Direct Dynamic Retargeting for Humanoid Imitation Learning from Videos
Pith reviewed 2026-05-25 03:56 UTC · model grok-4.3
The pith
Direct Dynamic Retargeting generates dynamically feasible humanoid trajectories straight from video by skipping intermediate kinematic projections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Direct Dynamic Retargeting (DDR) formulates the retargeting problem in task space and solves it with a sampling-based Model Predictive Control solver inside a physics simulator, producing high-fidelity, dynamically feasible trajectories directly from expert videos without any intermediate kinematic projection step.
What carries the argument
Direct Dynamic Retargeting (DDR) as a single-stage task-space optimization using sampling-based MPC inside a physics simulator
If this is right
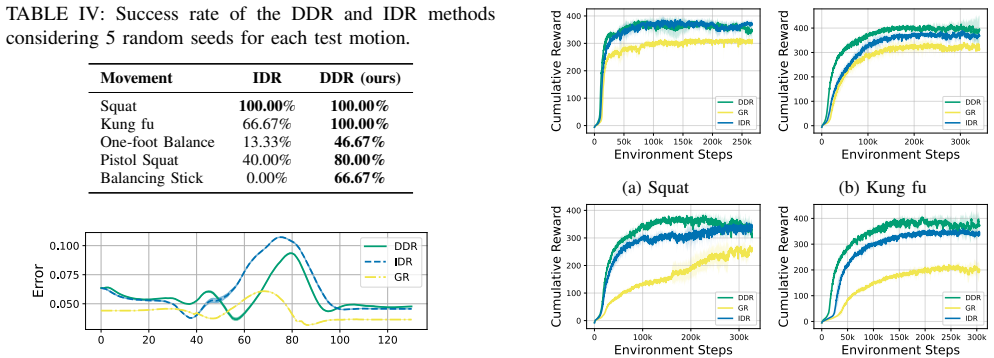
- DDR achieves higher demonstration tracking accuracy than geometric or indirect dynamic retargeting baselines.
- Physically viable references from DDR accelerate convergence when used to train reinforcement learning policies.
- RL agents trained with DDR references execute agile and balancing behaviors more successfully than those trained with biased references.
Where Pith is reading between the lines
- The same direct task-space formulation could be applied to retargeting between other robot morphologies that differ in mass distribution.
- Removing the kinematic stage may reduce the number of hyperparameters that must be tuned when adapting new video datasets.
- The approach could be tested on contact-rich motions such as climbing or manipulation where intermediate projections are especially restrictive.
Load-bearing premise
The geometric bias created by intermediate kinematic projections is the main reason standard retargeting pipelines produce suboptimal dynamic behavior.
What would settle it
A controlled experiment that applies the same sampling-based MPC solver and simulator to both a DDR pipeline and a two-stage geometric-plus-dynamic pipeline and finds no accuracy difference in demonstration tracking.
Figures






read the original abstract
Imitation Learning from monocular video demonstrations provides a scalable approach for teaching complex skills to humanoid robots. However, translating human motion to humanoids requires overcoming significant morphological mismatches. Standard approaches rely on Geometric Retargeting or Indirect Dynamic Retargeting pipelines. We identify that these intermediate kinematic projections introduce a geometric bias, restricting the search space and yielding suboptimal dynamic behaviors. In this paper, we propose Direct Dynamic Retargeting (DDR), a novel single-stage framework that generates high-fidelity, dynamically feasible trajectories directly from expert videos. By formulating the problem in the task space and leveraging a sampling-based Model Predictive Control solver within a physics simulator, DDR natively optimizes over complex contact sequences while mitigating input drift. Our experiments demonstrate that bypassing the geometric bias allows DDR to outperform state-of-the-art baselines in demonstration tracking accuracy. Furthermore, we establish that providing such physically viable references to RL agents accelerates training convergence and enhances the final execution of agile and balancing behaviors. Source code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that geometric and indirect dynamic retargeting from monocular videos introduce geometric bias via intermediate kinematic projections, yielding suboptimal dynamic behaviors for humanoid robots. It proposes Direct Dynamic Retargeting (DDR), a single-stage task-space framework that uses a sampling-based MPC solver inside a physics simulator to directly optimize dynamically feasible trajectories and complex contact sequences from expert videos. Experiments are said to show that DDR outperforms state-of-the-art baselines in demonstration tracking accuracy and that the resulting references accelerate RL convergence while improving execution of agile and balancing behaviors.
Significance. If the central claims hold after proper controls, the approach could improve the quality of video-based imitation references for humanoids, reducing reliance on biased kinematic intermediates and thereby accelerating RL for dynamic skills. The stated plan to release source code supports reproducibility.
major comments (2)
- [Abstract] The abstract states that DDR 'outperform[s] state-of-the-art baselines in demonstration tracking accuracy' by 'bypassing the geometric bias.' No information is given on whether the baselines were run with the identical sampling-based MPC solver, contact model, simulator fidelity, or solver budget. Without this control, performance deltas cannot be attributed to the absence of intermediate kinematic projections rather than solver or implementation differences.
- [Abstract] The claim that 'providing such physically viable references to RL agents accelerates training convergence' is load-bearing for the second contribution. The abstract provides no description of an ablation that applies the same MPC solver to geometrically retargeted references, leaving the geometric-bias explanation unisolated from other factors such as simulator or MPC differences.
minor comments (1)
- The abstract notes that source code will be made publicly available; confirming this in the camera-ready version would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns about isolating the effect of geometric bias from solver differences are valid, and we will strengthen the manuscript by adding the suggested controls and ablations.
read point-by-point responses
-
Referee: [Abstract] The abstract states that DDR 'outperform[s] state-of-the-art baselines in demonstration tracking accuracy' by 'bypassing the geometric bias.' No information is given on whether the baselines were run with the identical sampling-based MPC solver, contact model, simulator fidelity, or solver budget. Without this control, performance deltas cannot be attributed to the absence of intermediate kinematic projections rather than solver or implementation differences.
Authors: The baselines follow the standard geometric and indirect dynamic retargeting pipelines from prior literature, which are purely kinematic and do not employ sampling-based MPC. DDR's formulation directly optimizes task-space trajectories inside the simulator. To isolate the contribution of bypassing kinematic projections, we will add an ablation that applies the identical MPC solver, contact model, and solver budget to the geometrically retargeted references and report the resulting tracking accuracy. This will appear in the revised experiments section. revision: yes
-
Referee: [Abstract] The claim that 'providing such physically viable references to RL agents accelerates training convergence' is load-bearing for the second contribution. The abstract provides no description of an ablation that applies the same MPC solver to geometrically retargeted references, leaving the geometric-bias explanation unisolated from other factors such as simulator or MPC differences.
Authors: We agree that the current experiments do not fully isolate whether the RL acceleration arises from dynamic feasibility versus other implementation differences. We will add an ablation that feeds the same MPC solver the outputs of the geometric retargeting baselines and compare the resulting RL training curves and final policy performance. These results will be incorporated into the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces Direct Dynamic Retargeting as a single-stage optimization framework that directly solves a task-space MPC problem inside a physics simulator. No equations, fitted parameters, or self-citations appear in the abstract or described method that reduce any claimed prediction or result to the inputs by construction. The central premise (that bypassing intermediate kinematic projections removes geometric bias) is presented as an empirical hypothesis tested against baselines rather than a self-definitional or self-citation-dependent derivation. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual imitation enables contextual humanoid control,
A. Allshire, H. Choi, J. Zhang, D. McAllister, A. Zhang, C. M. Kim, T. Darrell, P. Abbeel, J. Malik, and A. Kanazawa, “Visual imitation enables contextual humanoid control,” inProceedings of the Conf. on Robot Learning, 2025. TABLE VII: Reference tracking metrics of imitation policies: Root Mean Square Error (RMSE) on the joint configurations, mean cartes...
work page 2025
-
[2]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi, “Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction,” 2025
work page 2025
-
[3]
Learning to walk via deep reinforcement learning,
T. Haarnoja, S. Ha,et al., “Learning to walk via deep reinforcement learning,” inRobotics: Science and Systems XV, 2019
work page 2019
-
[4]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,
X. B. Penget al., “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,”ACM Trans. Graph., 2018
work page 2018
-
[5]
Latent conditioned loco-manipulation using motion priors,
M. St˛ epie´n, R. Kourdis, C. Roux, and O. Stasse, “Latent conditioned loco-manipulation using motion priors,” inIEEE-RAS 24th Int. Conf. on Humanoid Robots, 2025
work page 2025
-
[6]
Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu, “Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,” 2025
work page 2025
-
[7]
X.-S. Lei, J. Pan, and J.-B. Su, “Humanoid robot locomotion,” inInt. Conf. on Machine Learning and Cybernetics, 2005
work page 2005
-
[8]
Hub: Learning extreme humanoid balance,
T. Zhang, B. Zheng, R. Nai, Y . Hu, Y .-J. Wang, G. Chen, F. Lin, J. Li, C. Hong, K. Sreenath, and Y . Gao, “Hub: Learning extreme humanoid balance,”arXiv preprint arXiv:.07294, 2025
work page 2025
-
[9]
Learning agile robotic locomotion skills by imitating animals,
X. Bin Penget al., “Learning agile robotic locomotion skills by imitating animals,” inRobotics: Science and Systems XVI, 2020
work page 2020
-
[10]
Ppr: Physically plausible reconstruction from monocular videos,
G. Yang, S. Yang, J. Z. Zhang, Z. Manchester, and D. Ramanan, “Ppr: Physically plausible reconstruction from monocular videos,” in IEEE/CVF Int. Conf. on Computer Vision, 2023
work page 2023
-
[11]
DynaRetarget: Dynamically-Feasible retargeting using Sampling- Based trajectory optimization,
V . Dhedin, I. Taouil, S. Omar, D. Yu, K. Tao, A. Dai, and M. Khadiv, “DynaRetarget: Dynamically-Feasible retargeting using Sampling- Based trajectory optimization,” 2026
work page 2026
-
[12]
Spatio-temporal motion retargeting for quadruped robots,
T. Yoon, D. Kang, S. Kim, J. Cheng, M. S. Ahn, S. Coros, and S. Choi, “Spatio-temporal motion retargeting for quadruped robots,” IEEE Trans. on Robotics, 2025
work page 2025
-
[13]
Spider: Scalable physics-informed dexterous retargeting,
C. Pan, C. Wang, H. Qi, Z. Liu, H. Bharadhwaj, A. Sharma, T. Wu, G. Shi, J. Malik, and F. Hogan, “Spider: Scalable physics-informed dexterous retargeting,” 2025
work page 2025
-
[14]
A tutorial on the cross-entropy method,
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein, “A tutorial on the cross-entropy method,”Annals of operations research, 2005
work page 2005
-
[15]
Crocoddyl: An Efficient and Versatile Framework for Multi-Contact Optimal Control,
C. Mastalli, R. Budhiraja, W. Merkt, G. Saurel, B. Hammoud, M. Naveau, J. Carpentier, L. Righetti, S. Vijayakumar, and N. Mansard, “Crocoddyl: An Efficient and Versatile Framework for Multi-Contact Optimal Control,” inIEEE Int. Conf. on Robotics and Automation, 2020
work page 2020
-
[16]
K. Ayusawa and E. Yoshida, “Motion retargeting for humanoid robots based on simultaneous morphing parameter identification and motion optimization,”IEEE Trans. on Robotics, 2017
work page 2017
-
[17]
Pink: Python inverse kinematics based on Pinocchio,
S. Caronet al., “Pink: Python inverse kinematics based on Pinocchio,”
-
[18]
Available: https://github.com/stephane-caron/pink
[Online]. Available: https://github.com/stephane-caron/pink
-
[19]
Pyroki: A modular toolkit for robot kinematic optimization,
C. M. Kim*, B. Yi*, H. Choi, Y . Ma, K. Goldberg, and A. Kanazawa, “Pyroki: A modular toolkit for robot kinematic optimization,” in IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2025
work page 2025
-
[20]
Optimization-based motion retargeting integrating spatial and dynamic constraints for humanoid,
T. Moulard, E. Yoshida, and S. Nakaoka, “Optimization-based motion retargeting integrating spatial and dynamic constraints for humanoid,” inIEEE ISR, 2013
work page 2013
-
[21]
X. Zhanget al., “Kinodynamic motion retargeting for humanoid locomotion via multi-contact whole-body trajectory optimization,” 2026
work page 2026
-
[22]
Agility meets stability: Versatile humanoid control with heterogeneous data,
Y . Pan, R. Qiao, L. Chen, K. Chitta, L. Pan, H. Mai, Q. Bu, C. Zheng, H. Zhao, P. Luo, and H. Li, “Agility meets stability: Versatile humanoid control with heterogeneous data,”arXiv preprint arXiv:.17373, 2025
work page 2025
-
[23]
Amp: Adversarial motion priors for stylized physics-based character control,
X. B. Penget al., “Amp: Adversarial motion priors for stylized physics-based character control,”ACM Trans. on Graphics, 2021
work page 2021
-
[24]
Smpl: A skinned multi-person linear model,
M. Loperet al., “Smpl: A skinned multi-person linear model,” in Seminal Graphics Papers: Pushing the Boundaries, V olume 2, 2023
work page 2023
-
[25]
Hydrax: Sampling-based model predictive control on gpu with jax and mujoco mjx,
V . Kurtz, “Hydrax: Sampling-based model predictive control on gpu with jax and mujoco mjx,” 2024, https://github.com/vincekurtz/hydrax
work page 2024
-
[26]
Cat: Constraints as terminations for legged locomotion reinforcement learning,
E. Chane-Sane, P.-A. Leziart,et al., “Cat: Constraints as terminations for legged locomotion reinforcement learning,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2024
work page 2024
-
[27]
C. Roux, E. Chane-Sane, L. de Matteïs, T. Flayols, J. Manhes, O. Stasse, P. Souères, and N. Mansard, “Constrained reinforcement learning for unstable point-feet bipedal locomotion applied to the bolt robot,” inIEEE-RAS 24rd Int. Conf. on Humanoid Robots, 2025
work page 2025
-
[28]
Proximal Policy Optimization Algorithms
J. Schulmanet al., “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
skrl: Modular and flexible library for reinforcement learning,
A. Serrano-Muñozet al., “skrl: Modular and flexible library for reinforcement learning,”Journal of Machine Learning Research, 2023
work page 2023
-
[30]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittalet al., “Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
J. Carpentier, G. Saurel, G. Buondonno, J. Mirabel, F. Lamiraux, O. Stasse, and N. Mansard, “The pinocchio c++ library – a fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives,” inIEEE Int. Symposium on System Integrations, 2019
work page 2019
-
[32]
A. Bambadeet al., “Proxqp: an efficient and versatile quadratic programming solver for real-time robotics applications and beyond,” IEEE Transactions on Robotics, 2025
work page 2025
-
[33]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” inIEEE/RSJ int. conf. on intelligent robots and systems, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.