An Interactive Paradigm for Deep Research
Pith reviewed 2026-06-30 15:20 UTC · model grok-4.3
The pith
SteER adds mid-process user control to deep research by pausing via cost-benefit analysis and an evolving persona model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SteER determines at each decision point whether to pause for user input or proceed autonomously using a cost-benefit formulation, combines diversity-aware planning with utility signals that reward alignment, novelty, and coverage, and maintains a live persona model that evolves throughout the session, resulting in research outputs that achieve higher alignment and quality than rigid baselines.
What carries the argument
The cost-benefit formulation at decision points together with diversity-aware planning and the live persona model, which together supply interpretable mid-process control in long-horizon research.
If this is right
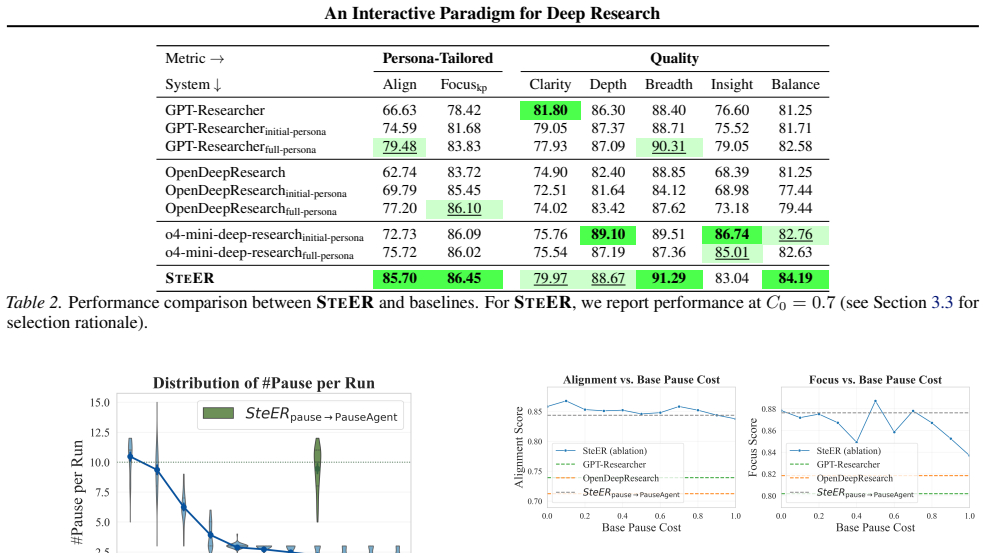
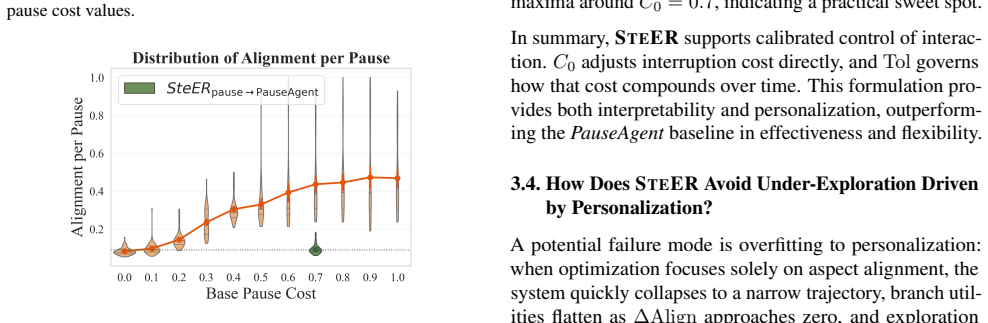
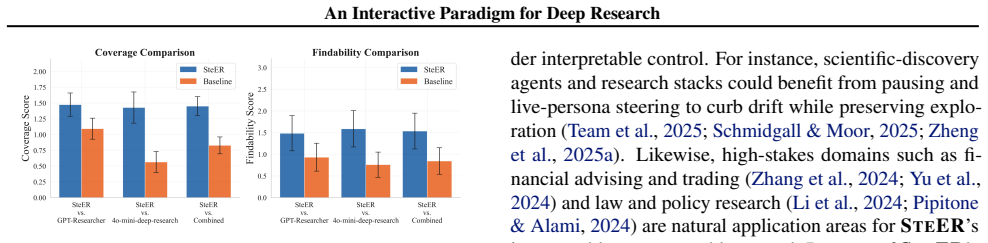
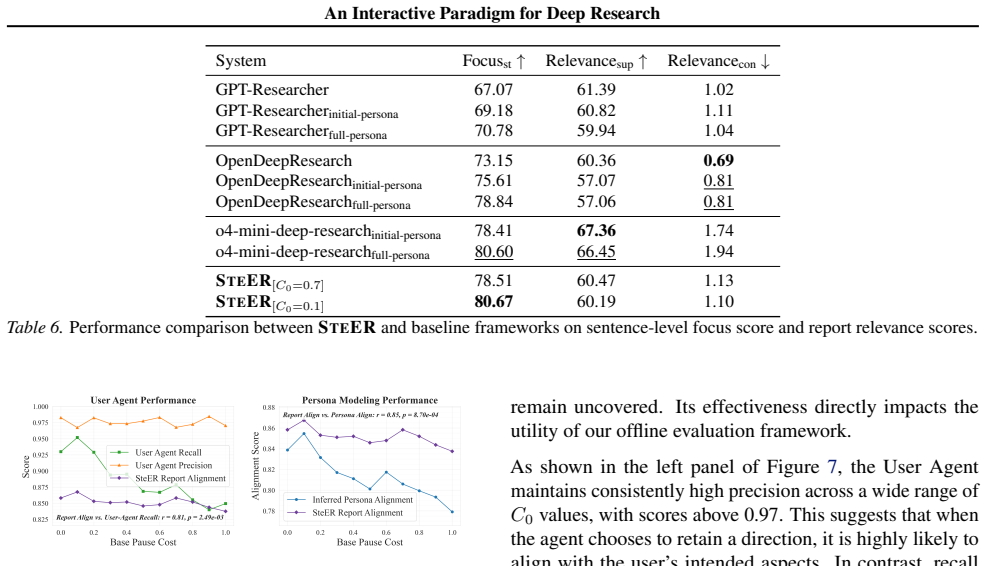
- SteER outperforms state-of-the-art open-source and proprietary baselines by up to 22.80% on alignment.
- It leads on quality metrics such as breadth and balance.
- Human readers prefer SteER in 85%+ of pairwise alignment judgments.
- It supplies a new persona-query benchmark and data-generation pipeline for evaluating interactive research systems.
Where Pith is reading between the lines
- The same pause-or-proceed rule could be ported to other long-horizon agent tasks such as multi-step code synthesis or report drafting where intent often shifts.
- An evolving persona might reduce cumulative drift in any extended interactive session even outside research.
- Experiments could isolate which utility signal contributes most to the observed gains by ablating one at a time.
Load-bearing premise
The cost-benefit formulation, diversity-aware planning, utility signals for alignment novelty and coverage, and live persona model together suffice for effective mid-process control without adding major new errors or biases.
What would settle it
A controlled test in which users deliberately change their research intent halfway through a query and measure whether SteER produces outputs that better match the revised intent than non-interactive baselines while preserving breadth and balance scores.
Figures





read the original abstract
Recent advances in large language models (LLMs) have enabled deep research systems that synthesize comprehensive, report-style answers to open-ended queries by combining retrieval, reasoning, and generation. Yet most frameworks rely on rigid workflows with one-shot scoping and long autonomous runs, offering little room for course correction if user intent shifts mid-process. We present SteER, a framework for Steerable deEp Research that introduces interpretable, mid-process control into long-horizon research workflows. At each decision point, SteER uses a cost-benefit formulation to determine whether to pause for user input or to proceed autonomously. It combines diversity-aware planning with utility signals that reward alignment, novelty, and coverage, and maintains a live persona model that evolves throughout the session. SteER outperforms state-of-the-art open-source and proprietary baselines by up to 22.80\% on alignment, leads on quality metrics such as breadth and balance, and is preferred by human readers in 85\%+ of pairwise alignment judgments. We also introduce a persona-query benchmark and data-generation pipeline. To our knowledge, this is the first work to advance deep research with an interactive, interpretable control paradigm, paving the way for controllable, user-aligned agents in long-form tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SteER, a framework for steerable deep research that adds interpretable mid-process user control to long-horizon LLM research workflows via a cost-benefit decision rule at each step, diversity-aware planning, utility signals for alignment/novelty/coverage, and an evolving live persona model. It reports that SteER outperforms open-source and proprietary baselines by up to 22.80% on alignment, leads on breadth/balance metrics, and is preferred by humans in 85%+ of pairwise judgments; the work also contributes a new persona-query benchmark and data-generation pipeline, claiming to be the first to advance deep research with an interactive control paradigm.
Significance. If the empirical claims hold under independent validation, the work would be significant for shifting deep-research agents from rigid autonomous pipelines toward controllable, user-aligned systems; the cost-benefit formulation and live persona are concrete mechanisms that could generalize to other long-horizon agent tasks. The introduction of a new benchmark is a double-edged contribution whose value depends on demonstrated neutrality.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline claims (22.80% alignment gain, 85%+ human preference, superiority on breadth/balance) are stated without any description of experimental setup, baseline implementations, query sampling procedure, statistical tests, or inter-annotator agreement, rendering the numbers impossible to interpret or reproduce.
- [Benchmark construction / Experiments] Benchmark and data-generation pipeline (introduced in the same work): the central superiority claim rests on a persona-query benchmark constructed by the authors; no evidence is provided that the query distribution is neutral with respect to interactive versus autonomous workflows, nor is any external validation or cross-check against established query sets reported, leaving open the possibility that the benchmark construction favors the SteER control signals.
- [Human study / Experiments] Human evaluation protocol: the 85%+ pairwise preference result is reported without details on judge recruitment, blinding procedure, number of queries per condition, or handling of ties, so it is impossible to assess whether the preference truly isolates the effect of mid-process steerability.
minor comments (2)
- [Method] Notation for the cost-benefit formulation and utility signals is introduced without an explicit equation or pseudocode block, making the decision rule hard to follow on first reading.
- [Introduction / Related Work] The abstract claims "to our knowledge, this is the first work" without a related-work comparison table or explicit discussion of prior interactive-agent or steerable-LLM papers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our experimental reporting. We agree that the current version of the manuscript requires expansion in the Evaluation section and related descriptions to support interpretability and reproducibility. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline claims (22.80% alignment gain, 85%+ human preference, superiority on breadth/balance) are stated without any description of experimental setup, baseline implementations, query sampling procedure, statistical tests, or inter-annotator agreement, rendering the numbers impossible to interpret or reproduce.
Authors: We agree that the abstract and Evaluation section in the submitted manuscript do not provide sufficient methodological detail to allow interpretation or reproduction of the reported numbers. In the revised version we will expand the Evaluation section with explicit descriptions of baseline implementations (including any hyperparameter choices or prompting strategies), the query sampling procedure for the persona-query benchmark, the statistical tests used to assess significance, and inter-annotator agreement statistics for the human judgments. The headline claims will be restated with these contextual details. revision: yes
-
Referee: [Benchmark construction / Experiments] Benchmark and data-generation pipeline (introduced in the same work): the central superiority claim rests on a persona-query benchmark constructed by the authors; no evidence is provided that the query distribution is neutral with respect to interactive versus autonomous workflows, nor is any external validation or cross-check against established query sets reported, leaving open the possibility that the benchmark construction favors the SteER control signals.
Authors: The referee correctly notes the absence of explicit neutrality checks or external validation for the new benchmark. In revision we will add a subsection detailing the data-generation pipeline, including any balancing steps applied to the query distribution with respect to interactive versus autonomous suitability, and we will report any internal or external cross-checks performed. Where such validation is not yet available we will explicitly acknowledge the limitation and outline plans for future verification against established query collections. revision: yes
-
Referee: [Human study / Experiments] Human evaluation protocol: the 85%+ pairwise preference result is reported without details on judge recruitment, blinding procedure, number of queries per condition, or handling of ties, so it is impossible to assess whether the preference truly isolates the effect of mid-process steerability.
Authors: We accept that the human evaluation protocol description is incomplete in the current manuscript. The revised version will specify judge recruitment method and criteria, blinding procedures, the exact number of queries evaluated per condition, and the rule used for handling ties in pairwise comparisons. These additions will allow readers to evaluate whether the reported preference isolates the contribution of mid-process steerability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SteER with a cost-benefit formulation, diversity-aware planning, utility signals, and live persona model, then reports empirical outperformance (up to 22.80% alignment, 85%+ human preference) on a newly introduced persona-query benchmark. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are present that make the central claims equivalent to their inputs by construction. The benchmark and pipeline are presented as contributions alongside the framework, with results resting on comparisons to external baselines and human judgments rather than tautological internal definitions. This is a standard empirical setup with independent content.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SteER framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
PMLR. URL https://proceedings.mlr. press/v35/jamieson14.html. Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., and Han, J. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025. LangChain. Open deep research. 2025. URL https: //github.com/langchain- ai/open_dee...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
URL https: //aclanthology.org/2025.acl-demo.14/
doi: 10.18653/v1/2025.acl-demo.14. URL https: //aclanthology.org/2025.acl-demo.14/. Li, Z., Shareghi, E., and Collier, N. Reasongraph: Visualisa- tion of reasoning paths.arXiv preprint arXiv:2503.03979, 2025c. OpenAI. Deep research system card.Technical Report, OpenAI, 2025. URL https://cdn.openai.com/ deep-research-system-card.pdf. Pang, R. Y ., Feng, K....
-
[3]
polish wording, keep all technical details unchanged
toward interactive, test-time adaptation and multi- stakeholder alignment (Xie et al., 2025). Recent trends probe persona behavior in interaction (e.g., consistency and drift under dialogue) (Frisch & Giulianelli, 2024) and build agent mechanisms that adapt actions to user preferences at inference time (Zhang et al., 2025c). While this work estab- lishes ...
2025
-
[4]
Read the persona aspects carefully, treating them as the ground truth for evaluation
-
[5]
Provide evidence quotes for all non-zero aspect cover- age ratings
-
[6]
Complete all steps in sequence (coverage→ findability →comparison)
-
[7]
These safeguards helped ensure high-quality, reproducible annotations grounded in persona-aligned judgments
Judge strictly by persona relevance, not by report ver- bosity, formatting, or personal opinion. These safeguards helped ensure high-quality, reproducible annotations grounded in persona-aligned judgments. Blinding considerations.Pairwise comparison in open- ended generation cannot guarantee perfect blinding, and we treat this as a known limitation rather...
-
[8]
Explore different directions relevant to this query
-
[9]
Cover a good wide range of topics and aspects of the query
-
[10]
Consider recent developments up to \{current_time\} 19 An Interactive Paradigm for Deep Research
-
[11]
Are somewhat tailored to the user’s background and needs, but not constrained by the user’s persona and interests
-
[12]
follow_up_questions
Each follow-up question should cover a distinct thematic facet - do not repeat other questions For each question, provide a confidence score between 0.0 and 1.0 indicating: - Relevance of the question to the main research query - Insightfulness of the question that would be useful for the final report generation - How likely this question is to lead to va...
-
[13]
Learnings that address the user’s checklist items
-
[14]
Information relevant to their background and interests
-
[15]
Follow-up questions that would help address their specific needs
-
[16]
wild-card
Each follow-up question should cover a distinct thematic facet - do not repeat other questions For each follow-up question, provide a confidence score between 0.0 and 1.0 indicating: - How likely this question is to lead to valuable information for this user - Alignment with user’s persona and checklist items - Relevance to the original research query Add...
-
[17]
Effectively searches for information to answer the follow-up question
-
[18]
Is optimized for search engines
-
[19]
Maintains connection to the original research query
-
[20]
search_queries
Considers the user’s persona and interests For each search query, also provide a clear research goal that describes: - What specific information or insights this search aims to discover 20 An Interactive Paradigm for Deep Research - How it relates to the original research question - What direction of the topic it will explore Follow-up questions: \{follow...
-
[21]
Specific to this user’s background and interests
-
[22]
Relevant to the research query
-
[23]
Actionable and measurable
-
[24]
checklist_items
Distinct from other items Return your response as a JSON object with the following structure: \{ "checklist_items": [ "specific aspect this user would expect to see addressed", "another specific aspect relevant to their interests" ] \} Persona Modeling System Prompt You are an expert at understanding user personas and updating them based on user interacti...
-
[25]
Background and interests
-
[26]
Specific preferences and priorities
-
[27]
Communication style and concerns
-
[28]
additional_persona_info
Any new aspects they care about IMPORTANT: Do NOT output repetitive information: - Only include NEW persona information that isn’t already covered in the current persona - Only include NEW checklist items that aren’t already in the current checklist - If nothing new can be inferred, return empty strings and empty arrays Return your response as a JSON obje...
-
[29]
Starts with a natural introduction
-
[30]
Lists each research direction as numbered bullet points (1., 2., 3., etc.)
-
[31]
For each direction, provide a concise summary (1 sentence) that captures the essence of what that search query would explore, rather than showing the raw search query
-
[32]
1, 3") - To suggest new follow-up questions: start a new line with
Provides clear selection instructions: - To select directions: just type the bullet numbers (e.g., "1, 3") - To suggest new follow-up questions: start a new line with "New follow-up questions:" followed by each new follow-up question on separate lines
-
[33]
clarification_question
Matches the user’s communication style Return your response as a JSON object with the following structure: \{ "clarification_question": "your structured question to the user with concise summaries" \} 21 An Interactive Paradigm for Deep Research Report Generation System Prompt You are a professional research report writer specializing in persona-aware rep...
-
[34]
Synthesize information from multiple levels of research depth
-
[35]
Integrate findings from various research branches
-
[36]
Present a coherent narrative that builds from foundational to advanced insights
-
[37]
Maintain proper citation of sources throughout
-
[38]
Be well-structured with clear sections and subsections
-
[39]
Have a minimum length of \{total_words\} words
-
[40]
Follow \{report_format\} format with markdown syntax
-
[41]
Use markdown tables, lists and other formatting features when presenting comparative data, statistics, or structured information
-
[42]
evaluations
Be tailored to the user’s persona and interests Additional requirements: - Prioritize insights that emerged from deeper levels of research - Highlight connections between different research branches - Include relevant statistics, data, and concrete examples - Focus on directions that align with the user’s interests and checklist - Use language and explana...
-
[43]
Specific to this user’s background, needs, and context
-
[44]
Actionable and measurable (can be used to evaluate a response)
-
[45]
Relevant to the query and persona
-
[46]
aspects": [ \{
Distinct from other aspects (no overlap) Format your response in JSON format where each aspect is a clear, specific expectation that can be used to evaluate whether a response adequately addresses this user’s needs and provide a clear explanation of why each aspect is significant for the user and what specific details they would expect to see in the respo...
-
[49]
type": "object
Goes beyond mere keyword mentions or general background information A sentence does NOT cover an aspect if it: - Only provides general background or introductory information - Mentions keywords related to the topic but doesn’t address the specific concern - Gives broad overviews without targeting the particular interest - Describes general principles with...
-
[50]
Directly addresses the specific concern or interest described in the aspect
-
[51]
Provides substantive, detailed information that would be valuable to someone with that specific aspect
-
[52]
point_number
Goes beyond mere keyword mentions or general background information A key point does NOT cover an aspect if it only provides introductory information or broad overviews **Default to NOT covering aspects unless there is clear, direct, substantial relevance to the specific user concern. ** Response strictly in JSON format: \{ "point_number": \{ "cover_aspec...
-
[53]
Clearly aims to gather information directly relevant to the specific concern described by the aspect; AND
-
[54]
response_number
Goes beyond surface keywords or generic curiosity. A follow-up does NOT cover an aspect if it: - Is a broad/background question without tailoring to that aspect; OR - Only mentions related keywords but lacks a targeted objective tied to the aspect; OR - Is unrelated to the user’s stated concerns. Respond strictly in JSON format: \{ "response_number": \{ "...
-
[55]
Selecting ONLY the most relevant direction numbers that have the highest priority for this research
-
[56]
Suggesting new follow-up questions ONLY if you feel there’s a very important direction missing from the proposal
-
[57]
selected_directions
Providing natural commentary as this user would speak **IMPORTANT CONSTRAINTS: ** - **DO NOT select directions or suggest questions that are outside your persona and aspects/interests** - **DO NOT suggest questions you have already asked before or that are similar to the questions you have already asked (check your history above)** - Only focus on areas t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.