Weierstrass Positional Encoding for Vision Transformers
Pith reviewed 2026-05-25 05:46 UTC · model grok-4.3
The pith
Weierstrass elliptic functions map 2D patch coordinates to compact four-dimensional encodings that respect image grid geometry in vision transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WePE constructs four-dimensional positional features by evaluating the Weierstrass elliptic function and its derivative on normalized two-dimensional coordinates placed in the complex plane. The resulting encodings inherit double periodicity and a lattice structure that aligns with the regular geometry of image patch grids, while the algebraic addition formula permits direct computation of relative positional information between arbitrary patch pairs.
What carries the argument
The Weierstrass elliptic function and its derivative applied to complex inputs, which generate compact four-dimensional features carrying double periodicity and the addition formula for relative encodings.
If this is right
- Plug-and-play insertion into existing vision transformers with no noticeable memory or compute overhead when using precomputed lookup tables.
- Resolution-agnostic behavior that preserves performance across different input sizes without retraining the positional component.
- Direct derivation of relative positional encodings between any patch pair via the addition formula without additional parameters.
- More faithful preservation of monotonic relationships between Euclidean spatial distances and encoded distances due to the nonlinear lattice properties.
Where Pith is reading between the lines
- The lattice-matching property could extend naturally to other regularly gridded data such as video frames or volumetric medical scans.
- The double periodicity might reduce boundary artifacts when patches wrap around image edges in certain augmentation schemes.
- Because relative positions derive algebraically, the encoding could support efficient attention masking or relative bias terms without extra storage.
Load-bearing premise
That the nonlinear geometric properties and algebraic addition formula of the Weierstrass elliptic function will produce better modeling of spatial proximity and higher task performance when inserted into standard vision transformer architectures.
What would settle it
A controlled replacement of WePE with standard sinusoidal encodings or random periodic features on the same ViT backbones that shows no performance difference or a reversal of gains on multiple image classification and detection benchmarks.
Figures









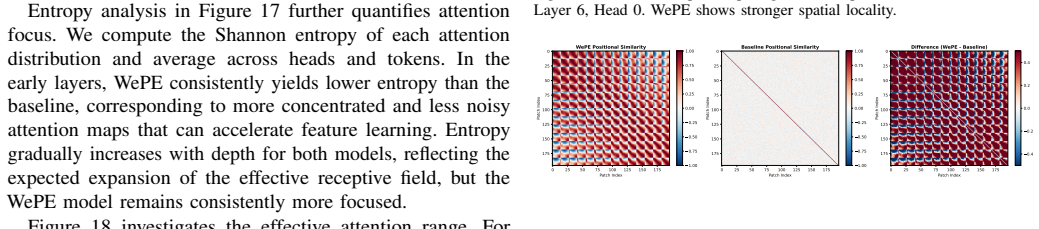





read the original abstract
Vision Transformers have achieved remarkable success in computer vision, but their common use of learnable one-dimensional positional encodings weakens the inherent two-dimensional spatial structure of images after patch flattening. Existing positional encodings often lack geometric constraints and do not preserve a monotonic relationship between Euclidean spatial distances and sequential index distances, limiting ViTs' ability to exploit spatial proximity priors. Motivated by the usefulness of periodicity in positional encoding, we propose Weierstrass elliptic Positional Encoding (WePE), a mathematically grounded method for encoding two-dimensional coordinates in the complex domain. WePE maps normalized 2D patch coordinates onto the complex plane and constructs compact four-dimensional positional features using the Weierstrass elliptic function and its derivative. The double periodicity provides a principled representation of 2D positions, and its intrinsic lattice structure naturally matches the regular geometry of image patch grids. Its nonlinear geometric properties help model spatial distance relationships more faithfully, while the algebraic addition formula enables relative positional information between arbitrary patch pairs to be derived directly from their absolute encodings. WePE is plug-and-play and resolution-agnostic, allowing seamless integration into existing ViTs. Extensive experiments show that WePE brings consistent performance gains in most settings. With precomputed lookup tables, these improvements introduce no noticeable computational or memory overhead. Additional analyses and ablation studies further validate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Weierstrass Positional Encoding (WePE) for Vision Transformers. Normalized 2D patch coordinates are mapped to the complex plane, and the Weierstrass elliptic function ℘(z) together with its derivative are used to produce compact 4D positional features. The method is claimed to exploit double periodicity and lattice structure to match image grids, model spatial distances more faithfully via nonlinear geometry, and support relative positions through the algebraic addition formula, while being plug-and-play, resolution-agnostic, and yielding consistent performance gains with no overhead via precomputed tables.
Significance. If the empirical claims hold, WePE would supply a mathematically principled 2D positional encoding grounded in elliptic-function theory, offering a structured alternative to learnable 1D encodings and potentially strengthening spatial reasoning in ViTs. The resolution independence and lack of runtime overhead are practical strengths; the novelty lies in the specific choice of the Weierstrass function and its lattice properties.
major comments (2)
- [Abstract] Abstract: the central claim that the nonlinear geometric properties and addition formula of the Weierstrass function produce more faithful distance relationships and higher task performance is unsupported by any direct metric (e.g., correlation between encoded distance and Euclidean distance) or ablation that isolates the elliptic function from a generic periodic 4D encoding.
- [Abstract] Abstract: the assertion of 'consistent performance gains in most settings' and 'no noticeable computational or memory overhead' supplies no experimental details, baselines, error bars, datasets, or ablation results, rendering the primary empirical claim impossible to evaluate.
minor comments (1)
- [Abstract] The abstract states that the addition formula 'enables relative positional information between arbitrary patch pairs to be derived directly,' yet standard ViT architectures add absolute encodings; the manuscript should clarify whether and how the addition formula is actually invoked during training or inference.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our abstract. We address the two major comments point by point below and will make corresponding revisions to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the nonlinear geometric properties and addition formula of the Weierstrass function produce more faithful distance relationships and higher task performance is unsupported by any direct metric (e.g., correlation between encoded distance and Euclidean distance) or ablation that isolates the elliptic function from a generic periodic 4D encoding.
Authors: We agree that the abstract would be strengthened by explicit reference to supporting quantitative evidence. The manuscript provides theoretical motivation via the elliptic function properties and reports downstream task improvements, but does not include a direct correlation metric between encoded and Euclidean distances nor an ablation against a generic periodic 4D baseline. We will add both: a distance-correlation analysis and a targeted ablation study in the revised version, and will update the abstract to cite these results. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'consistent performance gains in most settings' and 'no noticeable computational or memory overhead' supplies no experimental details, baselines, error bars, datasets, or ablation results, rendering the primary empirical claim impossible to evaluate.
Authors: The full manuscript contains the requested experimental details (datasets, baselines, multiple runs with error bars, and overhead measurements via precomputed tables) in the Experiments and Ablation sections. The abstract is intentionally concise and therefore omits these specifics. We will revise the abstract to include brief but concrete references to the experimental protocol, key datasets, and overhead results while preserving length constraints. revision: yes
Circularity Check
WePE construction draws from external elliptic function properties with no self-referential or fitted reductions.
full rationale
The paper defines WePE by mapping normalized 2D patch coordinates to the complex plane and applying the Weierstrass elliptic function ℘(z) together with its derivative to produce 4D features. These steps invoke standard, externally established mathematical properties (double periodicity, lattice structure, addition formula) that pre-exist the paper and are not defined in terms of the encoding's own outputs or ViT performance. No equations or claims reduce a prediction to a fitted input by construction, and no load-bearing self-citations or uniqueness theorems are invoked. Experimental results are presented as separate empirical validation rather than logical entailments of the inputs, leaving the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The Weierstrass elliptic function possesses double periodicity and an algebraic addition formula.
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words,”arXiv preprint arXiv:2010.11929, vol. 7, p. 5, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Gradient- based learning applied to document recognition,
Y . LeCun, L. B´eon, Y . Bengio, and P. Haffner, “Gradient- based learning applied to document recognition,”Pro- ceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 2002
work page 2002
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[4]
Visualizing and under- standing convolutional networks,
M. D. Zeiler and R. Fergus, “Visualizing and under- standing convolutional networks,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2014, pp. 818–833
work page 2014
-
[5]
Self-attention with relative position representations,
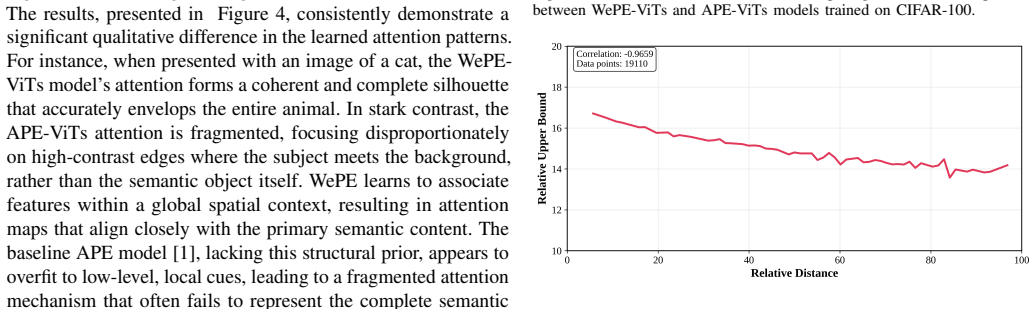
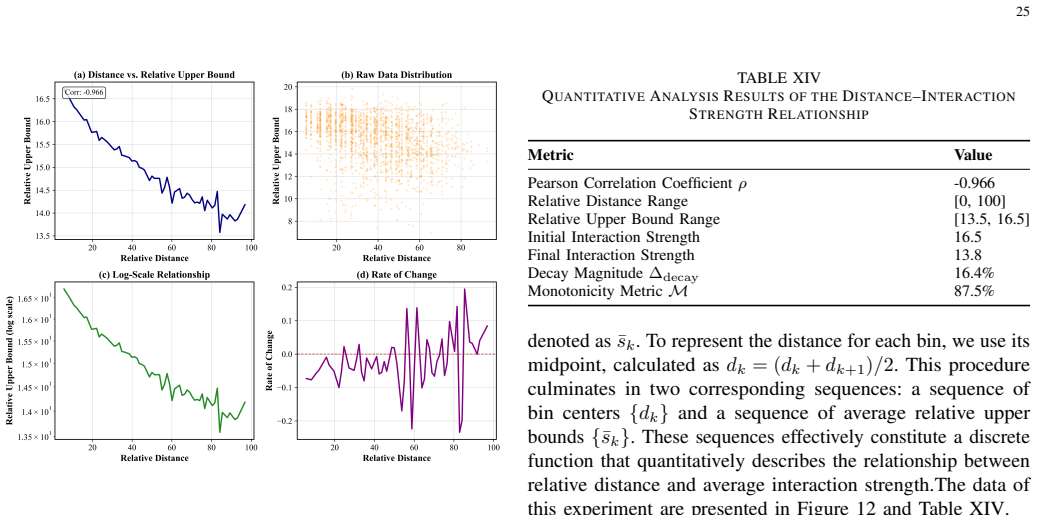
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human TABLE IX SENSITIVITY TO THE LATTICE SCALING FACTORSα u =α v. αu =α v ρProxy loss Mean|f| 0.20 0.613 4.464 0.323 0.40 0.625 4.488 0.106 0.6...
work page 2018
-
[6]
N. Parmar, A. Vaswani, J. Uszkoreit, L. Kaiser, N. Shazeer, A. Ku, and D. Tran, “Image transformer,” inProceedings of the 35th International Conference on Machine Learning (ICML 2018). PMLR, 2018, pp. 4055–4064
work page 2018
-
[7]
Fourier position embedding: Enhancing attention’s periodic extension for length generalization,
E. Hua, C. Jiang, X. Lv, K. Zhang, Y . Sun, Y . Fan, X. Zhu, B. Qi, N. Ding, and B. Zhou, “Fourier position embedding: Enhancing attention’s periodic extension for length generalization,”arXiv preprint arXiv:2412.17739, 2024
-
[8]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
work page 2024
-
[9]
Liere: Lie rotational posi- tional encodings,
S. Ostmeier, B. Axelrod, M. Varma, M. Moseley, A. S. Chaudhari, and C. Langlotz, “Liere: Lie rotational posi- tional encodings,” inProceedings of the 42nd Interna- tional Conference on Machine Learning (ICML 2025), 2025
work page 2025
-
[10]
Rotary position em- bedding for vision transformer,
B. Heo, S. Park, D. Han, and S. Yun, “Rotary position em- bedding for vision transformer,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 289–305
work page 2024
-
[11]
Rethinking and improving relative position encoding for vision transformer,
K. Wu, H. P. amenities, M. Chen, J. Fu, and H. Chao, “Rethinking and improving relative position encoding for vision transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 12 TABLE XI COEFFICIENT OF VARIATION(CV =STD/MEAN)OF KEY METRICS ACROSS EACH HYPERPARAMETER SWEEP. CV<0.01INDICATES NEGLIGIBLE SENSITIVITY. S...
work page 2021
-
[12]
On the relationship between self-attention and convolutional layers,
J. B. Cordonnier, A. Loukas, and M. Jaggi, “On the relationship between self-attention and convolutional layers,”arXiv preprint arXiv:1911.03584, 2019
-
[13]
Theorie der abel’schen functionen,
K. Weierstraß, “Theorie der abel’schen functionen,”Jour- nal f ¨ur die reine und angewandte Mathematik (Crelle’s Journal), vol. 47, pp. 289–306, 1854
-
[14]
Nist digital library of mathematical func- tions,
D. W. Lozier, “Nist digital library of mathematical func- tions,”Annals of Mathematics and Artificial Intelligence, vol. 38, no. 1, pp. 105–119, 2003
work page 2003
-
[15]
N. J. Higham,Accuracy and Stability of Numerical Algorithms. SIAM, 2002
work page 2002
-
[16]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normal- ization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Learning representations by back-propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” Nature, vol. 323, no. 6088, pp. 533–536, 1986
work page 1986
-
[18]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 4171–4186
work page 2019
-
[19]
How to train your vit? data, augmentation, and regularization in vision transformers,
A. Steiner, A. Kolesnikov, X. Zhai, R. Wightman, J. Uszkoreit, and L. Beyer, “How to train your vit? data, augmentation, and regularization in vision transformers,” arXiv preprint arXiv:2106.10270, 2021
-
[20]
Cubic convolution interpolation for digital image processing,
R. Keys, “Cubic convolution interpolation for digital image processing,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 29, no. 6, pp. 1153– 1160, 2003
work page 2003
-
[21]
Training data-efficient image trans- formers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablay- rolles, and H. J ´egou, “Training data-efficient image trans- formers & distillation through attention,” inProceedings of the 38th International Conference on Machine Learning (ICML 2021). PMLR, 2021, pp. 10 347–10 357
work page 2021
-
[22]
H. Jiawei and M. Kamber,Data Mining: Concepts and Techniques. Morgan Kaufmann, 2006
work page 2006
-
[23]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[24]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L. J. Li, K. Li, and L. Fei- Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 248–255
work page 2009
-
[25]
Visionllama: A unified llama backbone for vision tasks,
X. Chu, J. Su, B. Zhang, and C. Shen, “Visionllama: A unified llama backbone for vision tasks,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–18
work page 2024
-
[26]
Bridging the gap between vision transformers and convolutional neural net- works on small datasets,
Z. Lu, H. Xie, C. Liu, and Y . Zhang, “Bridging the gap between vision transformers and convolutional neural net- works on small datasets,”Advances in Neural Information Processing Systems, vol. 35, pp. 14 663–14 677, 2022
work page 2022
-
[27]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
X. Zhai, J. Puigcerver, A. Kolesnikov, P. Ruyssen, C. Riquelme, M. Lucic, J. Djolonga, A. S. Pinto, M. Neu- mann, A. Dosovitskiyet al., “A large-scale study of representation learning with the visual task adaptation benchmark,”arXiv preprint arXiv:1910.04867, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[28]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Geometric transformer with interatomic positional encoding,
Y . Wang, S. Li, T. Wang, B. Shao, N. Zheng, and T. Liu, “Geometric transformer with interatomic positional encoding,”Advances in Neural Information Processing Systems, vol. 36, pp. 55 981–55 994, 2023
work page 2023
-
[30]
Toeplitz and circulant matrices: A review,
R. M. Gray, “Toeplitz and circulant matrices: A review,” 2006
work page 2006
-
[31]
E. E. Catmull,A Subdivision Algorithm for Computer Display of Curved Surfaces. The University of Utah, 1974
work page 1974
-
[32]
Imagenet-21k pretraining for the masses,
T. Ridnik, E. Ben-Baruch, A. Noy, and L. Zelnik-Manor, “Imagenet-21k pretraining for the masses,”arXiv preprint arXiv:2104.10972, 2021
-
[33]
Deep residual learn- ing for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learn- ing for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
work page 2016
-
[34]
C. M. Bishop and N. M. Nasrabadi,Pattern Recognition and Machine Learning. Springer, 2006, vol. 4
work page 2006
-
[35]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022
work page 2021
-
[36]
Rethinking spatial dimensions of vision transformers,
B. Heo, S. Yun, D. Han, S. Chun, J. Choe, and S. J. Oh, “Rethinking spatial dimensions of vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 11 936–11 945
work page 2021
-
[37]
Exploring plain vision transformer backbones for object detection,
Y . Li, H. Mao, R. Girshick, and K. He, “Exploring plain vision transformer backbones for object detection,” in European Conference on Computer Vision. Springer, 2022, pp. 280–296
work page 2022
-
[38]
Masked autoencoders are scalable vision learners,
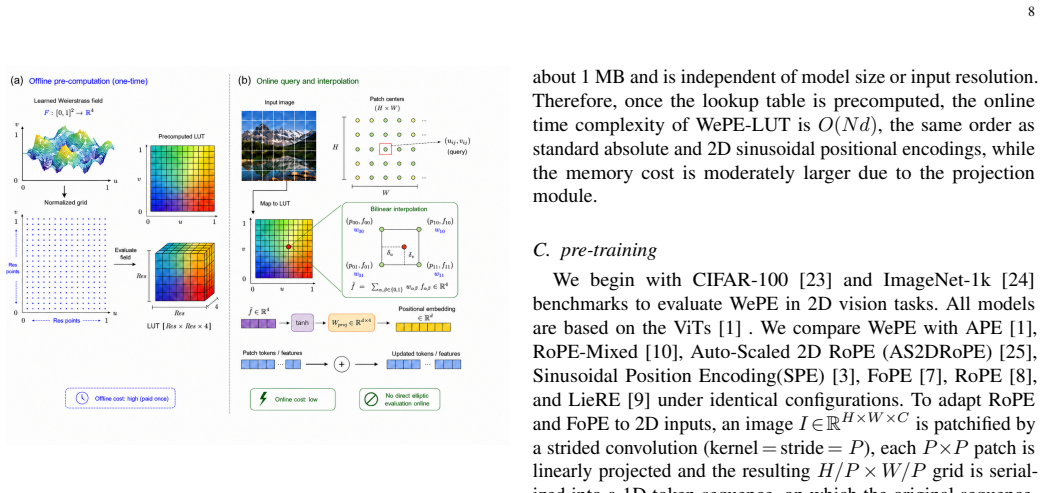
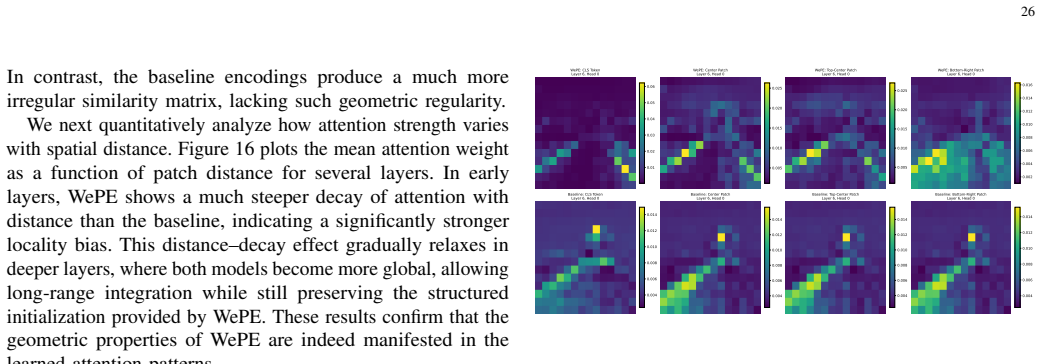
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009. 13 APPENDIXA SUPPLEMENTARYBACKGROUNDKNOWLEDGE Mainstream explicit function-based positional encodings for Vision Transformers [1] th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.