Cascade-KDE: Robust Time-Series Restoration under Out-of-Distribution Impulse Corruptions
Pith reviewed 2026-06-30 16:00 UTC · model grok-4.3
The pith
Cascade-KDE restores time series by truncating a 2D temporal-amplitude density to exclude impulse outliers while preserving local features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cascade-KDE estimates a two-dimensional temporal-amplitude density from corrupted observations, applies Density-Truncated Robust Expectation to limit influence of abnormal points, and refines the sequence through an exponential cascade with adaptive stopping, producing restored trajectories that remain close to the original local structure under out-of-distribution impulse corruptions.
What carries the argument
Density-Truncated Robust Expectation applied to a two-dimensional temporal-amplitude density estimate.
If this is right
- Restored series achieve higher curve fidelity and better derivative preservation than classical filters or learning-based baselines.
- Downstream classification accuracy improves when the restored data is used as input.
- Runtime is lower than the compared baselines while still delivering the fidelity gains.
- Bounded density-based restoration can serve as a practical preprocessing step in noisy time-series pipelines.
Where Pith is reading between the lines
- The same truncation logic could be tested on multivariate sensor streams where impulses appear in only some channels.
- Adaptive stopping in the cascade might reduce unnecessary iterations in other iterative restoration algorithms.
- Controlled experiments that vary the fraction of impulses while holding signal features fixed would directly test the separation claim.
Load-bearing premise
A two-dimensional temporal-amplitude density estimated from the corrupted observations, combined with density truncation, can reliably separate out-of-distribution impulses from the underlying signal without distorting task-critical local features.
What would settle it
A dataset in which genuine high-amplitude signal features occupy low-density regions in the temporal-amplitude plane, so that truncation removes or distorts those features.
Figures

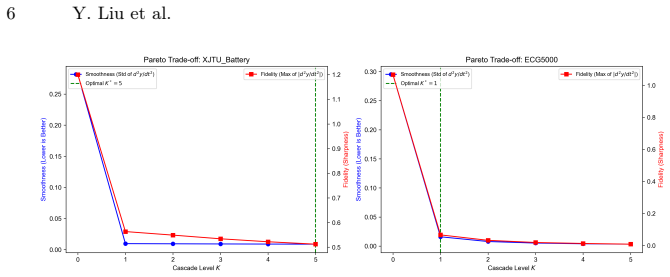
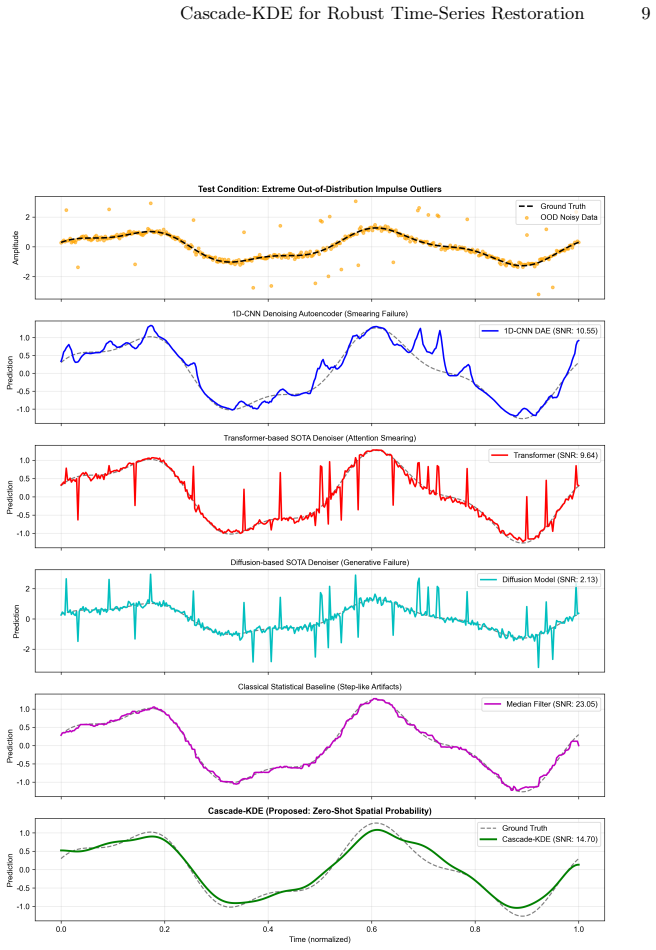
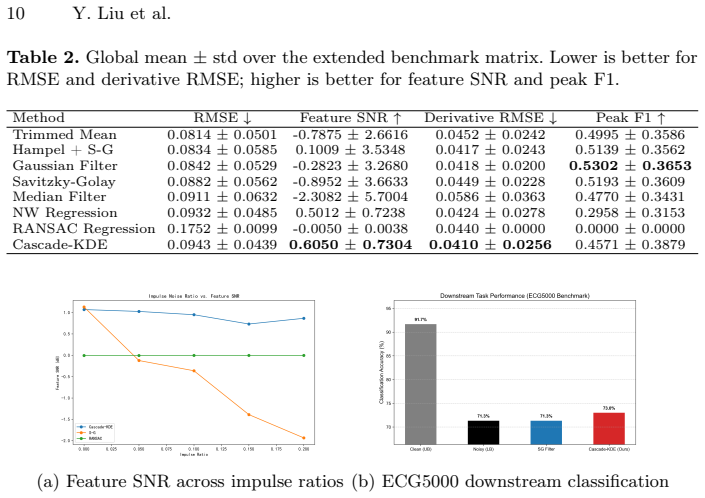

read the original abstract
Real-world time-series data in industrial sensing, healthcare, and energy systems is often corrupted by a mixture of Gaussian noise and occasional large-magnitude impulse outliers. For tasks that depend on local shape, such as ECG morphology analysis and battery degradation monitoring, the main requirement is not only low reconstruction error but also preservation of derivative peaks and task-critical features. We propose Cascade-KDE, a training-free restoration framework for corrupted time series. The method first estimates a two-dimensional temporal-amplitude density, then applies a Density-Truncated Robust Expectation to limit the influence of distant abnormal points, and finally refines the sequence through an exponential cascade with adaptive stopping. This design aims to improve robustness under out-of-distribution impulse corruptions while keeping the restored trajectory close to the original local structure. Across several benchmark datasets, the proposed method shows consistent gains over classical filters and representative learning-based baselines on curve fidelity, derivative preservation, downstream classification, and runtime efficiency. These results suggest that bounded density-based restoration is a practical option for feature-preserving preprocessing in noisy time-series pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cascade-KDE, a training-free framework for restoring time series corrupted by Gaussian noise and out-of-distribution impulse outliers. It estimates a two-dimensional temporal-amplitude density directly from the corrupted input, applies Density-Truncated Robust Expectation to limit the influence of abnormal points, and refines the sequence via an exponential cascade with adaptive stopping. The central claim is that this yields consistent gains over classical filters and learning-based baselines on curve fidelity, derivative preservation, downstream classification accuracy, and runtime efficiency across several benchmark datasets, while preserving task-critical local structure.
Significance. If the separation assumption holds, the approach could provide a practical training-free preprocessing option for feature-sensitive applications such as ECG morphology analysis and battery degradation monitoring, where both reconstruction accuracy and derivative fidelity matter. The emphasis on bounded density estimation from corrupted observations alone is a potentially useful direction for robust time-series pipelines.
major comments (2)
- [Method description (abstract and §3)] The core assumption that a 2D temporal-amplitude density estimated from the corrupted observations, followed by density truncation inside the Robust Expectation step, can systematically isolate OOD impulses without distorting task-critical local features or derivatives is load-bearing for all reported gains. No analytic bound on the truncation threshold, no sensitivity analysis, and no ablation isolating the truncation operator are supplied, leaving the separation claim unverified even if tables appear favorable.
- [Abstract and Results] Abstract asserts empirical gains on curve fidelity, derivative preservation, downstream classification, and runtime across multiple benchmark datasets, yet supplies neither quantitative numbers, error bars, dataset descriptions, statistical tests, nor implementation details. This prevents any assessment of whether the claimed improvements are statistically meaningful or reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the central assumptions of Cascade-KDE and the presentation of empirical results. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The core assumption that a 2D temporal-amplitude density estimated from the corrupted observations, followed by density truncation inside the Robust Expectation step, can systematically isolate OOD impulses without distorting task-critical local features or derivatives is load-bearing for all reported gains. No analytic bound on the truncation threshold, no sensitivity analysis, and no ablation isolating the truncation operator are supplied, leaving the separation claim unverified even if tables appear favorable.
Authors: The referee correctly notes that the separation assumption underpins the reported gains. The Density-Truncated Robust Expectation step is designed so that OOD impulses fall into low-density regions of the estimated 2D temporal-amplitude distribution and are thereby down-weighted, while in-distribution points retain influence; this is motivated by principles from robust kernel density estimation. We do not supply an analytic bound on the truncation threshold. However, we will add a sensitivity analysis across a range of truncation values and an ablation that isolates the truncation operator from the rest of the cascade in the revised manuscript to provide stronger empirical verification of the separation claim. revision: yes
-
Referee: [Abstract and Results] Abstract asserts empirical gains on curve fidelity, derivative preservation, downstream classification, and runtime across multiple benchmark datasets, yet supplies neither quantitative numbers, error bars, dataset descriptions, statistical tests, nor implementation details. This prevents any assessment of whether the claimed improvements are statistically meaningful or reproducible.
Authors: The abstract as written states the existence of gains without numerical values or statistical details, which limits immediate assessment. The full manuscript already contains the supporting tables with error bars, dataset descriptions, implementation details, and results on downstream tasks. To address the concern directly, we will revise the abstract to include representative quantitative improvements (e.g., relative reductions in reconstruction and derivative error) and will ensure that any statistical tests used in the experiments section are explicitly referenced. revision: yes
Circularity Check
No significant circularity; training-free method with no self-referential derivations or fitted predictions
full rationale
The paper describes a training-free Cascade-KDE procedure that estimates a 2D temporal-amplitude density directly from the input corrupted series, applies density truncation in a Robust Expectation step, and refines via exponential cascade. No equations, parameters, or results are presented that reduce by construction to the inputs (e.g., no fitted quantity renamed as a prediction, no self-citation chains justifying uniqueness, and no ansatz smuggled via prior work). Performance claims rest on empirical benchmarks rather than analytic derivations that loop back to the method's own definitions. This is the expected non-finding for a preprocessing heuristic without hidden self-dependencies.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Density-Truncated Robust Expectation
no independent evidence
-
exponential cascade with adaptive stopping
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the AAAI conference on artificial intelligence
Chen, D., Lin, Y., Li, W., Li, P., Zhou, J., Sun, X.: Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In: Proceedings of the AAAI conference on artificial intelligence. vol. 34, pp. 3438–3445 (2020)
2020
-
[2]
IEEE access9, 120043–120065 (2021)
Choi, K., Yi, J., Park, C., Yoon, S.: Deep learning for anomaly detection in time- series data: Review, analysis, and guidelines. IEEE access9, 120043–120065 (2021)
2021
-
[3]
arXiv preprint arXiv:2002.09545 (2020)
Gao, J., Song, X., Wen, Q., Wang, P., Sun, L., Xu, H.: Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv preprint arXiv:2002.09545 (2020)
-
[4]
In: 2025 IEEE Applied Power Electronics Con- ference and Exposition (APEC)
Gong, T., Lee, J., Lee, S., Kim, Y., Ko, B., Na, W., Choi, S., Kim, J.: Enhanced incremental capacity analysis for evaluating battery degradation mechanisms of optimized fast charging methods. In: 2025 IEEE Applied Power Electronics Con- ference and Exposition (APEC). pp. 3006–3011. IEEE (2025)
2025
-
[5]
In: 2025 IEEE Vehicle Power and Propulsion Conference (VPPC)
Liao, B., Liu, Y., Gong, Y., Wu, Y., Sun, J.: State-of-charge estimation for battery based on integrated incremental capacity analysis and dual extended kalman filter. In: 2025 IEEE Vehicle Power and Propulsion Conference (VPPC). pp. 1–6. IEEE (2025)
2025
-
[6]
Frontiers of Information Technology & Electronic Engineering25(1), 19–41 (Dec 2023)
Lin, L., Li, Z., Li, R., Li, X., Gao, J.: Diffusion models for time-series ap- plications: a survey. Frontiers of Information Technology & Electronic Engineering25(1), 19–41 (Dec 2023). https://doi.org/10.1631/fitee.2300310, http://dx.doi.org/10.1631/FITEE.2300310
-
[7]
In: Proceedings of the 33rd ACM Inter- national Conference on Information and Knowledge Management
Peng, J., Lei, R., Wei, Z.: Beyond over-smoothing: Uncovering the trainability challenges in deep graph neural networks. In: Proceedings of the 33rd ACM Inter- national Conference on Information and Knowledge Management. pp. 1878–1887 (2024)
2024
-
[8]
In: Meila, M., Zhang, T
Rasul, K., Seward, C., Schuster, I., Vollgraf, R.: Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8857–8868. PMLR (18–24 Jul 2021), https://proceedi...
2021
-
[9]
In: Proceed- ings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining
Su, Y., Zhao, Y., Niu, C., Liu, R., Sun, W., Pei, D.: Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In: Proceed- ings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. pp. 2828–2837 (2019) 14 Y. Liu et al
2019
-
[10]
Advances in neural information processing systems34, 24804–24816 (2021)
Tashiro, Y., Song, J., Song, Y., Ermon, S.: Csdi: Conditional score-based diffusion models for probabilistic time series imputation. Advances in neural information processing systems34, 24804–24816 (2021)
2021
-
[11]
Ionics31(3), 2457–2471 (2025)
Wen, J., Wang, C., Zhao, Z., Sun, Z.: Capacity estimation of lithium-ion batter- ies based on segment ic curve data dimensionality reduction and reconstruction methods. Ionics31(3), 2457–2471 (2025)
2025
-
[12]
Journal of Electrochemical Energy Conversion and Storage22(4), 041012 (2025)
Yang, B., Huang, L., Wei, K., Shu, X., Garg, A., Li, Y.: A novel state of health estimation method for lithium-ion batteries based on incremental capacity curve. Journal of Electrochemical Energy Conversion and Storage22(4), 041012 (2025)
2025
-
[13]
In: Proceedings of the ACM Web Conference 2026
Zheng, Z., Yang, Y., Guan, Z., Zhao, W., Huang, X., Lu, W.: Beyond single- granularity prompts: A multi-scale chain-of-thought prompt learning for graph. In: Proceedings of the ACM Web Conference 2026. pp. 547–558 (2026)
2026
-
[14]
In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2
Zheng, Z., Yang, Y., Guan, Z., Zhao, W., Lu, W.: Discrepancy-aware graph mask auto-encoder. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. pp. 4038–4049 (2025)
2025
-
[15]
In: Pro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2
Zheng, Z., Yang, Y., Guan, Z., Zhao, W., Lu, W.: Enhancing homophily- heterophily separation: Relation-aware learning in heterogeneous graphs. In: Pro- ceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2. pp. 4050–4061 (2025)
2025
-
[16]
Empowering Heterogeneous Graph Foundation Models via Decoupled Relation Alignment
Zheng, Z., Yang, Y., Wang, Z., Guan, Z., Zhao, W.: Empowering heteroge- neous graph foundation models via decoupled relation alignment. arXiv preprint arXiv:2605.00731 (2026), https://arxiv.org/abs/2605.00731
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.