DDX-TRACE: A Benchmark for Medical Diagnostic Trajectories in VLMs
Pith reviewed 2026-05-25 04:51 UTC · model grok-4.3
The pith
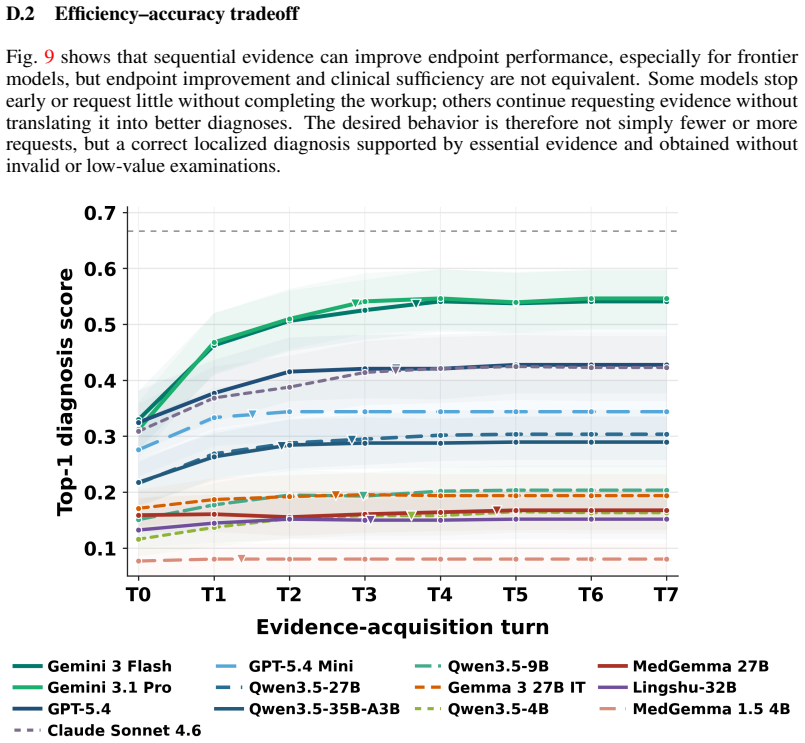
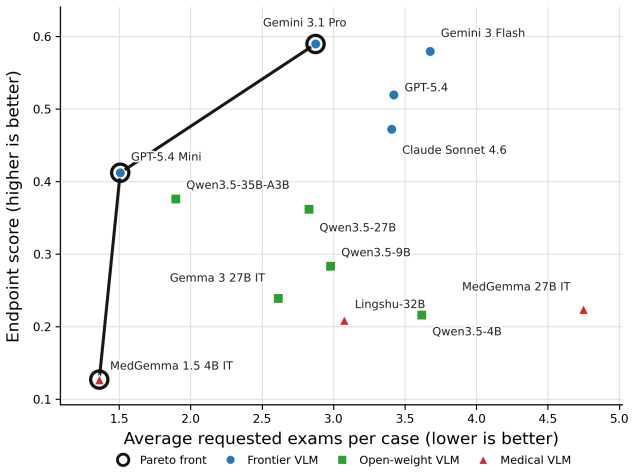
Medical AI benchmarks that score only final diagnoses can mask unsupported guesses and inefficient workups by models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
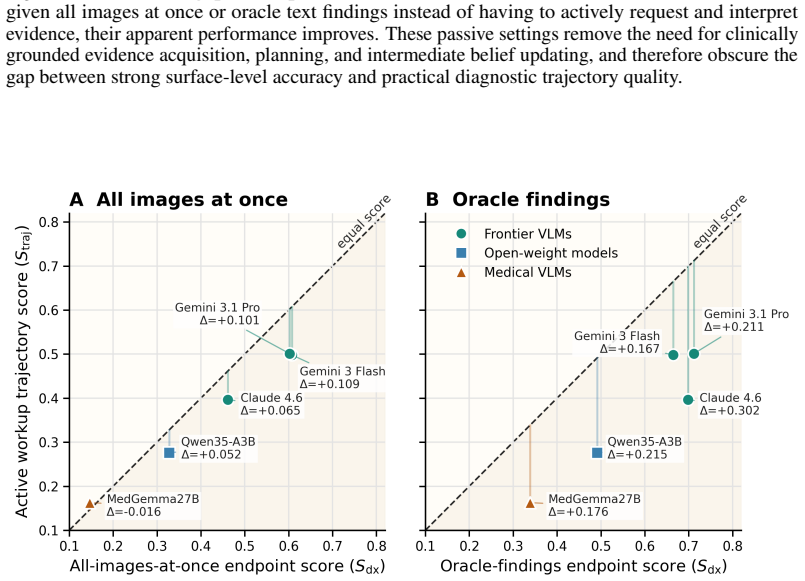
The paper claims that final diagnosis scores substantially misrepresent workup quality because models may guess plausible diagnoses without essential evidence, request useful studies but misinterpret raw images, or acquire evidence inefficiently while updating uncertainty poorly. DDX-TRACE evaluates state-of-the-art vision-language models on full diagnostic trajectories under a hidden-evidence protocol over 211 challenging cases, where each case begins with limited clinical history, models request studies freely, receive matched image bundles, update probabilistic differentials, and conclude with a localized diagnosis. Controlled evidence variants isolate bottlenecks in planning, visual证据提取,
What carries the argument
DDX-TRACE benchmark that uses a physician-adjudicated hidden-evidence protocol to evaluate sequential diagnostic trajectories instead of final answers alone.
If this is right
- High final diagnosis scores do not guarantee that models requested or used essential evidence.
- Visual interpretation of raw images can fail even when appropriate studies are requested.
- Evidence acquisition can remain inefficient while uncertainty updating stays poor.
- Controlled variants of available evidence can separate failures in planning from failures in visual extraction and differential reasoning.
Where Pith is reading between the lines
- Training methods for medical vision-language models could shift from rewarding correct endpoints to rewarding evidence-supported sequences.
- Trajectory evaluation might be required before safe clinical deployment to avoid models that reach answers through unsupported paths.
- Similar hidden-evidence benchmarks could be built for other specialties to test whether the same mismatch between final score and process quality appears.
Load-bearing premise
The 211 cases and the physician-adjudicated hidden-evidence protocol accurately capture real clinical diagnostic trajectories.
What would settle it
If models with high final diagnosis scores on DDX-TRACE consistently request the same essential studies and interpret the images in line with the physician-adjudicated evidence paths, that observation would undermine the claim that final scores substantially misrepresent workup quality.
Figures






read the original abstract
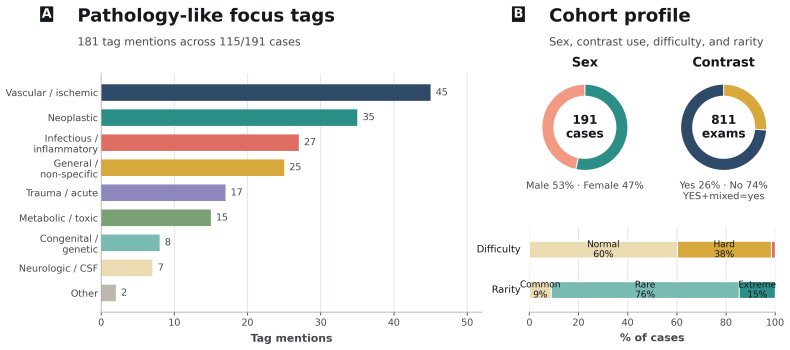
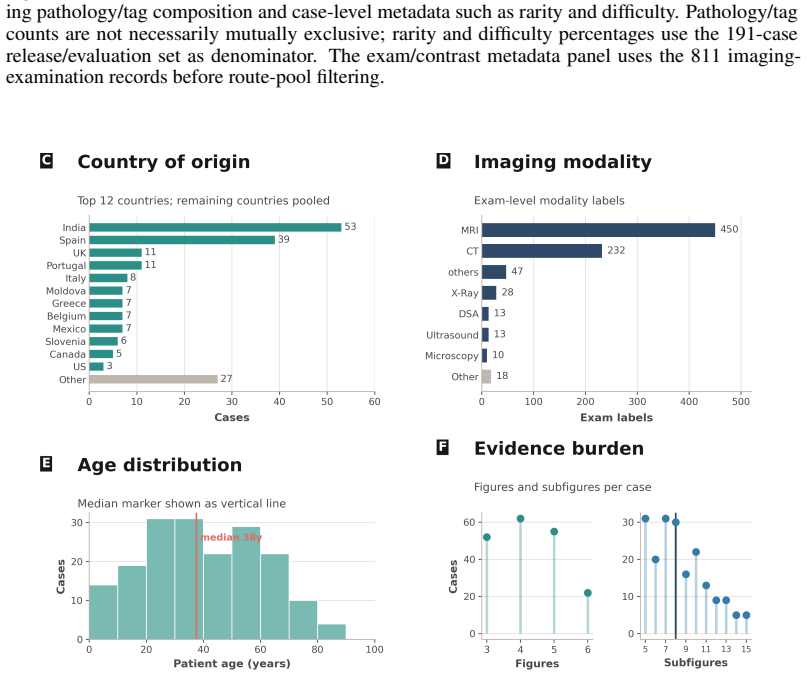
Medical diagnosis is not a single prediction from a fully specified vignette. It is a sequential workup: clinicians decide what evidence to obtain, revise a differential diagnosis, and stop when the diagnosis is sufficiently supported. Most medical AI benchmarks instead reveal the relevant context upfront and score only the final answer, making unsupported correct guesses, premature closure, inefficient workups, and poor uncertainty updating invisible. We introduce DDX-TRACE, a physician-adjudicated benchmark for multimodal neuroradiology that evaluates diagnostic trajectories under hidden evidence over 211 challenging cases. Each case begins with limited clinical history; models request imaging studies in free form, receive matched image bundles when available, update a probabilistic differential diagnosis after each turn, and stop with a localized final diagnosis. Evaluating state-of-the-art VLMs, we find that final diagnosis scores can substantially misrepresent workup quality: models may guess plausible diagnoses without essential evidence, request useful studies but misinterpret raw images, or acquire evidence inefficiently while updating uncertainty poorly. Controlled evidence variants isolate bottlenecks in planning, visual evidence extraction, and downstream differential reasoning. DDX-TRACE shifts medical AI evaluation from final answers to evidence-supported diagnostic trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DDX-TRACE, a physician-adjudicated benchmark of 211 neuroradiology cases that evaluates VLMs on sequential diagnostic trajectories under hidden evidence. Models begin with limited clinical history, issue free-form study requests, receive matched image bundles, update probabilistic differentials after each turn, and terminate with a localized final diagnosis. The central claims are that final-diagnosis scores substantially misrepresent workup quality (e.g., correct guesses without essential evidence, misinterpretation of raw images, inefficient evidence acquisition with poor uncertainty updating) and that controlled evidence variants can isolate bottlenecks in planning, visual extraction, and differential reasoning.
Significance. If the adjudication protocol and variant design are shown to be robust, the benchmark would represent a meaningful advance over static final-answer medical AI evaluations by surfacing clinically relevant failure modes that current leaderboards conceal. The shift toward trajectory-based assessment is a substantive contribution to the field.
major comments (2)
- [Abstract / Benchmark Design] Abstract and Benchmark Design section: The claim that controlled evidence variants isolate specific bottlenecks in planning, visual evidence extraction, and downstream differential reasoning rests on the hidden-evidence protocol and physician adjudication of 'essential evidence' and stopping criteria being accurate and reproducible. The manuscript provides no inter-rater agreement statistics, no sensitivity analysis on adjudication thresholds, and no explicit mapping procedure from free-form study requests to matched bundles; without these, apparent model failures in the three bottleneck categories could be artifacts of adjudication noise rather than genuine model deficiencies.
- [Evaluation and Results] Evaluation and Results section: The abstract states that 'evaluating state-of-the-art VLMs, we find that final diagnosis scores can substantially misrepresent workup quality' yet supplies no quantitative results, error analysis, or validation details (e.g., per-bottleneck performance deltas, inter-case variance, or comparison against physician trajectories). This absence directly undermines the load-bearing empirical support for the misrepresentation claim.
minor comments (1)
- [Abstract] The abstract would benefit from at least one summary statistic (e.g., aggregate accuracy gap between final diagnosis and trajectory quality) to ground the high-level findings.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review of our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / Benchmark Design] Abstract and Benchmark Design section: The claim that controlled evidence variants isolate specific bottlenecks in planning, visual evidence extraction, and downstream differential reasoning rests on the hidden-evidence protocol and physician adjudication of 'essential evidence' and stopping criteria being accurate and reproducible. The manuscript provides no inter-rater agreement statistics, no sensitivity analysis on adjudication thresholds, and no explicit mapping procedure from free-form study requests to matched bundles; without these, apparent model failures in the three bottleneck categories could be artifacts of adjudication noise rather than genuine model deficiencies.
Authors: We agree that quantitative validation of the adjudication protocol is necessary to support the bottleneck isolation claims. The manuscript describes the multi-physician adjudication process for essential evidence and stopping criteria but does not include inter-rater agreement statistics or sensitivity analyses. We will add these in the revision, including Fleiss' kappa for key decisions and a sensitivity analysis on adjudication thresholds. We will also expand the description of the mapping procedure from free-form study requests to matched image bundles. revision: yes
-
Referee: [Evaluation and Results] Evaluation and Results section: The abstract states that 'evaluating state-of-the-art VLMs, we find that final diagnosis scores can substantially misrepresent workup quality' yet supplies no quantitative results, error analysis, or validation details (e.g., per-bottleneck performance deltas, inter-case variance, or comparison against physician trajectories). This absence directly undermines the load-bearing empirical support for the misrepresentation claim.
Authors: The Evaluation and Results section presents quantitative comparisons between final diagnosis accuracy and trajectory quality metrics. We acknowledge that additional error analysis and validation details would strengthen the empirical support. We will expand the section to include per-bottleneck performance deltas, inter-case variance, and comparisons to physician trajectories on a subset of cases where feasible. revision: yes
Circularity Check
No circularity; benchmark is an independent evaluation framework
full rationale
The paper presents DDX-TRACE as a new physician-adjudicated benchmark for diagnostic trajectories, with no mathematical derivations, equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citations are invoked as load-bearing for uniqueness theorems or ansatzes. The central claims rest on empirical evaluation of existing VLMs against the benchmark rather than any self-referential reduction. The 211 cases and adjudication protocol are described as external to the models being tested, making the framework self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical diagnosis is a sequential process of evidence gathering, differential diagnosis updating, and stopping when sufficiently supported.
Reference graph
Works this paper leans on
-
[1]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Holistic evaluation of large language models for medical tasks with medhelm.Nature Medicine, pages 1–9, 2026
work page 2026
-
[3]
Crystal T Chang, Hodan Farah, Haiwen Gui, Shawheen Justin Rezaei, Charbel Bou-Khalil, Ye-Jean Park, Akshay Swaminathan, Jesutofunmi A Omiye, Akaash Kolluri, Akash Chaurasia, et al. Red teaming chatgpt in medicine to yield real-world insights on model behavior.npj Digital Medicine, 8(1):149, 2025
work page 2025
-
[4]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
work page 2024
-
[6]
Zhihong Chen, Maya Varma, Justin Xu, Magdalini Paschali, Dave Van Veen, Andrew Johnston, Alaa Youssef, Louis Blankemeier, Christian Bluethgen, Stephan Altmayer, et al. A vision- language foundation model to enhance efficiency of chest x-ray interpretation.arXiv preprint arXiv:2401.12208, 2024
-
[7]
Christopher Chiu, Silviu Pitis, and Mihaela van der Schaar. Simulating viva voce examinations to evaluate clinical reasoning in large language models.arXiv preprint arXiv:2510.10278, 2025
-
[8]
Eurorad: The radiological case database
European Society of Radiology. Eurorad: The radiological case database
-
[9]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Wang Siyuan, Zhongyu Wei, and Fei Huang. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. InProceedings of the 31st International Conference on Computational Linguistics, pages 10183–10213, 2025
work page 2025
- [10]
-
[11]
Evalu- ation and mitigation of the limitations of large language models in clinical decision-making
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, Georgios Kaissis, et al. Evalu- ation and mitigation of the limitations of large language models in clinical decision-making. Nature medicine, 30(9):2613–2622, 2024
work page 2024
-
[12]
Iryna Hartsock and Ghulam Rasool. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelligence, 7:1430984, 2024
work page 2024
-
[13]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[14]
Medagentbench: a virtual ehr environment to benchmark medical llm agents
Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. Medagentbench: a virtual ehr environment to benchmark medical llm agents. Nejm Ai, 2(9):AIdbp2500144, 2025
work page 2025
-
[15]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
work page 2021
-
[16]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019. 11
work page 2019
-
[17]
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W Safranek, Abid A Anwar, Andrew Zhang, et al. Medcalc- bench: Evaluating large language models for medical calculations.Advances in Neural Infor- mation Processing Systems, 37:84730–84745, 2024
work page 2024
-
[18]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
work page 2018
-
[19]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
work page 2023
-
[20]
Medical visual question answering: A survey.Artificial Intelligence in Medicine, 143:102611, 2023
Zhihong Lin, Donghao Zhang, Qingyi Tao, Danli Shi, Gholamreza Haffari, Qi Wu, Mingguang He, and Zongyuan Ge. Medical visual question answering: A survey.Artificial Intelligence in Medicine, 143:102611, 2023
work page 2023
-
[21]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
work page 2021
-
[22]
Sequential diagnosis with language models.arXiv preprint arXiv:2506.22405, 2025
Harsha Nori, Mayank Daswani, Christopher Kelly, Scott Lundberg, Marco Tulio Ribeiro, Marc Wilson, Xiaoxuan Liu, Viknesh Sounderajah, Jonathan Carlson, Matthew P Lungren, et al. Sequential diagnosis with language models.arXiv preprint arXiv:2506.22405, 2025
-
[23]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
work page 2022
-
[24]
Jiazhen Pan, Bailiang Jian, Paul Hager, Yundi Zhang, Che Liu, Friedrike Jungmann, Hong- wei Bran Li, Chenyu You, Junde Wu, Jiayuan Zhu, et al. Beyond benchmarks: Dynamic, automatic and systematic red-teaming agents for trustworthy medical language models.arXiv preprint arXiv:2508.00923, 2025
-
[25]
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 337–347. Springer, 2025
work page 2025
-
[26]
Towards building multilingual language model for medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards building multilingual language model for medicine. Nature Communications, 15(1):8384, 2024
work page 2024
-
[27]
Qwen Team. Qwen3.5-35B-A3B model card. Hugging Face model card, 2026. https: //huggingface.co/Qwen/Qwen3.5-35B-A3B(accessed March 2026)
work page 2026
-
[28]
Qwen Team. Qwen3.5 model collection. Hugging Face model collection, 2026. https: //huggingface.co/collections/Qwen/qwen35(accessed March 2026)
work page 2026
-
[29]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023. 12
work page 2023
-
[32]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature Medicine, pages 1–8, 2025
work page 2025
-
[33]
Ryutaro Tanno, David GT Barrett, Andrew Sellergren, Sumedh Ghaisas, Sumanth Dathathri, Abigail See, Johannes Welbl, Charles Lau, Tao Tu, Shekoofeh Azizi, et al. Collaboration between clinicians and vision–language models in radiology report generation.Nature Medicine, 31(2):599–608, 2025
work page 2025
-
[34]
Kevin Wu, Eric Wu, Rahul Thapa, Kevin Wei, Angela Zhang, Arvind Suresh, Jacqueline J Tao, Min Woo Sun, Alejandro Lozano, and James Zou. Medcasereasoning: Evaluating and learning diagnostic reasoning from clinical case reports.arXiv preprint arXiv:2505.11733, 2025
-
[35]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Medical thinking with multiple images
Zonghai Yao, Benlu Wang, Yifan Zhang, Junda Wang, Iris Xia, Zhipeng Tang, Shuo Han, Feiyun Ouyang, Zhichao Yang, Arman Cohan, and Hong Yu. Medical thinking with multiple images. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[37]
Huatuogpt, towards taming language model to be a doctor
Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Guiming Chen, Jianquan Li, Xiangbo Wu, Zhang Zhiyi, Qingying Xiao, et al. Huatuogpt, towards taming language model to be a doctor. InFindings of the association for computational linguistics: EMNLP 2023, pages 10859–10885, 2023
work page 2023
-
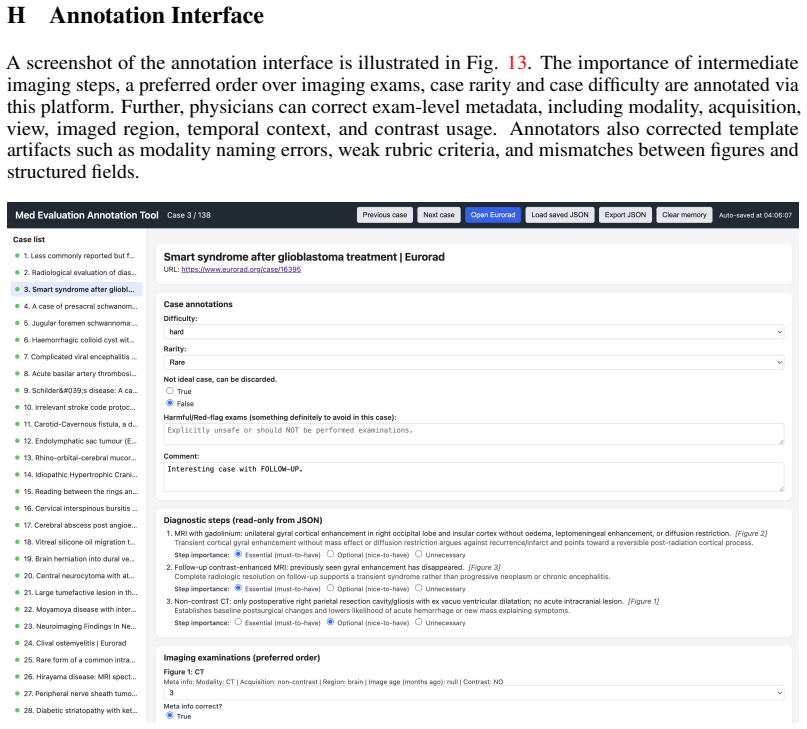
[38]
An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
Weike Zhao, Chaoyi Wu, Yanjie Fan, Pengcheng Qiu, Xiaoman Zhang, Yuze Sun, Xiao Zhou, Shuju Zhang, Yu Peng, Yanfeng Wang, et al. An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
work page 2026
-
[39]
Ask patients with patience: Enabling llms for human-centric medical dialogue with grounded reasoning
Jiayuan Zhu, Jiazhen Pan, Yuyuan Liu, Fenglin Liu, and Junde Wu. Ask patients with patience: Enabling llms for human-centric medical dialogue with grounded reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2846–2857, 2025
work page 2025
-
[40]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 13 Appendix A Pictorial Illustration of DDX-TRACE Workflow 15 B Limitations 15 C Benchmark Statistics and Data Distribution 16 D Extend...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
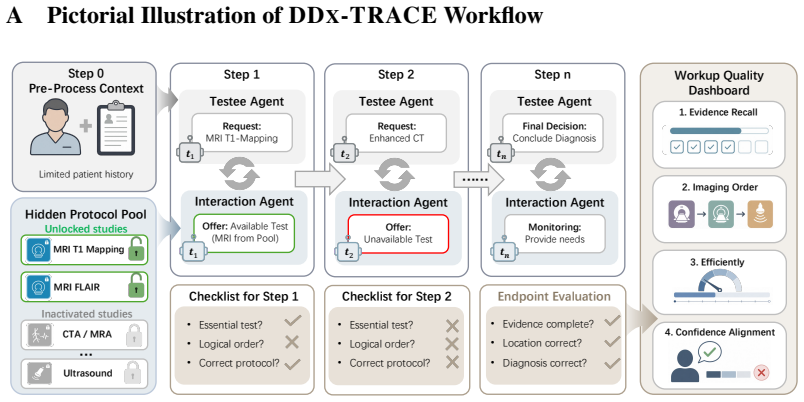
Confidence Alignment 𝒕𝒏𝒕"𝒕# 𝒕𝒏𝒕"𝒕# Hidden Protocol Pool \ MRI T1 Mapping CTA / MRA… MRIFLAIR Ultrasound Unlocked studies Inactivated studies …… Figure 4:DDX-TRACE overview.Each case begins with limited clinical history only, and the agent does not receive a list of available examinations. The agent interacts with the environment by requesting imaging exam...
-
[42]
Based on the imaging figures provided, what is the most likely diagnosis?
Candidate-model decoding settings are reported separately in Appendix J.1. For each case, the judge receives the case-specific diagnosis and localization rubrics, the model’s final output, and the set of unique diagnosis strings that appeared anywhere in the trajectory. It returns normalized endpoint scores for diagnosis and localization, together with ex...
-
[43]
Localisation -- where the abnormality is
-
[44]
Diagnosis -- the most likely diagnosis. REQUIREMENTS - Output must be a single JSON object that strictly matches the provided JSON Schema. - Provide analytic criteria for score levels "3", "2", "1", "0" in EACH of the sections (Localisation / Diagnosis). - Include a **reference_answer** for EACH section: - Localisation.reference_answer must be an object w...
-
[45]
final diagnosis quality using the provided case-specific diagnosis rubric
-
[46]
final localization quality using the provided case-specific localization rubric
-
[47]
final four-item differential-list quality using the reference differential set and the global rubric below
-
[48]
exact/acceptable/unmatched labels and 0-3 diagnosis-rubric scores for every diagnosis string in the trajectory. Global rubric for final differential-list quality (0-3): - 0: The list is mostly off-target, fails to include the final diagnosis or close equivalent, and has little overlap with the reference differential set. - 1: The list contains one or more...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.