Market Regime Council for Dynamic Credit Assignment in Multi-Agent LLM Decision Systems
Pith reviewed 2026-06-30 13:20 UTC · model grok-4.3
The pith
Market Regime Council assigns exact Shapley credits across agent coalitions for online LLM portfolio weighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
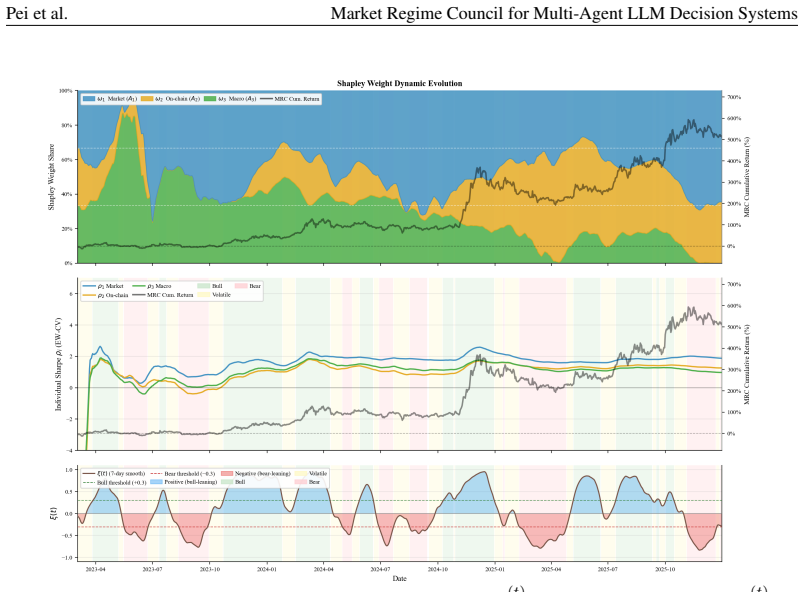
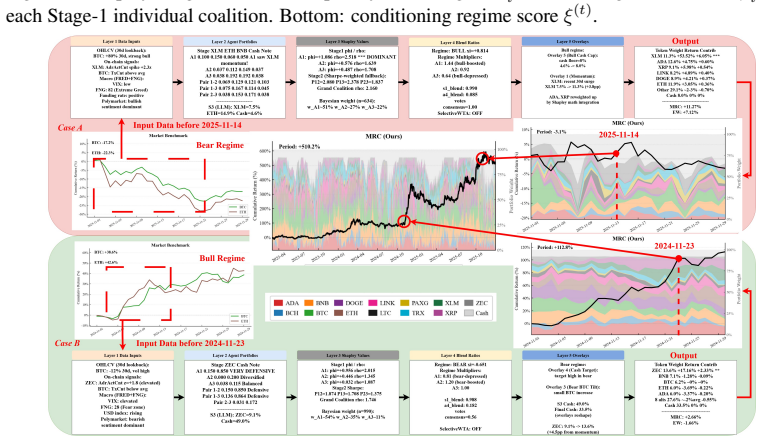
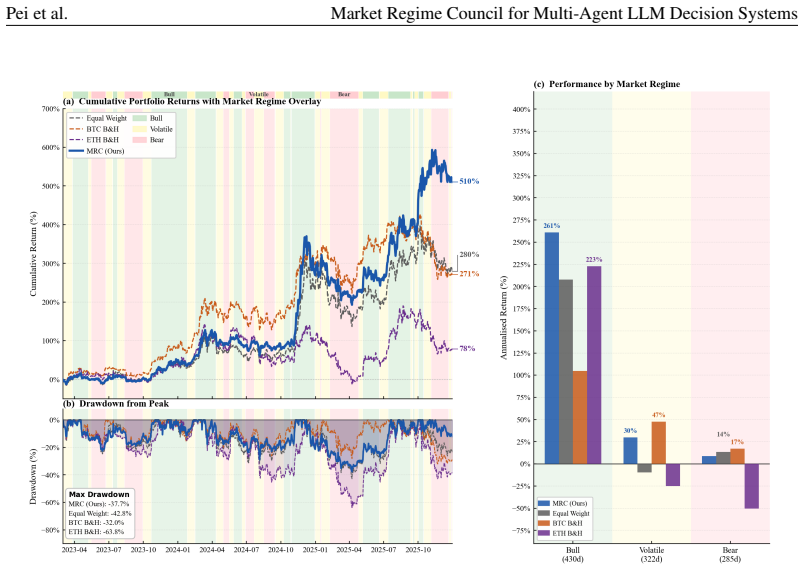
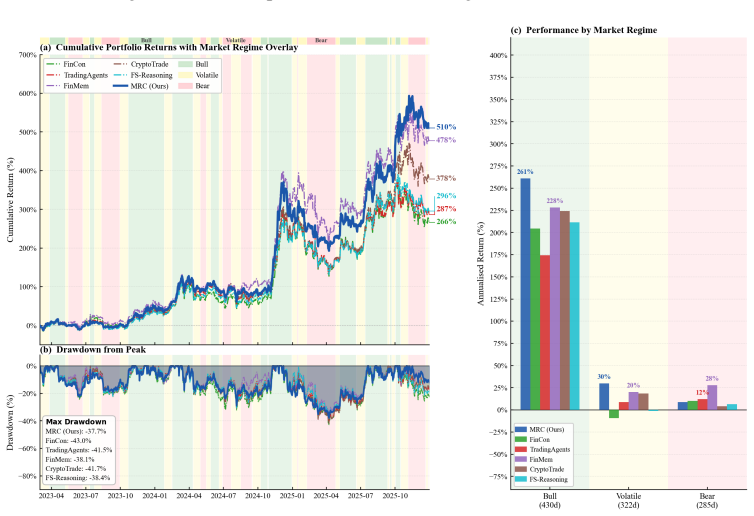
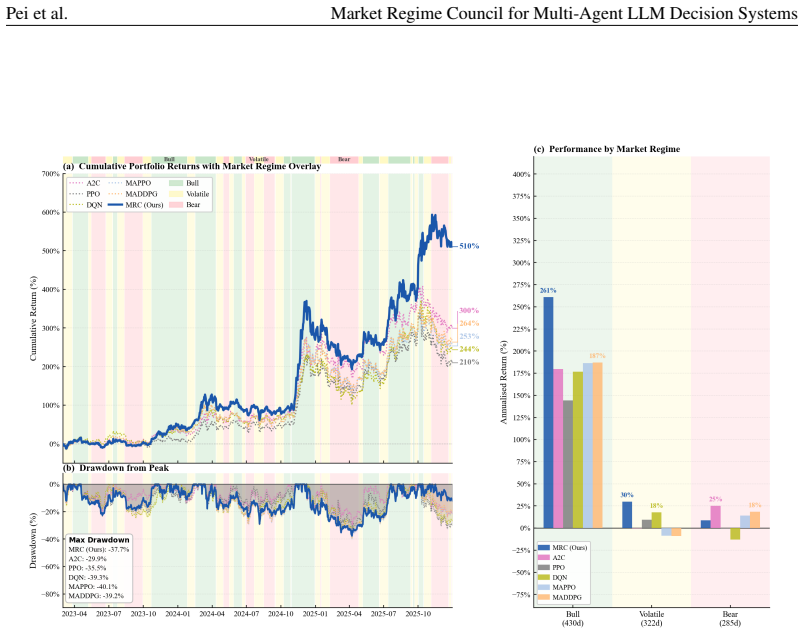
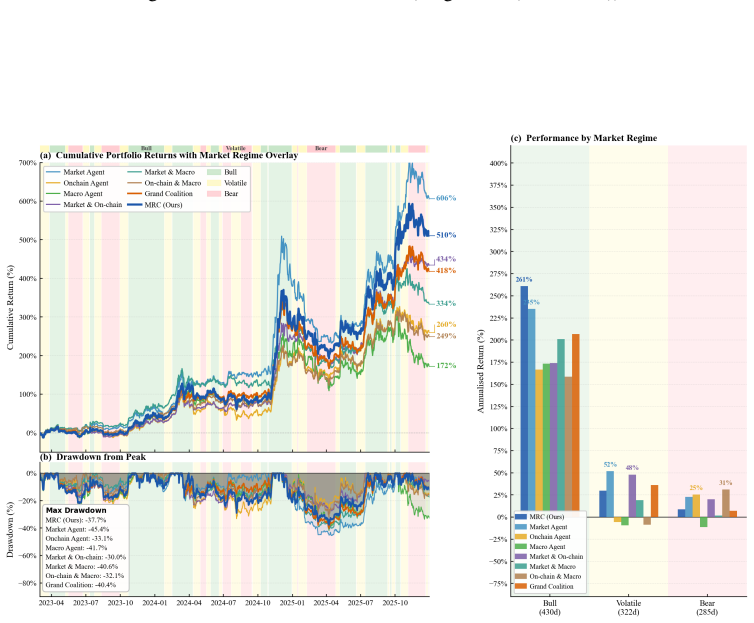
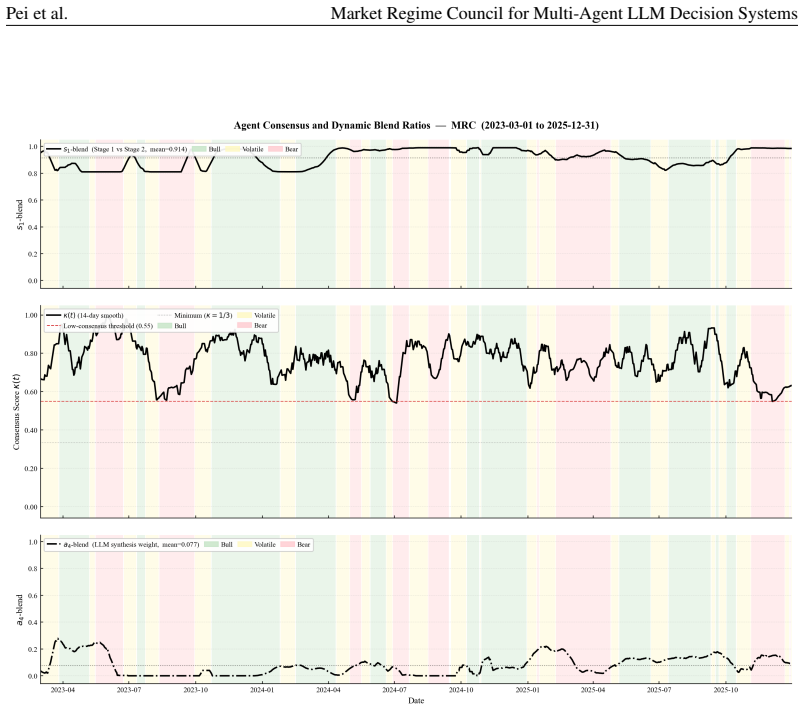
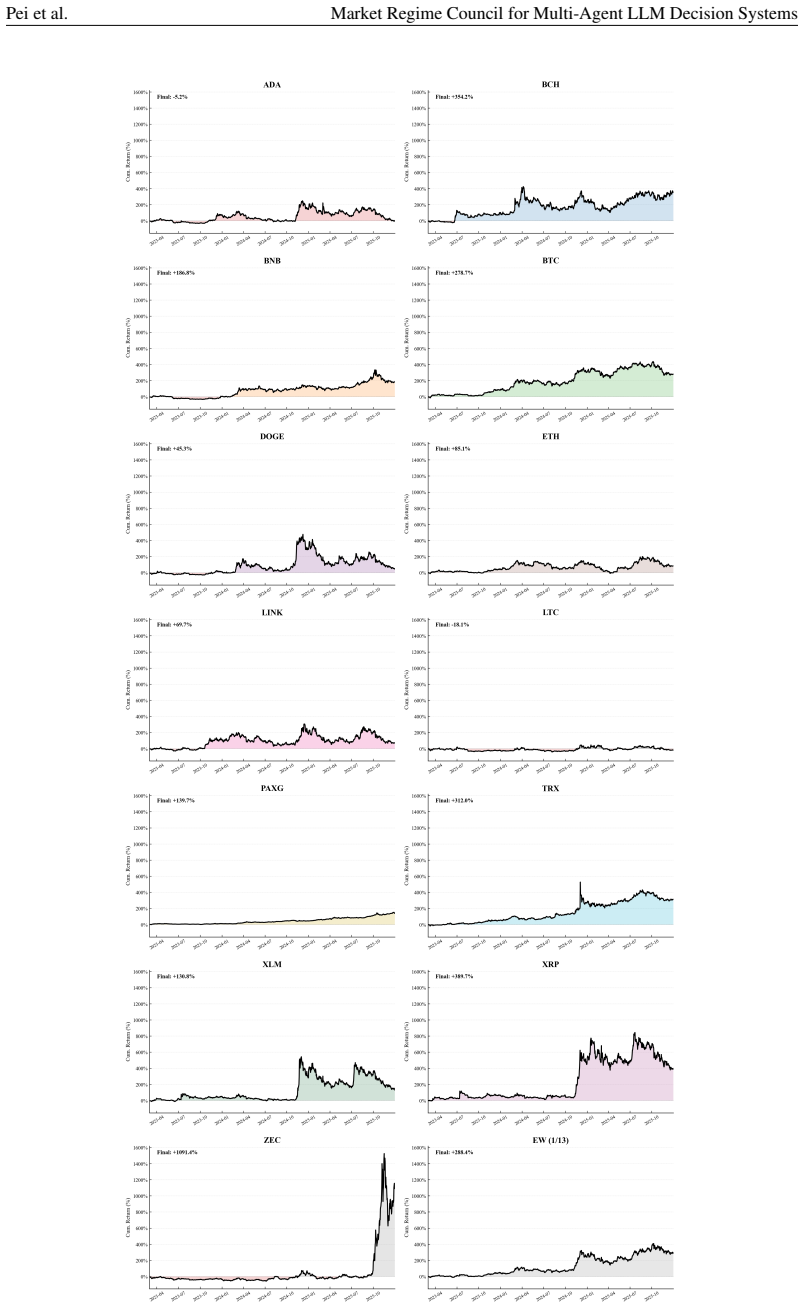
MRC computes exact Shapley credits across single, pairwise, and Grand-coalition outputs for online agent weighting, using exponentially weighted performance histories, a Bayesian adaptive mixture to stabilize early periods, and regime-dependent multipliers; instantiated with three specialist agents it records each rebalance through a five-layer causal trace and, over 1,037 trading days on 13 crypto assets, attains a Sharpe ratio of 1.51 and 440.1 percent cumulative return while ranking first on cumulative return, Sharpe ratio, and information ratio among active baselines and lowest maximum drawdown among active methods.
What carries the argument
Shapley value calculation over all coalition outputs to derive exact marginal contributions that determine agent weights at each rebalance.
Load-bearing premise
Exponentially weighted historical performance and the chosen regime-dependent multipliers will continue to produce accurate marginal contributions and stable weights when applied to future unseen market regimes and asset sets.
What would settle it
A forward test on new trading days after the study window in which MRC no longer ranks first on Sharpe ratio or cumulative return among the same active baselines.
Figures


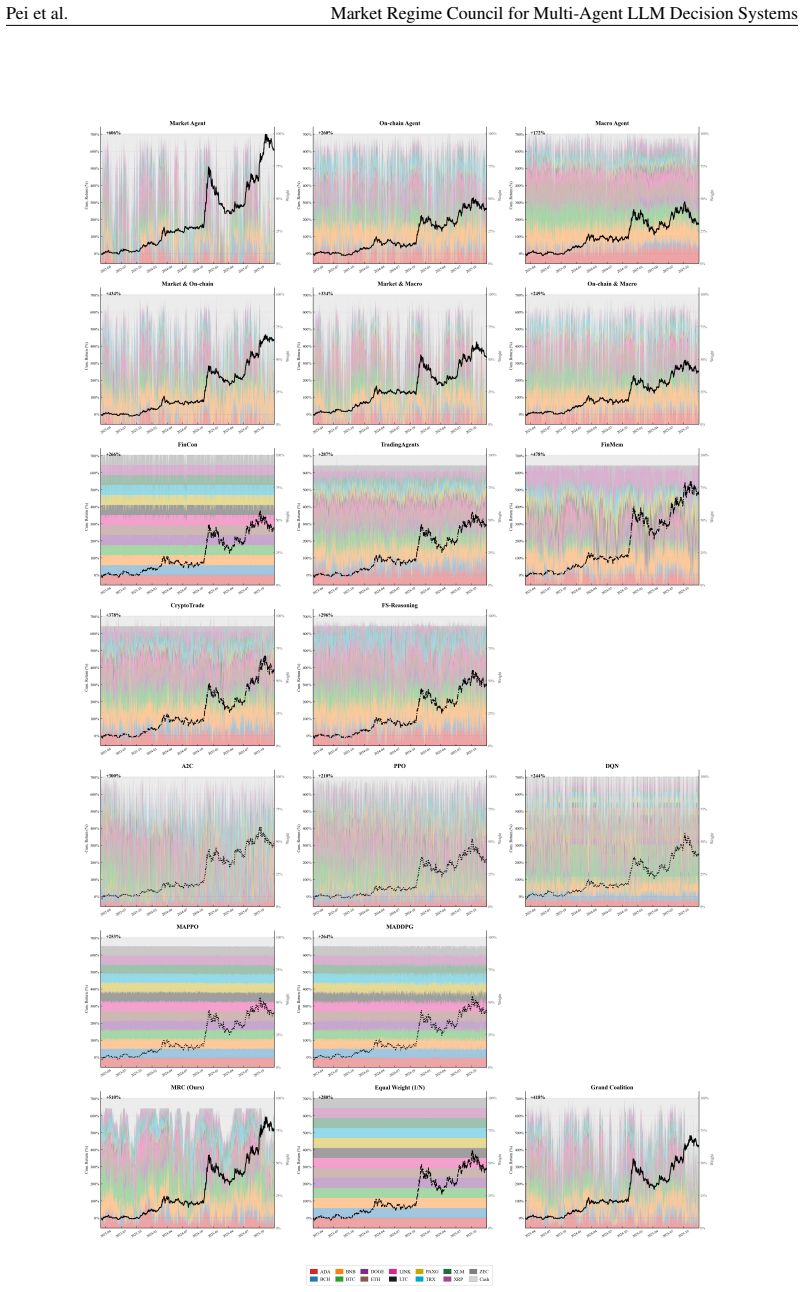
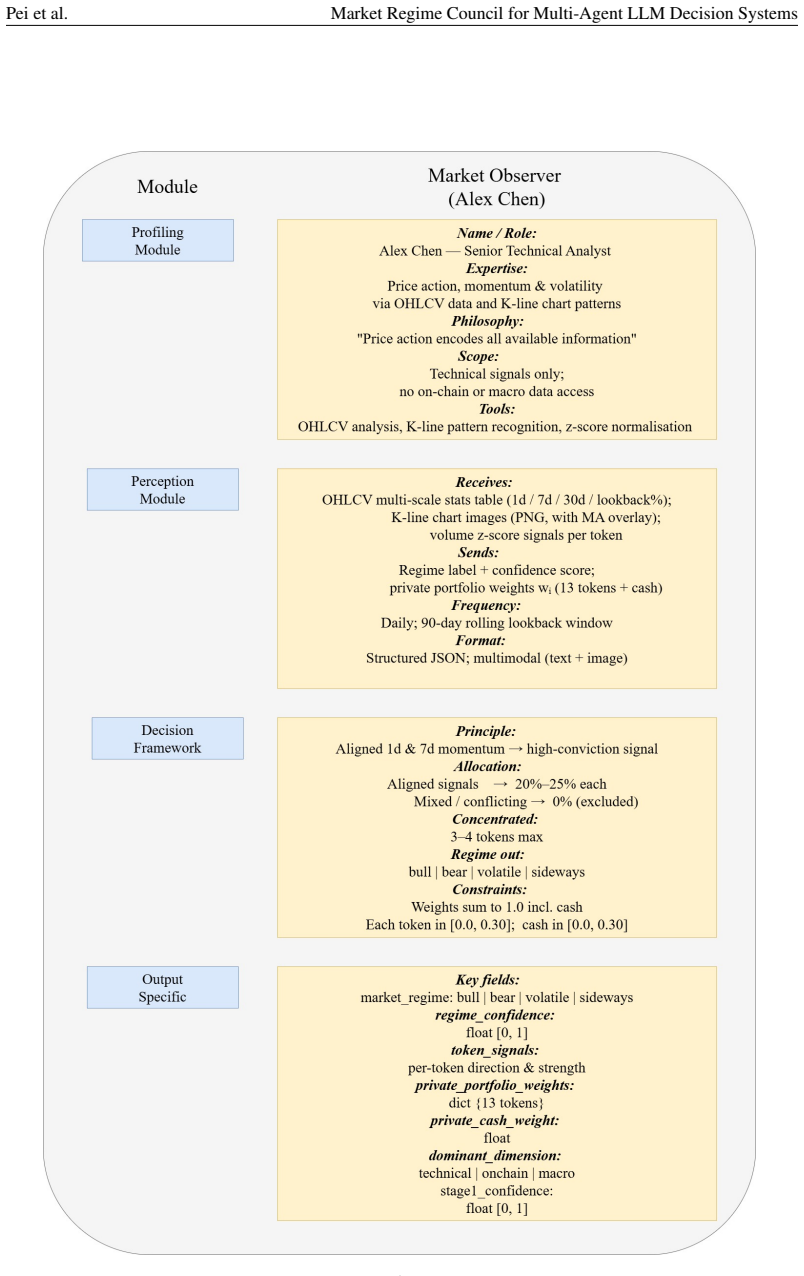

read the original abstract
Multi-agent LLM decision systems for portfolio management still lack a principled way to assign credit across specialist agents, remain vulnerable to cold-start dominance under regime shifts, and offer limited transparency into how final allocations are formed. We propose Market Regime Council (MRC), a cooperative multi-agent decision system that computes exact Shapley credits across all single, pairwise, and Grand-coalition outputs for online agent weighting. Instantiated with N=3 specialist agents, at each trading period, MRC recomputes coalition-based Shapley weights from exponentially weighted performance histories, uses a Bayesian adaptive mixture to stabilize early periods, applies regime-dependent multipliers to adjust agent authority, and records each rebalance through a five-layer causal trace. Over 1,037 trading days across 13 crypto assets and five seeds, MRC achieves a Sharpe ratio of 1.51 and a cumulative return of 440.1%, ranking first on CR, SR, and IR among active baselines and attaining the lowest MDD among active methods. Ablation results show that the gains come from Shapley-weighted integration across coalition outputs rather than from any single stage in isolation. Code and demo data are included in the supplementary material.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Market Regime Council (MRC), a cooperative multi-agent LLM system for portfolio management that assigns credit via exact Shapley values computed over single, pairwise, and grand-coalition outputs. At each period it recomputes weights from exponentially weighted performance histories, applies a Bayesian adaptive mixture for early stabilization, and modulates authority with regime-dependent multipliers while logging a five-layer causal trace. On 1,037 trading days across 13 crypto assets and five seeds, MRC reports a Sharpe ratio of 1.51 and cumulative return of 440.1 %, ranking first among active baselines on CR, SR, and IR and lowest MDD; ablations attribute gains to the Shapley integration step. Code and demo data are supplied.
Significance. If the performance claims survive rigorous out-of-sample and cross-regime validation, MRC would supply a concrete, auditable mechanism for dynamic credit assignment in multi-agent LLM decision systems, directly addressing cold-start and regime-shift problems. The provision of code and data is a clear strength that enables direct reproduction and extension.
major comments (2)
- [Method and Experimental Results] The central performance claim (SR 1.51, CR 440.1 % over 1,037 days) rests on regime-dependent multipliers and exponentially weighted Shapley credits, yet the manuscript provides no description of how market regimes are detected, labeled, or validated out-of-sample; without this, it is impossible to determine whether the multipliers are fitted to the same regime sequence used for evaluation.
- [Method] Weights are derived directly from the same performance histories that enter the final return calculation; the text does not specify walk-forward validation, parameter tuning protocol, or hold-out regime labeling, leaving open the possibility that the reported ranking versus baselines is partly an artifact of in-sample fitting rather than a property of the credit-assignment rule.
minor comments (1)
- [Ablation Study] The abstract states that ablation results isolate the contribution of Shapley-weighted integration, but the main text should include a table or figure that quantifies each component's marginal effect with the same five-seed protocol.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying areas where additional methodological detail is required. We address each major comment below and will revise the manuscript to improve transparency on regime handling and validation procedures.
read point-by-point responses
-
Referee: [Method and Experimental Results] The central performance claim (SR 1.51, CR 440.1 % over 1,037 days) rests on regime-dependent multipliers and exponentially weighted Shapley credits, yet the manuscript provides no description of how market regimes are detected, labeled, or validated out-of-sample; without this, it is impossible to determine whether the multipliers are fitted to the same regime sequence used for evaluation.
Authors: We agree that the manuscript currently lacks an explicit description of the market regime detection, labeling, and out-of-sample validation procedures. This omission limits the ability to assess whether the regime multipliers introduce in-sample bias. In the revised manuscript we will add a dedicated subsection in the Methods section that specifies the regime identification algorithm, the market indicators and thresholds used for labeling, the temporal separation between regime estimation and performance evaluation, and the out-of-sample checks performed to confirm that multipliers are not fitted to the evaluation regime sequence. revision: yes
-
Referee: [Method] Weights are derived directly from the same performance histories that enter the final return calculation; the text does not specify walk-forward validation, parameter tuning protocol, or hold-out regime labeling, leaving open the possibility that the reported ranking versus baselines is partly an artifact of in-sample fitting rather than a property of the credit-assignment rule.
Authors: The referee is correct that the manuscript does not currently detail the walk-forward validation protocol, hyperparameter tuning procedure, or hold-out regime labeling. Without these specifications it is difficult to rule out leakage. We will expand the Experimental Setup section to describe the rolling-window approach used for exponentially weighted histories, the separation of any parameter selection onto a distinct validation period, and confirmation that regime labeling was performed without access to future performance data. These additions will clarify that the reported ranking is attributable to the credit-assignment mechanism rather than fitting artifacts. revision: yes
Circularity Check
No circularity: empirical evaluation of weighting method does not reduce to input by construction
full rationale
The provided abstract and text describe a method that recomputes Shapley weights from exponentially weighted performance histories, applies Bayesian mixture and regime multipliers, then reports out-of-sample-style empirical metrics (SR 1.51, CR 440.1%) over 1,037 days with ablations. No equations are shown that equate the final portfolio returns directly to the input histories by definition, nor is any 'prediction' of performance claimed as a fitted quantity. No self-citations, uniqueness theorems, or ansatzes are invoked. The evaluation is presented as a standard empirical test of the credit-assignment procedure rather than a tautological restatement of its inputs; any concern about parameter tuning or regime labeling is an external generalization issue, not a reduction in the derivation chain itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Ang, J. Chen, and Y . Xing. Downside risk.The review of financial studies, 19(4):1191–1239, 2006
2006
-
[2]
A. B. Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. García, S. Gil-López, D. Molina, R. Benjamins, et al. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai.Information fusion, 58:82–115, 2020
2020
-
[3]
Beechey, T
D. Beechey, T. M. Smith, and Ö. ¸ Sim¸ sek. Explaining reinforcement learning with Shapley values. InInternational Conference on Machine Learning, pages 2003–2014. PMLR, 2023
2003
-
[4]
T. M. Cover. Universal portfolios.Mathematical finance, 1(1):1–29, 1991
1991
-
[5]
DeMiguel, L
V . DeMiguel, L. Garlappi, and R. Uppal. Optimal versus naive diversification: How inefficient is the 1/n portfolio strategy?The review of Financial studies, 22(5):1915–1953, 2009
1915
-
[6]
Towards A Rigorous Science of Interpretable Machine Learning
F. Doshi-Velez and B. Kim. Towards a rigorous science of interpretable machine learning.arXiv preprint arXiv:1702.08608, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch. Improving factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[8]
Freund and R
Y . Freund and R. E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences, 55(1):119–139, 1997
1997
-
[9]
R. C. Grinold and R. N. Kahn. Active portfolio management. 2000
2000
-
[10]
S. Gu, B. Kelly, and D. Xiu. Empirical asset pricing via machine learning.The Review of Financial Studies, 33(5):2223–2273, 2020
2020
-
[11]
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang. Large language model based multi-agents: a survey of progress and challenges. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8048–8057, 2024
2024
-
[12]
E. Hazan. Introduction to online convex optimization.Foundations and Trends in Optimization, 2(3-4):157–325, 2016
2016
-
[13]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, et al. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2023
2023
-
[14]
Hull.Risk management and financial institutions,+ Web Site, volume 733
J. Hull.Risk management and financial institutions,+ Web Site, volume 733. John Wiley & Sons, 2012
2012
-
[15]
Jadbabaie, A
A. Jadbabaie, A. Rakhlin, S. Shahrampour, and K. Sridharan. Online optimization: Competing with dynamic comparators. InArtificial Intelligence and Statistics, pages 398–406. PMLR, 2015. 10 Pei et al. Market Regime Council for Multi-Agent LLM Decision Systems
2015
-
[16]
J. Li, Y . Liu, W. Liu, S. Fang, L. Wang, C. Xu, and J. Bian. MarS: a financial market simulation engine powered by generative foundation model. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Y . Li, B. Luo, Q. Wang, N. Chen, X. Liu, and B. He. CryptoTrade: A reflective LLM-based agent to guide zero-shot cryptocurrency trading. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1094–1106, 2024
2024
-
[18]
X.-Y . Liu, H. Yang, Q. Chen, R. Zhang, L. Yang, B. Xiao, and C. D. Wang. FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance.Deep RL Workshop, NeurIPS 2020, 2020
2020
-
[19]
X.-Y . Liu, Z. Xia, J. Rui, J. Gao, H. Yang, M. Zhu, C. Wang, Z. Wang, and J. Guo. FinRL- Meta: Market environments and benchmarks for data-driven financial reinforcement learning. Advances in Neural Information Processing Systems, 35:1835–1849, 2022
2022
-
[20]
Longerstaey and M
J. Longerstaey and M. Spencer. RiskmetricsTM—technical document.Morgan Guaranty Trust Company of New York: New York, 51:54, 1996
1996
-
[21]
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
2017
-
[22]
S. M. Lundberg and S.-I. Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017
2017
-
[23]
Y . Luo, Y . Feng, J. Xu, P. Tasca, and Y . Liu. LLM-powered multi-agent system for automated crypto portfolio management.arXiv preprint arXiv:2501.00826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
T. Miller. Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
2019
-
[25]
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. Human-level control through deep rein- forcement learning.nature, 518(7540):529–533, 2015
2015
-
[26]
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
1928
-
[27]
Ottaviani and P
M. Ottaviani and P. Sørensen. Information aggregation in debate: who should speak first? Journal of Public Economics, 81(3):393–421, 2001
2001
-
[28]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[29]
why should i trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin. " why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016
2016
-
[30]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
L. S. Shapley et al. A value for n-person games. 1953
1953
-
[32]
W. F. Sharpe et al. The Sharpe ratio.Streetwise–the Best of the Journal of Portfolio Management, 3(3):169–85, 1998
1998
-
[33]
S. Shen, C. Ma, C. Li, W. Liu, Y . Fu, S. Mei, X. Liu, and C. Wang. RiskQ: risk-sensitive multi- agent reinforcement learning value factorization.Advances in Neural Information Processing Systems, 36:34791–34825, 2023. 11 Pei et al. Market Regime Council for Multi-Agent LLM Decision Systems
2023
-
[34]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36: 8634–8652, 2023
2023
-
[35]
J. Wang, Y . Zhang, Y . Gu, and T.-K. Kim. Shaq: Incorporating Shapley value theory into multi-agent q-learning.Advances in Neural Information Processing Systems, 35:5941–5954, 2022
2022
-
[36]
J. Wang, Y . Li, Y . Zhang, W. Pan, and S. Kaski. Open ad hoc teamwork with cooperative game theory. InInternational Conference on Machine Learning, volume 235 ofPMLR, pages 50902–50930, 2024. URLhttps://proceedings.mlr.press/v235/wang24an.html
2024
- [37]
-
[38]
Q. Wang, Y . Gao, Z. Tang, B. Luo, N. Chen, and B. He. Exploring llm cryptocurrency trading through fact-subjectivity aware reasoning. InProceedings of the ICLR 2025 Workshop on Advances in Financial AI, 2025
2025
-
[39]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[40]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, et al. AutoGen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[41]
S. Wu, O. Irsoy, S. Lu, V . Dabravolski, M. Dredze, S. Gehrmann, P. Kambadur, D. Rosen- berg, and G. Mann. Bloomberggpt: A large language model for finance.arXiv preprint arXiv:2303.17564, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [42]
-
[43]
Q. Xie, W. Han, Z. Chen, R. Xiang, X. Zhang, Y . He, M. Xiao, D. Li, Y . Dai, D. Feng, et al. FinBen: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024
2024
-
[44]
FinGPT: Open-source financial large lan- guage models,
H. Yang, X.-Y . Liu, and C. D. Wang. Fingpt: Open-source financial large language models. arXiv preprint arXiv:2306.06031, 2023. URL https://arxiv.org/abs/2306.06031. First official FinGPT paper; FinLLM Workshop at IJCAI 2023
- [45]
-
[46]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[47]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing reasoning and acting in language models. In11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[48]
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu. The surprising effectiveness of PPO in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
2022
-
[49]
Y . Yu, Z. Yao, H. Li, Z. Deng, Y . Jiang, Y . Cao, Z. Chen, J. W. Suchow, Z. Cui, R. Liu, et al. FinCon: A synthesized LLM multi-agent system with conceptual verbal reinforcement for enhanced financial decision making.Advances in Neural Information Processing Systems, 37: 137010–137045, 2024
2024
-
[50]
Y . Yu, H. Li, Z. Chen, Y . Jiang, Y . Li, J. W. Suchow, D. Zhang, and K. Khashanah. FinMem: A performance-enhanced LLM trading agent with layered memory and character design.IEEE Transactions on Big Data, 2025. 12 Pei et al. Market Regime Council for Multi-Agent LLM Decision Systems
2025
-
[51]
Yuzhe, Y
Y . Yuzhe, Y . Zhang, M. Wu, K. Zhang, Y . Zhang, H. Yu, Y . Hu, and B. Wang. TwinMarket: A scalable behavioral and social simulation for financial markets. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[52]
Zhang, L
W. Zhang, L. Zhao, H. Xia, S. Sun, J. Sun, M. Qin, X. Li, Y . Zhao, Y . Zhao, X. Cai, et al. A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist. InProceedings of the 30th acm sigkdd conference on knowledge discovery and data mining, pages 4314–4325, 2024
2024
-
[53]
conceptual signals
M. Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the 20th international conference on machine learning (icml-03), pages 928–936, 2003. 13 Pei et al. Market Regime Council for Multi-Agent LLM Decision Systems Appendix A Related Work A.1 LLM-based Multi-Agent Trading System LLM multi-agent systems for ...
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.