AgentFugue: Agent Scaling for Long-Horizon Tasks through Collective Reasoning
Pith reviewed 2026-06-30 13:26 UTC · model grok-4.3
The pith
A shared reasoning hub lets multiple peer agents turn parallel explorations into reusable intermediate results for long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
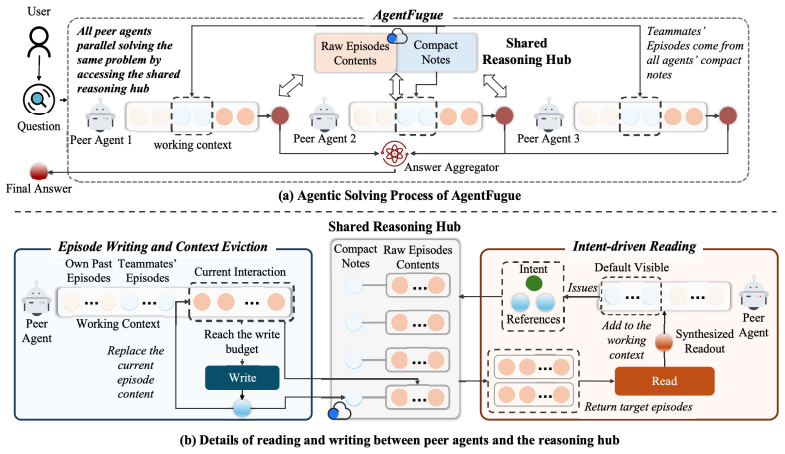
AgentFugue is a collective reasoning framework built around a shared reasoning hub. As peer agents explore the same task in parallel, the hub records concise notes on what each agent has established, attempted, or ruled out and enables each agent to selectively access what other agents have discovered in a form useful for its current search. This turns otherwise isolated trajectories into a connected ecology of reusable intermediate reasoning without requiring centralized planning. The hub is instantiated as a plug-in communication layer trained with supervised fine-tuning and end-to-end reinforcement learning. Across the challenging long-horizon settings studied, AgentFugue improves over st
What carries the argument
The shared reasoning hub, a plug-in layer that records concise notes from each peer agent and surfaces them for selective access by others.
If this is right
- Peer agents can access and build on non-redundant intermediate results from one another without explicit role assignments.
- Scaling the number of peer agents becomes a source of capability improvement distinct from scaling individual model size or tools.
- The approach functions as an add-on layer that does not require redesigning the underlying agent scaffolding or workflow.
- Training the hub with a mix of supervised fine-tuning and reinforcement learning suffices to produce useful note recording and retrieval.
Where Pith is reading between the lines
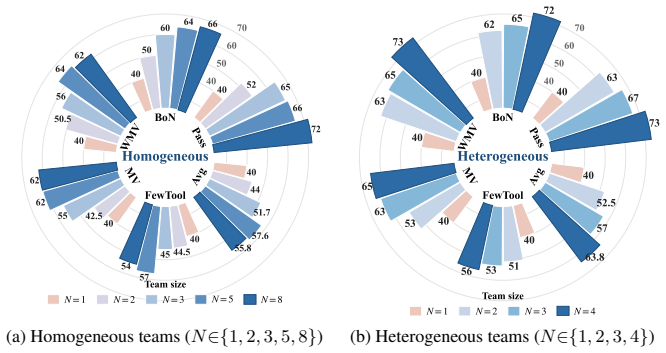
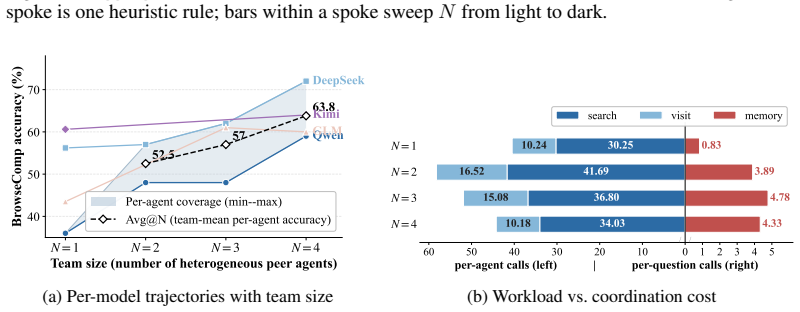
- The same hub design could be tested on tasks outside the studied long-horizon settings to see whether the collective benefit generalizes.
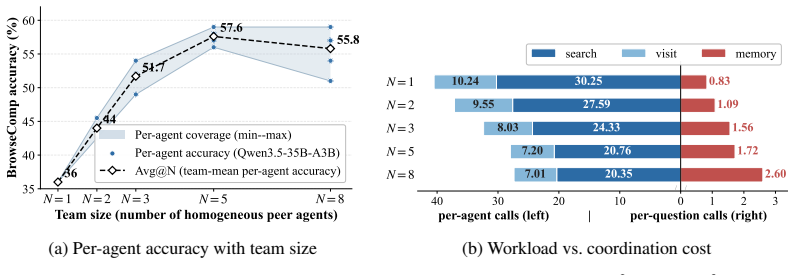
- Varying the number of peer agents while measuring the marginal gain per added agent would clarify how the sharing mechanism scales.
- If the hub can be made to work across different base agents, it would support treating multi-agent systems as reusable ecologies rather than one-off ensembles.
Load-bearing premise
That performance gains arise from the collective sharing mechanism itself rather than from simply running more agents and therefore using more total compute.
What would settle it
A controlled comparison that holds total compute fixed while removing the hub's note-recording and sharing function, then checks whether the multi-agent performance advantage disappears.
Figures
read the original abstract
Recent progress on long-horizon agentic tasks has been driven largely by scaling up individual agents through stronger models, better tools, and more effective scaffolding. In contrast, much less is understood about scaling out: whether multiple peer agents, all targeting the same task, can become an additional source of capability without relying on explicit role specialization or workflow orchestration. We study this question and propose AgentFugue, a collective reasoning framework built around a shared reasoning hub. As peer agents explore the same task in parallel, the hub records concise notes on what each agent has established, attempted, or ruled out, and enables each agent to selectively access what other agents have discovered in a form useful for its current search. This design turns otherwise isolated trajectories into a connected ecology of reusable intermediate reasoning without requiring centralized planning. We instantiate the hub as a plug-in communication layer, trained with supervised fine-tuning and end-to-end reinforcement learning. Across the challenging long-horizon settings we study, AgentFugue improves over strong baselines. Our results suggest that collective reasoning can turn scaling out peer agent systems into a distinct source of capability gains, rather than merely a way of spending more compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AgentFugue, a collective reasoning framework for scaling out peer agents on long-horizon tasks. Peer agents run in parallel on the same task; a shared reasoning hub records concise notes on what each has established, attempted, or ruled out and enables selective access to non-redundant intermediates. The hub is instantiated as a plug-in layer trained via supervised fine-tuning followed by end-to-end reinforcement learning. The paper claims that this architecture yields improvements over strong baselines in the studied settings and that collective reasoning constitutes a distinct source of capability gains beyond additional compute.
Significance. If the empirical claims hold under proper controls, the work would identify a new, orthogonal axis for agent scaling—collective reuse of intermediate reasoning—distinct from both single-agent model scaling and explicit multi-agent orchestration. This could meaningfully expand the design space for long-horizon agent systems.
major comments (2)
- [Abstract] Abstract: the claim that AgentFugue “improves over strong baselines” and that gains arise from collective reasoning rather than increased compute is unsupported by any reported metrics, statistical tests, ablation results, or experimental details. Without these, the central attribution cannot be evaluated.
- [Results / Experimental Setup (missing)] No section describes a compute-matched baseline that runs the same number K of peer agents with identical total token budget but without the hub, nor an ablation that disables selective access while holding communication volume constant. These controls are load-bearing for the claim that observed gains are due to the shared reasoning hub rather than extra inference steps.
minor comments (1)
- The description of how the hub is trained (SFT then RL) and how selective access is implemented would benefit from an explicit algorithmic outline or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional experimental controls and clarity in the abstract would strengthen the attribution of gains to the shared reasoning hub. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AgentFugue “improves over strong baselines” and that gains arise from collective reasoning rather than increased compute is unsupported by any reported metrics, statistical tests, ablation results, or experimental details. Without these, the central attribution cannot be evaluated.
Authors: The abstract is a high-level summary of the work. The full manuscript reports quantitative results, including performance metrics across long-horizon tasks and comparisons against baselines, in the Results section. To improve self-containment and address the concern directly, we will revise the abstract to reference the key metrics, note the presence of ablations, and indicate that statistical details appear in the main text. revision: yes
-
Referee: [Results / Experimental Setup (missing)] No section describes a compute-matched baseline that runs the same number K of peer agents with identical total token budget but without the hub, nor an ablation that disables selective access while holding communication volume constant. These controls are load-bearing for the claim that observed gains are due to the shared reasoning hub rather than extra inference steps.
Authors: We agree these controls are necessary to isolate the contribution of the hub. In the revised version we will add (1) a compute-matched baseline in which K peer agents run without the hub but consume an identical total token budget and (2) an ablation that removes selective access while preserving the same communication volume (e.g., by broadcasting all notes). Both will be reported with the corresponding performance numbers. revision: yes
Circularity Check
No circularity; architectural proposal with empirical claims only
full rationale
The paper describes an architectural framework (shared reasoning hub trained via SFT + RL) and reports empirical improvements over baselines. No equations, fitted parameters presented as predictions, self-citational load-bearing premises, or reductions of claims to inputs by construction appear in the abstract or described content. The central claim is an empirical suggestion about collective reasoning gains, not a derivation that collapses to its own definitions or prior self-work. Per rules, absence of quoted self-referential steps yields score 0.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Arbor combines a coordinator, executors, and a hypothesis tree to enable cumulative autonomous research, outperforming Codex and Claude Code by over 2.5x on six real tasks and reaching 86.36% Any Medal on MLE-Bench Lite.
Reference graph
Works this paper leans on
-
[1]
Bradley C. A. Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.CoRR, abs/2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Chang, Andrew Drozdov, Shubham Toshniwal, Owen Oertell, Alexander Trott, Jacob P
Jonathan D. Chang, Andrew Drozdov, Shubham Toshniwal, Owen Oertell, Alexander Trott, Jacob P. Portes, Abhay Gupta, Pallavi Koppol, Ashutosh Baheti, Sean Kulinski, Ivan Zhou, Irene Dea, Krista Opsahl-Ong, Simon Favreau-Lessard, Sean Owen, Jose Javier Gonzalez Ortiz, Arnav Singhvi, Xabi Andrade, Cindy Wang, Kartik Sreenivasan, Sam Havens, Jialu Liu, Peyton ...
-
[3]
Iterresearch: Rethinking long-horizon agents with interaction scaling, 2026
Guoxin Chen, Zile Qiao, Xuanzhong Chen, Donglei Yu, Haotian Xu, Wayne Xin Zhao, Ruihua Song, Wenbiao Yin, Huifeng Yin, Liwen Zhang, Kuan Li, Minpeng Liao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Iterresearch: Rethinking long-horizon agents with interaction scaling, 2026
2026
-
[4]
Reconcile: Round-table conference improves reasoning via consensus among diverse llms
Justin Chih-Yao Chen, Swarnadeep Saha, and Mohit Bansal. Reconcile: Round-table conference improves reasoning via consensus among diverse llms. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16,...
2024
-
[5]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InThe Twelfth International Conference on Learning Representations, ICLR 202...
2024
-
[6]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. In Inês Lynce, Nello Murano, Mauro Vallati, Serena Villata, Federico Chesani, Michela Milano, Andrea Omicini, and Mehdi Dastani, editors,ECAI 2025 - 28th European Conference on Artificial Intelligence, 25-...
2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, IC...
2024
-
[9]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. Lightmem: Lightweight and efficient memory-augmented generation.CoRR, abs/2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Zhaopeng Feng, Liangcai Su, Zhen Zhang, Xinyu Wang, Xiaotian Zhang, Xiaobin Wang, Run- nan Fang, Qi Zhang, Baixuan Li, Shihao Cai, Rui Ye, Hui Chen, Yong Jiang, Joey Tianyi Zhou, Chenxiong Qian, Pengjun Xie, Bryan Hooi, Zuozhu Liu, and Jingren Zhou. Agentswing: Adap- tive parallel context management routing for long-horizon web agents.CoRR, abs/2603.27490, 2026
-
[11]
Metagpt: Meta programming for A multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for A multi-agent collaborative framework. InThe Twelfth International Conference on Learning Representations, ICL...
2024
-
[12]
Yuyang Hu, Jiongnan Liu, Jiejun Tan, Yutao Zhu, and Zhicheng Dou. Memory matters more: Event-centric memory as a logic map for agent searching and reasoning.CoRR, abs/2601.04726, 2026
-
[13]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Qingwen Bu, Jie M. Zhang, Michael Luck, and Heming Cui. Agentcoder: Multi- agent-based code generation with iterative testing and optimisation.CoRR, abs/2312.13010, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.CoRR, abs/2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Flashrag: A modular toolkit for efficient retrieval-augmented generation research
Jiajie Jin, Yutao Zhu, Zhicheng Dou, Guanting Dong, Xinyu Yang, Chenghao Zhang, Tong Zhao, Zhao Yang, and Ji-Rong Wen. Flashrag: A modular toolkit for efficient retrieval-augmented generation research. In Guodong Long, Michale Blumestein, Yi Chang, Liane Lewin-Eytan, Zi Helen Huang, and Elad Yom-Tov, editors,Companion Proceedings of the ACM on Web Confere...
2025
-
[17]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orl...
2022
-
[18]
Agentic aggregation for parallel scaling of long-horizon agentic tasks, 2026
Yoonsang Lee, Howard Yen, Xi Ye, and Danqi Chen. Agentic aggregation for parallel scaling of long-horizon agentic tasks, 2026
2026
-
[19]
Tongyi DeepResearch Technical Report
Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhang, Zile Qiao, Chenxi Wang, Donglei Yu, Gang Fu, Haiyang Shen, Jiayi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Parallelmuse: Agentic parallel thinking for deep information seeking.CoRR, abs/2510.24698, 2025
Baixuan Li, Dingchu Zhang, Jialong Wu, Wenbiao Yin, Zhengwei Tao, Yida Zhao, Liwen Zhang, Haiyang Shen, Runnan Fang, Pengjun Xie, Jingren Zhou, and Yong Jiang. Parallelmuse: Agentic parallel thinking for deep information seeking.CoRR, abs/2510.24698, 2025
-
[21]
CAMEL: communicative agents for "mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: communicative agents for "mind" exploration of large language model society. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- matio...
2023
-
[22]
More agents is all you need
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. Trans. Mach. Learn. Res., 2024, 2024. 11
2024
-
[23]
WebSailor: Navigating Super-human Reasoning for Web Agent
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. Websailor: Navigating super-human reasoning for web agent.CoRR, abs/2507.02592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, ...
2025
-
[25]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yutao Zhu, Yongkang Wu, Ji-Rong Wen, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability.CoRR, abs/2504.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Encouraging divergent thinking in large language models through multi- agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agent debate. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024,...
2024
-
[27]
A dynamic llm-powered agent network for task-oriented agent collaboration, 2024
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic llm-powered agent network for task-oriented agent collaboration, 2024
2024
-
[28]
Courier Corporation, 1987
Alfred Mann.The Study of Fugue. Courier Corporation, 1987
1987
-
[29]
Candès, and Tatsunori Hashimoto
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel J. Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural ...
2025
-
[30]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback.CoRR, abs/2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Introducing deep research
OpenAI. Introducing deep research. https://openai.com/index/ introducing-deep-research/, February 2025. Accessed: 2026-05-06
2025
-
[33]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Sy...
2024
-
[34]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Sum- mer Yue, Alexandr Wang, and Dan Hendrycks. Humanity’s last exam.CoRR, abs/2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Learning to reason across parallel samples for LLM reasoning.CoRR, abs/2506.09014, 2025
Jianing Qi, Xi Ye, Hao Tang, Zhigang Zhu, and Eunsol Choi. Learning to reason across parallel samples for LLM reasoning.CoRR, abs/2506.09014, 2025. 12
-
[36]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. Chatdev: Communicative agents for software development. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Li...
2024
-
[37]
Scaling large language model- based multi-agent collaboration
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model- based multi-agent collaboration. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[38]
Memobrain: Executive memory as an agentic brain for reasoning.CoRR, abs/2601.08079, 2026
Hongjin Qian, Zhao Cao, and Zheng Liu. Memobrain: Executive memory as an agentic brain for reasoning.CoRR, abs/2601.08079, 2026
-
[39]
Zile Qiao, Guoxin Chen, Xuanzhong Chen, Donglei Yu, Wenbiao Yin, Xinyu Wang, Zhen Zhang, Baixuan Li, Huifeng Yin, Kuan Li, Rui Min, Minpeng Liao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Webresearcher: Unleashing unbounded reasoning capability in long-horizon agents.CoRR, abs/2509.13309, 2025
-
[40]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. InThe Twelfth International Conference on Learning...
2024
-
[41]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems...
2023
-
[42]
Hugginggpt: Solving AI tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving AI tasks with chatgpt and its friends in hugging face. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Proce...
2023
-
[43]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing System...
2023
-
[44]
Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[45]
OpenReview.net, 2025
2025
-
[46]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, and Jiecao Chen. Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
-
[47]
Memsifter: Offloading llm memory retrieval via outcome-driven proxy reasoning, 2026
Jiejun Tan, Zhicheng Dou, Liancheng Zhang, Yuyang Hu, Yiruo Cheng, and Ji-Rong Wen. Memsifter: Offloading llm memory retrieval via outcome-driven proxy reasoning, 2026
2026
-
[48]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi K2.5: visual agentic intelligence.CoRR, abs/2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Llama Team. The llama 3 herd of models.CoRR, abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024
2024
-
[52]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[53]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
2023
-
[54]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria...
2024
-
[55]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[56]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.CoRR, abs/2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neura...
2022
-
[58]
Widesearch: Benchmarking agentic broad info-seeking.CoRR, abs/2508.07999, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, Wenhao Huang, Yang Wang, and Ke Wang. Widesearch: Benchmarking agentic broad info-seeking.CoRR, abs/2508.07999, 2025
-
[59]
Webdancer: Towards autonomous information seeking agency.CoRR, abs/2505.22648, 2025
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Webdancer: Towards autonomous information seeking agency.CoRR, abs/2505.22648, 2025
-
[60]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversation framework.CoRR, abs/2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. Resum: Unlocking long-horizon search intelligence via context summarization.CoRR, abs/2509.13313, 2025
-
[62]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: agentic memory for LLM agents.CoRR, abs/2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Inf...
2023
-
[64]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[65]
OpenReview.net, 2023
2023
-
[66]
Agentfold: Long-horizon web agents with proactive context management
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, Pengjun Xie, Fei Huang, Siheng Chen, Jingren Zhou, and Yong Jiang. Agentfold: Long-horizon web agents with proactive context management. CoRR, abs/2510.24699, 2025
-
[67]
Aflow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation. InThe Thirteenth International Confer- ence on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[68]
The majority is not always right: RL training for solution aggregation.CoRR, abs/2509.06870, 2025
Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, and Ilia Kulikov. The majority is not always right: RL training for solution aggregation.CoRR, abs/2509.06870, 2025
-
[69]
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language P...
2025
-
[70]
Failure Map
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024...
2024
-
[71]
Built in 1800s -- convict labor began late 1870s (could count as 1800s, even if main building was 1932)
1932
-
[72]
City has a university --Sugar Land doesn’t have a university, but Texas A&M is nearby (∼30 mi)
-
[73]
Enrollment 75k-80k -- Wikipedia showed 74,829 / 77,491 (close to range)
-
[74]
Two wars --unclear but suggested
-
[75]
some sources say 111k-118k, official city says 84k-87k (conflicting)
City population 100k-125k -- “some sources say 111k-118k, official city says 84k-87k (conflicting)”
-
[76]
conflicting
5-year increase 5k-10k -- “conflicting.” Exact Answer:Texas Prison System Central State Farm Main Building (Central Unit), Sugar Land, Texas Confidence: 65%(gold answer: Fort Henry) Take-away.Shared memory faithfully recorded both the unique positive lead and the disqualifying evidence, but the compressed summary made the local uniqueness of one clue more...
-
[77]
The user’s goal, constraints, and preferences
-
[78]
Key facts established during the conversation
-
[79]
Tools used and the most important results from them
-
[80]
Partial conclusions, promising leads, and failed approaches
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.