WideDepth: Millimeter-Accurate Benchmark for Fisheye Depth Estimation
Pith reviewed 2026-06-30 15:41 UTC · model grok-4.3
The pith
WideDepth supplies the first indoor fisheye depth benchmark with millimeter-accurate LiDAR labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
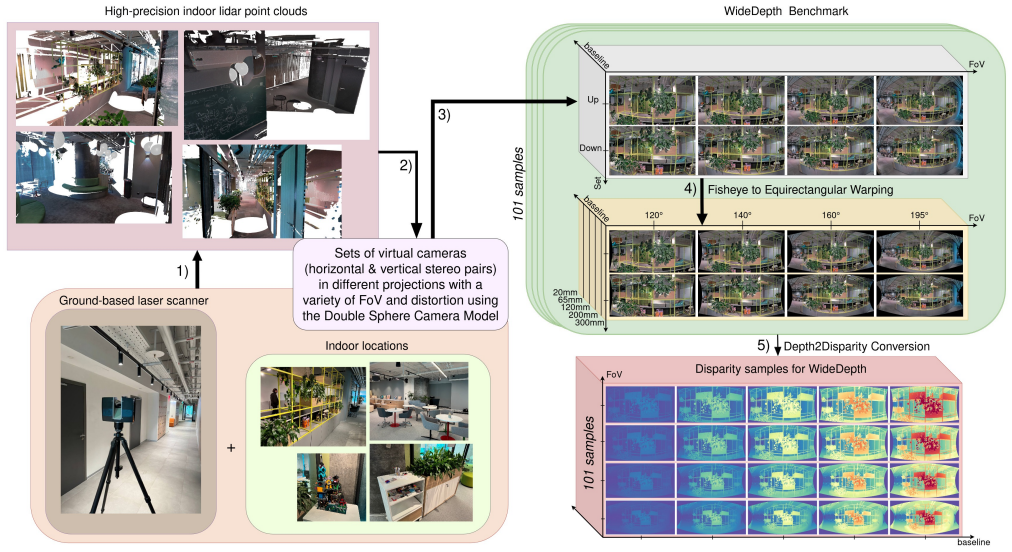
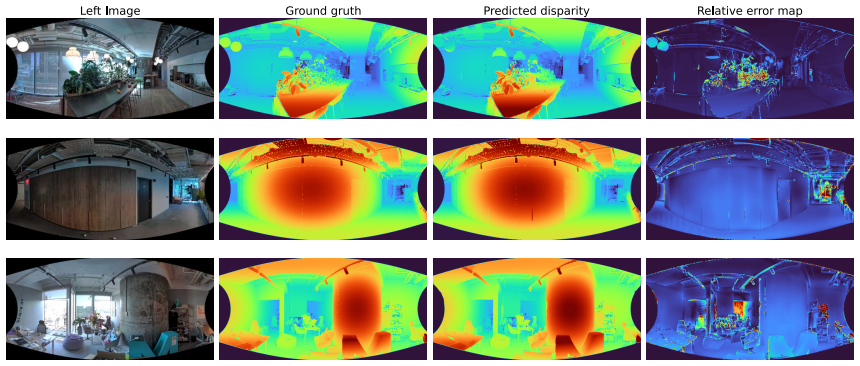
WideDepth is the first indoor dataset for fisheye depth estimation, featuring 101 scenes containing 5K high-resolution stereo pairs labeled with millimeter-level ground truth depth and disparity. The dataset also includes paired pinhole and fisheye samples across varying fields of view and baselines in both horizontal and vertical stereo setups. A method to adapt pinhole-trained stereo models to fisheye images is proposed together with a novel stereo fisheye image generation pipeline based on high-resolution LiDAR scans. State-of-the-art models are evaluated on the benchmark, and 18K LiDAR-derived sparse depth training samples are released that achieve up to a 62 percent performance boost wh
What carries the argument
The WideDepth dataset together with its LiDAR-based stereo fisheye image generation and labeling pipeline that supplies millimeter-accurate ground truth.
If this is right
- State-of-the-art monocular, stereo matching, and depth completion models can be evaluated on fisheye data with precise quantitative metrics.
- Pinhole-trained stereo models can be adapted to fisheye images using the supplied adaptation method and paired samples.
- Fine-tuning pinhole-based models with the 18K LiDAR-derived sparse depth samples yields up to 62 percent performance improvement on fisheye data.
- The benchmark supports research on varying fields of view, baselines, and horizontal versus vertical stereo configurations for indoor robotics.
Where Pith is reading between the lines
- The dataset could support development of fisheye-specific network architectures instead of relying only on adaptation from pinhole models.
- Millimeter accuracy enables testing of depth methods for near-field robotic manipulation tasks where centimeter-scale errors are unacceptable.
- The LiDAR-to-fisheye generation pipeline could be reused to create training data for other wide-angle camera models or outdoor settings.
- Direct comparisons across the dataset's horizontal and vertical stereo setups could identify configurations that minimize distortion effects.
Load-bearing premise
The LiDAR scanning and labeling pipeline produces true millimeter-level accuracy for all fisheye views and stereo configurations without systematic bias from calibration, occlusion, or surface properties.
What would settle it
Independent high-precision measurements on the same scenes that show average depth label errors larger than a few millimeters.
Figures



read the original abstract
Fisheye cameras are increasingly adopted in robotics for near-field manipulation, navigation, and immersive perception, yet indoor depth benchmarks with accurate ground truth are still missing. To address this, we introduce WideDepth - the first indoor dataset for fisheye depth estimation, featuring 101 scenes containing 5K high-resolution stereo pairs labeled with millimeter-level ground truth depth and disparity. Our dataset also includes paired pinhole and fisheye samples across varying fields of view and baselines in both horizontal and vertical stereo setups. We further propose a method to adapt pinhole-trained stereo models to fisheye images and introduce a novel stereo fisheye image generation pipeline based on high-resolution LiDAR scans. Leveraging these methods, we thoroughly evaluate state-of-the-art monocular depth, stereo matching, and depth completion models on our benchmark. Additionally, we provide 18K LiDAR-derived sparse depth training samples, achieving up to a 62% performance boost on fisheye data when fine-tuning pinhole-based stereo models. In summary, the high precision and versatility of our benchmark set a strong foundation for advancing research in fisheye depth estimation and robotics perception. Project page: https://ilyaind.github.io/WideDepth
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WideDepth as the first indoor fisheye depth estimation benchmark, comprising 101 scenes with 5K high-resolution stereo pairs that include millimeter-level ground truth depth and disparity labels generated via a high-resolution LiDAR scanning and projection pipeline. It provides paired pinhole and fisheye imagery across multiple fields of view and stereo baselines, proposes an adaptation method for pinhole-trained stereo models to fisheye data, describes a LiDAR-based stereo fisheye image generation pipeline, evaluates state-of-the-art monocular, stereo, and depth completion models, and supplies 18K sparse depth samples that reportedly yield up to a 62% performance boost when fine-tuning pinhole models on fisheye data.
Significance. If the millimeter-level ground truth accuracy can be independently validated, the dataset would address a clear gap by supplying the first dedicated high-precision indoor benchmark for fisheye depth estimation, directly supporting robotics applications that rely on fisheye cameras for near-field manipulation and navigation.
major comments (2)
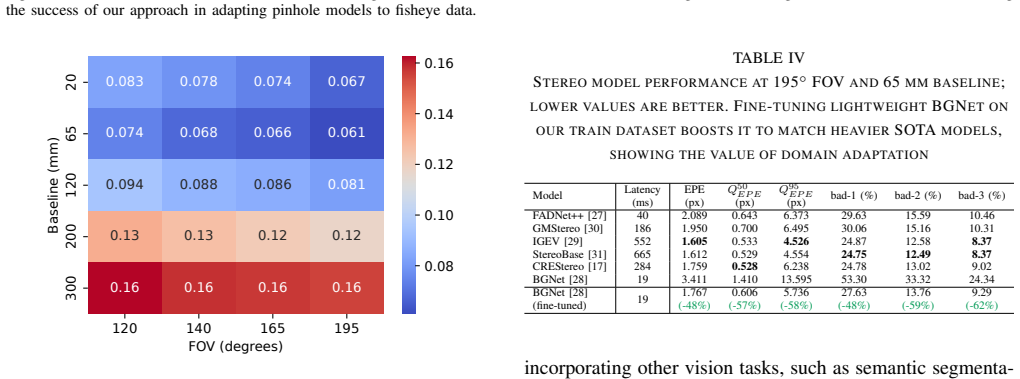
- [Abstract] Abstract: the central claim of 'millimeter-level ground truth depth and disparity' for all fisheye views rests on an unvalidated LiDAR-to-image projection pipeline; no error histograms, calibration target comparisons, or stratified accuracy metrics (by range or angle) are supplied to confirm sub-millimeter extrinsic calibration and distortion model fidelity, which directly undermines the title and dataset utility.
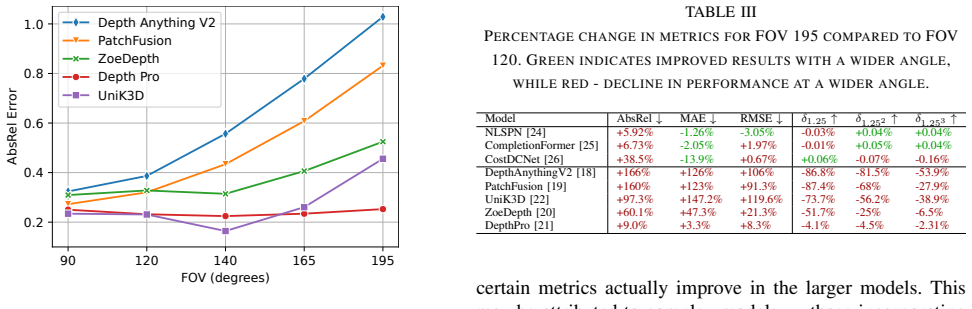
- [Abstract] Abstract: the reported 'up to a 62% performance boost' from fine-tuning with the 18K LiDAR-derived sparse depth samples is presented without baseline values, absolute error metrics, or per-model breakdowns, rendering the quantitative claim impossible to evaluate against the stated evaluation of SOTA models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'millimeter-level ground truth depth and disparity' for all fisheye views rests on an unvalidated LiDAR-to-image projection pipeline; no error histograms, calibration target comparisons, or stratified accuracy metrics (by range or angle) are supplied to confirm sub-millimeter extrinsic calibration and distortion model fidelity, which directly undermines the title and dataset utility.
Authors: We agree that the current manuscript does not supply the requested validation artifacts (error histograms, calibration target comparisons, or stratified metrics) to fully substantiate the millimeter-level claim across fisheye views. The LiDAR projection pipeline is described in Section 3, but explicit quantitative validation of extrinsic calibration and distortion fidelity is missing. We will add these analyses in the revised version, including error distributions, target-based comparisons, and breakdowns by range and angle, to support the title and dataset claims. revision: yes
-
Referee: [Abstract] Abstract: the reported 'up to a 62% performance boost' from fine-tuning with the 18K LiDAR-derived sparse depth samples is presented without baseline values, absolute error metrics, or per-model breakdowns, rendering the quantitative claim impossible to evaluate against the stated evaluation of SOTA models.
Authors: We acknowledge that the abstract presents the 62% figure without accompanying baseline values, absolute metrics, or per-model details, which prevents direct evaluation. This result originates from the fine-tuning experiments in Section 5.3 comparing adapted models to their pinhole baselines on fisheye data. In the revision we will expand both the abstract and the experimental section to report the necessary baselines, absolute errors, and per-model breakdowns so the claim can be assessed alongside the SOTA evaluations. revision: yes
Circularity Check
No circularity; empirical dataset contribution with no derivation chain
full rationale
The paper presents a new fisheye depth dataset generated from LiDAR scans, an adaptation method for stereo models, and empirical evaluations of existing models. No equations, predictions, fitted parameters, or self-citations form a load-bearing derivation that reduces to its own inputs by construction. The millimeter accuracy claim is an assertion about the data collection pipeline rather than a derived result. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard stereo calibration and LiDAR-to-camera registration yield millimeter-accurate depth labels for fisheye images.
Reference graph
Works this paper leans on
-
[1]
Indoor segmen- tation and support inference from RGBD images,
P. K. Nathan Silberman, Derek Hoiem and R. Fergus, “Indoor segmen- tation and support inference from RGBD images,” inECCV, 2012
2012
-
[2]
SUN RGB-D: A RGB-D scene understanding benchmark suite,
S. Song, S. P. Lichtenberg, and J. Xiao, “SUN RGB-D: A RGB-D scene understanding benchmark suite,” in2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 567–576. [Online]. Available: https://api.semanticscholar.org/CorpusID:6242669
2015
-
[3]
Matterport3D: Learning from RGB-D data in indoor environments,
A. X. Chang, A. Dai, T. A. Funkhouser, M. Halber, M. Nießner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3D: Learning from RGB-D data in indoor environments,” in2017 International Conference on 3D Vision (3DV), 2017, pp. 667–676. [Online]. Available: https://api.semanticscholar.org/CorpusID:21435690
2017
-
[4]
IRS: A large naturalistic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation,
Q. Wang, Z. Shizhen, Q. Yan, F. Deng, K. Zhao, and X. Chu, “IRS: A large naturalistic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation,” in2021 IEEE International Conference on Multimedia and Expo (ICME), 2021, pp. 1–6. [Online]. Available: https://api.semanticscholar.org/CorpusID:236273594
2021
-
[5]
High-resolution stereo datasets with subpixel-accurate ground truth,
D. Scharstein, H. Hirschm ¨uller, Y . Kitajima, G. Krathwohl, N. Nesic, X. Wang, and P. Westling, “High-resolution stereo datasets with subpixel-accurate ground truth,” inGerman Conference on Pattern Recognition, 2014. [Online]. Available: https://api.semanticscholar. org/CorpusID:14915763
2014
-
[6]
Open challenges in deep stereo: the booster dataset,
P. Z. Ramirez, F. Tosi, M. Poggi, S. Salti, S. Mattoccia, and L. di Stefano, “Open challenges in deep stereo: the booster dataset,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 21 136–21 146. [Online]. Available: https://api.semanticscholar.org/CorpusID:249538677
2022
-
[7]
SynWoodScape: Synthetic surround-view fisheye camera dataset for autonomous driving,
A. R. Sekkat, Y . Dupuis, V . R. Kumar, H. Rashed, S. K. Yogamani, P. Vasseur, and P. Honeine, “SynWoodScape: Synthetic surround-view fisheye camera dataset for autonomous driving,”IEEE Robotics and Automation Letters, vol. 7, pp. 8502–8509, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:247362954
2022
-
[8]
The OmniScape dataset,
A. R. Sekkat, Y . Dupuis, P. Vasseur, and P. Honeine, “The OmniScape dataset,” in2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 1603–1608. [Online]. Available: https://api.semanticscholar.org/CorpusID:221847109
2020
-
[9]
1 year, 1000 km: The Oxford RobotCar dataset,
W. P. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 year, 1000 km: The Oxford RobotCar dataset,”The International Journal of Robotics Research, vol. 36, pp. 15–3, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:22556995
2017
-
[10]
KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D,
Y . Liao, J. Xie, and A. Geiger, “KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2D and 3D,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, pp. 3292–3310, 2021. [Online]. Available: https://api.semanticscholar. org/CorpusID:238198653
2021
-
[11]
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving,
S. K. Yogamani, C. Hughes, J. Horgan, G. Sistu, P. Varley, D. O’Dea, M. Uˇriˇc´aˇrand Stefan Milz, M. Simon, K. Amende, C. Witt, H. Rashed, S. Chennupati, S. Nayak, S. Mansoor, X. Perroton, and P. P´erez, “WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019...
2019
-
[12]
OmniVidar: omnidirectional depth estimation from multi-fisheye images,
S. Xie, D. Wang, and Y .-H. Liu, “OmniVidar: omnidirectional depth estimation from multi-fisheye images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 529–21 538
2023
-
[13]
MODE: Multi-view omnidirectional depth estimation with 360 ◦ cameras,
M. Li, X. Jin, X. Hu, J. Dai, S. Du, and Y . Li, “MODE: Multi-view omnidirectional depth estimation with 360 ◦ cameras,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 197–213
2022
-
[14]
The double sphere camera model,
V . Usenko, N. Demmel, and D. Cremers, “The double sphere camera model,” in2018 International Conference on 3D Vision (3DV). IEEE, 2018, pp. 552–560
2018
-
[15]
Extending kalibr: Calibrating the extrinsics of multiple IMUs and of individual axes,
J. Rehder, J. Nikolic, T. Schneider, T. Hinzmann, and R. Siegwart, “Extending kalibr: Calibrating the extrinsics of multiple IMUs and of individual axes,” in2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 4304–4311
2016
-
[16]
Helvipad: A real-world dataset for omnidi- rectional stereo depth estimation,
M. Zayene, J. Endres, A. Havolli, C. Corbi `ere, S. Cherkaoui, A. Kon- touli, and A. Alahi, “Helvipad: A real-world dataset for omnidi- rectional stereo depth estimation,”arXiv preprint arXiv:2411.18335, 2024
-
[17]
Practical stereo matching via cascaded recurrent network with adaptive correlation,
J. Li, P. Wang, P. Xiong, T. Cai, Z. Yan, L. Yang, J. Liu, H. Fan, and S. Liu, “Practical stereo matching via cascaded recurrent network with adaptive correlation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 263–16 272
2022
-
[18]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”ArXiv, vol. abs/2406.09414, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270440448
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
PatchFusion: An end-to-end tile-based framework for high-resolution monocular metric depth estimation,
Z. L. et al., “PatchFusion: An end-to-end tile-based framework for high-resolution monocular metric depth estimation,” in CVPR’24, 2024, pp. 10 016–10 025. [Online]. Available: https: //api.semanticscholar.org/CorpusID:265659202
2024
-
[20]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
S. B. et al., “ZoeDepth: Zero-shot transfer by combining relative and metric depth,”ArXiv, vol. abs/2302.12288, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257205739
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun, “Depth Pro: Sharp monocular metric depth in less than a second,” 2024. [Online]. Available: https://arxiv.org/abs/2410.02073
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
UniK3D: Universal camera monocular 3d esti- mation,
L. Piccinelli, C. Sakaridis, M. Segu, Y .-H. Yang, S. Li, W. Abbeloos, and L. Van Gool, “UniK3D: Universal camera monocular 3d esti- mation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[23]
Monocular depth estimation using deep learning: A review,
A. Masoumian, H. A. Rashwan, J. Cristiano, M. S. Asif, and D. Puig, “Monocular depth estimation using deep learning: A review,” Sensors (Basel, Switzerland), vol. 22, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:250718139
2022
-
[24]
Non-local spatial propagation network for depth completion,
J. Park, K. Joo, Z. Hu, C.-K. Liu, and I. S. Kweon, “Non-local spatial propagation network for depth completion,” 2020. [Online]. Available: https://arxiv.org/abs/2007.10042
-
[25]
CompletionFormer: Depth completion with convolutions and vision transformers,
Y . Zhang, X. Guo, M. Poggi, Z. Zhu, G. Huang, and S. Mattoccia, “CompletionFormer: Depth completion with convolutions and vision transformers,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 18 527–18 536. [Online]. Available: https://api.semanticscholar.org/CorpusID:258309598
2023
-
[26]
CostDCNet: Cost volume based depth completion for a single RGB-D image,
J. Kam, S. K. J. Kim, J. Park, and S. Lee, “CostDCNet: Cost volume based depth completion for a single RGB-D image,” in European Conference on Computer Vision, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:253513199
2022
-
[27]
FADNet++: Real-time and accurate disparity estimation with configurable networks,
Q. Wang, S. Shi, S. gang Zheng, K. Zhao, and X. Chu, “FADNet++: Real-time and accurate disparity estimation with configurable networks,”ArXiv, vol. abs/2110.02582, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:238407735
-
[28]
Bilateral grid learning for stereo matching networks,
B. Xu, Y . Xu, X. Yang, W. Jia, and Y . Guo, “Bilateral grid learning for stereo matching networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 1–10
2021
-
[29]
Iterative geometry encod- ing volume for stereo matching,
G. Xu, X. Wang, X. Ding, and X. Yang, “Iterative geometry encod- ing volume for stereo matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21 919–21 928
2023
-
[30]
Unifying flow, stereo and depth estimation,
H. Xu, J. Zhang, J. Cai, H. Rezatofighi, F. Yu, D. Tao, and A. Geiger, “Unifying flow, stereo and depth estimation,” 2023. [Online]. Available: https://arxiv.org/abs/2211.05783
-
[31]
OpenStereo: A comprehensive benchmark for stereo matching and strong baseline,
X. Guo, C. Zhang, J. Lu, Y . Wang, Y . Duan, T. Yang, Z. Zhu, and L. Chen, “OpenStereo: A comprehensive benchmark for stereo matching and strong baseline,” 2024. [Online]. Available: https://arxiv.org/abs/2312.00343
-
[32]
A survey on deep stereo matching in the twenties,
F. Tosi, L. Bartolomei, and M. Poggi, “A survey on deep stereo matching in the twenties,”International Journal of Computer Vision, vol. 133, pp. 4245–4276, 2025, appendix C defines EPE, RMSE, bad-τ, and KITTI D1 outlier metrics. [Online]. Available: https://link.springer.com/article/10.1007/s11263-024-02331-0
-
[33]
AdaBelief optimizer: Adapting stepsizes by the belief in observed gradients,
J. Zhuang, T. M. Tang, Y . Ding, S. C. Tatikonda, N. C. Dvornek, X. Papademetris, and J. S. Duncan, “AdaBelief optimizer: Adapting stepsizes by the belief in observed gradients,”ArXiv, vol. abs/2010.07468, 2020. [Online]. Available: https://api.semanticscholar. org/CorpusID:222377595
-
[34]
Super-convergence: very fast training of neural networks using large learning rates,
L. N. Smith and N. Topin, “Super-convergence: very fast training of neural networks using large learning rates,” inDefense + Commercial Sensing, 2018. [Online]. Available: https://api.semanticscholar.org/ CorpusID:260552651
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.