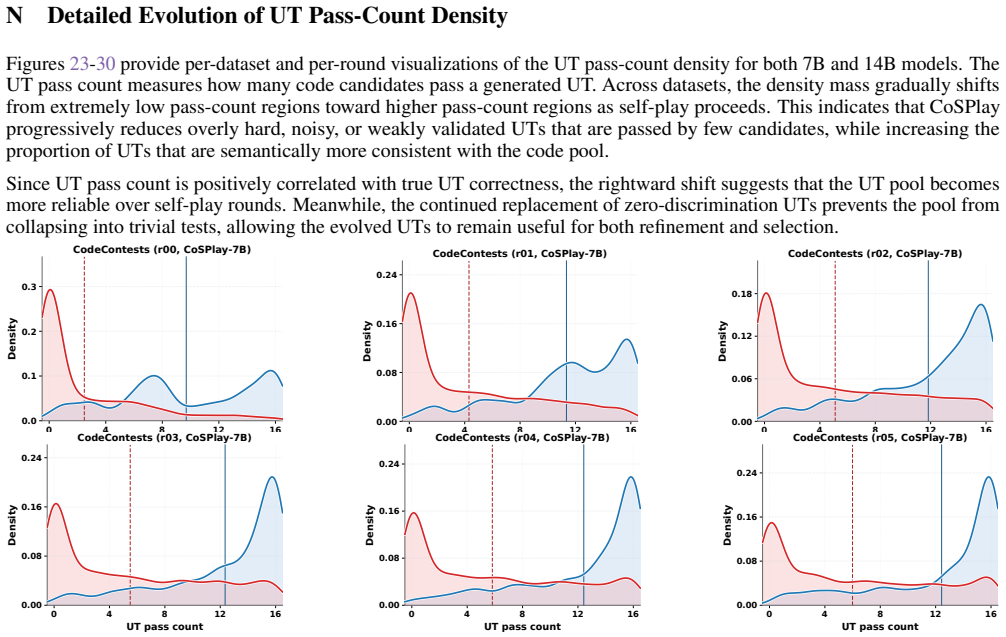
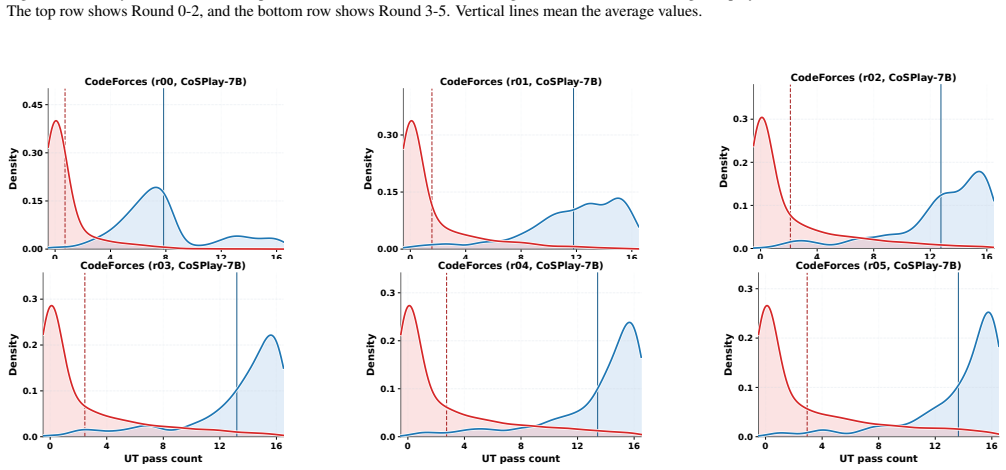

















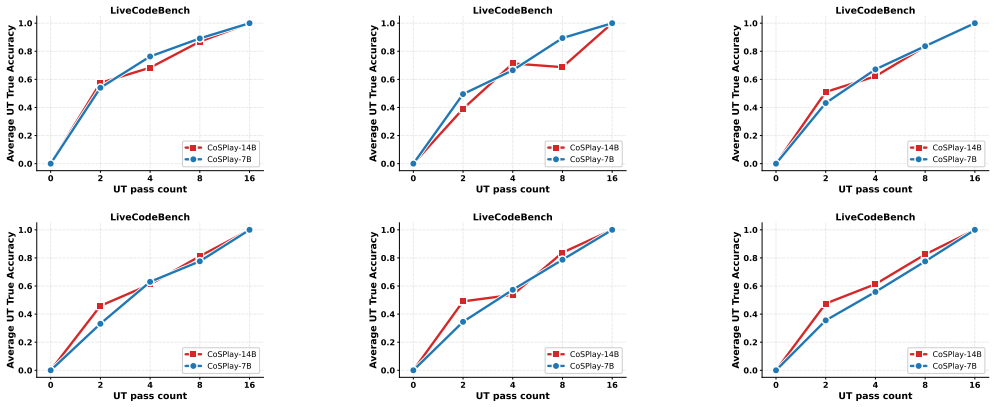
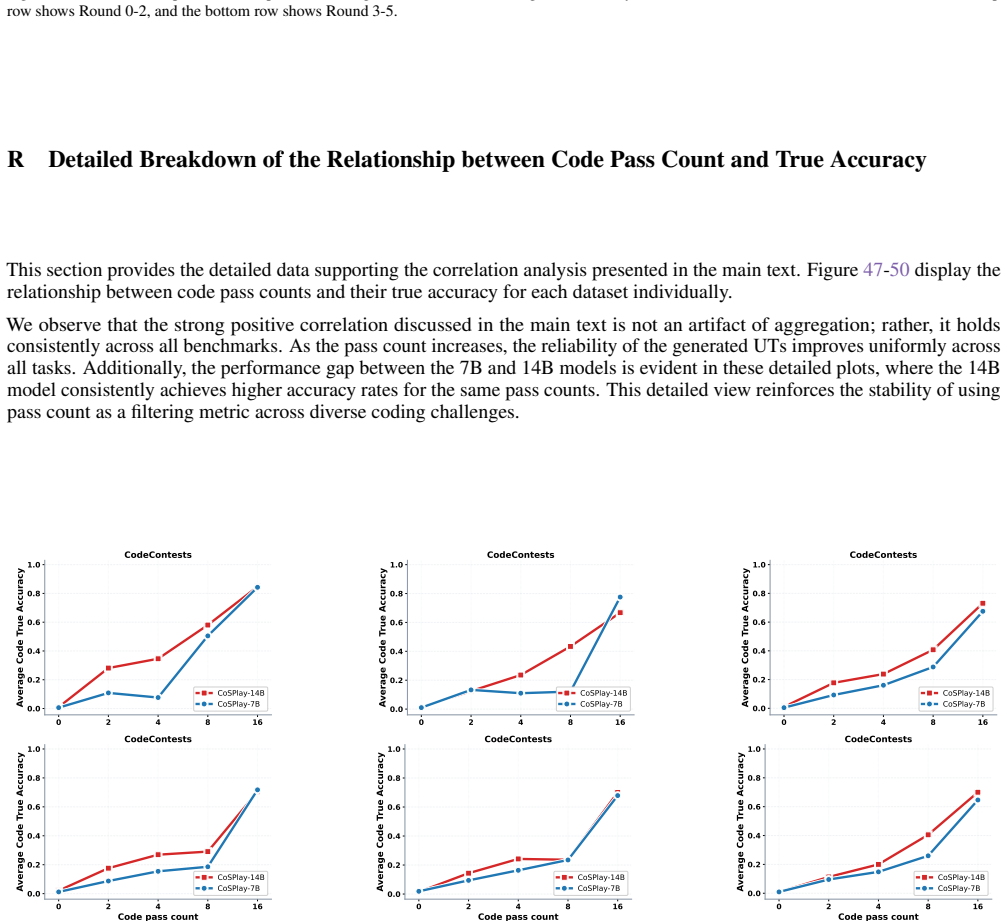
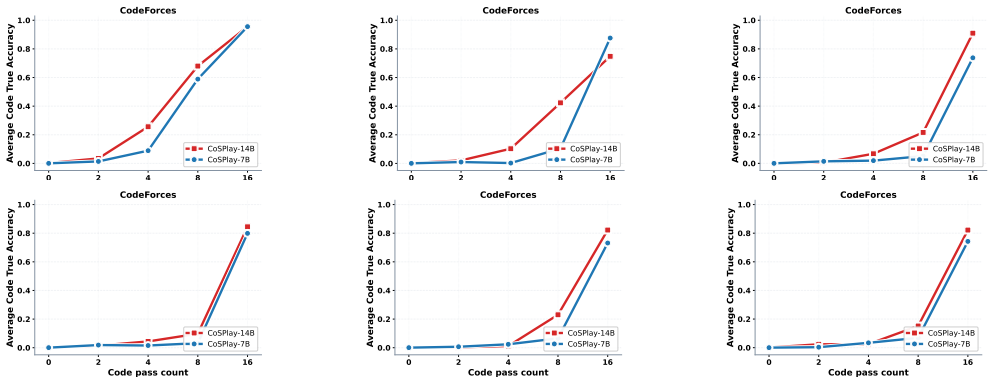
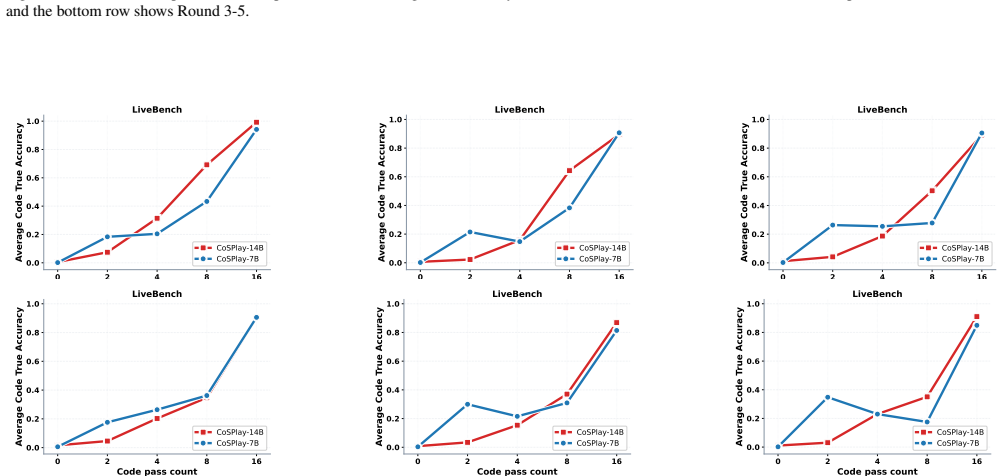








read the original abstract
Recently, Reinforcement Learning with Verifiable Rewards (RLVR) and Test-Time Scaling (TTS) have advanced LLM code generation through executable verification. Yet Ground-Truth Unit Tests (GT UTs) remain a bottleneck: SOTA RLVR methods require them for costly training, while existing TTS methods lose competitiveness without them. This motivates GT-free TTS, where existing methods directly use self-generated UTs to refine and select code candidates. Yet such UTs are often noisy or spuriously coupled with wrong code, and UT quality in turn cannot be validated without reliable code. The key challenge is therefore to jointly improve both. To this end, we present CoSPlay, a GT-free, training-free framework that jointly improves codes and UTs through cooperative self-play. It first explores diverse solution ideas and identifies their potential failure modes to produce discriminative UT ideas. It then uses bidirectional pass-count signals from the Code-UT execution matrix to iteratively prune or fix weak codes and refresh or replace unreliable UTs, letting the two pools co-evolve. Finally, when multiple codes remain tied at the highest pass count, it picks the final code from the largest output-consensus cluster, since correct codes agree on the same inputs while wrong codes diverge. Experiments on four challenging benchmarks show that CoSPlay on Qwen2.5-7B-Instruct improves average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%, matching or surpassing the RLVR model CURE-7B. When applied to CURE-7B, it further improves BoN by 5.7%. CoSPlay also generalizes across diverse backbones and outperforms GT-free TTS baselines under comparable token budgets, with continued gains as the budget scales up. These results suggest a scalable inference strategy for competitive code generation without any GT data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoSPlay, a training-free, ground-truth-free test-time scaling framework for LLM code generation. It generates diverse code and unit-test candidates, then uses iterative bidirectional pass-count signals from the Code-UT execution matrix to prune weak codes and unreliable tests, allowing the two pools to co-evolve. When pass counts tie, it selects the code from the largest output-consensus cluster. Experiments claim that applying CoSPlay to Qwen2.5-7B-Instruct raises average BoN from 22.1% to 33.2% and UT accuracy from 14.6% to 78.3%, matching or exceeding the RLVR baseline CURE-7B, with further gains when applied to CURE-7B itself; the method also scales with token budget across backbones.
Significance. If the empirical claims and the correctness of the co-evolution loop hold, the work offers a practical inference-time alternative to RLVR that removes dependence on ground-truth unit tests while achieving competitive or superior performance. The bidirectional pruning plus consensus tie-breaker is a concrete, reproducible mechanism that could be adopted by other TTS pipelines.
major comments (3)
- [Method description of iterative pruning / Code-UT matrix update] The central pruning step (bidirectional pass-count signals from the Code-UT execution matrix) is load-bearing for the GT-free claim, yet the manuscript provides no analysis or counter-example showing that the iteration cannot converge to a mutually consistent but incorrect code-UT cluster. The skeptic concern is not addressed: when wrong codes share failure signatures, the corresponding wrong UTs can achieve comparable aggregate pass counts, and the output-consensus tie-breaker is applied only after pruning, so it cannot correct an earlier mis-pruning. A concrete test (e.g., controlled injection of consistent error modes on a synthetic benchmark) is required.
- [Experiments / main results table] Table reporting the main results (BoN and UT accuracy gains on four benchmarks) does not include ablations that isolate the contribution of the bidirectional pruning versus the final consensus clustering, nor does it report failure cases where the matrix-based selection chose an incorrect code. Without these, it is impossible to verify that the reported 11-point BoN lift is attributable to the claimed mechanism rather than to increased sampling diversity alone.
- [Experiments / comparison to CURE-7B] The claim that CoSPlay matches or surpasses CURE-7B (an RLVR model trained with GT UTs) is central, but the manuscript does not report whether the same token budget was used for the RLVR baseline or whether CURE-7B was allowed additional inference-time scaling. This comparison is therefore not yet on equal footing.
minor comments (2)
- [Method] Notation for the Code-UT execution matrix (row/column sums) is introduced without an explicit equation or pseudocode listing the update rules; adding a compact algorithm box would improve reproducibility.
- [Abstract / Experiments] The abstract states “continued gains as the budget scales up,” but the corresponding scaling plot or table is not referenced in the text; ensure every quantitative claim points to a specific figure or table.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and proposing revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Method description of iterative pruning / Code-UT matrix update] The central pruning step (bidirectional pass-count signals from the Code-UT execution matrix) is load-bearing for the GT-free claim, yet the manuscript provides no analysis or counter-example showing that the iteration cannot converge to a mutually consistent but incorrect code-UT cluster. The skeptic concern is not addressed: when wrong codes share failure signatures, the corresponding wrong UTs can achieve comparable aggregate pass counts, and the output-consensus tie-breaker is applied only after pruning, so it cannot correct an earlier mis-pruning. A concrete test (e.g., controlled injection of consistent error modes on a synthetic benchmark) is required.
Authors: We agree that an analysis of potential convergence to incorrect but consistent clusters is important for validating the GT-free claim. The current manuscript relies on empirical results across benchmarks but does not include synthetic counter-examples or failure mode analysis for the iterative loop. To address this, we will add a new experiment section with a synthetic benchmark involving injected consistent error modes. This will demonstrate the pruning dynamics and show how the bidirectional signals and consensus selection interact in controlled settings. revision: yes
-
Referee: [Experiments / main results table] Table reporting the main results (BoN and UT accuracy gains on four benchmarks) does not include ablations that isolate the contribution of the bidirectional pruning versus the final consensus clustering, nor does it report failure cases where the matrix-based selection chose an incorrect code. Without these, it is impossible to verify that the reported 11-point BoN lift is attributable to the claimed mechanism rather than to increased sampling diversity alone.
Authors: We acknowledge that the main results table lacks component ablations and failure case reporting. The experiments focus on end-to-end performance, but to isolate the bidirectional pruning from consensus clustering, we will include additional ablation tables in the revised manuscript. We will also add analysis of cases where incorrect codes were selected, discussing the conditions under which the method fails. revision: yes
-
Referee: [Experiments / comparison to CURE-7B] The claim that CoSPlay matches or surpasses CURE-7B (an RLVR model trained with GT UTs) is central, but the manuscript does not report whether the same token budget was used for the RLVR baseline or whether CURE-7B was allowed additional inference-time scaling. This comparison is therefore not yet on equal footing.
Authors: This is a fair point regarding the fairness of the comparison. The manuscript states that comparisons are under comparable token budgets, but does not provide the specific numbers for CURE-7B inference. In the revision, we will explicitly report the token budgets used for CoSPlay and for evaluating CURE-7B, ensuring the comparison is on equal footing. If discrepancies exist, we will adjust the experiments accordingly. revision: yes
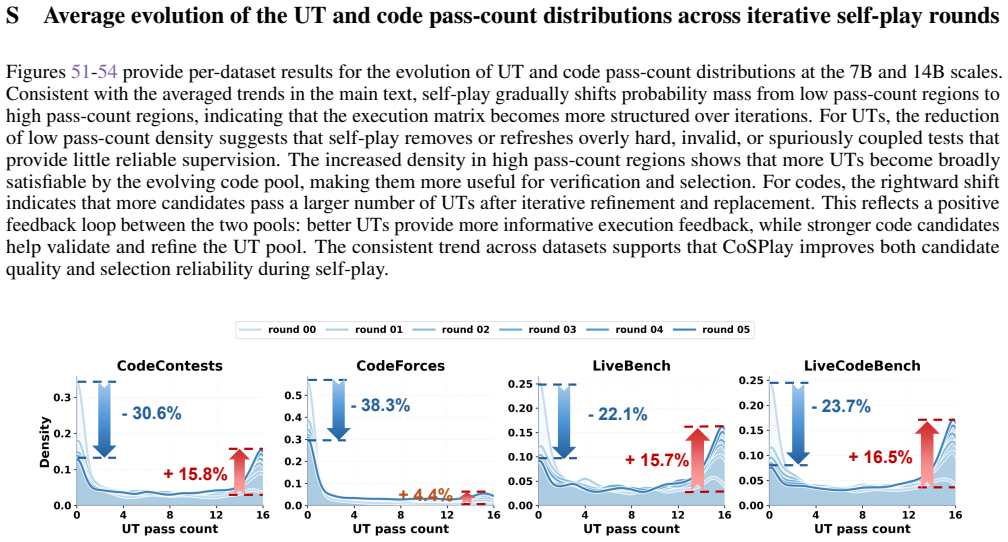
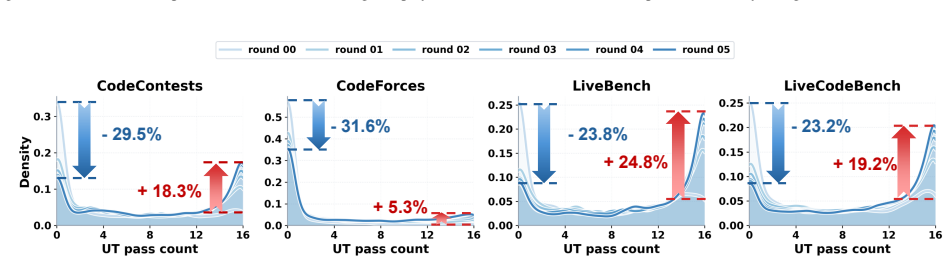
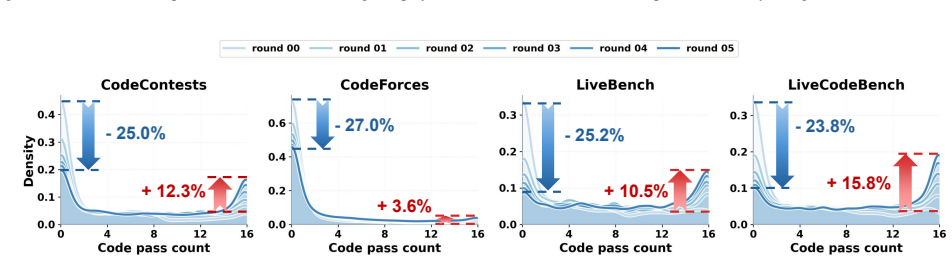
Circularity Check
No significant circularity; derivation grounded in external execution signals
full rationale
The CoSPlay method generates candidate codes and unit tests, executes them to populate a Code-UT matrix, then uses row/column pass-count sums for iterative pruning and an output-consensus tie-breaker. These signals originate from actual program execution against the generated artifacts rather than from model logits, fitted parameters, or prior self-citations. No equation or step reduces the claimed improvement to a self-definition, a renamed input, or a load-bearing self-citation chain. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, and et. al. Qwen technical report.arXiv, 2023
2023
-
[2]
Pütz, and Thomas Bartz-Beielstein
Vekil Bekmyradov, Noah C. Pütz, and Thomas Bartz-Beielstein. Llms taking shortcuts in test generation: A study with sap hana and leveldb.arXiv, 2026
2026
-
[3]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv, 2024
2024
-
[4]
Codet: Code generation with generated tests
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. Codet: Code generation with generated tests. InICLR, 2023
2023
-
[5]
Revisit self-debugging with self-generated tests for code generation
Xiancai Chen, Zhengwei Tao, Kechi Zhang, Changzhi Zhou, Xinyu Zhang, Wanli Gu, Yuanpeng He, Mengdi Zhang, Xunliang Cai, Haiyan Zhao, and Zhi Jin. Revisit self-debugging with self-generated tests for code generation. InACL Long, 2025
2025
-
[6]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, and et. al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 2025
2025
-
[7]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InEMNLP, 2023
2023
-
[8]
Repair-r1: Better test before repair.arXiv, 2025
Haichuan Hu, Xiaochen Xie, and Quanjun Zhang. Repair-r1: Better test before repair.arXiv, 2025
2025
-
[9]
Enhancing large language models in coding through multi- perspective self-consistency
Baizhou Huang, Shuai Lu, Xiaojun Wan, and Nan Duan. Enhancing large language models in coding through multi- perspective self-consistency. InACL 2024 (Long Papers), 2024
2024
-
[10]
Qwen2.5-coder technical report.arXiv, 2024
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report.arXiv, 2024
2024
-
[11]
Multi-turn code generation through single-step rewards
Arnav Kumar Jain, Gonzalo Gonzalez-Pumariega, Wayne Chen, Alexander M Rush, Wenting Zhao, and Sanjiban Choudhury. Multi-turn code generation through single-step rewards. InICML, 2025
2025
-
[12]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In ICLR, 2025
2025
-
[13]
Reasoning with sampling: Your base model is smarter than you think.arXiv, 2025
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think.arXiv, 2025
2025
-
[14]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, 2023
2023
-
[15]
Learning to generate unit test via adversarial reinforcement learning
Dongjun Lee, Changho Hwang, and Kimin Lee. Learning to generate unit test via adversarial reinforcement learning. arXiv, 2025
2025
-
[16]
Gonzalez, and Ion Stoica
Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E. Gonzalez, and Ion Stoica. S*: Test time scaling for code generation. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[17]
Codetree: Agent-guided tree search for code generation with large language models
Jierui Li, Hung Le, Yingbo Zhou, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Codetree: Agent-guided tree search for code generation with large language models. InNAACL, 2025
2025
-
[18]
Competition-level code generation with alphacode.Science, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 2022
2022
-
[19]
SFS: Smarter code space search improves LLM inference scaling
Jonathan Light, Yue Wu, Yiyou Sun, Wenchao Yu, Yanchi Liu, Xujiang Zhao, Ziniu Hu, Haifeng Chen, and Wei Cheng. SFS: Smarter code space search improves LLM inference scaling. InICLR, 2025
2025
-
[20]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR, 2024
2024
-
[21]
Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. InNeurIPS, 2023. 12
2023
-
[22]
Code-r1: Reproducing r1 for code with reliable rewards
Jiawei Liu and Lingming Zhang. Code-r1: Reproducing r1 for code with reliable rewards. 2025
2025
-
[23]
Inference-time scaling for generalist reward modeling.arXiv, 2025
Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. Inference-time scaling for generalist reward modeling.arXiv, 2025
2025
-
[24]
Dynamic scaling of unit tests for code reward modeling
Zeyao Ma, Xiaokang Zhang, Jing Zhang, Jifan Yu, Sijia Luo, and Jie Tang. Dynamic scaling of unit tests for code reward modeling. InACL Long, 2025
2025
-
[25]
Codeforces.Hugging Face repository, 2025
Guilherme Penedo, Anton Lozhkov, Hynek Kydlíˇcek, Loubna Ben Allal, Edward Beeching, Agustín Piqueres Lajarín, Quentin Gallouédec, Nathan Habib, Lewis Tunstall, and Leandro von Werra. Codeforces.Hugging Face repository, 2025
2025
-
[26]
Learning to generate unit tests for automated debugging
Archiki Prasad, Elias Stengel-Eskin, Justin Chen, Zaid Khan, and Mohit Bansal. Learning to generate unit tests for automated debugging. InCOLM, 2025
2025
-
[27]
Seed-coder: Let the code model curate data for itself.arXiv, 2025
ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Shen Zheng, Anxiang Zhang, Kaibo Liu, Daoguang Zan, Tao Sun, Jinhua Zhu, Shulin Xin, Dong Huang, Yetao Bai, Lixin Dong, Chao Li, Jianchong Chen, Hanzhi Zhou, Yifan Huang, Guanghan Ning, Xierui Song, Jiaze Chen, Siyao Liu, Kai Shen, Liang Xiang, and Yonghui Wu. Seed-coder: Let the code...
2025
-
[28]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023
2023
-
[29]
Mastering the game of go with deep neural networks and tree search.Nature, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search.Nature, 2016
2016
-
[30]
Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv, 2017
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv, 2017
2017
-
[31]
Effective large language model debugging with best-first tree search
Jialin Song, Jonathan Raiman, and Bryan Catanzaro. Effective large language model debugging with best-first tree search. arXiv, 2024
2024
-
[32]
Code repair with LLMs gives an exploration-exploitation tradeoff
Hao Tang, Keya Hu, Jin Peng Zhou, Si Cheng Zhong, Wei-Long Zheng, Xujie Si, and Kevin Ellis. Code repair with LLMs gives an exploration-exploitation tradeoff. InNeurIPS, 2024
2024
-
[33]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, and et. al. Kimi k1.5: Scaling reinforcement learning with llms.arXiv, 2025
2025
-
[34]
Hendryx, Summer Yue, and Hugh Zhang
Evan Z Wang, Federico Cassano, Catherine Wu, Yunfeng Bai, William Song, Vaskar Nath, Ziwen Han, Sean M. Hendryx, Summer Yue, and Hugh Zhang. Planning in natural language improves LLM search for code generation. InICLR, 2025
2025
-
[35]
CURE: Co-evolving coders and unit testers via reinforcement learning
Yinjie Wang, Ling Yang, Ye Tian, Ke Shen, and Mengdi Wang. CURE: Co-evolving coders and unit testers via reinforcement learning. InNeurIPS, 2025
2025
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[37]
Livebench: A challenging, contamination-limited llm benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination-limited llm benchmark. InICLR, 2025
2025
-
[38]
Teaching language models to critique via reinforcement learning
Zhihui Xie, Jie chen, Liyu Chen, Weichao Mao, Jingjing Xu, and Lingpeng Kong. Teaching language models to critique via reinforcement learning. InICML, 2025
2025
-
[39]
Griffiths, Yuan Cao, and Karthik R Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InNeurIPS, 2023
2023
-
[40]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and et. al. Dapo: An open-source llm reinforcement learning system at scale. InNeurIPS, 2025
2025
-
[41]
Reasoning through execution: Unifying process and outcome rewards for code generation
Zhuohao Yu, Weizheng Gu, Yidong Wang, Xingru Jiang, Zhengran Zeng, Jindong Wang, Wei Ye, and Shikun Zhang. Reasoning through execution: Unifying process and outcome rewards for code generation. InICML, 2025
2025
-
[42]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InNeurIPS, 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InNeurIPS, 2025. 13
2025
-
[43]
ACECODER: Acing coder RL via automated test-case synthesis
Huaye Zeng, Dongfu Jiang, Haozhe Wang, Ping Nie, Xiaotong Chen, and Wenhu Chen. ACECODER: Acing coder RL via automated test-case synthesis. InACL Long, 2025
2025
-
[44]
Focused-DPO: Enhancing code generation through focused preference optimization on error-prone points
Kechi Zhang, Ge Li, Jia Li, Yihong Dong, Jia Li, and Zhi Jin. Focused-DPO: Enhancing code generation through focused preference optimization on error-prone points. InACL findings, 2025
2025
-
[45]
Thinking before running! efficient code generation with thorough exploration and optimal refinement
Xiaoqing Zhang, Yuhan Liu, Flood Sung, Xiuying Chen, Shuo Shang, and Rui Yan. Thinking before running! efficient code generation with thorough exploration and optimal refinement. InACL findings, 2025
2025
-
[46]
o1-coder: an o1 replication for coding.arXiv, 2024
Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, and Jitao Sang. o1-coder: an o1 replication for coding.arXiv, 2024
2024
-
[47]
Absolute zero: Reinforced self-play reasoning with zero data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. InNeurIPS, 2025
2025
-
[48]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham M. Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: RL post-training amplifies behaviors learned in pretraining. InCOLM, 2025
2025
-
[49]
Debug like a human: A large language model debugger via verifying runtime execution step by step
Li Zhong, Zilong Wang, and Jingbo Shang. Debug like a human: A large language model debugger via verifying runtime execution step by step. InACL findings, 2024. 14 Appendix A Theory Analysis 17 A.1 Analysis of Pass-Count Signals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 A.2 Analysis of Execution-Consensus Clustering . ...
2024
-
[50]
Both the posterior odds ratio and the posterior probability of correctness are strictly increasing ins
If q1 > q0, then r >1 . Both the posterior odds ratio and the posterior probability of correctness are strictly increasing ins
-
[51]
The support count changes neither the posterior odds ratio nor the posterior probability of correctness
If q1 =q 0, then r= 1 . The support count changes neither the posterior odds ratio nor the posterior probability of correctness
-
[52]
Both the posterior odds ratio and the posterior probability of correctness are strictly decreasing ins
If q1 < q 0, then 0< r <1 . Both the posterior odds ratio and the posterior probability of correctness are strictly decreasing ins. Moreover, Eq. (11) shows that the posterior odds ratio depends onsthrough the exponential factorr s. Corollary A.2(Posterior convergence at a fixed support ratio).Under the binomial model in Theorem A.1, let m be the number o...
-
[53]
Hence, when η > η ⋆, D(η)>0 , and the posterior probability of correctness converges exponentially fast to1
If q1 > q0, then D is strictly increasing. Hence, when η > η ⋆, D(η)>0 , and the posterior probability of correctness converges exponentially fast to1. When η < η ⋆, D(η)<0 , and the posterior probability of correctness converges exponentially fast to0
-
[54]
Hence, when η < η ⋆, the posterior probability of correctness converges exponentially fast to1, and whenη > η ⋆, it converges exponentially fast to0
If q1 < q 0, then D is strictly decreasing, so the sign direction is reversed. Hence, when η < η ⋆, the posterior probability of correctness converges exponentially fast to1, and whenη > η ⋆, it converges exponentially fast to0
-
[55]
Left") elifleft_sum == right_sum: print(
If η=η ⋆, then D(η) = 0, and the posterior odds remain only at constant order. No exponential decision is obtained. This proves the claim. A.2 Analysis of Execution-Consensus Clustering Execution-Consensus Clustering is applied after BoN filtering. Let Chigh be the high-scoring set retained by BoN, and draw a codecfrom this set. All probabilities below ar...
2025
-
[56]
We have 1 test casewiththeinputvaluesm= 10,a= 4,b= 4,andc= 11
-
[57]
3.amonkeys (4 monkeys) want to sitinrow 1
There are 10 seatsineach of the 2 rows, so a total of 20 seats. 3.amonkeys (4 monkeys) want to sitinrow 1. 4.bmonkeys (4 monkeys) want to sitinrow 2. 5.cmonkeys (11 monkeys) have no preference
-
[58]
We need to maximize the number of monkeys seated, following their seating preferences
-
[59]
We first seat theamonkeysinrow 1andbmonkeysinrow 2, which takes up 4 seatsineach row
-
[60]
There are10−4 = 6seats leftinrow 1and10−4 = 6seats leftinrow 2
-
[61]
•After seating 6 monkeysinrow 1, we have11−6 = 5monkeys left
We now seat thecmonkeys, startingwiththosewithno preference: •We can seat up to 6 of these monkeysinrow 1 since there are 6 seats left. •After seating 6 monkeysinrow 1, we have11−6 = 5monkeys left. •We can then seat the remaining 5 monkeysinrow 2 since there are 6 seats left
-
[62]
Fixed Code from CoSPlay-14B Analysis: The errorisa logical error (wrong answer),asthe code runs but produces the wrong output
Therefore, we have seated 4 monkeysinrow 1, 4 monkeysinrow 2,and6 monkeysinrow 1 plus 5 monkeysinrow 2, which totals to4 + 4 + 6 + 5 = 19monkeys. Fixed Code from CoSPlay-14B Analysis: The errorisa logical error (wrong answer),asthe code runs but produces the wrong output. Let's trace the logic to find the divergence from the expected output. Given: •The i...
-
[63]
If`a > m`, then the number of monkeys that can sit in row 1 is limited to`m`
-
[64]
If`b > m`, then the number of monkeys that can sit in row 2 is limited to`m`
-
[65]
The remaining seats after seating monkeys with preferences are`2 * m - (a + b)`
-
[66]
Left")elif left_sum == right_sum: print(
If there are more no-preference monkeys than remaining seats, only the available seats can be filled. Fixed Code def max_seats(m, a, b, c): # Limit monkeys preferring row 1 and row 2 to the available seats a = min(a, m) b = min(b, m) # Calculate the remaining seats after seating monkeys with preferences remaining_seats = 2 * m - (a + b) # Monkeys with no ...
-
[67]
second observation 60
-
[68]
Just output the numbered observations, nothingelse
third observation •Do NOT addanyextra text, headings,orexplanations beforeorafter thelist. Just output the numbered observations, nothingelse. <|im_end|> <|im_start|>assistant Prompt for specific solution idea generation <|im_start|>system You are an expert Python programmer. <|im_end|> <|im_start|>user You will be given an competitive programming questio...
-
[69]
first derived observation
-
[70]
second derived observation
-
[71]
Just output the numbered observations, nothingelse
third derived observation •Do NOT addanyextra text, headings,orexplanations beforeorafter thelist. Just output the numbered observations, nothingelse. <|im_end|> <|im_start|>assistant: Prompt for code generation from solution idea <|im_start|>system You are a helpful assistanthelpuser solve problems. <|im_end|> <|im_start|>user You need to write Python sc...
-
[72]
Unit Test Input
third attack idea •Do NOT addanyextra text, headings,orexplanations beforeorafter thelist. Just output the numbered observations, nothingelse. <|im_end|> <|im_start|>assistant Prompt for UT input generation from UT attack idea <|im_start|>system You are an expert Software Engineering Tester designing unit test to uncover the potential bugs. <|im_end|> <|i...
-
[73]
Use only the given unit testinput;ifit seems mismatched to the problemformat, donotinvent missing data
-
[74]
Explanation
Match the EXAMPLE's output format exactly (spacing/line breaks/order); no brackets/commas unless shown; empty output -> blank line. # Response Format Explanation: [Your step-by-step logic tracing here] Test output: [Raw Output Data ONLY] Let’s think step by step. <|im_end|> <|im_start|>assistant Prompt for generating non-coupling UT # Role You are an expe...
-
[75]
Do NOT copy the previous attempt
Recompute strictlyfromthe giveninput;iftheinput formatseems off, donotinvent missing data. Do NOT copy the previous attempt
-
[76]
Actual Execution Output
Match the EXAMPLE's output format exactly (spacing/line breaks/order); no brackets/commas unless shown; empty output→blank line. # Response Format Explanation: [Your step-by-step logic tracing here] Test output: [Raw Output Data ONLY] Let’s think step by step. Prompt for code fixing <|im_start|>system You are an expert programmer designing codeforcompetit...
-
[77]
Each line represents ONE independent testinput
-
[78]
Each testinputmust strictly follow theinput format andconstraints of the problem
-
[79]
Each line MUST startwiththe exact prefix: CASE|
-
[80]
Do NOT include parameter names, variable labels, code,or anyexplanatory text
After CASE|, output ONLY the rawinputvaluesincorrect order. Do NOT include parameter names, variable labels, code,or anyexplanatory text. Problem: **Problem:** ``` {problem} ``` You MUST outputinthe following EXACTformat: CASE|```<input fortest case>``` <|im_end|> <|im_start|>assistant Prompt for direct code generation <|im_start|>system You are a helpful...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.