MASt3R-Nav: WayPixel Navigation in Relative 3D Maps
Pith reviewed 2026-06-30 16:10 UTC · model grok-4.3
The pith
Pixel-relative connectivity from 3D image matching yields a dense costmap that conditions more accurate navigation control than image- or object-level maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
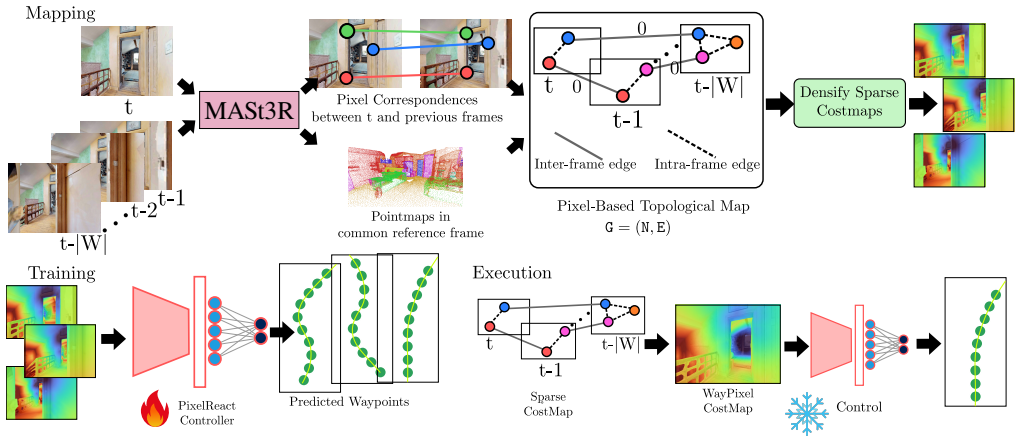
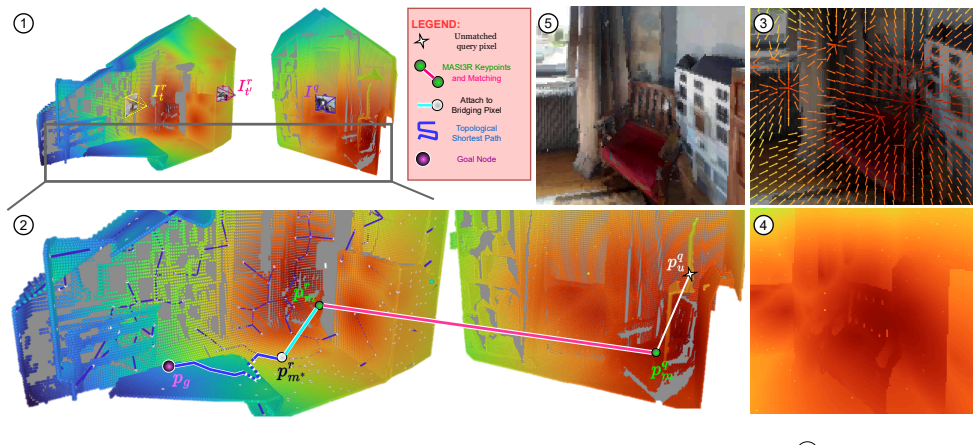
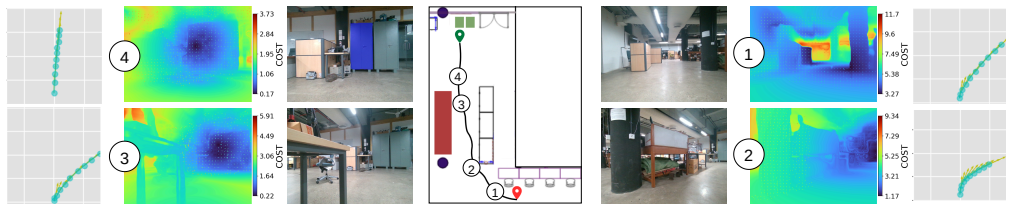
The central claim is that a map built solely from inter-image pixel correspondences in relative 3D coordinate systems supports global path planning and high-performance control. By approximating intra-image pixel connectivity and deriving the WayPixel Costmap, the representation preserves dense geometric cues locally while avoiding any requirement for a single consistent 3D reconstruction, resulting in measurably more accurate trajectory predictions than image- or object-level alternatives.
What carries the argument
The WayPixel Costmap, obtained by sparsifying the pixel-relative connectivity graph constructed from 3D-grounded image matching on image sequences.
If this is right
- Global path planning remains possible by sparsifying the intra-image portion of the pixel connectivity graph.
- A controller trained on the dense pixel costmap produces more accurate trajectory rollouts than one trained on image- or object-level maps.
- The same representation supports four distinct navigation task types in simulation and transfers to real-world robot demonstrations.
- Navigation capability exceeds teach-and-repeat limits while still avoiding the need for globally consistent geometry.
Where Pith is reading between the lines
- The method could enable incremental map building in large or changing environments where drift prevents global consistency.
- Failure modes would concentrate on image pairs where matching produces unreliable correspondences rather than on global alignment errors.
- Combining the costmap with online matching updates might allow reactive replanning without rebuilding an entire map.
Load-bearing premise
Reliable pixel correspondences can be extracted from 3D-grounded image matching applied to the input image sequences.
What would settle it
An ablation that replaces the pixel-level costmap with an image-level or object-level map on the same four navigation tasks and measures the resulting drop in success rate or increase in trajectory error.
Figures


read the original abstract
Visual navigation ability is strongly tied to its underlying representation of the world. Unlike classical 3D maps that require globally-consistent geometry, image- or object-relative topological graphs almost entirely do away with geometric understanding. But, this comes at the cost of navigation capability, often limiting it to merely teach-and-repeat. In this work, we propose a novel map representation in the form of pixel-relative connectivity, which is geometrically accurate but does not require global geometric consistency. Inspired by recent progress in 3D grounded image matching, we construct a map from an image sequence through inter-image connectivity based on pixel correspondences in the relative 3D coordinate systems of individual image pairs. We then use this pixel-level graph to perform global path planning by approximating and sparsifying intra-image pixel connectivity. Through this, we derive a ''WayPixel Costmap'' representation and train a controller conditioned on it to predict a trajectory rollout. We show that this dense pixel-level costmap based on relative geometry is a more accurate conditioning variable for control prediction than its image- and object-level counterparts. This enables a highly capable navigation system, as validated on four types of navigation tasks in the simulator and through real world demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MASt3R-Nav for visual navigation using a novel pixel-relative connectivity map derived from pairwise 3D correspondences obtained via MASt3R image matching on image sequences. The method constructs an inter-image graph in relative 3D coordinates, approximates and sparsifies intra-image pixel connectivity to form a WayPixel Costmap, and trains a controller to predict trajectory rollouts conditioned on this costmap. The central claim is that this dense pixel-level costmap based on relative geometry provides a more accurate conditioning signal for control than image- or object-level alternatives, enabling capable performance on four simulator navigation tasks and real-world demonstrations without requiring globally consistent 3D geometry.
Significance. If the superiority claim holds under the stated assumptions, the work offers a useful intermediate representation between globally consistent metric maps and purely topological graphs, potentially improving navigation robustness in environments where full SLAM is impractical. The grounding in recent 3D image matching and the multi-task validation are positive elements; the approach could influence downstream work on relative-geometry navigation if the error-propagation issues are addressed.
major comments (3)
- [Abstract / Method (pixel-relative connectivity)] Abstract and method description: the superiority of the pixel-level WayPixel Costmap over image- and object-level baselines is the load-bearing claim, yet the construction relies exclusively on pairwise MASt3R correspondences without transitivity enforcement or drift correction across the sequence. Local matching failures (common under varying texture, lighting, or motion in the four tasks) propagate directly into the sparsified costmap used for global planning, which directly risks the accuracy advantage asserted.
- [Experiments] Experiments section: the validation on four simulator tasks and real-world demos is cited to support the 'highly capable' claim, but no quantitative comparison (e.g., success rate deltas, trajectory error, or conditioning accuracy metrics) versus the image- and object-level baselines is referenced; without these, the central empirical assertion cannot be evaluated.
- [Method] Method (approximating and sparsifying intra-image pixel connectivity): the step that converts the pixel graph into the costmap for control prediction is described at a high level only; any approximation that discards geometric fidelity would undermine the 'dense pixel-level' advantage, yet no error bounds or sensitivity analysis is indicated.
minor comments (2)
- [Abstract] Abstract: the phrase 'highly capable navigation system' is qualitative; replace or qualify with reference to specific performance numbers once the experiments section is expanded.
- Notation: 'WayPixel Costmap' is introduced without an explicit definition or equation; add a short formal description or diagram reference for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below. Where the comments identify gaps in analysis or presentation, we agree that revisions are warranted and will incorporate them.
read point-by-point responses
-
Referee: [Abstract / Method (pixel-relative connectivity)] Abstract and method description: the superiority of the pixel-level WayPixel Costmap over image- and object-level baselines is the load-bearing claim, yet the construction relies exclusively on pairwise MASt3R correspondences without transitivity enforcement or drift correction across the sequence. Local matching failures (common under varying texture, lighting, or motion in the four tasks) propagate directly into the sparsified costmap used for global planning, which directly risks the accuracy advantage asserted.
Authors: The use of purely pairwise MASt3R correspondences without transitivity or global drift correction is an intentional design choice that enables navigation without requiring globally consistent 3D geometry, which is a central contribution. We acknowledge that local matching failures can propagate and that this could affect the asserted accuracy advantage over baselines. In the revision we will add a dedicated discussion subsection analyzing error propagation through the pipeline and the role of the sparsification step in limiting its impact. revision: yes
-
Referee: [Experiments] Experiments section: the validation on four simulator tasks and real-world demos is cited to support the 'highly capable' claim, but no quantitative comparison (e.g., success rate deltas, trajectory error, or conditioning accuracy metrics) versus the image- and object-level baselines is referenced; without these, the central empirical assertion cannot be evaluated.
Authors: The experiments section reports success rates and trajectory metrics for MASt3R-Nav on the four tasks and real-world demonstrations. Direct quantitative comparisons (including deltas) against the image- and object-level baselines are not presented in tabular form with the requested metrics. We will revise the experiments section to include an explicit comparison table reporting success-rate deltas, trajectory error, and conditioning accuracy versus the baselines. revision: yes
-
Referee: [Method] Method (approximating and sparsifying intra-image pixel connectivity): the step that converts the pixel graph into the costmap for control prediction is described at a high level only; any approximation that discards geometric fidelity would undermine the 'dense pixel-level' advantage, yet no error bounds or sensitivity analysis is indicated.
Authors: The approximation and sparsification procedure is outlined in Section 3.4 via a connectivity-strength sampling rule. We agree that the current description is high-level and that the absence of error bounds or sensitivity analysis weakens the claim of preserving dense pixel-level fidelity. In the revision we will expand the method section with a more detailed algorithmic description, provide approximate error bounds derived from the sampling density, and add a sensitivity analysis on the sparsification threshold. revision: yes
Circularity Check
No circularity: empirical validation of costmap superiority is independent of construction
full rationale
The derivation proceeds by constructing a pixel-relative connectivity graph from MASt3R pairwise matches, sparsifying it into a WayPixel Costmap, and training a controller on that representation. Superiority over image/object baselines is shown via direct experimental comparison on four navigation tasks plus real-world demos. No equation or claim reduces the output to a fitted input by construction, no self-citation is load-bearing for the central result, and the graph construction step is presented as an engineering choice rather than a uniqueness theorem. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using occupancy grids for mobile robot perception and navigation,
A. Elfes, “Using occupancy grids for mobile robot perception and navigation,”Computer, vol. 22, no. 6, pp. 46–57, 1989
1989
-
[2]
Semi-parametric Topological Memory for Navigation
N. Savinov, A. Dosovitskiy, and V . Koltun, “Semi-parametric topolog- ical memory for navigation,”arXiv preprint arXiv:1803.00653, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Gnm: A general navigation model to drive any robot,
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine, “Gnm: A general navigation model to drive any robot,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 7226–7233
2023
-
[4]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 608–10 615
2023
-
[5]
Robohop: Segment-based topological map representation for open-world visual navigation,
S. Garg, K. Rana, M. Hosseinzadeh, L. Mares, N. S ¨underhauf, F. Dayoub, and I. Reid, “Robohop: Segment-based topological map representation for open-world visual navigation,” in2024 IEEE In- ternational Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 4090–4097
2024
-
[6]
Objectreact: Learning object-relative control for visual navigation,
S. Garg, D. Craggs, V . Bhat, L. Mares, S. Podgorski, M. Krishna, F. Dayoub, and I. Reid, “Objectreact: Learning object-relative control for visual navigation,” inConference on Robot Learning. PMLR, 2025
2025
-
[7]
Tango: Traversablility-aware navigation with local metric control for topological goals,
S. Podgorski, S. Garg, M. Hosseinzadeh, L. Mares, F. Dayoub, and I. Reid, “Tango: Traversablility-aware navigation with local metric control for topological goals,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025
2025
-
[8]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 697–20 709
2024
-
[9]
Grounding image matching in 3d with mast3r,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 71–91
2024
-
[10]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[11]
Lsd-slam: Large-scale di- rect monocular slam,
J. Engel, T. Sch ¨ops, and D. Cremers, “Lsd-slam: Large-scale di- rect monocular slam,” inEuropean conference on computer vision. Springer, 2014, pp. 834–849
2014
-
[12]
Parallel tracking and mapping for small ar workspaces,
G. Klein and D. Murray, “Parallel tracking and mapping for small ar workspaces,” in2007 6th IEEE and ACM international symposium on mixed and augmented reality. IEEE, 2007, pp. 225–234
2007
-
[13]
Slam++: Simultaneous localisation and mapping at the level of objects,
R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat, P. H. Kelly, and A. J. Davison, “Slam++: Simultaneous localisation and mapping at the level of objects,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 1352–1359
2013
-
[14]
Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam,
L. Nicholson, M. Milford, and N. S ¨underhauf, “Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam,” IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 1–8, 2018
2018
-
[15]
Kimera: From slam to spatial perception with 3d dynamic scene graphs,
A. Rosinol, A. Violette, M. Abate, N. Hughes, Y . Chang, J. Shi, A. Gupta, and L. Carlone, “Kimera: From slam to spatial perception with 3d dynamic scene graphs,”The International Journal of Robotics Research, vol. 40, no. 12-14, pp. 1510–1546, 2021
2021
-
[16]
3d scene graph: A structure for unified semantics, 3d space, and camera,
I. Armeni, Z.-Y . He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese, “3d scene graph: A structure for unified semantics, 3d space, and camera,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5664–5673
2019
-
[17]
Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks,
Z. Ravichandran, L. Peng, N. Hughes, J. D. Griffith, and L. Carlone, “Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 9272–9279
2022
-
[18]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
2024
-
[19]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294–5306
2025
-
[20]
Mast3r-slam: Real- time dense slam with 3d reconstruction priors,
R. Murai, E. Dexheimer, and A. J. Davison, “Mast3r-slam: Real- time dense slam with 3d reconstruction priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 695–16 705
2025
-
[21]
Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion,
B. P. Duisterhof, L. Zust, P. Weinzaepfel, V . Leroy, Y . Cabon, and J. Revaud, “Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion,” in2025 International Conference on 3D Vi- sion (3DV). IEEE, 2025, pp. 1–10
2025
-
[22]
ViKiNG: Vision-Based Kilometer-Scale Nav- igation with Geographic Hints,
D. Shah and S. Levine, “ViKiNG: Vision-Based Kilometer-Scale Nav- igation with Geographic Hints,” inProceedings of Robotics: Science and Systems, 2022
2022
-
[23]
LM-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osinski, B. Ichter, and S. Levine, “LM-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in6th Annual Conference on Robot Learning, 2022
2022
-
[24]
Learning view and target invariant visual servoing for navigation,
Y . Li and J. Ko ˇsecka, “Learning view and target invariant visual servoing for navigation,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 658–664
2020
-
[25]
Scaling local control to large-scale topological navigation,
X. Meng, N. Ratliff, Y . Xiang, and D. Fox, “Scaling local control to large-scale topological navigation,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 672–678
2020
-
[26]
Zero-shot visual imitation,
D. Pathak, P. Mahmoudieh, G. Luo, P. Agrawal, D. Chen, Y . Shentu, E. Shelhamer, J. Malik, A. A. Efros, and T. Darrell, “Zero-shot visual imitation,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 2050–2053
2018
-
[27]
A tutorial on visual servo control,
“A tutorial on visual servo control,”IEEE transactions on robotics and automation, vol. 12, no. 5, pp. 651–670, 2002
2002
-
[28]
Path planning for robust image-based control,
Y . Mezouar and F. Chaumette, “Path planning for robust image-based control,”IEEE transactions on robotics and automation, vol. 18, no. 4, pp. 534–549, 2002
2002
-
[29]
Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill,
W. Cai, S. Huang, G. Cheng, Y . Long, P. Gao, C. Sun, and H. Dong, “Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5228–5234
2024
-
[30]
Self-attention with relative position representations,
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 2018, pp. 464–468
2018
-
[31]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[32]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva,et al., “On evaluation of embodied navigation agents,”arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Integrating egocentric localization for more realistic point-goal navi- gation agents,
S. Datta, O. Maksymets, J. Hoffman, S. Lee, D. Batra, and D. Parikh, “Integrating egocentric localization for more realistic point-goal navi- gation agents,” inConference on Robot Learning. PMLR, 2021, pp. 313–328
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.