CAFD: Concept-Aware DNN Fault Detection using VLMs
Pith reviewed 2026-06-30 18:15 UTC · model grok-4.3
The pith
CAFD uses vision-language models to extract concept failure ratios that improve DNN fault detection rates by an average of 18.3% over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
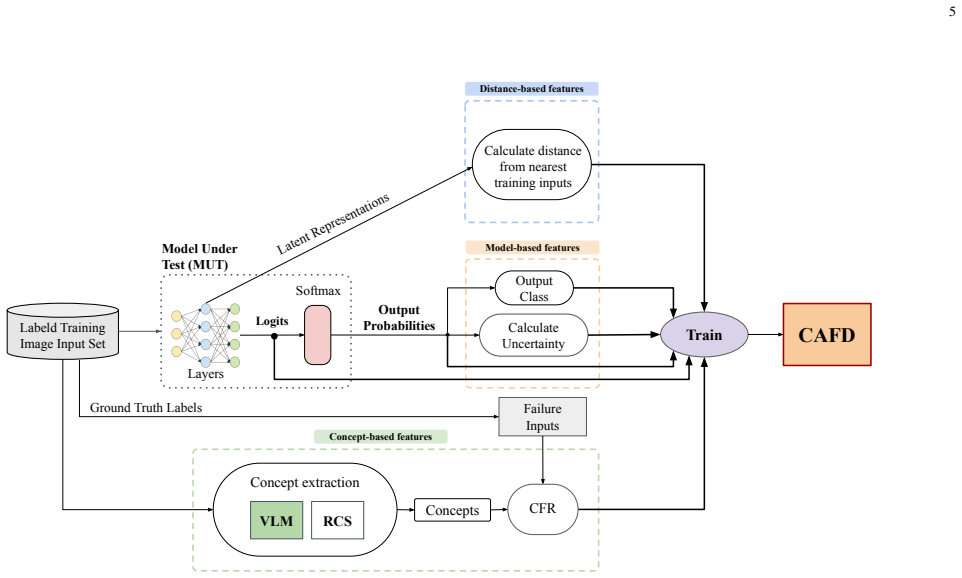
CAFD integrates model-based signals, distance-based features, and the Concept Failure Ratio (CFR) extracted via VLMs to detect faults in DNNs. CFR quantifies the likelihood that image concepts are associated with failures. This combination yields higher Fault Detection Rates than five state-of-the-art baselines, with an average improvement of 18.3% across subjects and selection budgets. The approach maintains efficiency suitable for real-world use on datasets including ImageNet.
What carries the argument
Concept Failure Ratio (CFR), a feature that leverages Vision-Language Models to extract textual concepts from images and measure their association with DNN failures.
If this is right
- CAFD outperforms baselines in Fault Detection Rate across constrained budgets.
- CFR acts as an effective indicator for fault detection.
- The method applies to multiple DNN models and large-scale datasets like ImageNet.
- Hybrid approaches can integrate semantic information while keeping computational overhead practical.
Where Pith is reading between the lines
- Incorporating external models like VLMs may help detect faults that pure internal signals miss in safety-critical systems.
- This approach could lead to detectors that adapt to new concepts without retraining the original DNN.
- Extending CFR to video or sequential data might broaden fault detection beyond static images.
Load-bearing premise
That the Concept Failure Ratio extracted from VLMs supplies semantic information about failures that is not already available from the DNN outputs or distance features alone.
What would settle it
Running the same evaluation but training the detector without the CFR feature and finding no drop in Fault Detection Rate compared to the full CAFD.
Figures
read the original abstract
Fault detection for Deep Neural Networks (DNNs) has received increasing attention in recent years. While more advanced hybrid approaches have been proposed to combine multiple sources of information and outperform earlier techniques, they often incur substantial computational overhead, limiting scalability and practicality in real-world settings. In this paper, we introduce Concept-Aware Fault Detection (CAFD), a learning-based approach that achieves superior fault detection performance by effectively integrating multiple information sources while maintaining practical efficiency. Specifically, CAFD is trained using a carefully selected set of informative features, including model-based signals derived from the DNN's outputs, distance-based features, and a novel concept-based feature, called Concept Failure Ratio (CFR). CFR leverages Vision-Language Models (VLMs) to extract textual concepts from images and quantify the likelihood that their presence is associated with DNN failures. By incorporating this feature, CAFD benefits from complementary semantic information, enabling more effective fault detection. Our results demonstrate that CFR serves as an effective indicator for DNN fault detection. We conduct an extensive empirical evaluation of CAFD, comparing it against five state-of-the-art baselines across three subject DNN models and datasets, including ImageNet. Across a wide range of constrained selection budgets, CAFD consistently outperforms all baselines in Fault Detection Rate (FDR), achieving average FDR improvements of 18.3% across all investigated subjects and budget sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAFD, a learning-based DNN fault detector that combines model-based signals, distance-based features, and a novel Concept Failure Ratio (CFR) derived from VLMs to extract semantic concepts and quantify failure likelihood. It claims CAFD outperforms five baselines in Fault Detection Rate (FDR) by an average of 18.3% across three subject models/datasets (including ImageNet) and varying budgets, with CFR providing complementary semantic information that makes it an effective indicator.
Significance. If the performance gains are shown to be robust and attributable to CFR, the approach could offer a scalable hybrid method for DNN fault detection that leverages external VLMs for semantic signals without high overhead. The empirical comparison to multiple baselines across budgets is a strength, but significance is limited by the absence of evidence that CFR supplies orthogonal information.
major comments (2)
- [Experimental Evaluation] The central performance claim (18.3% average FDR improvement) is attributed to the addition of CFR as complementary semantic information, yet the Experimental Evaluation section reports no ablation study, correlation analysis, or feature-importance metric (e.g., SHAP) that isolates CFR's contribution from the model-based and distance-based features alone. Without this, it cannot be verified whether the learning-based detector would achieve comparable gains from the non-CFR feature set.
- [Methodology] The Methodology section supplies no details on the training procedure for the learning-based detector (e.g., model architecture, hyperparameters, optimization), the exact method for combining the three feature types, dataset splits, or controls for selection bias in the constrained budgets, rendering the reported FDR numbers impossible to reproduce or assess for statistical significance.
minor comments (1)
- The abstract mentions 'three subject DNN models and datasets, including ImageNet' but does not name the other two models or datasets; this should be stated explicitly for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to add the requested analyses and details.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central performance claim (18.3% average FDR improvement) is attributed to the addition of CFR as complementary semantic information, yet the Experimental Evaluation section reports no ablation study, correlation analysis, or feature-importance metric (e.g., SHAP) that isolates CFR's contribution from the model-based and distance-based features alone. Without this, it cannot be verified whether the learning-based detector would achieve comparable gains from the non-CFR feature set.
Authors: We agree that the current manuscript does not include an ablation study or analysis isolating CFR's contribution, which limits verification of its complementary value. In the revised version we will add an ablation comparing the full feature set against the non-CFR features alone, plus correlation analysis and feature-importance metrics (e.g., SHAP) to demonstrate orthogonality. revision: yes
-
Referee: [Methodology] The Methodology section supplies no details on the training procedure for the learning-based detector (e.g., model architecture, hyperparameters, optimization), the exact method for combining the three feature types, dataset splits, or controls for selection bias in the constrained budgets, rendering the reported FDR numbers impossible to reproduce or assess for statistical significance.
Authors: We acknowledge that these implementation details are missing from the current manuscript. The revised manuscript will expand the Methodology section with the detector architecture, hyperparameters, optimization procedure, feature combination method, dataset splits, and controls for selection bias and statistical significance under constrained budgets. revision: yes
Circularity Check
No circularity; claims rest on external VLM features and empirical baseline comparisons
full rationale
The paper defines CAFD as a supervised detector trained on a feature vector that explicitly includes three distinct sources (model outputs, distance metrics, and VLM-derived CFR). Performance is reported via direct comparison to five external baselines on held-out data across multiple subjects and budgets; no equation reduces a claimed prediction to a fitted parameter by construction, and no load-bearing premise is justified solely by self-citation. The assumption that CFR supplies complementary information is an empirical hypothesis tested by the evaluation rather than a definitional identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can extract textual concepts from images that are meaningfully associated with DNN failure cases.
invented entities (1)
-
Concept Failure Ratio (CFR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep learning in computer vision: A critical review of emerging techniques and application scenar- ios,
J. Chai, H. Zeng, A. Li, and E. W. Ngai, “Deep learning in computer vision: A critical review of emerging techniques and application scenar- ios,”Machine Learning with Applications, vol. 6, p. 100134, 2021. 12
2021
-
[2]
A survey on deep learning for software engineering,
Y . Yang, X. Xia, D. Lo, and J. Grundy, “A survey on deep learning for software engineering,”ACM Computing Surveys (CSUR), vol. 54, no. 10s, pp. 1–73, 2022
2022
-
[3]
Autonomous tissue manipulation via surgical robot using deep reinforcement learning and evolutionary algorithm,
A. A. Shahkoo and A. A. Abin, “Autonomous tissue manipulation via surgical robot using deep reinforcement learning and evolutionary algorithm,”IEEE Transactions on Medical Robotics and Bionics, vol. 5, no. 1, pp. 30–41, 2023
2023
-
[4]
Test optimization in dnn testing: a survey,
Q. Hu, Y . Guo, X. Xie, M. Cordy, L. Ma, M. Papadakis, and Y . Le Traon, “Test optimization in dnn testing: a survey,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 4, pp. 1–42, 2024
2024
-
[5]
Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks,
Y . Feng, Q. Shi, X. Gao, J. Wan, C. Fang, and Z. Chen, “Deepgini: prioritizing massive tests to enhance the robustness of deep neural networks,” inProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2020, pp. 177–188
2020
-
[6]
Simple techniques work surprisingly well for neural network test prioritization and active learning,
M. Weiss and P. Tonella, “Simple techniques work surprisingly well for neural network test prioritization and active learning,” inProceedings of the 31th ACM SIGSOFT International Symposium on Software Testing and Analysis, 2022
2022
-
[7]
Distance- aware test input selection for deep neural networks,
Z. Li, Z. Xu, R. Ji, M. Pan, T. Zhang, L. Wang, and X. Li, “Distance- aware test input selection for deep neural networks,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024, pp. 248–260
2024
-
[8]
In defense of simple techniques for neural network test case selection,
S. Bao, C. Sha, B. Chen, X. Peng, and W. Zhao, “In defense of simple techniques for neural network test case selection,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2023, pp. 501–513
2023
-
[9]
Metasel: A test selection approach for fine-tuned dnn models,
A. Abbasishahkoo, M. Dadkhah, L. Briand, and D. Lin, “Metasel: A test selection approach for fine-tuned dnn models,”IEEE Transactions on Software Engineering, 2025
2025
-
[10]
Adaptive test selection for deep neural networks,
X. Gao, Y . Feng, Y . Yin, Z. Liu, Z. Chen, and B. Xu, “Adaptive test selection for deep neural networks,” inProceedings of the 44th International Conference on Software Engineering, 2022, pp. 73–85
2022
-
[11]
Deepgd: A multi-objective black-box test selection approach for deep neural net- works,
Z. Aghababaeyan, M. Abdellatif, M. Dadkhah, and L. Briand, “Deepgd: A multi-objective black-box test selection approach for deep neural net- works,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 6, pp. 1–29, 2024
2024
-
[12]
Robust test selection for deep neural networks,
W. Sun, M. Yan, Z. Liu, and D. Lo, “Robust test selection for deep neural networks,”IEEE Transactions on Software Engineering, vol. 49, no. 12, pp. 5250–5278, 2023
2023
-
[13]
Testrank: Bringing order into unlabeled test instances for deep learning tasks,
Y . Li, M. Li, Q. Lai, Y . Liu, and Q. Xu, “Testrank: Bringing order into unlabeled test instances for deep learning tasks,”Advances in Neural Information Processing Systems, vol. 34, pp. 20 874–20 886, 2021
2021
-
[14]
Test selection for deep neural networks using meta-models with uncertainty metrics,
D. Demir, A. Betin Can, and E. Surer, “Test selection for deep neural networks using meta-models with uncertainty metrics,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024, pp. 678–690
2024
-
[15]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[16]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision (IJCV), vol. 115, no. 3, pp. 211–252, 2015
2015
-
[17]
Guiding deep learning system testing using surprise adequacy,
J. Kim, R. Feldt, and S. Yoo, “Guiding deep learning system testing using surprise adequacy,” in2019 IEEE/ACM 41st International Con- ference on Software Engineering (ICSE). IEEE, 2019, pp. 1039–1049
2019
-
[18]
Deepxplore: Automated whitebox testing of deep learning systems,
K. Pei, Y . Cao, J. Yang, and S. Jana, “Deepxplore: Automated whitebox testing of deep learning systems,” inproceedings of the 26th Symposium on Operating Systems Principles, 2017, pp. 1–18
2017
-
[19]
Deepgauge: Multi-granularity testing criteria for deep learning systems,
L. Ma, F. Juefei-Xu, F. Zhang, J. Sun, M. Xue, B. Li, C. Chen, T. Su, L. Li, Y . Liu, J. Zhao, and Y . Wang, “Deepgauge: Multi-granularity testing criteria for deep learning systems,”2018 33rd IEEE/ACM In- ternational Conference on Automated Software Engineering (ASE), pp. 120–131, 2018
2018
-
[20]
Teasma: A practical methodology for test adequacy assessment of deep neural networks,
A. Abbasishahkoo, M. Dadkhah, L. Briand, and D. Lin, “Teasma: A practical methodology for test adequacy assessment of deep neural networks,”IEEE Transactions on Software Engineering, 2024
2024
-
[21]
Prioritiz- ing test inputs for deep neural networks via mutation analysis,
Z. Wang, H. You, J. Chen, Y . Zhang, X. Dong, and W. Zhang, “Prioritiz- ing test inputs for deep neural networks via mutation analysis,” in2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 2021, pp. 397–409
2021
-
[22]
A fast and elitist multiobjective genetic algorithm: Nsga-ii,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: Nsga-ii,”IEEE transactions on evolu- tionary computation, vol. 6, no. 2, pp. 182–197, 2002
2002
-
[23]
A highly efficient diversity-based input selection for dnn improvement using vlms,
A. Abbasishahkoo, M. Dadkhah, and L. Briand, “A highly efficient diversity-based input selection for dnn improvement using vlms,”arXiv preprint arXiv:2601.08024, 2026
-
[24]
Graphprior: Mutation-based test input prioritization for graph neural networks,
X. Dang, Y . Li, M. Papadakis, J. Klein, T. F. Bissyand´e, and Y . Le Traon, “Graphprior: Mutation-based test input prioritization for graph neural networks,”ACM Transactions on Software Engineering and Methodol- ogy, vol. 33, no. 1, pp. 1–40, 2023
2023
-
[25]
An empirical study on data distribution-aware test selection for deep learning enhancement,
Q. Hu, Y . Guo, M. Cordy, X. Xie, L. Ma, M. Papadakis, and Y . Le Traon, “An empirical study on data distribution-aware test selection for deep learning enhancement,”ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 31, no. 4, pp. 1–30, 2022
2022
-
[26]
Evaluating the robustness of test selection methods for deep neural networks,
Q. Hu, Y . Guo, X. Xie, M. Cordy, W. Ma, M. Papadakis, and Y . L. Traon, “Evaluating the robustness of test selection methods for deep neural networks,”arXiv preprint arXiv:2308.01314, 2023
-
[27]
Calibrated neighborhood aware confidence measure for deep metric learning,
M. Karpusha, S. Yun, and I. Fehervari, “Calibrated neighborhood aware confidence measure for deep metric learning,”arXiv preprint arXiv:2006.04935, 2020
-
[28]
Evaluating surprise adequacy for deep learning system testing,
J. Kim, R. Feldt, and S. Yoo, “Evaluating surprise adequacy for deep learning system testing,”ACM Transactions on Software Engineering and Methodology, vol. 32, no. 2, pp. 1–29, 2023
2023
-
[29]
Debugging and runtime analysis of neural networks with vlms (a case study),
B. C. Hu, D. Gopinath, C. S. P ˘as˘areanu, N. Narodytska, R. Mangal, and S. Jha, “Debugging and runtime analysis of neural networks with vlms (a case study),” in2025 IEEE/ACM 4th International Conference on AI Engineering–Software Engineering for AI (CAIN). IEEE, 2025, pp. 161–172
2025
-
[30]
Concept-based analysis of neural networks via vision-language models,
R. Mangal, N. Narodytska, D. Gopinath, B. C. Hu, A. Roy, S. Jha, and C. S. P ˘as˘areanu, “Concept-based analysis of neural networks via vision-language models,” inInternational Symposium on AI Verification. Springer, 2024, pp. 49–77
2024
-
[31]
Text-to-concept (and back) via cross-model alignment,
M. Moayeri, K. Rezaei, M. Sanjabi, and S. Feizi, “Text-to-concept (and back) via cross-model alignment,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 25 037–25 060
2023
-
[32]
Visual genome: Connecting language and vision using crowdsourced dense image annotations,
R. Krishna, Y . Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y . Kalantidis, L.-J. Li, D. A. Shammaet al., “Visual genome: Connecting language and vision using crowdsourced dense image annotations,” International journal of computer vision, vol. 123, no. 1, pp. 32–73, 2017
2017
-
[33]
Black-box testing of deep neural networks through test case diversity,
Z. Aghababaeyan, M. Abdellatif, L. Briand, M. Bagherzadehet al., “Black-box testing of deep neural networks through test case diversity,” IEEE Transactions on Software Engineering, vol. 49, no. 5, pp. 3182– 3204, 2023
2023
-
[34]
Supporting deep neural network safety analysis and retraining through heatmap-based unsupervised learning,
H. Fahmy, F. Pastore, M. Bagherzadeh, and L. Briand, “Supporting deep neural network safety analysis and retraining through heatmap-based unsupervised learning,”IEEE Transactions on Reliability, vol. 70, no. 4, pp. 1641–1657, 2021
2021
-
[35]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Density-based clustering based on hierarchical density estimates,
R. J. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical density estimates,” inPacific-Asia conference on knowledge discovery and data mining. Springer, 2013, pp. 160–172
2013
-
[37]
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,”Journal of computational and applied mathematics, vol. 20, pp. 53–65, 1987
1987
-
[38]
Density-based clustering validation,
D. Moulavi, P. A. Jaskowiak, R. J. Campello, A. Zimek, and J. Sander, “Density-based clustering validation,” inProceedings of the 2014 SIAM international conference on data mining. SIAM, 2014, pp. 839–847
2014
-
[39]
Comparison of feature importance mea- sures as explanations for classification models,
M. Saarela and S. Jauhiainen, “Comparison of feature importance mea- sures as explanations for classification models,”SN Applied Sciences, vol. 3, no. 2, p. 272, 2021
2021
-
[40]
Gene selection for cancer classification using support vector machines,
I. Guyon, J. Weston, S. Barnhill, and V . Vapnik, “Gene selection for cancer classification using support vector machines,”Machine learning, vol. 46, no. 1, pp. 389–422, 2002
2002
-
[41]
Explaining odds ratios,
M. Szumilas, “Explaining odds ratios,”Journal of the Canadian academy of child and adolescent psychiatry, vol. 19, no. 3, p. 227, 2010
2010
-
[42]
K. Alex, N. Vinod, and H. Geoffrey. The cifar-10 dataset. [Online]. Available: https://www.cs.toronto.edu/∼kriz/cifar.html
-
[43]
Multiple- boundary clustering and prioritization to promote neural network retrain- ing,
W. Shen, Y . Li, L. Chen, Y . Han, Y . Zhou, and B. Xu, “Multiple- boundary clustering and prioritization to promote neural network retrain- ing,” inProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, 2020, pp. 410–422
2020
-
[44]
Cats are not fish: Deep learning testing calls for out-of-distribution awareness,
D. Berend, X. Xie, L. Ma, L. Zhou, Y . Liu, C. Xu, and J. Zhao, “Cats are not fish: Deep learning testing calls for out-of-distribution awareness,” inProceedings of the 35th IEEE/ACM international conference on automated software engineering, 2020, pp. 1041–1052. 13
2020
-
[45]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[46]
The link to these artifacts will be made publicly available upon accep- tance of this paper
-
[47]
Boosting operational dnn testing efficiency through conditioning,
Z. Li, X. Ma, C. Xu, C. Cao, J. Xu, and J. L ¨u, “Boosting operational dnn testing efficiency through conditioning,” inProceedings of the 2019 27th ACM Joint meeting on European software engineering conference and symposium on the foundations of software engineering, 2019, pp. 499–509
2019
-
[48]
Deepmutation++: A mutation testing framework for deep learning systems,
Q. Hu, L. Ma, X. Xie, B. Yu, Y . Liu, and J. Zhao, “Deepmutation++: A mutation testing framework for deep learning systems,” in2019 34th IEEE/ACM International Conference on Automated Software Engineer- ing (ASE). IEEE, 2019, pp. 1158–1161
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.