Enhancing Reliability in LLM-Based Secure Code Generation
Pith reviewed 2026-06-30 15:10 UTC · model grok-4.3
The pith
Embedding mitigation guidance in chain-of-thought prompts cuts security vulnerabilities in LLM code generation by over half.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
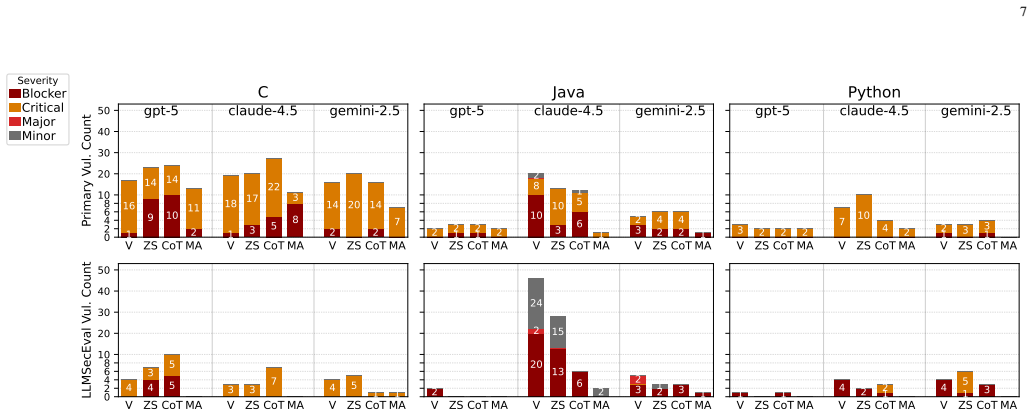
The Mitigation-Aware Chain-of-Thought (MA-CoT) framework embeds task-specific CWE mitigation guidance and language-aware safeguards to reduce recurring vulnerabilities. Evaluated across three LLMs, three languages, and four prompting strategies on a 200-task dataset with validation on LLMSecEval, MA-CoT is the only strategy that consistently improves security reliability, reducing total security findings from 92 to 39 on the primary dataset and from 73 to 4 on LLMSecEval, with similar drops in high-severity issues. Zero-shot and CoT are less reliable and may increase vulnerability, especially in C. A strict layered attribution shows residual risk concentrates in hardening-oriented patterns s
What carries the argument
The Mitigation-Aware Chain-of-Thought (MA-CoT) framework that adds task-specific CWE mitigation guidance and language-aware safeguards to standard chain-of-thought prompting.
Load-bearing premise
Static analysis tools combined with expert validation fully and fairly capture all relevant security vulnerabilities in the generated code without bias toward any prompting method.
What would settle it
Running the same code generation tasks with the four prompting strategies and having blinded security experts count vulnerabilities to see if MA-CoT still shows the reported reduction.
Figures

read the original abstract
Large language models (LLMs) are widely used for code generation, but their security reliability remains inconsistent across languages and prompting strategies. Existing prompt engineering improves functional correctness but rarely ensures consistent security outcomes. We introduce the \textit{Mitigation-Aware Chain-of-Thought (MA-CoT)} framework, which embeds task-specific CWE mitigation guidance and language-aware safeguards to reduce recurring vulnerabilities in generated code. We evaluate MA-CoT across three LLMs (gpt-5, claude-4.5, gemini-2.5), three programming languages (C, Java, Python), and four prompting strategies (Vanilla, Zero-shot, CoT, MA-CoT) on a 200-task primary dataset, with external validation on LLMSecEval. Using static analysis with expert validation, MA-CoT reduces total security findings from 92 to 39 (57.6\%) on the primary dataset and from 73 to 4 (94.5\%) on LLMSecEval. High-severity findings (Blocker + Critical) drop from 90 to 39 (56.7\%) and from 45 to 2 (95.6\%), respectively. Across both datasets, MA-CoT is the only strategy that consistently improves security reliability; Zero-shot and CoT are less reliable and may increase vulnerability, especially in C. We further introduce a strict layered attribution of vulnerability drivers (language-core vs. stack layers) and show that residual risk concentrates in hardening-oriented patterns (e.g., OS- and toolchain-dependent), motivating secure-by-construction primitives alongside prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Mitigation-Aware Chain-of-Thought (MA-CoT) framework, which embeds task-specific CWE mitigation guidance and language-aware safeguards into prompting for LLM code generation. It evaluates MA-CoT against Vanilla, Zero-shot, and CoT strategies across three LLMs (gpt-5, claude-4.5, gemini-2.5), three languages (C, Java, Python), and a 200-task primary dataset plus LLMSecEval, claiming via static analysis plus expert validation that MA-CoT is the only strategy that consistently reduces vulnerabilities (92→39 findings, 57.6%; 73→4 findings, 94.5%) while others may increase them, especially in C; it also introduces a layered attribution of vulnerability drivers.
Significance. If the measured reductions hold under rigorous validation, the work supplies a concrete prompting technique that improves security outcomes in LLM code generation and supplies a useful decomposition of residual risk into language-core versus stack-layer drivers. The reliance on an external benchmark (LLMSecEval) alongside the primary dataset is a positive methodological feature.
major comments (3)
- [§4] §4 (Evaluation setup): the headline reductions (92→39 and 73→4 total findings; 90→39 and 45→2 high-severity) are presented without error bars, statistical significance tests, or any description of the static-analysis tool versions, rule sets, or prompt-construction protocol; these omissions are load-bearing for the claim that MA-CoT is uniquely reliable.
- [§4.3] §4.3 (Expert validation): no inter-rater reliability statistics or blinding protocol is reported for the expert review step; without these, systematic differences in scrutiny across prompting conditions cannot be ruled out and directly affect the central claim that only MA-CoT improves security.
- [§5] §5 (Results): the conclusion that static analysis plus expert validation provides a complete, unbiased measure of vulnerability reduction rests on an untested assumption that the chosen tools detect all relevant flaw types uniformly; the paper does not address known limitations of static analyzers on semantic or context-dependent issues (e.g., incorrect hardening-API usage).
minor comments (2)
- [Abstract] Abstract and §3: model names 'gpt-5, claude-4.5, gemini-2.5' read as placeholders; replace with the actual model identifiers used in the experiments.
- [§3.2] §3.2: the 'strict layered attribution' of vulnerability drivers is introduced but lacks an explicit decision procedure or example trace that would allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology. We address each major comment below, indicating where revisions will be made to improve reproducibility and transparency.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation setup): the headline reductions (92→39 and 73→4 total findings; 90→39 and 45→2 high-severity) are presented without error bars, statistical significance tests, or any description of the static-analysis tool versions, rule sets, or prompt-construction protocol; these omissions are load-bearing for the claim that MA-CoT is uniquely reliable.
Authors: We agree these details are essential. In the revision we will expand §4 with: (1) exact tool versions and rule sets (SonarQube 9.9 with OWASP Top 10 and CWE rules; CodeQL with custom security queries); (2) the full prompt-construction protocol and templates for each strategy; (3) a note that all generations used temperature=0 for determinism on the fixed 200-task set. Because the study used single deterministic runs rather than repeated sampling, error bars and significance tests were not computed; we will add an explicit discussion of this design choice and its implications for generalizability. revision: partial
-
Referee: [§4.3] §4.3 (Expert validation): no inter-rater reliability statistics or blinding protocol is reported for the expert review step; without these, systematic differences in scrutiny across prompting conditions cannot be ruled out and directly affect the central claim that only MA-CoT improves security.
Authors: We will revise §4.3 to describe the validation protocol in full, including that the single security expert was blinded to prompting condition during review and that reviews were performed in randomized order. We will also note the absence of inter-rater reliability statistics due to the single-rater design and discuss this as a limitation. revision: yes
-
Referee: [§5] §5 (Results): the conclusion that static analysis plus expert validation provides a complete, unbiased measure of vulnerability reduction rests on an untested assumption that the chosen tools detect all relevant flaw types uniformly; the paper does not address known limitations of static analyzers on semantic or context-dependent issues (e.g., incorrect hardening-API usage).
Authors: We agree that static analyzers have well-known limitations on semantic and context-dependent flaws. The revised §5 will explicitly acknowledge these limitations, cite supporting literature, and explain how the subsequent expert validation step was intended to surface issues missed by automation (e.g., incorrect hardening-API usage). We will qualify the completeness claim accordingly. revision: yes
Circularity Check
No circularity: empirical comparison on external benchmarks with no derivations or self-referential fits
full rationale
The paper is an empirical evaluation of prompting strategies (Vanilla, Zero-shot, CoT, MA-CoT) on fixed datasets using static analysis tools plus expert validation. No equations, parameter fitting, or first-principles derivations are claimed. Results (e.g., security finding reductions) are direct measurements, not quantities defined in terms of themselves or forced by self-citation chains. External benchmarks (primary 200-task set, LLMSecEval) and tools provide independent grounding; the central claim does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static analysis tools combined with expert validation provide a reliable count of security vulnerabilities in generated code samples.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
From large to mammoth: A comparative evaluation of large language models in vulnerability detection,
J. Lin and D. Mohaisen, “From large to mammoth: A comparative evaluation of large language models in vulnerability detection,” in32nd Annual Network and Distributed System Security Symposium, NDSS 2025, San Diego, California, USA, February 24-28, 2025. The Internet Society, 2025
2025
-
[3]
A user-centered security evaluation of copilot,
O. Asare, M. Nagappan, and N. Asokan, “A user-centered security evaluation of copilot,” inICSE, 2024
2024
-
[4]
Duplicate bug report detection using an attention-based neural language model,
M. B. Messaoud, A. Miladi, I. Jenhani, M. W. Mkaouer, and L. Ghadhab, “Duplicate bug report detection using an attention-based neural language model,”IEEE Trans. Reliab., vol. 72, no. 2, pp. 846–858, 2023. [Online]. Available: https://doi.org/10.1109/TR.2022.3193645
-
[5]
Statically detecting vulnerabilities by processing programming languages as natural languages,
I. Medeiros, N. Neves, and M. Correia, “Statically detecting vulnerabilities by processing programming languages as natural languages,”IEEE Trans. Reliab., vol. 71, no. 2, pp. 1033–1056, 2022. [Online]. Available: https://doi.org/10.1109/TR.2021.3137314
-
[6]
Large language models in cybersecurity: A survey of applications, vulnerabilities, and defense techniques,
N. O. Jaffal, M. Alkhanafseh, and D. Mohaisen, “Large language models in cybersecurity: A survey of applications, vulnerabilities, and defense techniques,”AI, vol. 6, no. 9, 2025. [Online]. Available: https://www.mdpi.com/2673-2688/6/9/216
2025
-
[7]
Adoption of developer ai tools (copilot, etc) 2022 - 2025: Data & graphs show increase in ai use as developers evolve - gitclear,
—, “Adoption of developer ai tools (copilot, etc) 2022 - 2025: Data & graphs show increase in ai use as developers evolve - gitclear,” 12 2025, [Online; accessed 2025-12-27]. [Online]. Available: https://www.gitclear.com/research/developer_ai_ assistant_adoption_by_year_with_ai_delegation_buckets
2022
-
[8]
B. Yetistiren, I. Özsoy, M. Ayerdem, and E. Tüzün, “Evaluating the code quality of ai-assisted code generation tools: An empirical study on github copilot, amazon codewhisperer, and chatgpt,”CoRR, vol. abs/2304.10778, 2023
-
[9]
Asleep at the keyboard? assessing the security of github copilot’s code contri- butions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of github copilot’s code contri- butions,” inIEEE Symp. on Security & Privacy, 2022
2022
-
[10]
Security weaknesses of copilot-generated code in github projects: An empirical study,
Y . Fu, P. Liang, A. Tahir, Z. Li, M. Shahin, J. Yu, and J. Chen, “Security weaknesses of copilot-generated code in github projects: An empirical study,”CoRR, vol. abs/2310.02059, 2025
-
[11]
Lost at c: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, and B. Dolan-Gavitt, “Lost at c: A user study on the security implications of large language model code assistants,” inProceedings of the 32nd USENIX Security Symposium, 2023, pp. 2205–2222
2023
-
[12]
Is github’s copilot as bad as humans at introducing vulnerabilities in code?
O. Asare, M. Nagappan, and N. Asokan, “Is github’s copilot as bad as humans at introducing vulnerabilities in code?”Empir. Softw. Eng., vol. 28, no. 6, p. 129, 2023. [Online]. Available: https://doi.org/10.1007/s10664-023-10380-1
-
[13]
Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks,” in IEEE Symposium on Security and Privacy, 2024
2024
-
[14]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[15]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and ...
2022
-
[16]
Available: http://papers.nips.cc/paper_files/paper/2022/ hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html
[Online]. Available: http://papers.nips.cc/paper_files/paper/2022/ hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html
2022
-
[17]
ACM Trans Softw Eng Methodol 34(8):225:1--225:53, doi:10.1145/3722108, ://doi.org/10.1145/3722108
C. Tony, N. E. D. Ferreyra, M. Mutas, S. Dhif, and R. Scandariato, “Prompting techniques for secure code generation: A systematic investigation,”ACM TOSEM, vol. 34, no. 8, pp. 225:1–225:53, 2025. [Online]. Available: https://doi.org/10.1145/3722108
-
[18]
An empirical evaluation of llm-generated code security across prompting methods,
M. Kharma, A. Sabbah, M. AlKhanafseh, M. Hammoudeh, and D. Mo- haisen, “An empirical evaluation of llm-generated code security across prompting methods,” 2026, submitted to Empirical Software Engineer- ing
2026
-
[19]
Why does the effective context length of llms fall short?
C. An, J. Zhang, M. Zhong, L. Li, S. Gong, Y . Luo, J. Xu, and L. Kong, “Why does the effective context length of llms fall short?”CoRR, vol. abs/2410.18745, 2024
-
[20]
Rethinking the evaluation of secure code generation,
S.-C. Dai, J. Xu, and G. Tao, “Rethinking the evaluation of secure code generation,” 2025. [Online]. Available: https://arxiv.org/abs/2503.15554
-
[21]
Devaic: A tool for security assessment of ai-generated code,
D. Cotroneo, R. D. Luca, and P. Liguori, “Devaic: A tool for security assessment of ai-generated code,”Inf. Softw. Technol., vol. 177, p. 107572, 2025. [Online]. Available: https://doi.org/10.1016/j.infsof.2024. 107572
-
[22]
B. Lin, S. Wang, Y . Qin, L. Chen, and X. Mao, “Give llms a security course: Securing retrieval-augmented code generation via 13 knowledge injection,” inCCS, C. Huang, J. Chen, S. Shieh, D. Lie, and V . Cortier, Eds. ACM, 2025, pp. 3356–3370. [Online]. Available: https://doi.org/10.1145/3719027.3765049
-
[23]
N. Huynh and B. Lin, “Large language models for code generation: A comprehensive survey of challenges, techniques, evaluation, and applications,”CoRR, vol. abs/2503.01245, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.01245
-
[24]
Using AI assistants in software development: A qualitative study on security practices and concerns,
J. H. Klemmer, S. A. Horstmann, N. Patnaik, C. Ludden, C. B. Jr., C. Powers, F. Massacci, A. Rahman, D. V otipka, H. R. Lipford, A. Rashid, A. Naiakshina, and S. Fahl, “Using AI assistants in software development: A qualitative study on security practices and concerns,” inCCS. ACM, 2024, pp. 2726–2740. [Online]. Available: https://doi.org/10.1145/3658644.3690283
-
[25]
How secure is ai-generated code: a large-scale comparison of large language models,
N. Tihanyi, T. Bisztray, M. A. Ferrag, R. Jain, and L. C. Cordeiro, “How secure is ai-generated code: a large-scale comparison of large language models,”Empir. Softw. Eng., vol. 30, no. 2, p. 47, 2025. [Online]. Available: https://doi.org/10.1007/s10664-024-10590-1
-
[26]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,”CoRR, vol. abs/2402.07927, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.07927
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.07927 2024
-
[27]
arXiv preprint arXiv:2310.14735 , year=
B. Chen, Z. Zhang, N. Langrené, and S. Zhu, “Unleashing the potential of prompt engineering in large language models: a comprehensive review,”CoRR, vol. abs/2310.14735, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.14735
-
[28]
2024.From Vulnerabilities to Remediation: A Systematic Literature Review of LLMs in Code Security
E. Basic and A. Giaretta, “Large language models and code security: A systematic literature review,”CoRR, vol. abs/2412.15004, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2412.15004
-
[29]
You still have to study on the security of LLM generated code,
A. Schaad, S. Götz, and D. Binder, “You still have to study on the security of LLM generated code,” inICT Systems Security and Privacy Protection - 40th IFIP International Conference, SEC 2025, Maribor, Slovenia, May 21-23, 2025, Proceedings, Part II, ser. IFIP Advances in Information and Communication Technology, L. N. Zlatolas, K. Rannenberg, T. Welzer,...
-
[30]
Secure Code Generation at Scale with Reflexion
A. Datta, A. Aljohani, and H. Do, “Secure code generation at scale with reflexion,”CoRR, vol. abs/2511.03898, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2511.03898
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.03898 2025
-
[31]
Language models can solve computer tasks,
G. Kim, P. Baldi, and S. McAleer, “Language models can solve computer tasks,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[32]
J. Li, F. Rabbi, B. Yang, S. Wang, and J. Yang, “Secure-instruct: An automated pipeline for synthesizing instruction-tuning datasets using llms for secure code generation,” 2025. [Online]. Available: https://arxiv.org/abs/2510.07189
-
[33]
RESCUE: retrieval augmented secure code generation,
J. Shi and T. Zhang, “RESCUE: retrieval augmented secure code generation,”CoRR, vol. abs/2510.18204, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.18204
-
[34]
Towards secure code generation with llms: A study on common weakness enumeration,
J. Zhao, Y . Sun, C. Huang, C. Liu, Y . Guan, Y . Zeng, and Y . Liu, “Towards secure code generation with llms: A study on common weakness enumeration,”IEEE Transactions on Software Engineering, vol. 51, no. 12, pp. 3507–3523, 2025
2025
-
[35]
M. Nazzal, I. Khalil, A. Khreishah, and N. Phan, “Promsec: Prompt optimization for secure generation of functional source code with large language models (llms),” inCCS. ACM, 2024, pp. 2266–2280. [Online]. Available: https://doi.org/10.1145/3658644.3690298
-
[36]
Y . Nong, M. Aldeen, L. Cheng, H. Hu, F. Chen, and H. Cai, “Chain-of-thought prompting of large language models for discovering and fixing software vulnerabilities,”CoRR, vol. abs/2402.17230, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.17230
-
[37]
Self-planning code generation with large language models,
X. Jiang, Y . Dong, L. Wang, Z. Fang, Q. Shang, G. Li, Z. Jin, and W. Jiao, “Self-planning code generation with large language models,” ACM Trans. Softw. Eng. Methodol., vol. 33, no. 7, pp. 182:1–182:30,
-
[38]
Available: https://doi.org/10.1145/3672456
[Online]. Available: https://doi.org/10.1145/3672456
-
[39]
M. F. Kharma, S. Choi, M. Alkhanafseh, and D. Mohaisen, “Security and quality in llm-generated code: a multi-language, multi-model analysis,”IEEE Transactions on Dependable and Secure Computing, no. 01, pp. 1–15, 2026. [Online]. Available: https: //doi.org/10.1109/TDSC.2026.3672745
-
[40]
Llm-csec: Empirical evaluation of security in c/c++ code generated by large language models,
M. U. Shahid, C. M. Ahmed, and R. Ranjan, “Llm-csec: Empirical evaluation of security in c/c++ code generated by large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2511.18966
-
[41]
Cweval: Outcome-driven evaluation on functionality and security of LLM code generation,
J. Peng, L. Cui, K. Huang, J. Yang, and B. Ray, “Cweval: Outcome-driven evaluation on functionality and security of LLM code generation,” inIEEE/ACM International Workshop on Large Language Models for Code, LLM4Code@ICSE 2025, Ottawa, ON, Canada, May 3, 2025. IEEE, 2025, pp. 33–40. [Online]. Available: https://doi.org/10.1109/LLM4Code66737.2025.00009
-
[42]
Baxbench: Can llms generate correct and secure backends?
M. Vero, N. Mündler, V . Chibotaru, V . Raychev, M. Baader, N. Jovanovic, J. He, and M. T. Vechev, “Baxbench: Can llms generate correct and secure backends?” inICML. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=il3KRr4H9u
2025
-
[43]
J. Chen, H. Huang, Y . Lyu, J. An, J. Shi, C. Yang, T. Zhang, H. Tian, Y . Li, Z. Li, X. Zhou, X. Hu, and D. Lo, “Secureagentbench: Benchmarking secure code generation under realistic vulnerability scenarios,”CoRR, vol. abs/2509.22097, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.22097
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.22097 2025
-
[44]
Gpt-5 model | openai api,
—, “Gpt-5 model | openai api,” https://platform.openai.com/docs/ models/gpt-5, 09 2025, (Accessed on 2025-09-24)
2025
-
[45]
What’s new in claude 4.5 - claude doc,
——, “What’s new in claude 4.5 - claude doc,” https://platform.claude. com/docs/en/about-claude/models/whats-new-claude-4-5, 09 2025, (Ac- cessed on 2025-09-24)
2025
-
[46]
Gemini models | gemini api | google ai for developers,
——, “Gemini models | gemini api | google ai for developers,” https: //ai.google.dev/gemini-api/docs/models, 09 2025, (Accessed on 2025- 09-24)
2025
-
[47]
Code quality, security & static analysis tool with SonarQube,
——, “Code quality, security & static analysis tool with SonarQube,” https://www.sonarsource.com/products/sonarqube/, 05 2024, (Accessed on 05/12/2024)
2024
-
[48]
Llmseceval: A dataset of natural language prompts for security evaluations,
C. Tony, M. Mutas, N. E. D. Ferreyra, and R. Scandariato, “Llmseceval: A dataset of natural language prompts for security evaluations,” inMSR. IEEE, 2023, pp. 588–592. [Online]. Available: https://doi.org/10.1109/MSR59073.2023.00084
-
[49]
Benchmarking prompt engineering techniques for secure code generation with GPT models,
M. Bruni, F. Gabrielli, M. Ghafari, and M. Kropp, “Benchmarking prompt engineering techniques for secure code generation with GPT models,” inForge@ICSE. IEEE, 2025, pp. 93–103. [Online]. Available: https://doi.org/10.1109/Forge66646.2025.00018
-
[50]
SALLM: security assessment of generated code,
M. L. Siddiq, J. C. da Silva Santos, S. Devareddy, and A. Muller, “SALLM: security assessment of generated code,” inASE Workshops. ACM, 2024, pp. 54–65. [Online]. Available: https://doi.org/10.1145/ 3691621.3694934
-
[51]
S. Liu, B. Sabir, S. I. Jang, Y . Kansal, Y . Gao, K. Moore, A. Abuadbba, and S. Nepal, “From solitary directives to interactive encouragement! LLM secure code generation by natural language prompting,”CoRR, vol. abs/2410.14321, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2410.14321 APPENDIXA EXAMPLEENTRIES FROM THEMITIGATION-AWARE DATASET T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.