PathNavigate: A Training-Free Pathology Agent with Surprise-Guided Scan and Shared Slide Memory for Whole-Slide Image VQA
Pith reviewed 2026-05-25 05:03 UTC · model grok-4.3
The pith
PathNavigate first builds a slide-specific map of abnormal regions at low magnification using shared memory, then searches only inside that map for question-relevant high-resolution evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
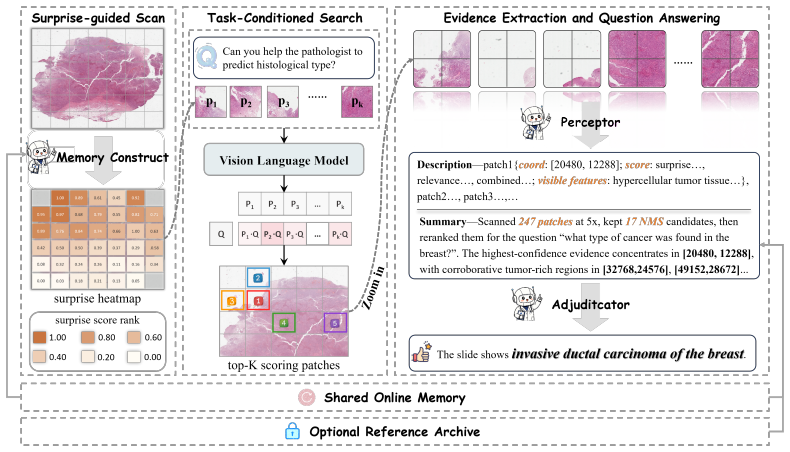
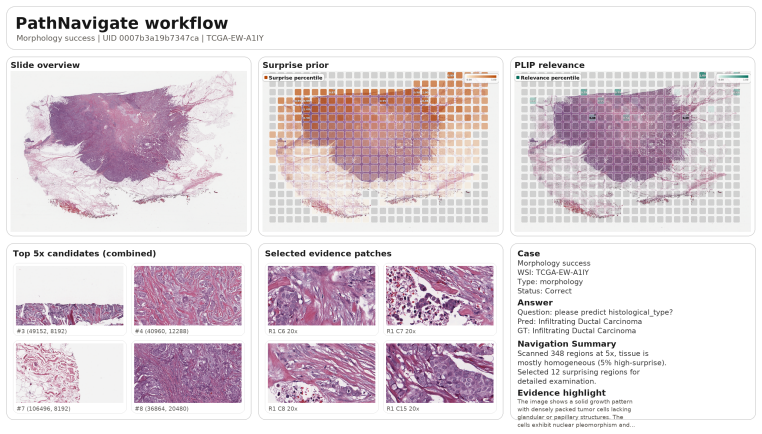
PathNavigate establishes that a shared online memory over frozen pathology features can produce a low-magnification surprise field marking an abnormal-region pool before any question matching occurs; question-conditioned PLIP relevance is then restricted to this pool to select high-magnification search targets; local evidence is extracted and answered by a frozen perceptor-adjudicator stack that re-uses the same memory as slide-level context, yielding improved accuracy and efficiency on WSI-VQA and SlideBench-BCNB without task-specific training.
What carries the argument
The surprise field generated by the shared online memory module over frozen features, which identifies abnormal regions independently of the query before relevance filtering begins.
If this is right
- Evidence selection becomes independent of whether the query explicitly names the morphology, allowing the agent to surface relevant regions that query-first methods overlook.
- The same online memory serves both the initial scan and the final readout, providing consistent slide-level context without additional modules.
- Navigation stays training-free because only frozen feature extractors and relevance scorers are used throughout.
- Evidence trajectories are produced by the two-stage process and are therefore directly inspectable by a pathologist.
- The design operates under a fixed inspection budget by limiting high-magnification visits to the surprise pool.
Where Pith is reading between the lines
- The same surprise-first scan could be tested on other gigapixel domains such as remote-sensing imagery where initial anomaly detection narrows later query-driven search.
- Replacing the frozen feature extractor with a newer one would directly update the surprise field without any retraining of the agent itself.
- The approach implicitly assumes that low-magnification features correlate strongly with the presence of high-magnification diagnostic morphology; measuring that correlation on held-out slides would quantify the assumption's strength.
- If the shared memory is made persistent across multiple slides from the same case, the agent could carry context between slides without extra engineering.
Load-bearing premise
The low-magnification surprise field reliably contains the regions holding the decisive high-resolution morphology needed to answer the query, even when that morphology is never mentioned in the question.
What would settle it
Run the agent on a curated set of slides where pathologists have pre-marked the exact high-resolution patches containing the diagnostic features; if the surprise field excludes more than a small fraction of those patches on average, the claimed accuracy and efficiency gains would not appear.
Figures







read the original abstract
Whole-slide image visual question answering (WSI-VQA) frames pathology as an extreme-context search problem: to answer a free-form clinical query, a system must first navigate a gigapixel slide under a strict inspection budget to locate sparse, high-resolution evidence. Existing approaches largely fall into two paradigms: i) supervised pathology multimodal large language models (MLLMs) and agents can absorb localization and reasoning into learned modules, but they often couple navigation to task-specific supervision and retraining, limiting their practicality; ii) training-free pathology agents avoid this cost by keeping core models frozen, but often follow a question-first design, constructing the initial candidate set mainly from query-conditioned relevance. This can miss decisive morphology that is not named in the question, and force heavier inference-time scaffolding. To address this challenge, we introduce PathNavigate, a training-free pathology agent built around a scan-search-readout routine. Before question matching, PathNavigate scans the current slide at low magnification with a shared online memory module over frozen pathology features, producing a slide-specific surprise field that marks an abnormal-region pool. It then applies question-conditioned PLIP relevance only within this pool to select high-magnification search targets. Finally, it extracts local high-magnification evidence and answers with a frozen perceptor-adjudicator stack, using the same online memory as slide-level context. Experiments on WSI-VQA and SlideBench-BCNB show that the proposed scan-search-readout design improves answer accuracy and yields more interpretable evidence-selection trajectories with higher efficiency.The code is available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PathNavigate, a training-free pathology agent for whole-slide image visual question answering (WSI-VQA). It proposes a scan-search-readout routine: a low-magnification scan with a shared online memory module over frozen pathology features produces a slide-specific surprise field marking an abnormal-region pool; question-conditioned PLIP relevance is then restricted to this pool to select high-magnification targets; finally, local high-magnification evidence is extracted and the query is answered by a frozen perceptor-adjudicator stack that reuses the online memory as slide-level context. Experiments on WSI-VQA and SlideBench-BCNB are stated to demonstrate improved answer accuracy, more interpretable evidence-selection trajectories, and higher efficiency. The code is released publicly.
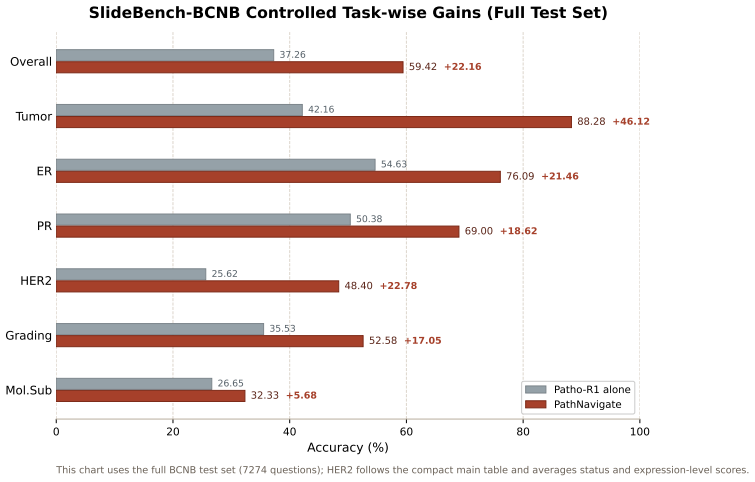
Significance. If the results hold, the work provides a practical training-free alternative to supervised multimodal LLMs for pathology VQA by addressing the limitation of question-first designs that can miss decisive morphology unnamed in the query. The surprise-guided navigation and shared memory mechanism could improve both accuracy and interpretability in gigapixel extreme-context search settings. The public code release supports reproducibility.
major comments (1)
- [Experiments] Experiments section: the central premise that the low-magnification surprise field (produced by shared online memory over frozen features) reliably contains the pool of regions holding query-decisive high-resolution morphology is not supported by any reported recall metric of ground-truth evidence patches inside the surprise pool, nor by an ablation isolating the surprise step or quantification of the surprise field (e.g., reconstruction error or density threshold). This assumption is load-bearing for the claim that restricting PLIP search to the pool improves accuracy over question-first baselines; if subtle high-res features are excluded at low mag, the pipeline cannot recover them.
minor comments (1)
- [Abstract] Abstract: asserts performance gains on WSI-VQA and SlideBench-BCNB but supplies no metrics, baselines, statistical details, or ablation results, which hinders immediate assessment of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the experimental validation of the surprise-guided mechanism. We address the concern point by point below.
read point-by-point responses
-
Referee: Experiments section: the central premise that the low-magnification surprise field (produced by shared online memory over frozen features) reliably contains the pool of regions holding query-decisive high-resolution morphology is not supported by any reported recall metric of ground-truth evidence patches inside the surprise pool, nor by an ablation isolating the surprise step or quantification of the surprise field (e.g., reconstruction error or density threshold). This assumption is load-bearing for the claim that restricting PLIP search to the pool improves accuracy over question-first baselines; if subtle high-res features are excluded at low mag, the pipeline cannot recover them.
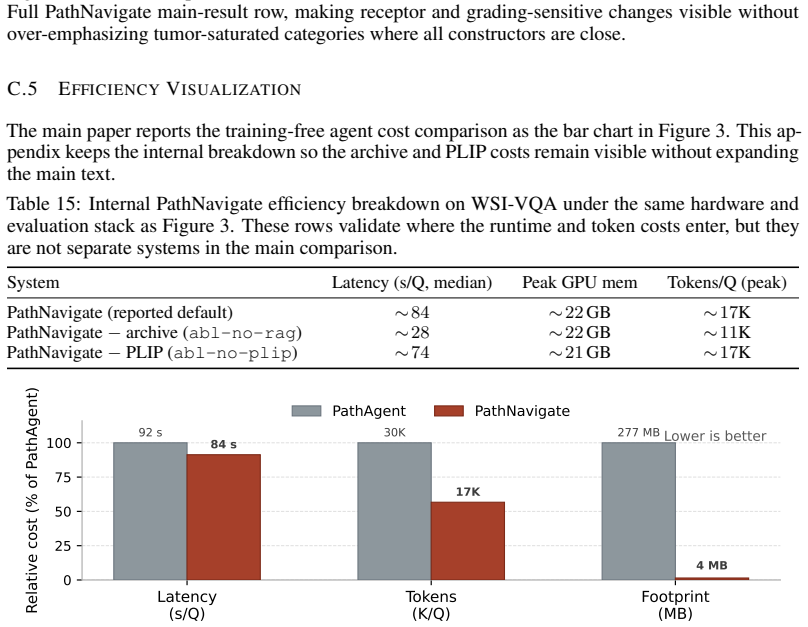
Authors: We agree that a direct recall metric on ground-truth evidence patches would provide stronger support for the assumption. However, neither WSI-VQA nor SlideBench-BCNB provides region-level annotations of ground-truth evidence patches, so such a recall cannot be computed without new labeling. The reported end-to-end accuracy gains, efficiency improvements, and qualitative trajectory analysis offer indirect support for the scan-search-readout design. We will add an ablation isolating the surprise step together with quantification of the surprise field (e.g., density thresholds) in the revision. revision: partial
- Reporting recall of ground-truth evidence patches inside the surprise pool, because the evaluation datasets lack the required region-level annotations.
Circularity Check
No significant circularity; empirical design with no derivations or fitted predictions
full rationale
The paper describes an empirical training-free agent architecture (scan with low-mag surprise field from shared online memory over frozen features, followed by question-conditioned search within that pool, then readout). No equations, parameter fits, uniqueness theorems, or self-citation chains are present in the provided text. The central premise is an engineering choice whose validity is tested via experiments on WSI-VQA and SlideBench-BCNB rather than derived from prior inputs. This matches the reader's assessment of negligible circularity burden. The design is self-contained against external benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and V ahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jingyun Chen, Linghan Cai, Zhikang Wang, Yi Huang, Songhan Jiang, Shenjin Huang, Hongpeng Wang, and Y ongbing Zhang. Pathagent: Toward interpretable analysis of whole-slide pathol- ogy images via large language model-based agentic reasoning. arXiv preprint arXiv:2511.17052, 2025a. Pingyi Chen, Honglin Li, Chenglu Zhu, Sunyi Zheng, Zhongyi Shui, and Lin Y ...
-
[3]
Gsco: Towards generalizable ai in medicine via generalist-specialist collaboration
Sunan He, Y uxiang Nie, Hongmei Wang, Shu Y ang, Yihui Wang, Zhiyuan Cai, Zhixuan Chen, Yingxue Xu, Luyang Luo, Huiling Xiang, et al. Gsco: Towards generalizable ai in medicine via generalist-specialist collaboration. arXiv preprint arXiv:2404.15127,
-
[4]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[5]
Guolin Huang, Wenting Chen, Jiaqi Y ang, Xinheng Lyu, Xiaoling Luo, Sen Y ang, Xiaohan Xing, and Linlin Shen. Survagent: Hierarchical cot-enhanced case banking and dichotomy-based multi- agent system for multimodal survival prediction. arXiv preprint arXiv:2511.16635,
-
[6]
Act like a pathologist: Tissue-aware whole slide image reasoning
Wentao Huang, Weimin Lyu, Peiliang Lou, Qingqiao Hu, Xiaoling Hu, Shahira Abousamra, Wen- chao Han, Ruifeng Guo, Jiawei Zhou, Chao Chen, et al. Act like a pathologist: Tissue-aware whole slide image reasoning. arXiv preprint arXiv:2603.00667,
-
[7]
11 Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Multimodal retrieval-augmented generation with large language models for medical vqa
AHM Karim and Ozlem Uzuner. Multimodal retrieval-augmented generation with large language models for medical vqa. arXiv preprint arXiv:2510.13856,
-
[9]
A co-evolving agentic ai system for medical imaging analysis
Songhao Li, Jonathan Xu, Tiancheng Bao, Y uxuan Liu, Y uchen Liu, Yihang Liu, Lilin Wang, Wen- hui Lei, Sheng Wang, Yinuo Xu, et al. A co-evolving agentic ai system for medical imaging analysis. arXiv preprint arXiv:2509.20279,
-
[10]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. MedGemma technical report. arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mehmet Saygin Seyfioglu, Wisdom O Ikezogwo, Fatemeh Ghezloo, Ranjay Krishna, and Linda Shapiro. Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13183–13192, 2024a. Mehmet Saygin Seyfioglu, Wisdom O Ikezo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
12 Y uxuan Sun, Yixuan Si, Chenglu Zhu, Xuan Gong, Kai Zhang, Pingyi Chen, Y e Zhang, Zhongyi Shui, Tao Lin, and Lin Y ang. Cpath-omni: A unified multimodal foundation model for patch and whole slide image analysis in computational pathology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10360–10371, 2025a. Y uxu...
-
[14]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Y u, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Chatcad: Interac- tive computer-aided diagnosis on medical image using large language models
Sheng Wang, Zihao Zhao, Xi Ouyang, Qian Wang, and Dinggang Shen. Chatcad: Interac- tive computer-aided diagnosis on medical image using large language models. arXiv preprint arXiv:2302.07257,
-
[16]
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Ypathrag: A retrieval-augmented generation framework and bench- mark for pathology
Deshui Y u, Yizhi Wang, Saihui Jin, Taojie Zhu, Fanyi Zeng, Wen Qian, Zirui Huang, Jingli Ouyang, Jiameng Li, Zhen Song, et al. Ypathrag: A retrieval-augmented generation framework and bench- mark for pathology. arXiv preprint arXiv:2510.08603,
-
[18]
join PathNavigate reproduced scan-search- readout Patho-R1-7B ( Zhang et al. , 2026b) / Qwen3.5- 4B (Y ang et al., 2025), Appendix B.1 Pretrained MLLM rows in the main tables include closed-source API endpoints and local Qwen thumbnail runs, all using the same single-thumbnail (Slide-T) visual input. The closed-source rows are identified by the exact endpo...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.