Measuring the Depth of LLM Unlearning via Activation Patching
Pith reviewed 2026-06-30 13:30 UTC · model grok-4.3
The pith
The Unlearning Depth Score quantifies how completely target knowledge has been erased from an LLM's internal layers using activation patching against a retain baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
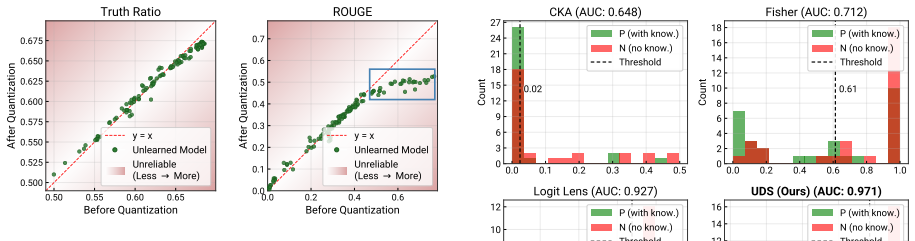
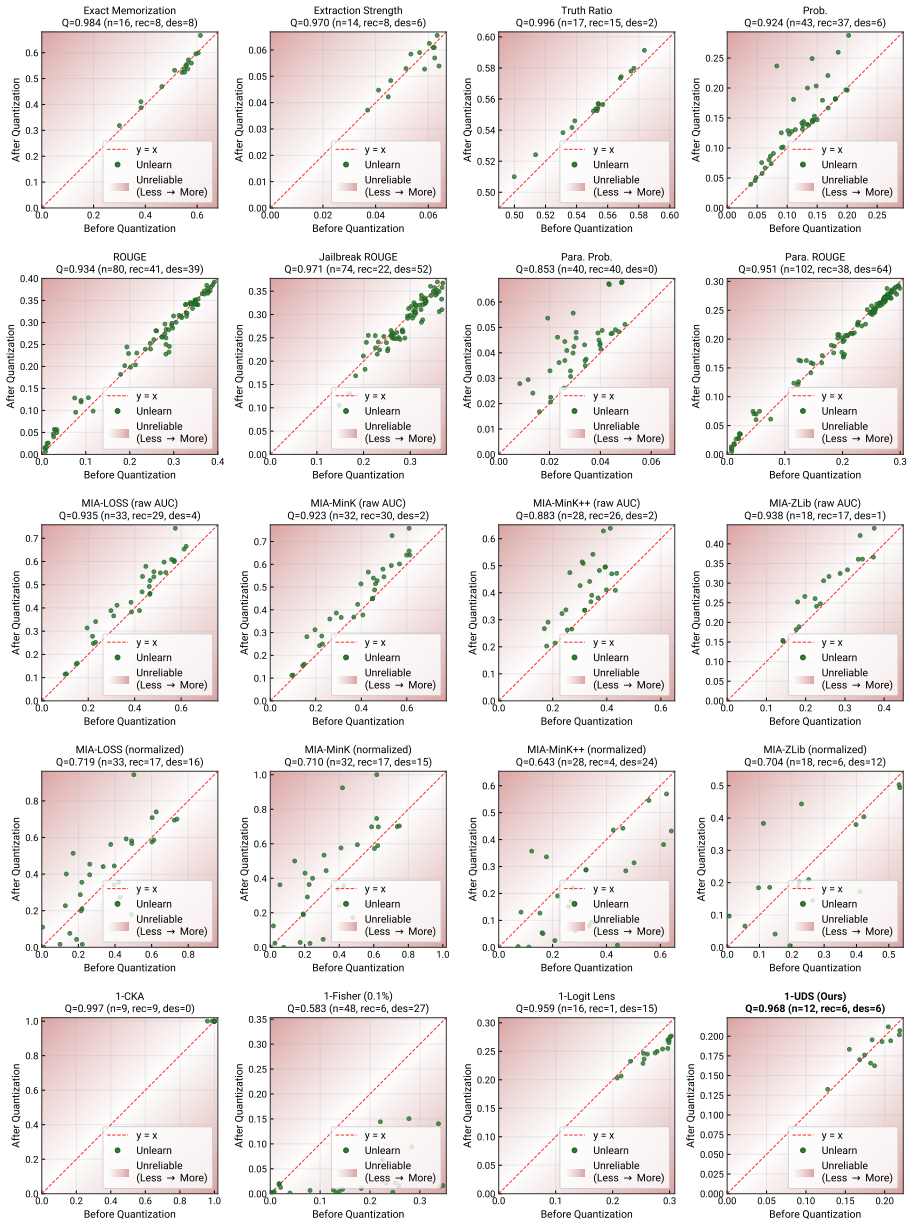
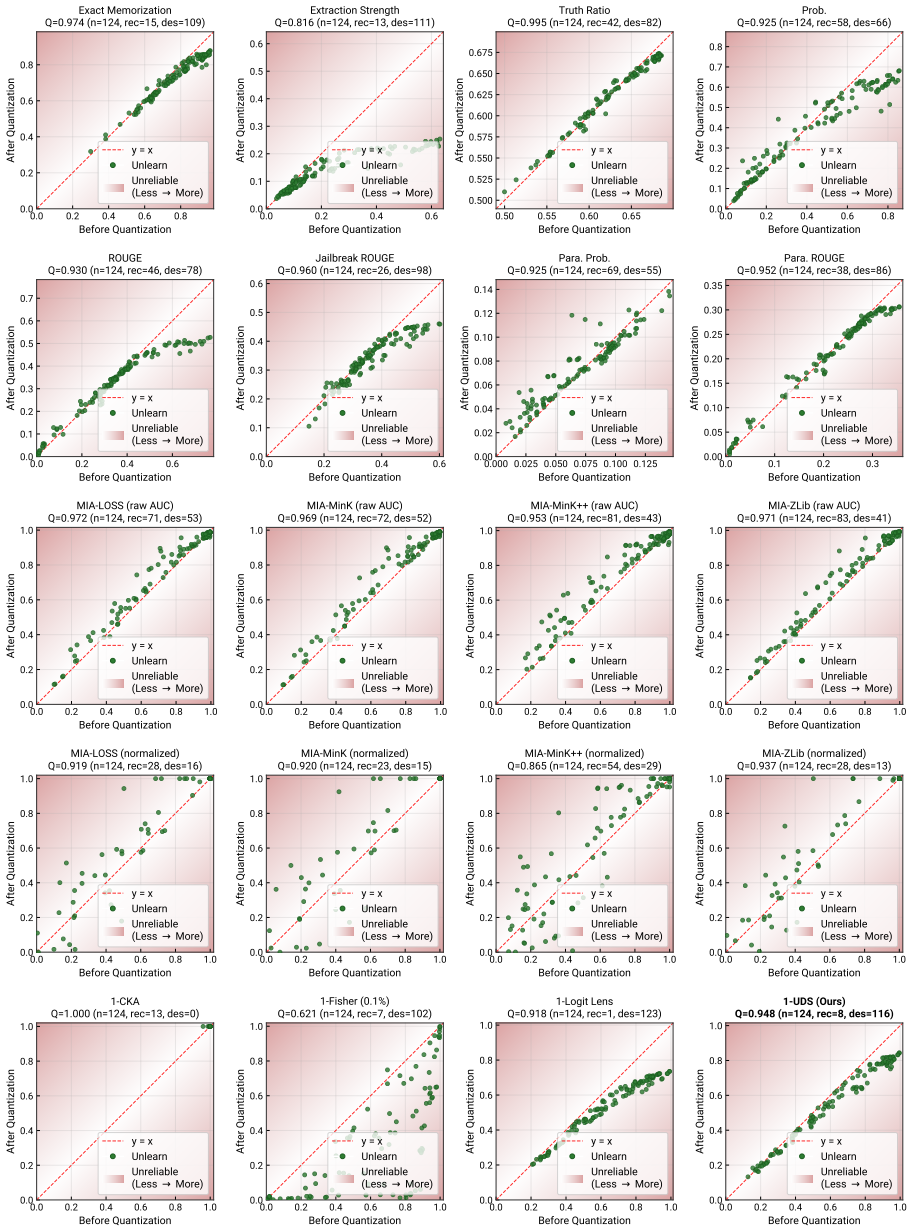
UDS identifies layers encoding target knowledge by comparing activations in the unlearned model to those in a retain model baseline then computes the fraction of that knowledge removed after unlearning to produce a 0-1 depth score. Across 150 unlearned models spanning eight methods UDS shows the highest faithfulness and robustness among twenty evaluated metrics while case studies indicate that white-box metrics disagree at the layer level and that erasure depth varies by example.
What carries the argument
The Unlearning Depth Score (UDS), a metric that locates layers holding target knowledge via activation patching against a retain model and then measures the fraction erased on a 0-1 scale.
If this is right
- White-box metrics can produce conflicting layer-level diagnoses of the same unlearned model.
- Erasure depth differs across individual examples even within one unlearning run.
- UDS supplies a single scalar that can be added to existing unlearning benchmarks.
- Evaluation pipelines can be streamlined by replacing multiple output metrics with one mechanistic score.
Where Pith is reading between the lines
- Developers could target specific layers identified by UDS to make future unlearning methods more efficient.
- The same patching technique might expose residual knowledge in other model-editing tasks such as fact correction.
- If UDS consistently reports shallow erasure then current methods may need redesign to reach deeper layers.
- Benchmarks could track UDS trends over successive model releases to measure progress in unlearning reliability.
Load-bearing premise
Activation patching against a retain model baseline can locate the exact layers that encode the target knowledge and measure its removal without introducing artifacts from the unlearning process itself.
What would settle it
Run UDS on an unlearned model where output behavior matches a fully retained model yet internal activations still differ from the retain baseline at the identified layers or where outputs appear erased but UDS reports near-zero depth.
Figures


read the original abstract
Large language model (LLM) unlearning has emerged as a crucial post-hoc mechanism for privacy protection and AI safety, yet auditing whether target knowledge is truly erased remains challenging. Existing output-level metrics fail to detect when this knowledge remains recoverable from internal representations. Recent white-box studies reveal such residual knowledge but often rely on auxiliary training or dataset-specific adaptations, leaving no generalizable metric. To address these limitations, we propose the Unlearning Depth Score (UDS), a metric that quantifies the mechanistic depth of unlearning via activation patching. UDS first identifies layers that encode the target knowledge using a retain model baseline, then measures how much of it is erased in the unlearned model on a 0-1 scale. In a meta-evaluation across 20 metrics on 150 unlearned models spanning 8 methods, UDS achieves the highest faithfulness and robustness, confirming our causal approach as the most reliable for unlearning evaluation. Case studies further reveal that white-box metrics can disagree at the layer level and that erasure depth varies across examples. We provide guidelines for integrating UDS into existing benchmarking frameworks and streamlining the evaluation pipeline. Code and data are available at https://github.com/gnueaj/unlearning-depth-score
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Unlearning Depth Score (UDS), a metric that quantifies the mechanistic depth of LLM unlearning via activation patching. UDS identifies layers encoding target knowledge using a retain-model baseline, then measures erasure on a 0-1 scale. The central claim, based on a meta-evaluation across 20 metrics and 150 unlearned models spanning 8 methods, is that UDS exhibits the highest faithfulness and robustness, making it the most reliable evaluation approach; case studies also note layer-level disagreements among white-box metrics.
Significance. If the claims hold after addressing baseline assumptions, this would supply a generalizable causal metric for unlearning evaluation that improves on output-level approaches and auxiliary-training-dependent white-box methods. The scale of the meta-evaluation (150 models, 8 methods) and public code/data release are positive features that could support adoption in AI safety benchmarks.
major comments (2)
- Abstract: the superiority claim in the meta-evaluation treats UDS as the reference for faithfulness, yet UDS layer identification depends on the retain-model baseline; this assumption is load-bearing because any unlearning-induced distribution shift or patching artifact would propagate into the faithfulness ranking, and the manuscript provides no explicit test isolating this risk.
- Abstract: the meta-evaluation reports UDS as highest in faithfulness and robustness, but without details on the exact definition of 'faithfulness' (e.g., correlation with ground-truth erasure or recovery experiments) or how post-hoc layer selection was validated, the claim that the causal approach is 'most reliable' cannot be assessed from the given description.
minor comments (2)
- The abstract states that 'erasure depth varies across examples'; including quantitative variation statistics or a table of per-example UDS scores would clarify this observation.
- Clarify whether the retain model is the original pretrained model or a separately trained model, and state any hyperparameters used in the patching procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and note planned revisions to improve clarity and address the identified gaps.
read point-by-point responses
-
Referee: Abstract: the superiority claim in the meta-evaluation treats UDS as the reference for faithfulness, yet UDS layer identification depends on the retain-model baseline; this assumption is load-bearing because any unlearning-induced distribution shift or patching artifact would propagate into the faithfulness ranking, and the manuscript provides no explicit test isolating this risk.
Authors: We acknowledge that the retain-model baseline is a core assumption for layer identification in UDS, and that the manuscript does not include an explicit isolation experiment for potential distribution shifts or patching artifacts. While the scale of the meta-evaluation (150 models across 8 methods) provides supporting evidence of robustness, we agree this is a substantive concern. In revision we will add a targeted analysis testing UDS sensitivity to baseline perturbations and discuss the implications for the faithfulness ranking. revision: yes
-
Referee: Abstract: the meta-evaluation reports UDS as highest in faithfulness and robustness, but without details on the exact definition of 'faithfulness' (e.g., correlation with ground-truth erasure or recovery experiments) or how post-hoc layer selection was validated, the claim that the causal approach is 'most reliable' cannot be assessed from the given description.
Authors: The abstract summarizes results concisely, but the full manuscript defines faithfulness via correlation with ground-truth erasure (verified through recovery experiments) and validates layer selection through consistency checks across methods. We agree the abstract claim would benefit from a brief definition or cross-reference. We will revise the abstract to include a short clarification of these terms while preserving length constraints. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines UDS via activation patching against a retain-model baseline and reports its superiority via a meta-evaluation on 150 models and 20 metrics. No quoted step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional tautology. The derivation remains self-contained against the external benchmark of the meta-evaluation; no load-bearing self-citation or ansatz smuggling is exhibited in the text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation patching can causally identify layers encoding target knowledge using a retain model baseline.
invented entities (1)
-
Unlearning Depth Score (UDS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Samyadeep Basu, Phillip Pope, and Soheil Feizi. 2021. https://openreview.net/forum?id=xHKVVHGDOEk Influence functions in deep learning are fragile . In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net
2021
-
[4]
Yoshua Bengio, Sören Mindermann, Daniel Privitera, Tamay Besiroglu, Rishi Bommasani, Stephen Casper, Yejin Choi, Philip Fox, Ben Garfinkel, Danielle Goldfarb, Hoda Heidari, Anson Ho, Sayash Kapoor, Leila Khalatbari, Shayne Longpre, Sam Manning, Vasilios Mavroudis, Mantas Mazeika, Julian Michael, and 77 others. 2025. https://arxiv.org/abs/2501.17805 Intern...
-
[5]
Choquette - Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette - Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. https://doi.org/10.1109/SP40001.2021.00019 Machine unlearning . In 42nd IEEE Symposium on Security and Privacy, SP 2021, San Francisco, CA, USA, 24-27 May 2021 , pages 141--159. IEEE
-
[6]
Brown, Dawn Song, \' U lfar Erlingsson, Alina Oprea, and Colin Raffel
Nicholas Carlini, Florian Tram \` e r, Eric Wallace, Matthew Jagielski, Ariel Herbert - Voss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Song, \' U lfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. https://www.usenix.org/conference/usenixsecurity21/presentation/carlini-extracting Extracting training data from large language models . In 30th USENI...
2021
-
[7]
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ram \' o n Huerta, and Ivan Vulic. 2025. https://doi.org/10.18653/V1/2025.NAACL-LONG.444 UNDIAL : Self-distillation with adjusted logits for robust unlearning in large language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[8]
Zico Kolter, and Pratyush Maini
Vineeth Dorna, Anmol Mekala, Wenlong Zhao, Andrew McCallum, Zachary Chase Lipton, J. Zico Kolter, and Pratyush Maini. 2025. https://arxiv.org/abs/2506.12618 Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics . In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processin...
-
[9]
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. 2025 a . https://arxiv.org/abs/2502.05374 Towards LLM unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond . In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025
-
[10]
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. 2025 b . https://openreview.net/forum?id=JbvSQm5h1l Simplicity prevails: Rethinking negative preference optimization for LLM unlearning . In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2025, NeurIPS 2025
2025
-
[11]
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. 2024. https://proceedings.mlr.press/v235/ghandeharioun24a.html Patchscopes: A unifying framework for inspecting hidden representations of language models . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , volume 235 of Proc...
2024
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The Llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Phillip Guo, Aaquib Syed, Abhay Sheshadri, Aidan Ewart, and Gintare Karolina Dziugaite. 2025. https://proceedings.mlr.press/v267/guo25k.html Mechanistic unlearning: Robust knowledge unlearning and editing via mechanistic localization . In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , volume...
2025
-
[14]
Yihuai Hong, Lei Yu, Haiqin Yang, Shauli Ravfogel, and Mor Geva. 2025. https://doi.org/10.18653/V1/2025.EMNLP-MAIN.985 Intrinsic test of unlearning using parametric knowledge traces . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025 , pages 19513--19535. Association fo...
-
[15]
Yihuai Hong, Yuelin Zou, Lijie Hu, Ziqian Zeng, Di Wang, and Haiqin Yang. 2024. https://doi.org/10.18653/V1/2024.EMNLP-MAIN.228 Dissecting fine-tuning unlearning in large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024 , pages 3933--3941. Associat...
-
[16]
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. 2023. https://doi.org/10.18653/V1/2023.ACL-LONG.805 Knowledge unlearning for mitigating privacy risks in language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toron...
- [17]
-
[18]
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/b1f78dfc9ca0156498241012aec4efa0-Abstract-Datasets_and_Benchmarks_Track.html RWKU : Benchmarking real-world knowledge unlearning for large language models . In Advances in Neural ...
2024
-
[19]
Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017. https://doi.org/10.1073/pnas.1611835114 Overcoming catastrophic forgetting in neural networks . Proceedings...
-
[20]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton. 2019. http://proceedings.mlr.press/v97/kornblith19a.html Similarity of neural network representations revisited . In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA , volume 97 of Proceedings of Machine Learn...
2019
-
[21]
Jaeung Lee, Suhyeon Yu, Yurim Jang, Simon S. Woo, and Jaemin Jo. 2026. https://doi.org/10.1109/TVCG.2026.3658325 Unlearning comparator: A visual analytics system for comparative evaluation of machine unlearning methods . IEEE Transactions on Visualization and Computer Graphics , 32(3):2852--2867
-
[22]
Li, Ann - Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm - Burger, Rassin Lababidi, Lennart Justen, Andrew B
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann - Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm - Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, and 27 others. 2024. https://proceedings.mlr.press/v235...
2024
-
[23]
Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, and Dylan Hadfield - Menell. 2024. https://doi.org/10.48550/ARXIV.2402.16835 Eight methods to evaluate robust unlearning in LLMs . CoRR, abs/2402.16835
-
[24]
Zico Kolter
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary Chase Lipton, and J. Zico Kolter. 2024. https://openreview.net/forum?id=B41hNBoWLo TOFU : A task of fictitious unlearning for LLM s . In First Conference on Language Modeling, COLM 2024
2024
-
[25]
Hasan, and Elita A
Anmol Reddy Mekala, Vineeth Dorna, Shreya Dubey, Abhishek Lalwani, David Koleczek, Mukund Rungta, Sadid A. Hasan, and Elita A. Lobo. 2025. https://aclanthology.org/2025.coling-main.252/ Alternate preference optimization for unlearning factual knowledge in large language models . In Proceedings of the 31st International Conference on Computational Linguist...
2025
-
[26]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. http://papers.nips.cc/paper_files/paper/2022/hash/6f1d43d5a82a37e89b0665b33bf3a182-Abstract-Conference.html Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 20...
2022
-
[27]
nostalgebraist. 2020. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens Interpreting GPT : the logit lens . LessWrong
2020
-
[28]
Vaidehi Patil, Peter Hase, and Mohit Bansal. 2024. https://openreview.net/forum?id=7erlRDoaV8 Can sensitive information be deleted from LLMs ? objectives for defending against extraction attacks . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[29]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html Direct preference optimization: Your language model is secretly a reward model . In Advances in Neural Information Processing Syst...
2023
- [30]
-
[31]
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. 2024. https://openreview.net/forum?id=zWqr3MQuNs Detecting pretraining data from large language models . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[32]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. 2025. https://openreview.net/forum?id=TArmA033BU MUSE : Machine unlearning six-way evaluation for language models . In The Thirteenth International Conference on Learning Representations, ICLR 2025
2025
-
[33]
Markosyan, Luke Zettlemoyer, and Armen Aghajanyan
Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. 2022. https://papers.nips.cc/paper_files/paper/2022/hash/fa0509f4dab6807e2cb465715bf2d249-Abstract-Conference.html Memorization without overfitting: Analyzing the training dynamics of large language models . In Advances in Neural Information Processing Systems 35: Annual Conferenc...
2022
-
[34]
Xiaoyu Xu, Xiang Yue, Yang Liu, Qingqing Ye, Huadi Zheng, Peizhao Hu, Minxin Du, and Haibo Hu. 2025. https://arxiv.org/abs/2505.16831 Unlearning isn't deletion: Investigating reversibility of machine unlearning in LLMs . CoRR, abs/2505.16831
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yuanshun Yao, Xiaojun Xu, and Yang Liu. 2024. http://papers.nips.cc/paper_files/paper/2024/hash/be52acf6bccf4a8c0a90fe2f5cfcead3-Abstract-Conference.html Large language model unlearning . In Advances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 1...
2024
-
[36]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. https://doi.org/10.1109/CSF.2018.00027 Privacy risk in machine learning: Analyzing the connection to overfitting . In 31st IEEE Computer Security Foundations Symposium, CSF 2018, Oxford, United Kingdom, July 9-12, 2018 , pages 268--282. IEEE Computer Society
-
[37]
Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. 2025. https://openreview.net/forum?id=ZGkfoufDaU Min-K\ In The Thirteenth International Conference on Learning Representations, ICLR 2025
2025
-
[38]
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. 2024. https://openreview.net/forum?id=MXLBXjQkmb Negative preference optimization: From catastrophic collapse to effective unlearning . In First Conference on Language Modeling, COLM 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.