Adaptive Punishment for Cooperation in Mixed-Motive Games
Pith reviewed 2026-06-30 12:15 UTC · model grok-4.3
The pith
APC combines dynamic punishment probability with a reward-guided defection module to promote cooperation while cutting ineffective costs in mixed-motive games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
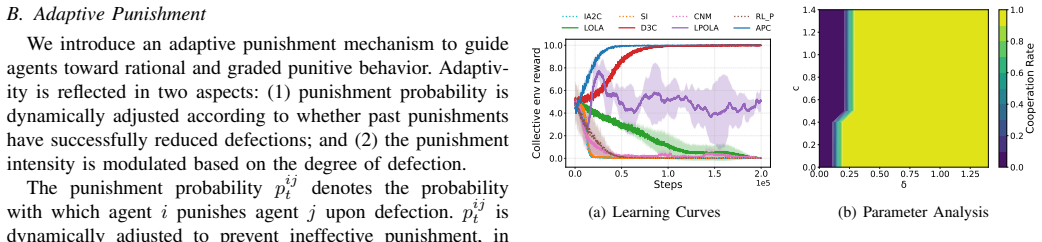
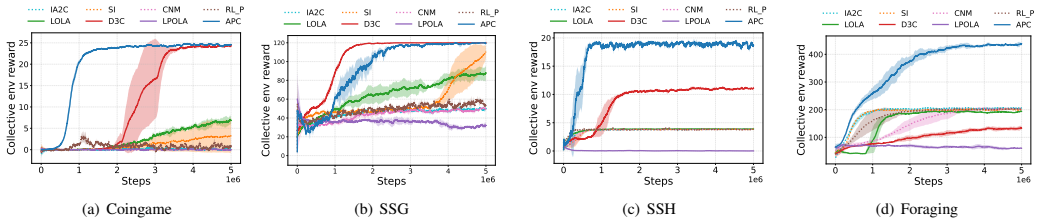
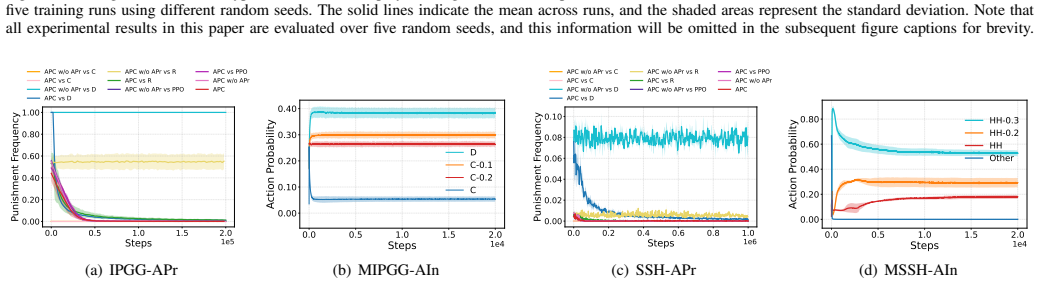
APC determines punishment intensity based on both a dynamic punishment probability and the severity of defection. This dynamic probability substantially reduces costly and ineffective punishment while also promotes cooperation. To accurately assess defection and its severity, we use a defection awareness module, whose learning is guided by game reward. Theoretical analysis and empirical results show APC performs effectively in iterated public goods game. Empirically, APC also significantly outperforms existing baselines across sequential social dilemmas, learning rational and effective punishment policies that foster cooperation by strategically deterring defection.
What carries the argument
Adaptive Punishment for Cooperation (APC), which sets punishment intensity via dynamic probability and a reward-guided defection awareness module.
If this is right
- In iterated public goods games APC sustains higher cooperation levels than fixed strategies.
- In sequential social dilemmas APC learns policies that deter defection without excessive cost to punishers.
- The combination of dynamic probability and severity assessment reduces second-order altruism costs while still enforcing cooperation.
- Agents under APC converge on rational punishment that targets only harmful defections.
Where Pith is reading between the lines
- The same adaptive logic could apply to real-world resource allocation problems where monitoring exact defection is noisy.
- If the reward signal used to train the awareness module is itself distorted, the entire punishment schedule may collapse.
- Extensions might test whether the same module structure works when agents have only partial observability of others' actions.
Load-bearing premise
The defection awareness module, trained on game rewards, can accurately judge the presence and severity of defection so that the dynamic probability actually cuts ineffective punishments.
What would settle it
An experiment in which disabling the defection awareness module or fixing the punishment probability at a constant value produces no gain in cooperation rates or total welfare over standard punishment baselines.
Figures

read the original abstract
Mixed-motive scenarios are ubiquitous in real-world multi-agent interactions, where self-interested agents often defect for immediate rewards, overlooking the potential of altruistic cooperation to improve long-term gains and collective welfare. Peer punishment can deter defection, but as costly second-order altruism, its persistent imposition may undermine the punisher's interests. Existing approaches often struggle to effectively implement punishment to promote cooperation. To balance the efficacy and cost of punishment, we propose Adaptive Punishment for Cooperation (APC), a distributed method that determines punishment intensity based on both a dynamic punishment probability and the severity of defection. This dynamic probability substantially reduces costly and ineffective punishment while also promotes cooperation. To accurately assess defection and its severity, we use a defection awareness module, whose learning is guided by game reward. Theoretical analysis and empirical results show APC performs effectively in iterated public goods game. Empirically, APC also significantly outperforms existing baselines across sequential social dilemmas, learning rational and effective punishment policies that foster cooperation by strategically deterring defection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Punishment for Cooperation (APC), a distributed multi-agent method for mixed-motive games. APC uses a defection awareness module whose learning is guided by game rewards to compute both a dynamic punishment probability and defection severity, thereby reducing costly punishment while deterring defection and promoting cooperation. The authors assert that theoretical analysis establishes effectiveness in the iterated public goods game and that empirical results show significant outperformance over baselines across sequential social dilemmas.
Significance. If the central claims hold, APC would supply a practical, reward-driven mechanism for adaptive second-order altruism in multi-agent reinforcement learning, with potential applicability to resource allocation and collective-action problems.
major comments (1)
- [Abstract] Abstract: the claim that the defection awareness module, trained only via game reward, can accurately assess both occurrence and severity of defection is load-bearing for the entire contribution. In iterated public goods games individual rewards are noisy aggregates of all agents' actions; the manuscript provides no derivation, ablation, or statistical test showing that reward signals suffice to disambiguate defection from simultaneous actions or stochastic payoffs. Without such evidence the dynamic punishment probability cannot be shown to systematically reduce ineffective punishment or to foster cooperation.
minor comments (2)
- [Abstract] Abstract: the phrase 'theoretical analysis' is used without any equation, key lemma, or result summary; a one-sentence statement of the main theoretical finding would improve clarity.
- The abstract asserts 'significantly outperforms existing baselines' yet supplies no information on the baselines, number of runs, error bars, or statistical tests; these details belong in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the defection awareness module. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the defection awareness module, trained only via game reward, can accurately assess both occurrence and severity of defection is load-bearing for the entire contribution. In iterated public goods games individual rewards are noisy aggregates of all agents' actions; the manuscript provides no derivation, ablation, or statistical test showing that reward signals suffice to disambiguate defection from simultaneous actions or stochastic payoffs. Without such evidence the dynamic punishment probability cannot be shown to systematically reduce ineffective punishment or to foster cooperation.
Authors: We agree that explicit evidence for the module's ability to disambiguate defection from noisy aggregate rewards is important. The theoretical analysis models expected rewards under the public goods structure and shows how reward-guided updates allow inference of defection, while the empirical results demonstrate reduced ineffective punishment and higher cooperation. However, the manuscript does not contain dedicated derivations, ablations, or statistical tests isolating this disambiguation step. We will add an ablation study together with statistical validation of the module's accuracy on occurrence and severity in the revised version. revision: yes
Circularity Check
No circularity; derivation self-contained with no reducible steps
full rationale
The provided abstract and context contain no equations, parameter-fitting descriptions, self-citations, or derivation chain that could be inspected for reduction to inputs. Claims of theoretical analysis and empirical outperformance are presented without any quoted mechanisms that match the enumerated circularity patterns (self-definitional, fitted-input prediction, etc.). Absent specific mathematical content or load-bearing self-references, the method description stands as an independent proposal rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scalable evaluation of multi-agent reinforcement learning with melting pot,
J. Z. Leibo, E. A. Du ´e˜nez-Guzm´an, A. Vezhnevets, J. P. Agapiou, P. Sunehag, R. Koster, J. Matyas, C. Beattie, I. Mordatch, and T. Graepel, “Scalable evaluation of multi-agent reinforcement learning with melting pot,” inProceedings of the 38th International Conference on Machine Learning, vol. 139, 2021, pp. 6187–6199
2021
-
[2]
Adasociety: An adaptive environment with social structures for multi-agent decision-making,
Y . Huang, X. Wang, H. Liu, F. Kong, A. Qin, M. Tang, X. Wang, S. Zhu, M. Bi, S. Qi, and X. Feng, “Adasociety: An adaptive environment with social structures for multi-agent decision-making,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, 2024
2024
-
[3]
Multi-agent actor-critic for mixed cooperative-competitive environ- ments,
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[4]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuylset al., “Value-decomposition networks for cooperative multi-agent learning,” arXiv preprint arXiv:1706.05296, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Costly punishment across human societies,
J. Henrich, R. McElreath, A. Barr, J. Ensminger, C. Barrett, A. Bolyanatz, J. C. Cardenas, M. Gurven, E. Gwako, N. Henrichet al., “Costly punishment across human societies,”Science, vol. 312, no. 5781, pp. 1767–1770, 2006
2006
-
[6]
Spurious normativity enhances learning of compliance and enforcement behavior in artificial agents,
R. K ¨oster, D. Hadfield-Menell, R. Everett, L. Weidinger, G. K. Hadfield, and J. Z. Leibo, “Spurious normativity enhances learning of compliance and enforcement behavior in artificial agents,”Proceedings of the National Academy of Sciences, vol. 119, no. 3, p. e2106028118, 2022
2022
-
[7]
D3C: reducing the price of anarchy in multi-agent learning,
I. Gemp, K. R. McKee, R. Everett, E. A. Du ´e˜nez-Guzm´an, Y . Bachrach, D. Balduzzi, and A. Tacchetti, “D3C: reducing the price of anarchy in multi-agent learning,” in21st International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2022, Auckland, New Zealand, May 9-13, 2022, 2022, pp. 498–506
2022
-
[8]
Learning to balance altruism and self-interest based on empathy in mixed-motive games,
F. Kong, Y . Huang, S. Zhu, S. Qi, and X. Feng, “Learning to balance altruism and self-interest based on empathy in mixed-motive games,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, 2024
2024
-
[9]
Combined effect of pure punishment and reward in the public goods game,
X. Sun, M. Li, H. Kang, Y . Shen, and Q. Chen, “Combined effect of pure punishment and reward in the public goods game,”Appl. Math. Comput., vol. 445, p. 127853, 2023
2023
-
[10]
Efficient adaptation in mixed-motive environments via hierarchical opponent modeling and planning,
Y . Huang, A. Liu, F. Kong, Y . Yang, S. Zhu, and X. Feng, “Efficient adaptation in mixed-motive environments via hierarchical opponent modeling and planning,” inForty-first International Conference on Machine Learning, ICML 2024, 2024
2024
-
[11]
Egoistic punishment outcompetes altruistic punishment in the spatial public goods game,
J. Li, Y . Liu, Z. Wang, and H. Xia, “Egoistic punishment outcompetes altruistic punishment in the spatial public goods game,”Scientific reports, vol. 11, no. 1, p. 6584, 2021
2021
-
[12]
Tax-based pure punishment and reward in the public goods game,
S. Wang, L. Liu, and X. Chen, “Tax-based pure punishment and reward in the public goods game,”Physics Letters A, vol. 386, p. 126965, 2021
2021
-
[13]
Evolution of cooperation under punish- ment,
S. Gao, J. Du, and J. Liang, “Evolution of cooperation under punish- ment,”Physical Review E, vol. 101, no. 6, p. 062419, 2020
2020
-
[14]
Conditional neu- tral punishment promotes cooperation in the spatial prisoner’s dilemma game,
Q. Song, Z. Cao, R. Tao, W. Jiang, C. Liu, and J. Liu, “Conditional neu- tral punishment promotes cooperation in the spatial prisoner’s dilemma game,”Appl. Math. Comput., vol. 368, 2020
2020
-
[15]
The probabilistic pool punishment proportional to the difference of payoff outperforms previous pool and peer punishment,
T. Ohdaira, “The probabilistic pool punishment proportional to the difference of payoff outperforms previous pool and peer punishment,” Scientific Reports, vol. 12, no. 1, p. 6604, 2022
2022
-
[16]
Inequity aversion improves cooperation in intertemporal social dilemmas,
E. Hughes, J. Z. Leibo, M. Phillips, K. Tuyls, E. A. Du ´e˜nez-Guzm´an, A. G. Casta ˜neda, I. Dunning, T. Zhu, K. R. McKee, R. Koster, H. Roff, and T. Graepel, “Inequity aversion improves cooperation in intertemporal social dilemmas,” inAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems, 2018, ...
2018
-
[17]
A multi-agent reinforcement learning model of common-pool resource appropriation,
J. P ´erolat, J. Z. Leibo, V . F. Zambaldi, C. Beattie, K. Tuyls, and T. Grae- pel, “A multi-agent reinforcement learning model of common-pool resource appropriation,” inAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, 2017, pp. 3643–3652
2017
-
[18]
Emergence of punishment in social dilemma with environmental feedback,
Z. Wang, Z. Song, C. Shen, and S. Hu, “Emergence of punishment in social dilemma with environmental feedback,” inThirty-Seventh AAAI Conference on Artificial Intelligence, 2023, pp. 11 708–11 716
2023
-
[19]
Investigating the impact of direct pun- ishment on the emergence of cooperation in multi-agent reinforcement learning systems,
N. Dasgupta and M. Musolesi, “Investigating the impact of direct pun- ishment on the emergence of cooperation in multi-agent reinforcement learning systems,”Auton. Agents Multi Agent Syst., vol. 39, no. 1, p. 19, 2025
2025
-
[20]
Learning to penalize other learning agents,
K. Schmid, L. Belzner, and C. Linnhoff-Popien, “Learning to penalize other learning agents,” in2021 Conference on Artificial Life, ALIFE 2021, online, July 19-23, 2021, J. Cejkov ´a, S. Holler, L. B. Soros, and O. Witkowski, Eds., 2021, p. 59
2021
-
[21]
The emergence of division of labor through decentralized social sanctioning,
A. Yaman, J. Z. Leibo, G. Iacca, and S. W. Lee, “The emergence of division of labor through decentralized social sanctioning,”CoRR, vol. abs/2208.05568, 2022
-
[22]
Maintaining cooperation in complex social dilemmas using deep reinforcement learning
A. Lerer and A. Peysakhovich, “Maintaining cooperation in complex social dilemmas using deep reinforcement learning,”arXiv preprint arXiv:1707.01068, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Prosocial learning agents solve gen- eralized stag hunts better than selfish ones,
A. Peysakhovich and A. Lerer, “Prosocial learning agents solve gen- eralized stag hunts better than selfish ones,” inProceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018, pp. 2043–2044
2018
-
[24]
Asynchronous methods for deep rein- forcement learning,
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep rein- forcement learning,” inInternational conference on machine learning. PmLR, 2016, pp. 1928–1937
2016
-
[25]
Learning with opponent-learning awareness,
J. N. Foerster, R. Y . Chen, M. Al-Shedivat, S. Whiteson, P. Abbeel, and I. Mordatch, “Learning with opponent-learning awareness,” in Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018, pp. 122–130
2018
-
[26]
Social influence as intrinsic motivation for multi-agent deep reinforcement learning,
N. Jaques, A. Lazaridou, E. Hughes, C ¸ . G ¨ulc ¸ehre, P. A. Ortega, D. Strouse, J. Z. Leibo, and N. de Freitas, “Social influence as intrinsic motivation for multi-agent deep reinforcement learning,” inProceedings of the 36th International Conference on Machine Learning, ICML 2019, vol. 97, 2019, pp. 3040–3049
2019
-
[27]
D3C: reducing the price of anarchy in multi-agent learning,
I. Gemp, K. R. McKee, R. Everett, E. A. Du ´e˜nez-Guzm´an, Y . Bachrach, D. Balduzzi, and A. Tacchetti, “D3C: reducing the price of anarchy in multi-agent learning,” in21st International Conference on Autonomous Agents and Multiagent Systems, 2022, pp. 498–506
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.