Not Too Generative, Not Too Discriminative: The Human Alignment Sweet Spot
Pith reviewed 2026-05-25 04:19 UTC · model grok-4.3
The pith
Human visual alignment peaks at intermediate mixtures of generative and discriminative learning rather than at either extreme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
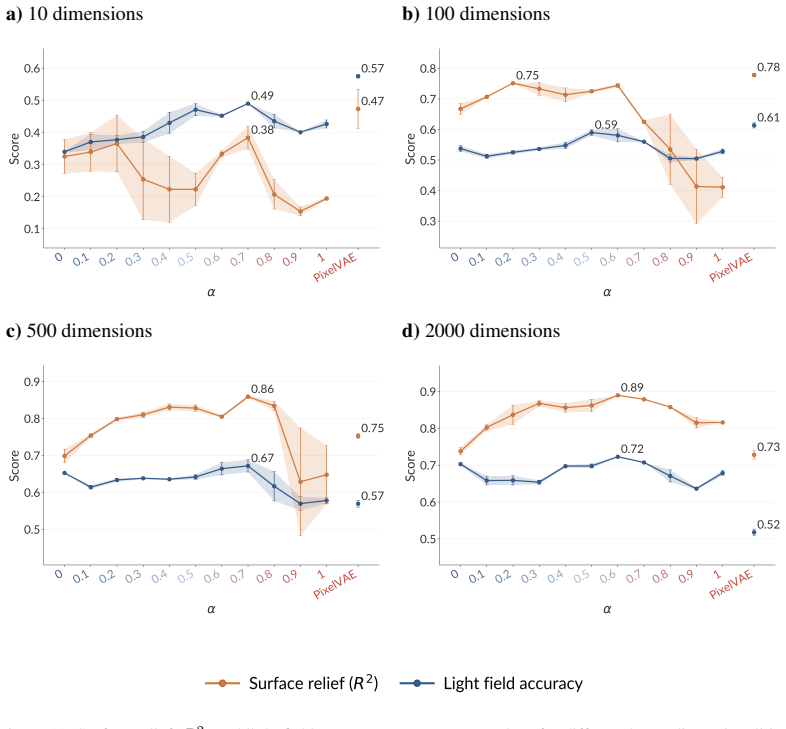
By varying the mixing coefficient in JEMs, the study shows that human alignment across the six benchmarks reaches its maximum at intermediate points on the generative-discriminative continuum. These hybrid models combine the categorical distinctions induced by discriminative learning with the structural sensitivity induced by generative learning, producing responses that better match human judgments at multiple levels of vision.
What carries the argument
Joint Energy-Based Models (JEMs) that use a single mixing coefficient to interpolate between discriminative and generative objectives inside one fixed architecture.
If this is right
- Intermediate hybrid models outperform both pure generative and pure discriminative models on the tested human-alignment metrics.
- The categorical structure from discriminative training and the input sensitivity from generative training are both required for the observed gains.
- The generative-discriminative dichotomy is not the right framing for achieving human-aligned visual representations.
- Balancing the two objectives inside a single model yields more human-like behavior than selecting one objective alone.
Where Pith is reading between the lines
- Training procedures in other domains might also benefit from explicit interpolation toward intermediate regimes rather than endpoint selection.
- The optimal mixing point could shift with changes in model scale or data distribution, offering a testable prediction for follow-up work.
- New benchmarks that separately measure category structure and input sensitivity could help locate the balance point more precisely.
Load-bearing premise
That varying only the mixing coefficient fully isolates the learning objective from all other differences in capacity, optimization, or regularization that normally separate generative and discriminative regimes.
What would settle it
A follow-up experiment that adds new human-judgment tasks and finds that intermediate mixing coefficients no longer outperform the pure generative and pure discriminative endpoints after matching for model size and training compute.
Figures


















read the original abstract
A central question in computational vision is whether human-like visual representations are better explained by discriminative or generative learning. Existing comparisons, however, often confound the learning objective with architecture, scale, and training data, leaving open whether the objective itself drives alignment. We address this confound using Joint Energy-Based Models (JEMs), which interpolate continuously between discriminative and generative training within a fixed architecture. By varying a single mixing coefficient, we isolate the effect of the learning objective and evaluate the resulting models across six human-alignment benchmarks spanning perceptual similarity, gloss perception, human response uncertainty, robustness, shape-texture cue conflict, and diagnostic feature attribution. Across this diverse suite, human alignment is consistently maximized at intermediate points of the generative-discriminative continuum, rather than at either endpoint. Hybrid JEMs combine the categorical structure induced by discriminative learning with the sensitivity to input structure induced by generative learning, yielding more human-like behavior across multiple levels of vision. These results suggest that the generative-discriminative dichotomy is the wrong axis for understanding human-aligned vision: alignment emerges not from choosing one objective over the other, but from balancing both.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human alignment with visual representations is maximized at intermediate points along the generative-discriminative continuum rather than at either extreme. It uses Joint Energy-Based Models (JEMs) with a single mixing coefficient λ to interpolate objectives while holding architecture fixed, then evaluates the resulting models on six human-alignment benchmarks (perceptual similarity, gloss perception, response uncertainty, robustness, shape-texture conflict, and feature attribution). The central result is that hybrid JEMs outperform pure generative or discriminative endpoints across this suite.
Significance. If the isolation of the objective holds, the result would be significant for computational vision: it supplies evidence that human-like behavior emerges from balancing rather than choosing between the two objectives, and it supplies a concrete method (fixed-architecture interpolation) for testing such claims. The use of a continuous mixing parameter within one model family is a methodological strength that directly targets the usual confounds of architecture and data.
major comments (2)
- [§3] §3 (JEM training and mixing coefficient): the central claim requires that alignment differences arise solely from the generative-discriminative balance. No loss-curve statistics, gradient-norm diagnostics, or effective-capacity measures are reported across λ values, leaving open the possibility that changes in optimization dynamics or implicit regularization (rather than the intended objective shift) produce the observed intermediate peak. This is load-bearing for the causal interpretation.
- [§4] §4 (benchmark results): the paper reports consistent maximization at intermediate λ but does not provide per-benchmark statistical tests, error bars, or controls for multiple comparisons that would establish the peak is reliably above the endpoints rather than within noise. Without these, the cross-benchmark claim rests on visual inspection alone.
minor comments (2)
- [§3] Notation for the mixing coefficient λ is introduced without an explicit equation relating it to the joint loss; adding the precise interpolation formula would improve reproducibility.
- [§4] Figure captions for the alignment plots do not state the number of random seeds or the exact human-subject sample sizes underlying each benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence that alignment differences stem from the objective balance rather than optimization artifacts, and for emphasizing the importance of statistical rigor. We agree these points are central to the causal interpretation and will revise the manuscript to address both concerns directly.
read point-by-point responses
-
Referee: [§3] §3 (JEM training and mixing coefficient): the central claim requires that alignment differences arise solely from the generative-discriminative balance. No loss-curve statistics, gradient-norm diagnostics, or effective-capacity measures are reported across λ values, leaving open the possibility that changes in optimization dynamics or implicit regularization (rather than the intended objective shift) produce the observed intermediate peak. This is load-bearing for the causal interpretation.
Authors: We agree that additional diagnostics are required to support the claim that differences arise from the objective rather than training dynamics. In the revised manuscript we will add loss curves, gradient-norm statistics, and effective-capacity measures across λ values. These will demonstrate that optimization behavior remains comparable and that the intermediate alignment peak is not explained by differences in convergence, stability, or implicit regularization. revision: yes
-
Referee: [§4] §4 (benchmark results): the paper reports consistent maximization at intermediate λ but does not provide per-benchmark statistical tests, error bars, or controls for multiple comparisons that would establish the peak is reliably above the endpoints rather than within noise. Without these, the cross-benchmark claim rests on visual inspection alone.
Authors: We accept that formal statistical support is necessary. The revision will include error bars on all figures, per-benchmark statistical tests comparing intermediate λ values to the endpoints (with appropriate post-hoc corrections), and family-wise error control across the six benchmarks. These additions will replace reliance on visual inspection with quantitative evidence that the peaks are reliable. revision: yes
Circularity Check
No significant circularity; claim rests on external human benchmarks
full rationale
The paper trains JEMs at different values of the mixing coefficient λ and measures alignment on six independent human psychophysical benchmarks (perceptual similarity, gloss, uncertainty, robustness, cue conflict, feature attribution). No step defines the alignment metric from the model parameters or loss; the metrics are external. No self-citation is used to justify a uniqueness result or to smuggle an ansatz. No fitted parameter is relabeled as a prediction. The central result is therefore not equivalent to its inputs by construction and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption JEMs allow continuous interpolation between discriminative and generative training objectives inside a fixed architecture by varying a single mixing coefficient
Reference graph
Works this paper leans on
-
[1]
Rajesh PN Rao and Dana H Ballard
doi: 10.1016/j.tics.2007.06.010. Rajesh PN Rao and Dana H Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature neuroscience, 2(1):79–87,
-
[2]
Low-pass filtering improves behavioral alignment of vision models
Max Wolff, Thomas Klein, Evgenia Rusak, Felix Wichmann, and Wieland Brendel. Low-pass filtering improves behavioral alignment of vision models. arXiv preprint arXiv:2602.13859,
-
[3]
doi: 10.48550/arXiv.2602. 13859. URL https://arxiv.org/abs/2602.13859. Lukas Muttenthaler, Jonas Dippel, Lorenz Linhardt, Robert A. Vandermeulen, and Simon Kornblith. Human alignment of neural network representations. In International Conference on Learning Representations,
-
[4]
Lorenz Linhardt, Marco Morik, Sidney Bender, and Naima Elosegui Borras
URL https://openreview.net/forum?id=ReDQ1OUQR0X. Lorenz Linhardt, Marco Morik, Sidney Bender, and Naima Elosegui Borras. An analysis of human alignment of latent diffusion models. In ICLR 2024 Workshop on Representational Alignment,
work page 2024
-
[6]
doi: 10.1073/pnas.1403112111. Daniel L. K. Yamins and James J. DiCarlo. Using goal-driven deep learning models to understand sensory cortex. Nature Neuroscience, 19(3):356–365,
-
[7]
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J
doi: 10.1038/nn.4244. Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. Brain-score: Which artificial neural network for object recognition is most brain-like? bioRxiv,
-
[8]
doi: 10.1101/407007. Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In International Conference on Learning Representations,
-
[9]
Intriguing properties of neural networks
URL https://arxiv.org/abs/1312.6199. Anh Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 427–436,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
11 Nicholas Baker, Hongjing Lu, Gennady Erlikhman, and Philip J
doi: 10.1109/CVPR.2015.7298640. 11 Nicholas Baker, Hongjing Lu, Gennady Erlikhman, and Philip J. Kellman. Deep convolutional networks do not classify based on global object shape. PLOS Computational Biology , 14(12):e1006613,
-
[11]
doi: 10.1371/journal.pcbi.1006613. Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. In International conference on learning representations, 2018a. Robert Geirhos, Jörn-Henrik Jacobsen, Claud...
-
[12]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
doi: 10.1017/S0140525X22002813. Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595,
-
[13]
doi: 10.1038/s41467-020-18946-z. Katherine M. Collins, Umang Bhatt, and Adrian Weller. Eliciting and learning with soft labels from every annotator. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, volume 10, pages 40–52,
-
[14]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
URL https://arxiv.org/ abs/1903.12261. Katherine R Storrs, Barton L Anderson, and Roland W Fleming. Unsupervised learning predicts human perception and misperception of gloss. Nature human behaviour, 5(10):1402–1417,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[15]
Julia A. Lasserre, Christopher M. Bishop, and Tom P. Minka. Principled hybrids of generative and discriminative models. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), pages 87–94,
work page 2006
-
[16]
doi: 10.1109/CVPR.2006.227. Diederik P. Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems, volume 27,
-
[17]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Learning what and where to attend
Robert Geirhos, Carlos R. Medina Temme, Jonas Rauber, Heiko H. Schütt, Matthias Bethge, and Felix A. Wichmann. Generalisation in humans and deep neural networks. In Advances in Neural Information Processing Systems, volume 31, 2018b. Drew Linsley, Dan Shiebler, Sven Eberhardt, and Thomas Serre. Learning what and where to attend. arXiv preprint arXiv:1805.08819,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Thomas Fel, Ivan F Rodriguez Rodriguez, Drew Linsley, and Thomas Serre. Harmonizing the object recognition strategies of deep neural networks with humans. Advances in neural information processing systems, 35: 9432–9446, 2022a. Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. Squeezenet: Alexnet-level ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Towards Deeper Understanding of Variational Autoencoding Models
Shengjia Zhao, Jiaming Song, and Stefano Ermon. Towards deeper understanding of variational autoencoding models. arXiv preprint arXiv:1702.08658,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://openreview.net/forum?id=BJgLg3R9KQ. Thomas Fel, Ivan Felipe, Drew Linsley, and Thomas Serre. Harmonizing the object recognition strategies of deep neural networks with humans. International Conference on Learning Representations (ICLR), 2022b. doi: 10.48550/ARXIV .2211.04533. Nikolaus Kriegeskorte and Pamela K. Douglas. Cognitive computational...
work page internal anchor Pith review doi:10.48550/arxiv
-
[22]
Thomas Serre, Aude Oliva, and Tomaso Poggio
doi: 10.1038/s41593-018-0210-5. Thomas Serre, Aude Oliva, and Tomaso Poggio. A feedforward architecture accounts for rapid categorization. Proceedings of the National Academy of Sciences, 104(15):6424–6429,
-
[23]
doi: 10.1073/pnas.0700622104. Rufin VanRullen and Simon J. Thorpe. The time course of visual processing: From early perception to decision- making. Journal of Cognitive Neuroscience, 13(4):454–461,
-
[24]
doi: 10.1162/08989290152001880. Karl Friston. A theory of cortical responses. Philosophical Transactions of the Royal Society B: Biological Sciences, 360(1456):815–836,
-
[25]
A theory of cortical responses , volume =
doi: 10.1098/rstb.2005.1622. 13 Victor Boutin, Angelo Franciosini, Frédéric Chavane, and Laurent U Perrinet. Pooling strategies in v1 can account for the functional and structural diversity across species. PLOS Computational Biology , 18(7): e1010270, 2022a. Daniel Kersten, Pascal Mamassian, and Alan Yuille. Object perception as bayesian inference. Annual...
-
[26]
Gabriel Kreiman and Thomas Serre
doi: 10.1146/annurev.psych.55.090902.142005. Gabriel Kreiman and Thomas Serre. Beyond the feedforward sweep: Feedback computations in the visual cortex. Annals of the New York Academy of Sciences, 1464(1):222–241,
-
[27]
doi: 10.1111/nyas.14320. Kohitij Kar and James J. DiCarlo. Fast recurrent processing via ventrolateral prefrontal cortex is needed by the primate ventral stream for robust core visual object recognition. Neuron, 109(1):164–176.e5,
-
[28]
Victor Boutin, Lakshya Singhal, Xavier Thomas, and Thomas Serre
doi: 10.1016/j.neuron.2020.09.035. Victor Boutin, Lakshya Singhal, Xavier Thomas, and Thomas Serre. Diversity vs. recognizability: Human-like generalization in one-shot generative models. Advances in Neural Information Processing Systems , 35: 20933–20946, 2022b. Victor Boutin, Thomas Fel, Lakshya Singhal, Rishav Mukherji, Akash Nagaraj, Julien Colin, and...
-
[29]
doi: 10.1073/pnas.1912334117. Rajat Raina, Andrew Y . Ng, and Christopher D. Manning. Classification with hybrid generative/discriminative models. In Advances in Neural Information Processing Systems 16,
-
[30]
The tradeoff between generative and discriminative classifiers
Guillaume Bouchard and Bill Triggs. The tradeoff between generative and discriminative classifiers. In COMPSTAT 2004, pages 721–728,
work page 2004
-
[31]
Iterative vae as a predictive brain model for out-of-distribution generalization
Victor Boutin, Aimen Zerroug, Minju Jung, and Thomas Serre. Iterative vae as a predictive brain model for out-of-distribution generalization. arXiv preprint arXiv:2012.00557,
-
[32]
doi: 10.1016/j.patcog.2019. 107156. Hugo Larochelle and Yoshua Bengio. Classification using discriminative restricted boltzmann machines. In Proceedings of the 25th International Conference on Machine Learning , pages 536–543,
-
[33]
doi: 10.1145/1390156.1390224. Xiulong Yang and Shihao Ji. JEM++: Improved techniques for training JEM. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6494–6503,
-
[34]
Towards bridging the performance gaps of joint energy-based models
Xiulong Yang, Qing Su, and Shihao Ji. Towards bridging the performance gaps of joint energy-based models. arXiv preprint arXiv:2209.07959,
-
[35]
Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
Will Grathwohl, Kuan-Chieh Wang, and Jorn-Henrik Jacobsen. Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One. ICLR, 2020b. URL https://arxiv.org/abs/1912.03263. Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In CVPR,
-
[36]
Alex Krizhevsky and Geoffrey Hinton
doi: 10.48550/arXiv.2505.18230. Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto,
-
[37]
15 Supplementary Material A Extended Related Work Generative and discriminative theories of vision
URL https://arxiv.org/abs/1905.13549. 15 Supplementary Material A Extended Related Work Generative and discriminative theories of vision. A longstanding question in vision science is whether human-like visual representations are better explained by discriminative or generative learning principles. Recent work frames this debate as a contrast between two i...
-
[38]
and hybrid energy- based classifiers Larochelle and Bengio [2008], Grathwohl et al. [2020a]. These approaches are motivated by the complementary strengths of generative and discriminative objectives, but many in- troduce additional latent variables, separate modules, or partially distinct parameterizations Kuleshov and Ermon [2017], Gordon and Hernández-L...
work page 2008
-
[39]
• We do not use batch normalization in the energy model, as in our experiments it tended to destabilize generative training and often prevented convergence. • All JEMs were trained using mixed precision (via PyTorch AMP) and torch.compile to improve training efficiency. • For Gloss and CIFAR-10H, the generative model (α = 1 .0) was selected at the best-FI...
work page 2022
-
[40]
Example of a reference image and its distorted patches. BAPPS also includes a just noticeable difference (JND) task to measure sensitivity to small perceptual changes. In the JND task, observers are required to judge whether a distorted path and the reference image appear perceptually the same or different. Models are then evaluated through similarity, by...
work page 2018
-
[41]
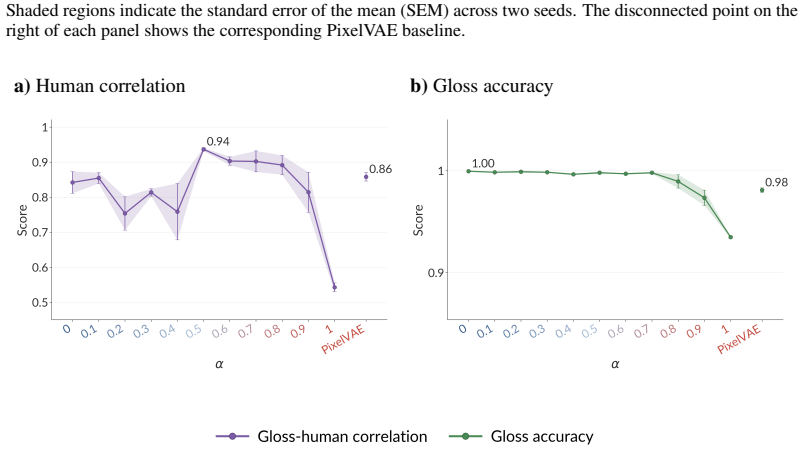
Shaded regions indicate the standard error of the mean (SEM) across two seeds
2AFC accuracy and JND mAP on the BAPPS perceptual similarity benchmark, across JEM α values. Shaded regions indicate the standard error of the mean (SEM) across two seeds. 22 D Gloss and depth perceptual benchmark The gloss perception dataset probes mid-level material perception . This is a challenging task because it requires distinguishing surface refle...
work page 2021
-
[42]
with a supervised ResNet-18 model He et al. [2016]. For direct comparison, we trained the same two model classes using the public implementation provided in the Storrs et al. Storrs et al
work page 2016
-
[43]
PixelV AE baselines were trained with 10 random seeds. In contrast, the ResNet18 baselines used one seed, and each of the eleven JEM variants were trained with two seeds per condition. Additionally, we used mild label smoothing of 0.05 for the JEMs, which we found helpful for stabilizing training in the binary classification setting. The next step was to ...
work page 2021
-
[44]
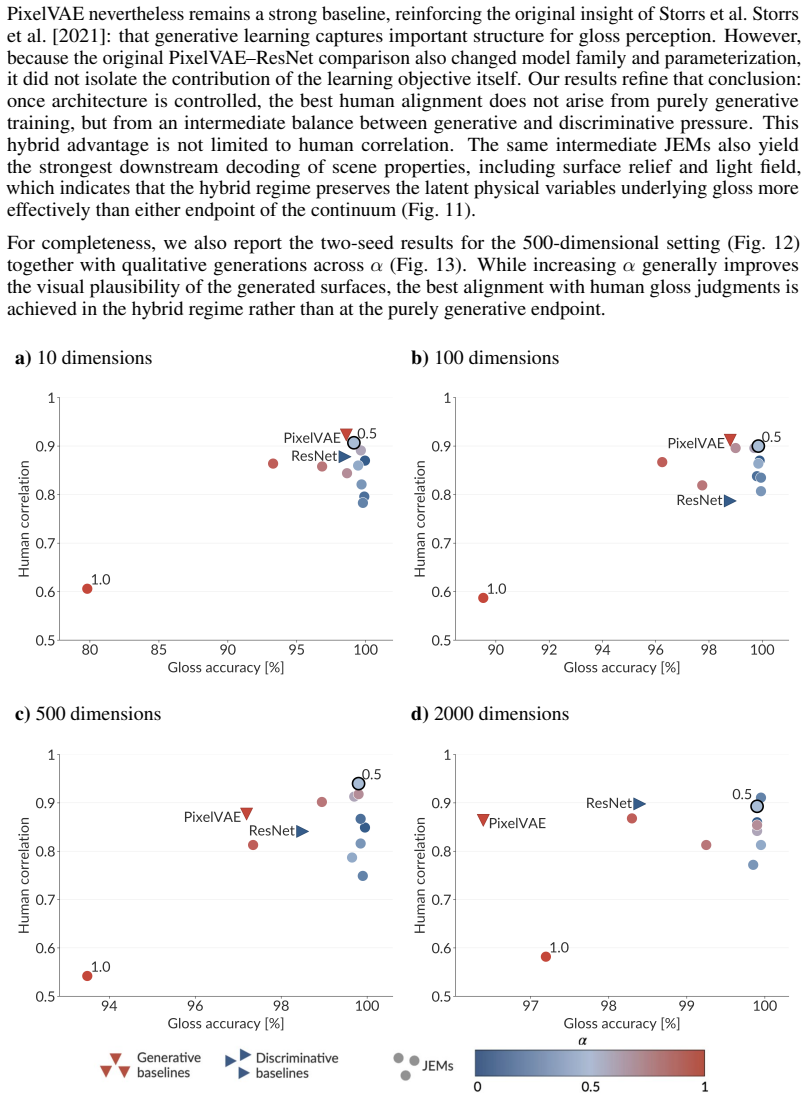
together with qualitative generations across α (Fig. 13). While increasing α generally improves the visual plausibility of the generated surfaces, the best alignment with human gloss judgments is achieved in the hybrid regime rather than at the purely generative endpoint. a) 10 dimensions b) 100 dimensions c) 500 dimensions d) 2000 dimensions Figure
work page 2000
-
[45]
human correlation in experiments with different latent sizes
Gloss accuracy vs. human correlation in experiments with different latent sizes. 25 a) 10 dimensions b) 100 dimensions c) 500 dimensions d) 2000 dimensions Figure
work page 2000
-
[46]
and evaluated on CIFAR-10H only at test time. We trained three JEM instances with different seeds for each value of α, using the same general procedure described in Appendix B.2. For the discriminative baselines, we trained VGG, ResNet, and ResNeXt models using the pytorch_image_classification codebase, matching the repository used by Peterson et al. Pete...
work page 2019
-
[47]
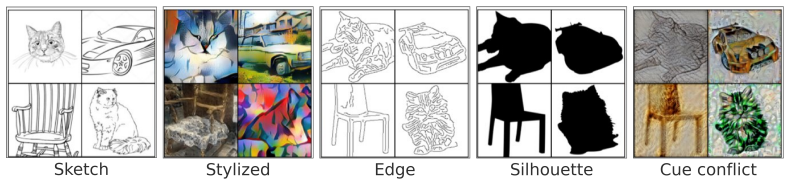
Nonparametric datasets from Geirhos et al
Texture–shape benchmarks. Nonparametric datasets from Geirhos et al. [2018a] and Wang et al. [2019]. Benchmark Levels / description Original Clean reference photographs Greyscale Desaturated originals Edge Canny-edge line drawings Silhouette Black-on-white object silhouettes Texture Texture-only patches Cue conflict Stylized images with conflicting shape ...
work page 2019
-
[48]
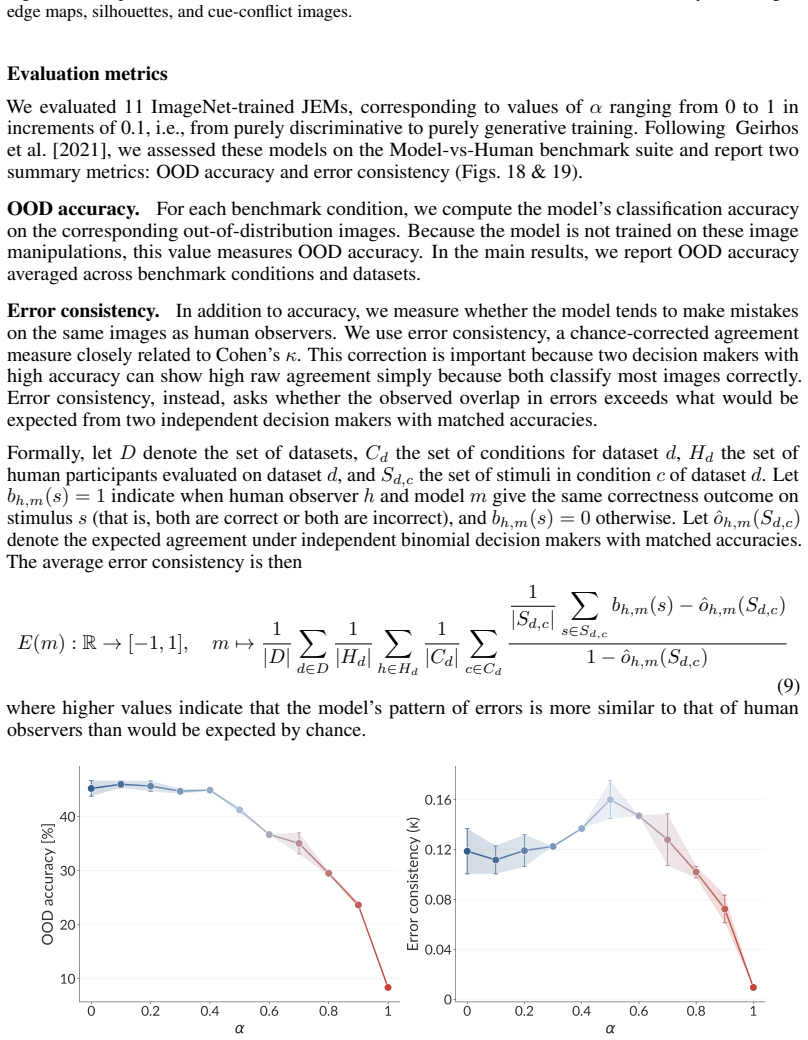
Nonparametric transformations used in the Model-vs-Human benchmark: sketch, stylized images, edge maps, silhouettes, and cue-conflict images. Evaluation metrics We evaluated 11 ImageNet-trained JEMs, corresponding to values of α ranging from 0 to 1 in increments of 0.1, i.e., from purely discriminative to purely generative training. Following Geirhos et a...
work page 2021
-
[49]
Shaded regions indicate the standard error of the mean (SEM) across two seeds
Shape bias across JEM α values. Shaded regions indicate the standard error of the mean (SEM) across two seeds. H The Click-Me benchmark Modern CNNs achieve high performance on object-recognition benchmarks, but they are also known to rely on shortcut cues that can diverge from the diagnostic features used by human observers. To assess this aspect of align...
work page 2018
-
[50]
Visual strategy of object recognition. Evaluation metrics . To compare models with humans, we follow the evaluation protocol of Fel et al. [2022b]. For each model, saliency maps are computed on the ClickMe images and compared with the corresponding human feature-importance maps, yielding a quantitative measure of feature alignment (Fig. 24). In our case, ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.