DisDop: Distillation with Domain Priors for Open-Vocabulary Aerial Object Detection
Pith reviewed 2026-06-30 13:41 UTC · model grok-4.3
The pith
DisDop distills multi-level domain priors from RemoteCLIP and DINOv3 into a lightweight detector to reach new state-of-the-art on open-vocabulary aerial detection benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
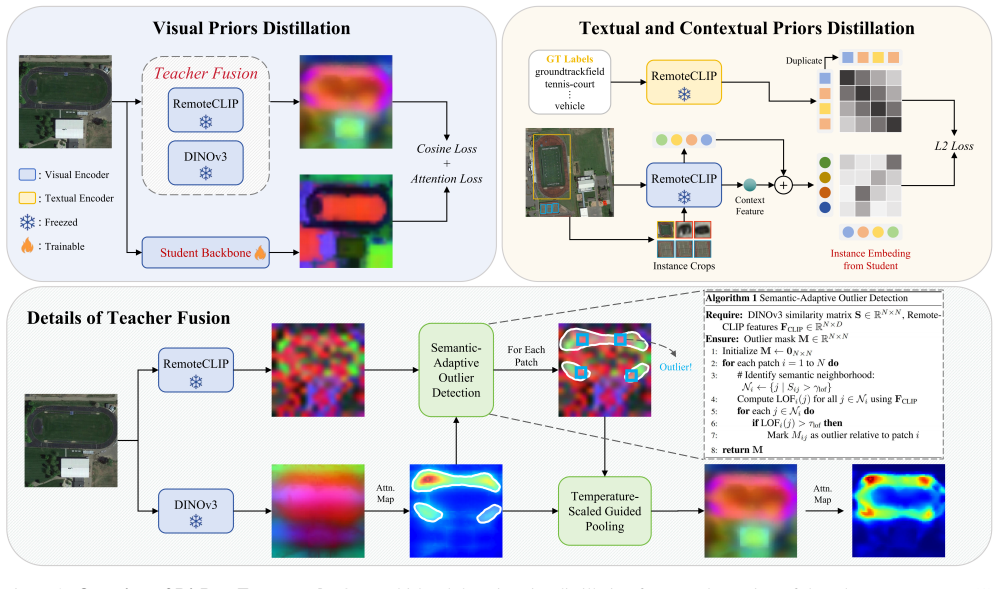
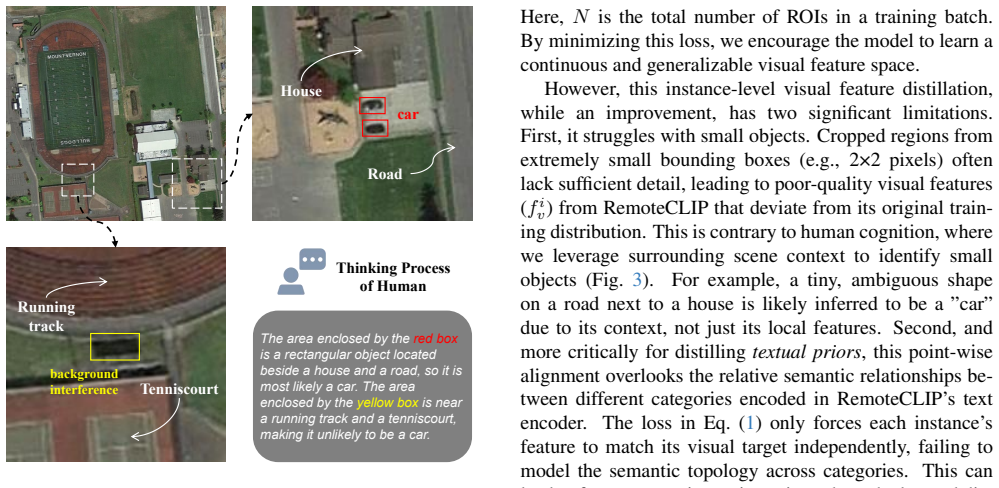
DisDop is a unified distillation framework that systematically transfers multi-level domain priors from remote sensing foundation models into a lightweight detector. Visual priors are obtained by fusing RemoteCLIP's cross-modal alignment capability with DINOv3's fine-grained local feature extraction via a teacher fusion strategy. Textual priors are distilled by modeling inter-category semantic relationships in RemoteCLIP's text encoder and by incorporating global contextual priors to strengthen local representations of small objects. This multi-level approach produces new state-of-the-art results on open-vocabulary aerial detection benchmarks.
What carries the argument
Teacher fusion strategy that combines RemoteCLIP cross-modal alignment with DINOv3 local feature extraction to transfer complementary strengths to the detector backbone, together with semantic relationship modeling for textual priors.
If this is right
- The lightweight detector inherits both cross-modal and fine-grained visual capabilities suited to aerial imagery.
- Explicit modeling of category semantics and global context improves recognition of small or rare objects.
- Performance gains are realized without retraining large foundation models from scratch.
- The same distillation pattern can be applied whenever domain-specific foundation models exist for a visual task.
Where Pith is reading between the lines
- The method implies that domain-specific pretraining can substitute for large-scale aerial annotation in many drone applications.
- Similar fusion of modality-specific teachers may generalize to other remote-sensing tasks such as segmentation or change detection.
- If the complementarity holds across more backbone sizes, the approach could lower the compute barrier for on-drone inference.
Load-bearing premise
RemoteCLIP's cross-modal alignment and DINOv3's local features are complementary and can be transferred to a lightweight detector backbone via the teacher fusion strategy without substantial degradation for aerial viewpoints.
What would settle it
An experiment in which the fused RemoteCLIP-DINOv3 teacher yields no accuracy gain over either model used alone on standard open-vocabulary aerial benchmarks would falsify the complementarity premise.
Figures

read the original abstract
With the widespread application of drones in recent years, object detection of aerial images has attracted increasing attention, especially open-vocabulary aerial detection which is not restricted to predefined categories. Due to the scarcity of drone's viewpoint images and their significant differences from natural images, it is difficult to achieve satisfying results by directly applying vanilla open-vocabulary detection methods designed for natural scenarios. Some studies propose to transfer knowledge from pre-trained models by using lightweight networks or generating pseudo labels, but they tend to rely on models trained on natural images, neglecting the potential of foundation models specifically tailored for remote sensing and aerial imagery. To address this limitation, we propose DisDop, a unified framework that systematically distills multi-level domain priors from remote sensing foundation models (e.g., RemoteCLIP and DINOv3) into a lightweight detector. Specifically, we first distill visual priors through a teacher fusion strategy that combines RemoteCLIP's cross-modal alignment capability with DINOv3's fine-grained local feature extraction ability, transferring their complementary strengths to the detector's backbone. Second, we distill textual priors embedded in RemoteCLIP's text encoder by explicitly modeling inter-category semantic relationships, while incorporating global contextual priors to enhance local feature representation for small objects. Through this multi-level prior distillation framework, our DisDop achieves new state-of-the-art performance on open-vocabulary aerial detection benchmarks. Extensive ablation analysis also demonstrates the rationality and effectiveness of our proposed modules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DisDop, a multi-level distillation framework for open-vocabulary aerial object detection. It transfers visual priors via a teacher-fusion strategy combining RemoteCLIP cross-modal alignment with DINOv3 local features into a lightweight detector backbone, textual priors by modeling inter-category semantic relationships from RemoteCLIP's text encoder, and global contextual priors to improve small-object representation. The central claim is that this approach yields new state-of-the-art mAP on open-vocabulary aerial detection benchmarks, supported by standard comparisons and component ablations.
Significance. If the reported mAP gains and ablations hold under the stated protocol, the work is significant for addressing the domain gap between natural-image and aerial imagery by leveraging remote-sensing-specific foundation models rather than generic ones. The explicit use of complementary teacher strengths (RemoteCLIP + DINOv3) and the inclusion of ablations isolating each distillation level provide a reproducible template for domain-adapted OVOD. This is particularly relevant for drone applications where labeled aerial data remains scarce.
minor comments (3)
- [Abstract] Abstract: the phrase 'new state-of-the-art performance on open-vocabulary aerial detection benchmarks' should name the specific datasets (e.g., DIOR-OV, FAIR1M-OV) and report the absolute mAP deltas versus the strongest baseline for immediate readability.
- [§4] §4 (Ablation tables): confirm that every ablation row includes the identical training schedule, data augmentation, and evaluation protocol as the full model so that incremental gains can be attributed solely to the added prior.
- [§3.2] Figure 3 / §3.2: the teacher-fusion diagram would benefit from an explicit equation or pseudocode block showing how RemoteCLIP and DINOv3 features are combined before distillation (e.g., weighted sum, attention, or concatenation) to remove any ambiguity in the visual-prior transfer step.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the recognition of its significance for domain-adapted open-vocabulary detection in aerial imagery, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper proposes an empirical multi-level distillation framework that transfers priors from external foundation models (RemoteCLIP and DINOv3) to a lightweight detector, with the central claim being improved SOTA performance on aerial OVOD benchmarks. No equations, fitted parameters, or predictions appear that reduce by construction to inputs or self-citations. The method description relies on standard distillation techniques and external pre-trained models, while results are validated through benchmark comparisons and ablations that are independent of the framework definition itself. This is the most common honest finding for method papers without internal mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geography-aware self-supervised learning
Kumar Ayush, Burak Uzkent, Chenlin Meng, Kumar Tan- may, Marshall Burke, David Lobell, and Stefano Ermon. Geography-aware self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, 2021. 7
2021
-
[2]
Satlaspretrain: A large- scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdi- nando, and Aniruddha Kembhavi. Satlaspretrain: A large- scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023. 7
2023
-
[3]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, Tian- heng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Yue Wu, Jifeng Dai, Jingdong Wang, Jianping Shi, Wanli Ouyang, Chen Change Loy, and Dahua Lin. MMDetection: Open mmlab detection toolbox and...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[4]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16901–16911, 2024. 3 8
2024
-
[5]
Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images
Bowei Du, Yecheng Huang, Jiaxin Chen, and Di Huang. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 13435–13444, 2023. 3
2023
-
[6]
Learning to prompt for open-vocabulary ob- ject detection with vision-language model
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open-vocabulary ob- ject detection with vision-language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14084–14093, 2022. 2
2022
-
[7]
Prompt- det: Towards open-vocabulary detection using uncurated im- ages
Chengjian Feng, Yujie Zhong, Zequn Jie, Xiangxiang Chu, Haibing Ren, Xiaolin Wei, Weidi Xie, and Lin Ma. Prompt- det: Towards open-vocabulary detection using uncurated im- ages. InEuropean conference on computer vision, pages 701–717. Springer, 2022
2022
-
[8]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Skysense: A multi-modal remote sens- ing foundation model towards universal interpretation for earth observation imagery
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, et al. Skysense: A multi-modal remote sens- ing foundation model towards universal interpretation for earth observation imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[10]
Global knowledge calibration for fast open-vocabulary segmentation
Kunyang Han, Yong Liu, Jun Hao Liew, Henghui Ding, Ji- ajun Liu, Yitong Wang, Yansong Tang, Yujiu Yang, Jiashi Feng, Yao Zhao, et al. Global knowledge calibration for fast open-vocabulary segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 797–807, 2023. 6
2023
-
[11]
Ufpmp-det: Toward accurate and efficient object detection on drone im- agery
Yecheng Huang, Jiaxin Chen, and Di Huang. Ufpmp-det: Toward accurate and efficient object detection on drone im- agery. InProceedings of the AAAI conference on artificial intelligence, pages 1026–1033, 2022. 3
2022
-
[12]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[13]
Density map guided object detection in aerial images
Changlin Li, Taojiannan Yang, Sijie Zhu, Chen Chen, and Shanyue Guan. Density map guided object detection in aerial images. Inproceedings of the IEEE/CVF conference on com- puter vision and pattern recognition workshops, pages 190– 191, 2020. 3
2020
-
[14]
Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogram- metry and remote sensing, 159:296–307, 2020
Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, and Junwei Han. Object detection in optical remote sensing images: A survey and a new benchmark.ISPRS journal of photogram- metry and remote sensing, 159:296–307, 2020. 6
2020
-
[15]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 3
2022
-
[16]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. 6, 7
2022
-
[17]
Toward open vocabulary aerial object detection with clip-activated student-teacher learning
Yan Li, Weiwei Guo, Xue Yang, Ning Liao, Dunyun He, Jiaqi Zhou, and Wenxian Yu. Toward open vocabulary aerial object detection with clip-activated student-teacher learning. InEuropean Conference on Computer Vision, pages 431–
-
[18]
Springer, 2024. 2, 3
2024
-
[19]
Re- moteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 2024
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Re- moteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 2024. 2, 6
2024
-
[20]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision, pages 38–55. Springer, 2024. 3
2024
-
[21]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
-
[22]
Hrd- net: High-resolution detection network for small objects
Ziming Liu, Guangyu Gao, Lin Sun, and Zhiyuan Fang. Hrd- net: High-resolution detection network for small objects. In 2021 IEEE international conference on multimedia and expo (ICME), pages 1–6. IEEE, 2021. 3
2021
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 6
2021
-
[24]
Change-aware sampling and contrastive learning for satellite images
Utkarsh Mall, Bharath Hariharan, Kavita Bala, and Kavita Bala. Change-aware sampling and contrastive learning for satellite images. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023. 7
2023
-
[25]
Jiancheng Pan, Yanxing Liu, Yuqian Fu, Muyuan Ma, Jiahao Li, Danda Pani Paudel, Luc Van Gool, and Xiaomeng Huang. Locate anything on earth: Advancing open-vocabulary ob- ject detection for remote sensing community.arXiv preprint arXiv:2408.09110, 2024. 3, 6, 7
-
[26]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[27]
Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brock- man, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-mae: A scale-aware masked autoencoder for multiscale geospatial representation learning. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, 2023. 7 9
2023
-
[28]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
2025
-
[29]
Ringmo: A remote sensing foundation model with masked image modeling.IEEE Transactions on Geo- science and Remote Sensing, 2022
Xian Sun, Peijin Wang, Wanxuan Lu, Zicong Zhu, Xiao- nan Lu, Qibin He, Junxi Li, Xuee Rong, Zhujun Yang, Hao Chang, et al. Ringmo: A remote sensing foundation model with masked image modeling.IEEE Transactions on Geo- science and Remote Sensing, 2022. 7
2022
-
[30]
Chao Tao, Ji Qi, Guo Zhang, Qing Zhu, Weipeng Lu, and Haifeng Li. Tov: The original vision model for optical re- mote sensing image understanding via self-supervised learn- ing.IEEE Journal of Selected Topics in Applied Earth Ob- servations and Remote Sensing, 2023. 7
2023
-
[31]
Mtp: Advancing remote sensing foun- dation model via multi-task pretraining.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024
Di Wang, Jing Zhang, Minqiang Xu, Lin Liu, Dongsheng Wang, Erzhong Gao, Chengxi Han, Haonan Guo, Bo Du, Dacheng Tao, et al. Mtp: Advancing remote sensing foun- dation model via multi-task pretraining.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024. 7
2024
-
[32]
Guoting Wei, Xia Yuan, Yu Liu, Zhenhao Shang, Kelu Yao, Chao Li, Qingsen Yan, Chunxia Zhao, Haokui Zhang, and Rong Xiao. Ova-detr: Open vocabulary aerial object detec- tion using image-text alignment and fusion.arXiv preprint arXiv:2408.12246, 2024. 2, 3
-
[33]
Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching
Xiaoshi Wu, Feng Zhu, Rui Zhao, and Hongsheng Li. Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7031–7040, 2023. 2
2023
-
[34]
Dota: A large-scale dataset for object detection in aerial images
Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Be- longie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liang- pei Zhang. Dota: A large-scale dataset for object detection in aerial images. InThe IEEE Conference on Computer Vision and Pattern Recognition, 2018. 6
2018
-
[35]
Clustered object detection in aerial images
Fan Yang, Heng Fan, Peng Chu, Erik Blasch, and Haibin Ling. Clustered object detection in aerial images. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 8311–8320, 2019. 3
2019
-
[36]
Lavt: Language-aware vision transformer for referring image segmentation
Zhao Yang, Jiaqi Wang, Yansong Tang, Kai Chen, Heng- shuang Zhao, and Philip HS Torr. Lavt: Language-aware vision transformer for referring image segmentation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18155–18165, 2022. 2
2022
-
[37]
Open-vocabulary detr with conditional matching
Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Open-vocabulary detr with conditional matching. InEuropean conference on computer vision, pages 106–122. Springer, 2022. 2
2022
-
[38]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Detrs beat yolos on real-time object detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16965–16974, 2024. 2
2024
-
[40]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 2
2022
-
[41]
Detecting twenty-thousand classes using image-level supervision
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Kr¨ahenb¨uhl, and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. InEuropean confer- ence on computer vision, pages 350–368. Springer, 2022. 2, 3 10
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.