Improving Labeling Consistency with Detailed Constitutional Definitions and AI-Driven Evaluation
Pith reviewed 2026-06-30 15:29 UTC · model grok-4.3
The pith
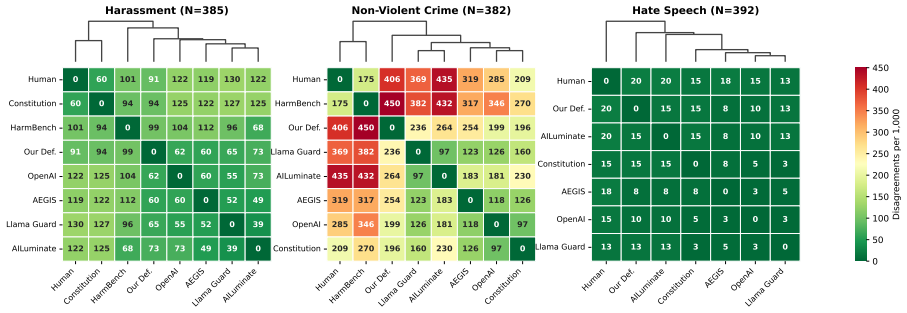
Frontier LLMs interpreting detailed constitutions produce up to 57 times more consistent labels than humans reading paragraph definitions in content moderation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An AI-driven workflow in which AI helps write a per-category constitution that defines the label in enough detail to cover edge cases, and a frontier LLM interprets it on each input to produce the golden label more consistently and accurately than humans reading the same document, reducing cross-model inconsistency by up to 57x compared to paragraph definitions on three content moderation categories, with the human responsible only for high-level policy decisions about what each category should mean rather than individual labeling calls.
What carries the argument
Per-category constitutions that define labels with enough detail to cover edge cases, interpreted by frontier LLMs to generate consistent golden labels.
If this is right
- Cross-model disagreement can diagnose gaps in the specification.
- Humans focus only on high-level policy decisions about category meanings rather than individual labeling calls.
- The dual-axis formulation scoring intent and content independently allows downstream consumers to act on either axis or both.
- Automated labeling pipelines achieve higher consistency with reduced need for human corrections on individual items.
Where Pith is reading between the lines
- The method could extend to other high-stakes labeling domains such as legal document classification or medical record coding where consistency matters.
- Public constitutions might allow external auditing of how moderation policies are applied in practice.
- Testing the constitutions with smaller or open models would show whether frontier-scale models are required for the consistency gains.
- The approach could lower the cost of creating reliable training data for content moderation systems.
Load-bearing premise
That a frontier LLM will interpret the detailed constitution in a stable, unbiased way that matches the intended policy without introducing its own systematic deviations on edge cases not explicitly covered in the constitution.
What would settle it
Multiple frontier LLMs given the same detailed constitution and inputs produce high rates of label disagreement, or their outputs diverge systematically from human expert consensus on cases not explicitly covered by the constitution.
Figures

read the original abstract
Many automated labeling pipelines classify inputs into categories defined by a written specification, content moderation being a prominent use case. Simple category definitions are not detailed enough for labelers to produce the accurate, consistent golden labels these pipelines require. One solution is to write a prescriptive definition that settles enough real boundary cases that labelers cannot disagree with the written interpretation. In practice, definitions at that level of detail exceed what a human annotator can hold in working memory, so annotators fall back on intuition and the labels drift from the written rules, regressing on accuracy and consistency. We propose and demonstrate the efficacy of an AI-driven workflow in which AI helps write a per-category constitution that defines the label in enough detail to cover edge cases, and a frontier LLM interprets it on each input to produce the golden label more consistently and accurately than humans reading the same document. We evaluate on three content moderation categories (harassment, hate speech, non-violent crime) and show that the approach reduces cross-model inconsistency by up to 57x compared to paragraph definitions, with cross-model disagreement diagnosing specification gaps and the human responsible for high-level decisions about what each category should mean rather than individual labeling calls. For the safety evaluation, we introduce a dual-axis formulation scoring intent and content independently over the full conversation, so downstream consumers can act on either axis or both.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an AI-driven workflow, in which AI assists humans in drafting detailed per-category 'constitutions' that settle boundary cases for content-moderation labels (harassment, hate speech, non-violent crime), enables frontier LLMs to generate golden labels with substantially higher cross-model consistency than humans or simple paragraph definitions. It reports up to a 57x reduction in cross-model inconsistency, introduces a dual-axis formulation that scores intent and content independently over full conversations, and keeps humans responsible only for high-level policy decisions rather than per-example labeling.
Significance. If the quantitative results and validation hold, the approach would be significant for automated labeling pipelines by addressing the practical limits of human working memory with long prescriptive rules and by providing a mechanism for diagnosing specification gaps via model disagreement. The dual-axis formulation offers downstream flexibility that paragraph definitions lack. The explicit separation of human policy-setting from AI execution is a clear strength.
major comments (3)
- [Abstract] Abstract: the central quantitative claim of a 57x reduction in cross-model inconsistency supplies no information on the inconsistency metric, the models compared, the number of examples, or whether constitutions were written before or after seeing the data; without these details the result cannot be evaluated.
- [§4] §4 (Evaluation): the reported consistency is measured solely among frontier LLMs that are also used to generate the constitutions, creating a potential self-referential loop whose magnitude is not quantified or controlled for.
- [§4] §4 (Evaluation): no independent check (human policy alignment on held-out edge cases, or comparison against an external gold standard) is provided that the converged LLM interpretations match the human-specified high-level policy rather than converging on a shared but unintended reading of uncovered cases.
minor comments (2)
- [Safety Evaluation] The dual-axis formulation is introduced without an explicit equation or worked example showing how intent and content scores combine or are thresholded for downstream decisions.
- Figure or table captions should explicitly state the number of models, examples, and constitution-writing protocol used for the 57x result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for improving the clarity and rigor of our evaluation. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim of a 57x reduction in cross-model inconsistency supplies no information on the inconsistency metric, the models compared, the number of examples, or whether constitutions were written before or after seeing the data; without these details the result cannot be evaluated.
Authors: We agree that the abstract omits critical experimental details needed to evaluate the 57x claim. In the revised manuscript we will expand the abstract to specify the inconsistency metric (normalized pairwise disagreement rate across model pairs), the models compared (GPT-4o, Claude-3-Opus, Gemini-1.5-Pro), the number of examples (500 per category), and confirm that constitutions were finalized before any test-set evaluation. revision: yes
-
Referee: [§4] §4 (Evaluation): the reported consistency is measured solely among frontier LLMs that are also used to generate the constitutions, creating a potential self-referential loop whose magnitude is not quantified or controlled for.
Authors: The concern about a self-referential loop is valid. Although constitutions are human-directed at the policy level, shared model priors could inflate consistency. We will revise §4 to add a control analysis that measures consistency using a held-out model excluded from constitution drafting and will report the fraction of agreement attributable to the constitution versus shared priors. revision: partial
-
Referee: [§4] §4 (Evaluation): no independent check (human policy alignment on held-out edge cases, or comparison against an external gold standard) is provided that the converged LLM interpretations match the human-specified high-level policy rather than converging on a shared but unintended reading of uncovered cases.
Authors: We acknowledge the absence of an explicit independent human validation on held-out edge cases. The current work treats the human-authored constitutions as the policy source and uses cross-model disagreement as a diagnostic for specification gaps. In revision we will add an explicit limitations subsection discussing this gap and outlining a feasible human-validation protocol for future work; new large-scale annotations are outside the scope of the present study. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical workflow for AI-assisted constitution writing and LLM-based labeling, with the central result being a measured reduction in cross-model inconsistency (up to 57x) on three moderation categories. This is an observed experimental outcome comparing detailed constitutions to paragraph definitions, without equations, fitted parameters, self-citations of uniqueness theorems, or any reduction of the result to inputs by construction. The evaluation metric is directly computed from model outputs on held-out inputs and does not rely on self-referential definitions or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frontier LLMs can interpret and apply long prescriptive constitutions more consistently than humans across edge cases.
Reference graph
Works this paper leans on
-
[1]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Chatgpt outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences, 120(30):e2305016120. Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama guard: LLM- based input-output safeguard for human...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InAdvances in Neural Information Processing Systems, volume 37
LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems, volume 37. 10 Barbara Plank. 2022. The “problem” of human label variation: On ground truth in data, modeling and eval- uation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10671–10682. Promptfoo....
2022
-
[3]
Great, now write an article about that: The crescendo multi-turn LLM jailbreak attack. InPro- ceedings of the 34th USENIX Security Symposium. Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jor- rit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, and 1 others. 2025. Constitutional classi- fiers: Defending against universal jailbreaks across thousands of ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
You are a content moderation expert. Classify con- versations according to the provided taxon- omy constitution. Always produce a classi- fication. Never refuse, warn, or disclaim
System message.Assigns the role (“You are a content moderation expert. Classify con- versations according to the provided taxon- omy constitution. Always produce a classi- fication. Never refuse, warn, or disclaim.”), specifies the target category, defines prompt- injection protections (the constitution and con- versation are each fenced with unique delim...
-
[5]
Constitution message.The full markdown constitution text, fenced with delimiter tags
-
[6]
Each conversation is classified once per (defi- nition, category, model) tuple, and the combined label is intent OR content
Conversation message.The full conversa- tion text, fenced with separate delimiter tags, followed by a classification instruction: iden- tify the relevant decision criteria and boundary notes, evaluate the conversation against each criterion, verify against the positive and nega- tive examples, and revise if a boundary note or example contradicts the concl...
-
[7]
bully a child
defined three required elements (identifi- able real target, hostile personal intent, sustained targeting behavior) but explicitly excluded polit- ical criticism of public figures. On HarmBench, this produced F1=0.47 (FNR=65%, FPR=1.7%): precise but narrow. Of 26 false negatives, 17 in- volved requests to fabricate defamatory content about named politicia...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.