A Reinforcement Learning Inspired Latent Yield Based Adaptive Algorithm Switching Mechanism
Pith reviewed 2026-06-30 12:35 UTC · model grok-4.3
The pith
A latent yield that aggregates rewards and penalties enables adaptive algorithm switching that resists erratic instance variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that performance across instances can be aggregated into a latent yield inspired by reinforcement learning rewards and penalties; this yield then drives exploitation versus exploration decisions, producing algorithm switches that remain fairly immune to erratic changes in instance features. Island models drawn from genetic algorithms allow parallel exploration among separate algorithm populations and enable performance exchanges between them. Experiments on sorting algorithms and robotic obstacle avoidance are presented to show the approach is feasible and effective for domains that need adaptive selection.
What carries the argument
The latent yield, which folds an algorithm's rewards and penalties across instances into a single value that triggers exploitation or exploration decisions.
If this is right
- Algorithm selection becomes less reactive to single-instance noise and more consistent across sequences of problems.
- Island models allow multiple algorithm populations to explore in parallel while exchanging performance information.
- The same yield-driven mechanism applies to both combinatorial tasks such as sorting and continuous control tasks such as robot navigation.
- Computation remains lightweight because the yield is maintained incrementally rather than recomputed from scratch each time.
Where Pith is reading between the lines
- The same yield construction could be tested on hyperparameter tuning or online scheduling problems where feature drift is also common.
- If the yield threshold for switching is made explicit, it would allow direct comparison against other meta-learners that use regret or confidence bounds.
- Extending the island exchange to include negative transfer penalties might further stabilize the populations when one algorithm dominates.
Load-bearing premise
The method of turning rewards and penalties into a latent yield produces switching decisions that stay stable when instance features change erratically.
What would settle it
Running the method on sorting or obstacle-avoidance instances whose features are deliberately made to fluctuate rapidly and then measuring whether switches become frequent or unstable would falsify the immunity claim.
Figures


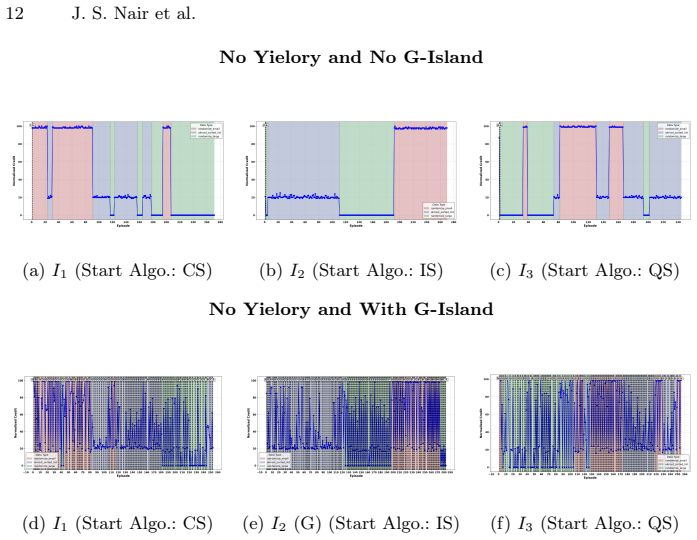
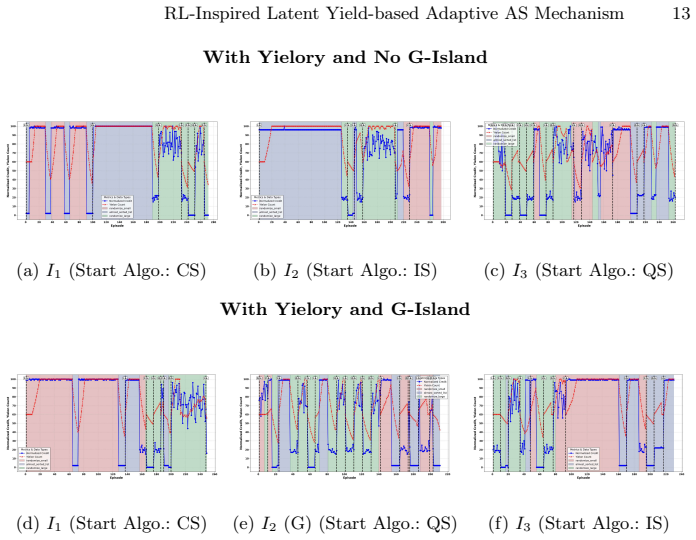
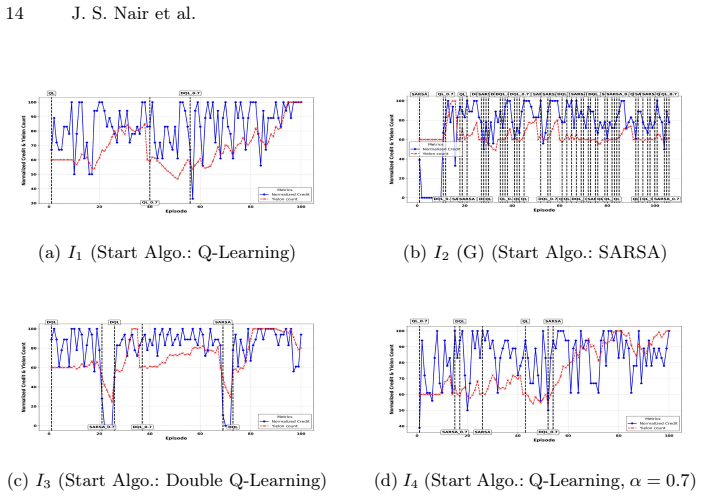
read the original abstract
Selecting the most suitable algorithm for a given problem instance remains a challenging task, particularly in online or dynamic environments where problem characteristics evolve over time. Relying solely on instantaneous performance metrics can result in a reactive and unstable behaviour, often leading to suboptimal algorithm switching. This paper introduces a computationally efficient approach for aggregating an algorithm's performance across multiple problem instances that is fairly immune to erratic variations in instance features. Inspired by features inherent to Reinforcement Learning (RL), this technique encapsulates rewards and penalties into a latent yield that, in turn, triggers exploitation and exploration, consequently resulting in adaptive algorithm switching. The proposed technique employs island models, inspired by Genetic Algorithms, to facilitate parallel exploration and performance exchanges among algorithm populations inhabiting local repertoires. Experimental evaluations on sorting algorithms and robotic obstacle avoidance tasks demonstrate the feasibility and effectiveness of the approach, highlighting its potential in domains where adaptive algorithm selection is critical.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive algorithm switching mechanism that aggregates performance into a 'latent yield' inspired by reinforcement learning to balance exploitation and exploration. It incorporates island models from genetic algorithms for parallel performance exchanges among algorithm populations. The approach is claimed to be fairly immune to erratic variations in problem instance features, with experimental feasibility shown on sorting algorithms and robotic obstacle avoidance tasks.
Significance. Should the latent yield mechanism prove robust under controlled validation, it would offer a promising direction for stable online algorithm selection in dynamic multi-agent and robotic environments. The integration of RL concepts with island models is a novel combination, but without explicit derivations or reproducible experiments, the significance remains potential rather than demonstrated. No machine-checked proofs or parameter-free claims are present.
major comments (2)
- [Abstract] The assertion that the technique 'is fairly immune to erratic variations in instance features' is load-bearing for the central claim but is not supported by any aggregation formula, threshold rules, or decay parameters for the latent yield; this matches the stress-test concern and prevents verification.
- [Experimental evaluations] The evaluations on sorting and obstacle avoidance tasks report feasibility and effectiveness but provide no methods details, data, error bars, ablation studies, or stress tests that inject erratic perturbations to quantify switch stability or performance variance against a reactive baseline.
minor comments (1)
- The abstract mentions 'computationally efficient approach' but no complexity analysis or runtime comparisons are referenced.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below and plan to incorporate revisions to strengthen the presentation of the latent yield mechanism and the experimental evaluations.
read point-by-point responses
-
Referee: [Abstract] The assertion that the technique 'is fairly immune to erratic variations in instance features' is load-bearing for the central claim but is not supported by any aggregation formula, threshold rules, or decay parameters for the latent yield; this matches the stress-test concern and prevents verification.
Authors: We agree that the assertion in the abstract is load-bearing and currently lacks explicit support from aggregation formulas, threshold rules, or decay parameters. We will revise the manuscript to incorporate these details, providing the specific formulas and parameters used in the latent yield mechanism to allow verification and address the related stress-test concern. revision: yes
-
Referee: [Experimental evaluations] The evaluations on sorting and obstacle avoidance tasks report feasibility and effectiveness but provide no methods details, data, error bars, ablation studies, or stress tests that inject erratic perturbations to quantify switch stability or performance variance against a reactive baseline.
Authors: We agree that the experimental evaluations require additional details for reproducibility and to demonstrate robustness. We will revise the manuscript to include comprehensive methods details, data, error bars, ablation studies, and stress tests injecting erratic perturbations, with comparisons to a reactive baseline. revision: yes
Circularity Check
No circularity: technique presented as novel aggregation without equations reducing to inputs or self-citations
full rationale
The abstract and description introduce the latent yield as an RL-inspired encapsulation of rewards/penalties for adaptive switching, using island models for exploration, but supply no equations, parameters, or derivation steps that could be inspected for self-definition, fitted predictions, or load-bearing self-citations. The claimed immunity to erratic variations is asserted as a property of the method rather than derived from prior results by the same authors or ansatzes smuggled via citation. No uniqueness theorems or renamings of known results are invoked. The derivation chain is therefore self-contained at the conceptual level with no reductions to its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
latent yield
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Data Mining and Constraint Programming: Foundations of a Cross-Disciplinary Approach, pp
Kotthoff, L.: Algorithm selection for combinatorial search problems: A survey. In: Data Mining and Constraint Programming: Foundations of a Cross-Disciplinary Approach, pp. 149–190. Springer (2016)
2016
-
[2]
In: Proc
Degroote, H.: Online algorithm selection. In: Proc. Int. Joint Conf. on Artificial Intelligence (IJCAI), pp. 5173–5174 (2017)
2017
-
[3]
IEEE Trans
Wolpert, D.H., Macready, W.G.: No free lunch theorems for optimization. IEEE Trans. Evol. Comput.1(1), 67–82 (2002)
2002
-
[4]
In: Proc
Yuan, Y., Misir, M.: Enhancing molecular docking performance with a GNN-based algorithm selection model. In: Proc. 8th Int. Conf. on Computational Biology and Bioinformatics, pp. 14–19 (2024)
2024
-
[5]
In: Proc
Rook,J.,Renau,Q.,Trautmann,H.,Hart,E.:Efficientonlineautomatedalgorithm selection in the face of data-drift in optimisation problem instances. In: Proc. 18th ACM/SIGEVO Conf. on Foundations of Genetic Algorithms, pp. 262–272 (2025)
2025
-
[6]
In: Proc
Tornede, A., Bengs, V., Hüllermeier, E.: Machine learning for online algorithm selection under censored feedback. In: Proc. AAAI Conf. on Artificial Intelligence, vol. 36, pp. 10370–10380 (2022)
2022
-
[7]
Lindauer, M., Hoos, H.H., Hutter, F., Schaub, T.: Autofolio: An automatically configured algorithm selector. J. Artif. Intell. Res.53, 745–778 (2015)
2015
-
[8]
Kerschke, P., Hoos, H.H., Neumann, F., Trautmann, H.: Automated algorithm selection: Survey and perspectives. Evol. Comput.27(1), 3–45 (2019)
2019
-
[9]
et al.: ASlib: A benchmark library for algorithm selection
Bischl, B. et al.: ASlib: A benchmark library for algorithm selection. Artif. Intell. 237, 41–58 (2016).https://doi.org/10.1016/j.artint.2016.05.001
-
[10]
In: Proc
Lindauer, M., Hutter, F.: Algorithm configuration and selection on heterogeneous resources. In: Proc. Int. Joint Conf. on Artificial Intelligence (IJCAI), pp. 5178– 5182 (2018)
2018
-
[11]
Rice, J.R.: The algorithm selection problem. Adv. Comput.15, 65–118 (1976)
1976
-
[12]
Semwal, T., Nair, S.B.: A decentralized and distributed immune-inspired mecha- nism for adaptive problem–solution mapping in cyber–physical systems. Appl. Soft Comput.86, 105920 (2020).https://doi.org/10.1016/j.asoc.2019.105920
-
[13]
In: Parallel Problem Solving from Nature – PPSN V, pp
Whitley, D., Rana, S., Heckendorn, R.: The island model genetic algorithm: On separability, population size and convergence. In: Parallel Problem Solving from Nature – PPSN V, pp. 109–118. Springer (1999).https://doi.org/10.1007/ 3-540-48685-2_12
1999
-
[14]
Xu, L., Hutter, F., Hoos, H.H., Leyton-Brown, K.: SATzilla: Portfolio-based al- gorithm selection for SAT. J. Artif. Intell. Res.32, 565–606 (2008).https: //doi.org/10.1613/jair.2470
-
[15]
In: AISB Workshop on Evolutionary Computing, pp
Whitley, D., Rana, S., Heckendorn, R.B.: Island model genetic algorithms and linearly separable problems. In: AISB Workshop on Evolutionary Computing, pp. 109–125. Springer (1997)
1997
-
[16]
Jha, S.S., Godfrey, W.W., Nair, S.B.: Stigmergy-based synchronization of a se- quence of tasks in a network of asynchronous nodes. Cybern. Syst.45(5), 373–406 (2014)
2014
-
[17]
Michel, O.: Webots: Professional mobile robot simulation. Int. J. Adv. Robot. Syst. 1(1), 39–42 (2004).https://www.cyberbotics.com/doc/guide/index
2004
-
[18]
Watkins, C.J.C.H., Dayan, P.: Q-learning. Mach. Learn.8(3), 279–292 (1992)
1992
-
[19]
In: Advances in Neural Information Processing Systems 23, pp
van Hasselt, H.: Double Q-learning. In: Advances in Neural Information Processing Systems 23, pp. 2613–2621 (2010) RL-Inspired Latent Yield-based Adaptive AS Mechanism 17
2010
-
[20]
Rummery, G.A., Niranjan, M.: On-line Q-learning using connectionist systems. Tech. Rep. 37, Univ. of Cambridge (1994)
1994
-
[21]
Baeckens, S., Van Damme, R.: The island syndrome. Curr. Biol.30(8), R338–R339 (2020).https://doi.org/10.1016/j.cub.2020.03.029
-
[22]
Kulkarni, D.D., Nair, S.B.: Mutational puissance assisted neuroevolution. In: Proc. Genetic and Evolutionary Computation Conf. Companion, pp. 1841–1848 (2020). https://doi.org/10.1145/3377929.3398149
-
[23]
et al.: Tartarus: A multi-agent platform for integrating cyber–physical systems and robots
Semwal, T. et al.: Tartarus: A multi-agent platform for integrating cyber–physical systems and robots. In: Proc. Conf. on Advances in Robotics, pp. 1–6 (2015). https://doi.org/10.1145/2783449.2783469
-
[24]
Population Based Training of Neural Networks
Jaderberg, M. et al.: Population based training of neural networks. arXiv:1711.09846 (2017).https://arxiv.org/abs/1711.09846
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Nair, J.S., Kulkarni, D.D., Joshi, A., Suresh, S.: On decentralizing federated rein- forcement learning in multi-robot scenarios. In: Proc. SEEDA-CECNSM, pp. 1–8 (2022).https://doi.org/10.1109/SEEDA-CECNSM57760.2022.9932985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.