SAM: State-Adaptive Memory for Long-Horizon Reasoning Agent
Pith reviewed 2026-06-30 13:34 UTC · model grok-4.3
The pith
SAM treats long-horizon reasoning as state-adaptive memory that uses compact cues to trigger intent-driven recall of raw trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAM is a standalone framework that consolidates ongoing interaction into compact memory cues while preserving raw trajectory pages for intent-driven recall. The cues serve as lightweight handles that allow the agent to reconstruct temporally distant information according to its current needs without retraining the underlying backbone. The memory module is further optimized through expert-guided supervision and reinforcement learning, aligning cue utility with trajectory-level performance.
What carries the argument
State-Adaptive Memory (SAM), which generates compact cues as handles for intent-driven recall of preserved raw trajectory pages rather than replacing history.
If this is right
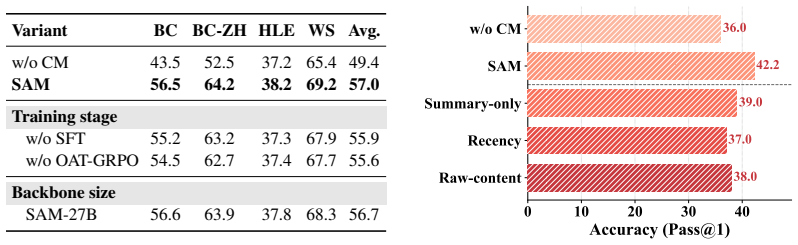
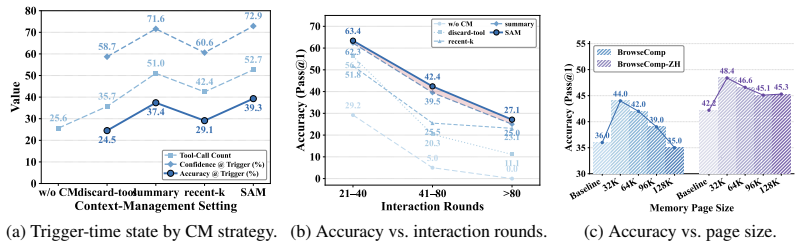
- SAM outperforms strong baselines across BrowseComp, BrowseComp-ZH, WideSearch, and HLE.
- The framework delivers gains over diverse agent backbones without retraining the LLM.
- Explicit modeling of state-adaptive memory supplies a foundation for long-horizon agentic reasoning.
- Raw trajectories remain available for reconstruction rather than being discarded or permanently compressed.
Where Pith is reading between the lines
- The separation of lightweight cues from full trajectories may reduce memory footprint in deployed agents while retaining access to details on demand.
- If cue utility can be aligned via RL, the same pattern could be tested in settings where agents must switch between multiple goals within one long session.
Load-bearing premise
Expert-guided supervision and reinforcement learning can produce memory cues whose utility aligns with trajectory-level performance, enabling effective intent-driven recall without retraining the LLM backbone.
What would settle it
An experiment in which SAM shows no improvement or underperforms baselines on BrowseComp, BrowseComp-ZH, WideSearch, and HLE when the state-adaptive cues and RL alignment are removed.
Figures

read the original abstract
Long-horizon agentic reasoning requires large language models to act over long interaction histories containing thoughts, tool calls, observations, and partial conclusions. The challenge is not merely that these histories grow long, but that information needed for the current decision may be scattered across distant steps and only become relevant later. Existing approaches address this difficulty by truncating the interaction history, compressing it into shorter surrogates, or retrieving selected parts of it for reuse, but they do not explicitly model how access to past interaction should adapt to the agent's evolving state. We instead cast long-horizon reasoning as a problem of state-adaptive memory. To this end, we propose State-Adaptive Memory~(SAM), a standalone framework that consolidates ongoing interaction into compact memory cues while preserving raw trajectory pages for intent-driven recall. These cues are not treated as replacements for history; rather, they serve as lightweight handles that allow the agent to reconstruct temporally distant information according to its current needs, without retraining the underlying backbone. We further optimize the memory module through expert-guided supervision and reinforcement learning, aligning it with trajectory-level utility. Across BrowseComp, BrowseComp-ZH, WideSearch, and HLE, SAM consistently outperforms strong baselines over diverse agent backbones. Our results suggest that explicit memory modeling provides a simple and effective foundation for long-horizon agentic reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAM, a standalone framework that models long-horizon agentic reasoning as state-adaptive memory. Interaction histories are consolidated into compact memory cues that act as handles for intent-driven recall of raw trajectory pages; the cues are optimized via expert-guided supervision and reinforcement learning to align with trajectory-level utility. The paper reports that SAM consistently outperforms strong baselines across BrowseComp, BrowseComp-ZH, WideSearch, and HLE on diverse agent backbones without retraining the underlying LLM.
Significance. If the reported gains are robust and attributable to the state-adaptive cue mechanism rather than ancillary factors, the work would supply a modular, backbone-agnostic approach to long-context agent reasoning that preserves raw history while enabling selective recall. This addresses a practical bottleneck in current agent systems.
major comments (2)
- [§4 (Optimization and Training)] The central claim that expert-guided supervision plus RL produces memory cues whose utility aligns with trajectory-level performance (and thereby drives the benchmark gains) is load-bearing, yet the manuscript provides no ablations that isolate this alignment. Removing the RL stage or the expert supervision while keeping the cue-generation architecture fixed would be required to test whether the optimization step, rather than the state-adaptive design itself, accounts for the observed improvements.
- [§3.3 (Reinforcement Learning Objective)] The reward formulation used in the RL stage is described only at a high level; it is unclear how credit is assigned to individual memory cues that affect decisions many steps later. Without a concrete reward definition or sensitivity analysis (e.g., §4.2 or Eq. (X)), it remains possible that the reported outperformance arises from distribution shift introduced by expert data rather than from improved intent-driven recall.
minor comments (2)
- [§5 (Experiments)] Table 1 and Table 2 report aggregate scores but do not include per-task variance or statistical significance tests; adding these would strengthen the cross-backbone comparison.
- [§3.1 (Memory Cue Construction)] The notation for memory cue generation (e.g., the function that maps state to cue) is introduced without an explicit equation; a single displayed equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, agreeing that additional experiments and clarifications are needed to strengthen the claims.
read point-by-point responses
-
Referee: [§4 (Optimization and Training)] The central claim that expert-guided supervision plus RL produces memory cues whose utility aligns with trajectory-level performance (and thereby drives the benchmark gains) is load-bearing, yet the manuscript provides no ablations that isolate this alignment. Removing the RL stage or the expert supervision while keeping the cue-generation architecture fixed would be required to test whether the optimization step, rather than the state-adaptive design itself, accounts for the observed improvements.
Authors: We agree that the manuscript currently lacks ablations isolating the optimization stages from the core state-adaptive cue architecture, and that such experiments are necessary to substantiate the load-bearing claim. In the revised version we will add these ablations: variants trained without the RL stage and without expert supervision (while retaining the identical cue-generation architecture) will be evaluated on the same benchmarks and reported in an expanded §4. This will allow direct assessment of whether the observed gains derive primarily from the state-adaptive design or from the optimization procedure. revision: yes
-
Referee: [§3.3 (Reinforcement Learning Objective)] The reward formulation used in the RL stage is described only at a high level; it is unclear how credit is assigned to individual memory cues that affect decisions many steps later. Without a concrete reward definition or sensitivity analysis (e.g., §4.2 or Eq. (X)), it remains possible that the reported outperformance arises from distribution shift introduced by expert data rather than from improved intent-driven recall.
Authors: We acknowledge that the current description of the RL reward is high-level and does not explicitly detail credit assignment across multi-step trajectories. In the revision we will expand §3.3 with the precise mathematical formulation of the reward (including its dependence on trajectory-level utility metrics) and add a sensitivity analysis subsection in §4.2 that varies the reward components and examines their effect on cue selection. These additions will help rule out distribution-shift explanations and clarify how individual cues receive credit for downstream performance. revision: yes
Circularity Check
No circularity; SAM framework and optimizations are presented as independent proposals evaluated on external benchmarks.
full rationale
The paper introduces State-Adaptive Memory (SAM) as a standalone framework that consolidates interaction histories into memory cues optimized via expert-guided supervision and reinforcement learning, then evaluates it empirically across BrowseComp, BrowseComp-ZH, WideSearch, and HLE on diverse agent backbones. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on benchmark outperformance rather than any derivation that reduces to its own inputs by construction. This is the expected non-finding for an empirical systems paper whose validity is tested externally.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Arbor combines a coordinator, executors, and a hypothesis tree to enable cumulative autonomous research, outperforming Codex and Claude Code by over 2.5x on six real tasks and reaching 86.36% Any Medal on MLE-Bench Lite.
Reference graph
Works this paper leans on
-
[1]
Atkinson and Richard M
Richard C. Atkinson and Richard M. Shiffrin. Human memory: A proposed system and its control processes. In Kenneth W. Spence and Janet Taylor Spence, editors,Psychology of Learning and Motivation, Psychology of Learning and Motivation, pages 89–195. Elsevier, 1968
1968
-
[2]
Guoxin Chen, Zile Qiao, Xuanzhong Chen, Donglei Yu, Haotian Xu, Wayne Xin Zhao, Ruihua Song, Wenbiao Yin, Huifeng Yin, Liwen Zhang, Kuan Li, Minpeng Liao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Iterresearch: Rethinking long-horizon agents via markovian state reconstruction.CoRR, abs/2511.07327, 2025
-
[3]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
2025
-
[4]
Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, and Siheng Chen. Openseeker: Democratizing frontier search agents by fully open-sourcing training data.CoRR, abs/2603.15594, 2026. 10
-
[5]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. Lightmem: Lightweight and efficient memory-augmented generation.CoRR, abs/2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zhaopeng Feng, Liangcai Su, Zhen Zhang, Xinyu Wang, Xiaotian Zhang, Xiaobin Wang, Run- nan Fang, Qi Zhang, Baixuan Li, Shihao Cai, Rui Ye, Hui Chen, Yong Jiang, Joey Tianyi Zhou, Chenxiong Qian, Pengjun Xie, Bryan Hooi, Zuozhu Liu, and Jingren Zhou. Agentswing: Adap- tive parallel context management routing for long-horizon web agents.CoRR, abs/2603.27490, 2026
-
[7]
Hipporag: Neurobiologically inspired long-term memory for large language models
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on N...
2024
-
[8]
Yuyang Hu, Jiongnan Liu, Jiejun Tan, Yutao Zhu, and Zhicheng Dou. Memory matters more: Event-centric memory as a logic map for agent searching and reasoning.CoRR, abs/2601.04726, 2026
-
[9]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.CoRR, abs/2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. ACON: optimizing context compression for long-horizon LLM agents.CoRR, abs/2510.00615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
A survey of frontiers in LLM reasoning: Inference scaling, learning to reason, and agentic systems.Trans
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. A survey of frontiers in LLM reasoning: Inference scaling, learning to reason, and agentic systems.Trans. Mach. Learn. Res., 2025, 2025
2025
-
[13]
WebSailor: Navigating Super-human Reasoning for Web Agent
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. Websailor: Navigating super-human reasoning for web agent.CoRR, abs/2507.02592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Deepagent: A general reasoning agent with scalable toolsets
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, Guanting Dong, Jiajie Jin, Yinuo Wang, Hao Wang, Yutao Zhu, Ji-Rong Wen, Yuan Lu, and Zhicheng Dou. Deepagent: A general reasoning agent with scalable toolsets. In Hakim Hacid, Yoelle Maarek, Francesco Bonchi, Ido Guy, and Emine Yilmaz, editors,Proceedings of the ACM Web Conference 2026, WWW 2026, Dubai, United Arab E...
2026
-
[16]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability.CoRR, abs/2504.21776, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Zhuofeng Li, Dongfu Jiang, Xueguang Ma, Haoxiang Zhang, Ping Nie, Yuyu Zhang, Kai Zou, Jianwen Xie, Yu Zhang, and Wenhu Chen. Openresearcher: A fully open pipeline for long-horizon deep research trajectory synthesis.CoRR, abs/2603.20278, 2026
-
[18]
Shukai Liu, Jian Yang, Bo Jiang, Yizhi Li, Jinyang Guo, Xianglong Liu, and Bryan Dai. Context as a tool: Context management for long-horizon swe-agents.CoRR, abs/2512.22087, 2025
-
[19]
Xiaoyuan Liu, Tian Liang, Dongyang Ma, Deyu Zhou, Haitao Mi, Pinjia He, and Yan Wang. The pensieve paradigm: Stateful language models mastering their own context.CoRR, abs/2602.12108, 2026
-
[20]
Miao Lu, Weiwei Sun, Weihua Du, Zhan Ling, Xuesong Yao, Kang Liu, and Jiecao Chen. Scaling LLM multi-turn RL with end-to-end summarization-based context management.CoRR, abs/2510.06727, 2025
-
[21]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback.CoRR, abs/2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems.CoRR, abs/2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Sean Follmer, Jeff Han, Jürgen Steimle, and Nathalie Henry Riche, editors,Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST 2023, San Fra...
2023
-
[24]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Sum- mer Yue, Alexandr Wang, and Dan Hendrycks. Humanity’s last exam.CoRR, abs/2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Memobrain: Executive memory as an agentic brain for reasoning.CoRR, abs/2601.08079, 2026
Hongjin Qian, Zhao Cao, and Zheng Liu. Memobrain: Executive memory as an agentic brain for reasoning.CoRR, abs/2601.08079, 2026
-
[26]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems...
2023
-
[27]
Look back to reason forward: Revisitable memory for long-context LLM agents
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context LLM agents. CoRR, abs/2509.23040, 2025
-
[28]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing System...
2023
-
[29]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
-
[30]
MemSifter: Offloading LLM Memory Retrieval via Outcome-Driven Proxy Reasoning
Jiejun Tan, Zhicheng Dou, Liancheng Zhang, Yuyang Hu, Yiruo Cheng, and Ji-Rong Wen. Memsifter: Offloading LLM memory retrieval via outcome-driven proxy reasoning.CoRR, abs/2603.03379, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Sentence-anchored gist com- pression for long-context llms.CoRR, abs/2511.08128, 2025
Dmitrii Tarasov, Elizaveta Goncharova, and Andrey Kuznetsov. Sentence-anchored gist com- pression for long-context llms.CoRR, abs/2511.08128, 2025
-
[32]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024
2024
-
[33]
A survey on large language model based autonomous agents.Frontiers Comput
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers Comput. Sci., 18(6):186345, 2024
2024
-
[34]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.CoRR, abs/2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Widesearch: Benchmarking agentic broad info-seeking.CoRR, abs/2508.07999, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, Wenhao Huang, Yang Wang, and Ke Wang. Widesearch: Benchmarking agentic broad info-seeking.CoRR, abs/2508.07999, 2025
-
[36]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. Resum: Unlocking long-horizon search intelligence via context summarization.CoRR, abs/2509.13313, 2025
-
[37]
Yuan-An Xiao, Pengfei Gao, Chao Peng, and Yingfei Xiong. Improving the efficiency of LLM agent systems through trajectory reduction.CoRR, abs/2509.23586, 2025
-
[38]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: agentic memory for LLM agents.CoRR, abs/2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Grounding Agent Memory in Contextual Intent
Ruozhen Yang, Yucheng Jiang, Yueqi Jiang, Priyanka Kargupta, Yunyi Zhang, and Jiawei Han. Grounding agent memory in contextual intent.CoRR, abs/2601.10702, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[41]
OpenReview.net, 2023
2023
-
[42]
Agentfold: Long-horizon web agents with proactive context management
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, Pengjun Xie, Fei Huang, Siheng Chen, Jingren Zhou, and Yong Jiang. Agentfold: Long-horizon web agents with proactive context management. CoRR, abs/2510.24699, 2025
-
[43]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi-conv rl-based memory agent.CoRR, abs/2507.02259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Trans. Inf. Syst., 43(6):155:1–155:47, 2025
2025
-
[45]
McKee, Thomas Miconi, Zacharie Bugaud, Mick Van Gelderen, and Jed McCaleb
Yicong Zheng, Kevin L. McKee, Thomas Miconi, Zacharie Bugaud, Mick Van Gelderen, and Jed McCaleb. Goal-directed search outperforms goal-agnostic memory compression in long-context memory tasks.CoRR, abs/2511.21726, 2025
-
[46]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors,Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2...
2024
-
[47]
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, Yuxin Gu, Sixin Hong, Jing Ren, Jian Chen, Chao Liu, and Yining Hua. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese.CoRR, abs/2504.19314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: learning to synergize memory and reasoning for efficient long-horizon agents.CoRR, abs/2506.15841, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Latent Collaboration in Multi-Agent Systems
Jiaru Zou, Xiyuan Yang, Ruizhong Qiu, Gaotang Li, Katherine Tieu, Pan Lu, Ke Shen, Hang- hang Tong, Yejin Choi, Jingrui He, James Zou, Mengdi Wang, and Ling Yang. Latent collabora- tion in multi-agent systems.CoRR, abs/2511.20639, 2025. A Limitations and Broader Impact Limitations.In this work, we introduce SAM, a standalone memory framework for long-hori...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
The user’s goal, constraints, and preferences
-
[51]
Key facts established during the conversation
-
[52]
Tools used and the most important results from them
-
[53]
Partial conclusions, promising leads, and failed approaches
-
[54]
Open questions, uncertainties, and what still needs to be done next. When relevant, include filenames, URLs, document names, entities, dates, parameters already examined, specific findings from tool outputs, decisions already made and why, and unresolved blockers or ambiguities. Requirements: Be concise but information-dense. Be factual and do not invent ...
-
[55]
Preserve important facts, findings, dates, names, and evidence when present
Keep only information that is directly relevant to the research goal. Preserve important facts, findings, dates, names, and evidence when present
-
[56]
Do not drop previously established key information unless it is contradicted or irrelevant
Incorporate prior extracted results when provided. Do not drop previously established key information unless it is contradicted or irrelevant
-
[57]
Add important new information from the current page, while avoiding repetition
-
[58]
Distinguish clearly between confirmed information and uncertain or incomplete information
-
[59]
Be concise, factual, and information-dense
-
[60]
Limitations
Output only the extracted information and summary. User template. Research goal: {goal} Previous extracted results: {previous_summary} Current page: {page_content} Integrate the previous results with the current page, keeping only information relevant to the goal. Output only the updated extracted information and summary. G Use of LLMs in Writing Aside fr...
-
[61]
Guidelines: • The answer NA means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.