Measuring Reasoning Quality in LLMs: A Multi-Dimensional Behavioral Framework
Pith reviewed 2026-06-30 13:24 UTC · model grok-4.3
The pith
Logical coherence in LLM reasoning is independent of answer correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
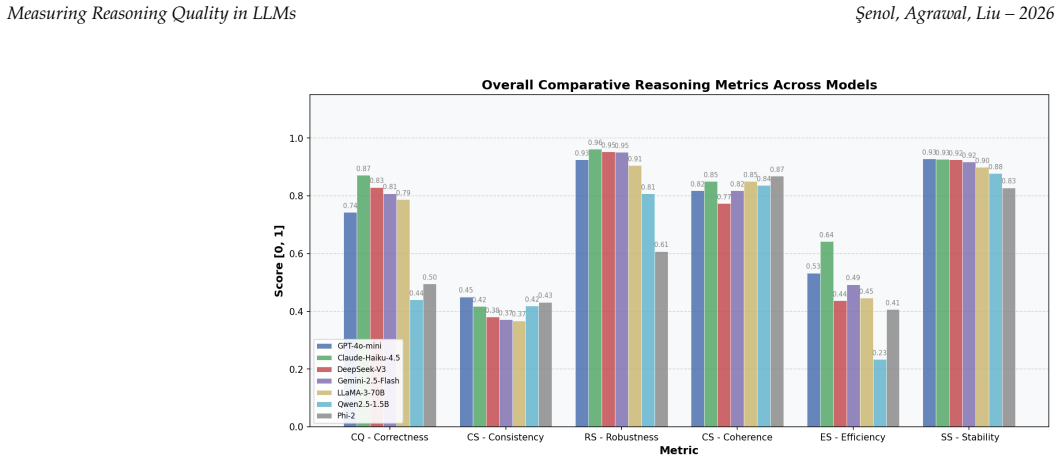
The authors establish a six-dimension framework (Correctness, Consistency, Robustness, Logical Coherence, Efficiency, Stability) that extracts distinct signals from model behavior on benchmarks; they report that logical coherence correlates near zero with correctness, that this orthogonality produces ranking reversals under different weighting schemes, and that eleven of fifteen dimension pairs meet discriminant-validity criteria.
What carries the argument
The six-dimension behavioral framework that scores model outputs on Correctness, Consistency, Robustness, Logical Coherence, Efficiency, and Stability from responses to fixed benchmark items.
If this is right
- Correct final answers can still fail accountability audits when the reasoning path is incoherent.
- Accuracy-only leaderboards can produce rankings that reverse when compliance or stability dimensions receive priority.
- Deployment choices can now separate models that are accurate but unstable from those that are both accurate and coherent.
- No single dimension can stand in for the full set because most pairs are independent.
Where Pith is reading between the lines
- Auditors in regulated domains could require separate logical-coherence thresholds even when accuracy is high.
- Future benchmarks might need to include items designed to stress each dimension independently rather than only final-answer difficulty.
- Model developers could optimize explicitly for the weakest dimension in a given profile instead of chasing aggregate accuracy.
Load-bearing premise
The six dimensions can be extracted as independent, reliable signals from the chosen benchmarks rather than reflecting artifacts of how items or scores are chosen.
What would settle it
A replication on new reasoning tasks that finds a statistically significant positive correlation between logical coherence scores and correctness scores would undermine the orthogonality result.
Figures



read the original abstract
LLMs have achieved remarkable success in complex reasoning tasks, yet current evaluation approaches predominantly rely on final-answer correctness, offering limited insight into the underlying reasoning processes that produce those answers. To address this gap, this study proposes a unified multi-dimensional framework for measuring reasoning quality in LLMs from a behavioral perspective, operationalizing six theoretically grounded dimensions: Correctness (CQ), Consistency (CS), Robustness (RS), Logical Coherence (LS), Efficiency (ES), and Stability (SS). Extensive experiments on seven LLMs across 975 items from four benchmarks demonstrate that the framework reveals behaviors invisible to accuracy-only metrics. Notably, logical coherence is orthogonal to correctness (r = -0.172, ns), confirming that correct answers can arise from incoherent reasoning, while Claude-Haiku-4.5 achieves the highest multi-dimensional score (Q_bal = 0.778). Furthermore, the framework exposes critical ranking inversions: DeepSeek-V3 ranks second under accuracy-priority but fifth under legal/compliance weighting, a reversal that single-metric evaluation cannot detect. Discriminant validity confirms 11/15 dimension pairs are independent (|r| < 0.50), providing psychometric support for treating each dimension as a distinct signal. The dimensional profiles produced by the framework directly support three classes of deployment decision: identifying models whose reasoning traces would fail accountability audits despite correct final answers (LS--CQ orthogonality); preventing ranking errors caused by accuracy-only benchmarking; and ensuring that no single metric silently substitutes for the six independent signals the framework captures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multi-dimensional behavioral framework to evaluate LLM reasoning quality beyond final-answer accuracy. It operationalizes six dimensions—Correctness (CQ), Consistency (CS), Robustness (RS), Logical Coherence (LS), Efficiency (ES), and Stability (SS)—and applies them to seven LLMs across 975 items from four benchmarks. Reported results include orthogonality between LS and CQ (r = -0.172, ns), Claude-Haiku-4.5 achieving the highest balanced score (Q_bal = 0.778), ranking inversions under different weightings (e.g., DeepSeek-V3 second by accuracy but fifth under legal/compliance), and discriminant validity for 11/15 dimension pairs (|r| < 0.50).
Significance. If the six dimensions can be shown to yield independent signals from behavioral traces, the framework would usefully extend accuracy-only evaluation by surfacing cases where correct answers arise from incoherent reasoning and by exposing ranking reversals invisible to single-metric benchmarks. The multi-model, multi-benchmark design supplies a reasonable empirical scope for testing such claims.
major comments (3)
- [§3] §3 (Framework Operationalization): Explicit rubrics, equations, or pseudocode must be supplied for scoring Logical Coherence (LS) on the same items used for Correctness (CQ). The orthogonality result (r = -0.172) is load-bearing for the central claim that the dimensions are distinct; without confirmation that LS scoring excludes the gold-answer label or lexical overlap with correct solutions, the near-zero correlation cannot be distinguished from an artifact of shared item features or scoring rules.
- [Results section, correlation analysis] Results, correlation table (presumably Table 4 or equivalent): The paper reports 11/15 pairs independent (|r| < 0.50) but does not state whether any multiple-comparison correction was applied to the 15 pairwise tests or how item-level scores were aggregated across the 975 items. This detail is required to interpret the discriminant-validity claim.
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The definition and weighting formula for the balanced quality score Q_bal must be given explicitly, including how the six dimensions are combined and whether any dimension is normalized by accuracy. The model ranking by Q_bal is presented as a key outcome yet cannot be reproduced or critiqued without the precise aggregation rule.
minor comments (2)
- [Abstract and §5] The abstract refers to 'legal/compliance weighting' that produces a ranking reversal; the corresponding section should list the exact weights applied to each dimension.
- [§2] Notation for the six dimensions (CQ, CS, RS, LS, ES, SS) is introduced without a summary table; a single table listing each dimension, its theoretical grounding, and its operational proxy would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to improve clarity and reproducibility. We address each major comment below and will revise the manuscript to supply the requested operational details, formulas, and methodological clarifications.
read point-by-point responses
-
Referee: [§3] §3 (Framework Operationalization): Explicit rubrics, equations, or pseudocode must be supplied for scoring Logical Coherence (LS) on the same items used for Correctness (CQ). The orthogonality result (r = -0.172) is load-bearing for the central claim that the dimensions are distinct; without confirmation that LS scoring excludes the gold-answer label or lexical overlap with correct solutions, the near-zero correlation cannot be distinguished from an artifact of shared item features or scoring rules.
Authors: We agree that explicit operationalization is required to substantiate the independence claim. In the revised manuscript we will insert detailed rubrics, equations, and pseudocode for LS. These will specify that LS is scored exclusively from the reasoning trace, with no access to the gold label and no use of lexical overlap metrics with the correct solution. This addition will confirm that the reported orthogonality is not an artifact. revision: yes
-
Referee: [Results section, correlation analysis] Results, correlation table (presumably Table 4 or equivalent): The paper reports 11/15 pairs independent (|r| < 0.50) but does not state whether any multiple-comparison correction was applied to the 15 pairwise tests or how item-level scores were aggregated across the 975 items. This detail is required to interpret the discriminant-validity claim.
Authors: We will add the missing methodological details in the revised Results section. No multiple-comparison correction was applied because the 15 correlations serve a descriptive, exploratory role in assessing discriminant validity rather than confirmatory inference. Item-level dimension scores were aggregated by simple averaging across the 975 items per model; we will also report this aggregation rule explicitly. revision: yes
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The definition and weighting formula for the balanced quality score Q_bal must be given explicitly, including how the six dimensions are combined and whether any dimension is normalized by accuracy. The model ranking by Q_bal is presented as a key outcome yet cannot be reproduced or critiqued without the precise aggregation rule.
Authors: We will supply the explicit definition of Q_bal in the revised §4. Q_bal is the unweighted arithmetic mean of the six dimension scores after each has been min-max normalized to [0,1]; no dimension is further normalized by accuracy. The precise equation and normalization procedure will be stated so that the reported value (0.778) and all model rankings can be reproduced. revision: yes
Circularity Check
No circularity: framework defined independently then applied empirically
full rationale
The paper first defines the six-dimensional framework (CQ, CS, RS, LS, ES, SS) from behavioral traces on 975 benchmark items, then reports empirical correlations (e.g., LS-CQ r = -0.172) and discriminant validity (11/15 pairs independent). No equations, self-citations, or operationalization steps are shown that reduce any dimension score or correlation to another by algebraic construction, fitted parameters, or renaming. The orthogonality result is presented as an observed outcome rather than a definitional necessity, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mathematical Essays on Rational Human Behavior in a Social Setting; Wiley: New York, 1957
Simon, H.A.Models of Man: Social and Rational. Mathematical Essays on Rational Human Behavior in a Social Setting; Wiley: New York, 1957
1957
-
[2]
Stanovich, K.E.Rationality and the Reflective Mind; Oxford University Press: New York, 2011
2011
-
[3]
Thagard, P .Coherence in Thought and Action; Life and Mind: Philosophical Issues in Biology and Psychology, MIT Press: Cambridge, MA, 2000
2000
-
[4]
Lieder, F.; Griffiths, T.L. Resource-Rational Analysis: Understanding Human Cognition as the Optimal Use of Limited Computational Resources.Behavioral and Brain Sciences2020,43, e1. https://doi.org/10.1017/S0140525X1900061X
-
[5]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, T.; Chen, A.; Radhakrishnan, A.; Steiner, B.; Denison, C.; Hernandez, D.; Li, D.; Durmus, E.; Hubinger, E.; Kernion, J.; et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.137022023
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Chain-of-thought is not explainability.Preprint, alphaXiv2025, p
Barez, F.; Wu, T.Y.; Arcuschin, I.; Lan, M.; Wang, V .; Siegel, N.; Collignon, N.; Neo, C.; Lee, I.; Paren, A.; et al. Chain-of-thought is not explainability.Preprint, alphaXiv2025, p. v1
-
[7]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2023, [arXiv:cs.CL/2203.11171]. 13 Measuring Reasoning Quality in LLMs ¸ Senol, Agrawal, Liu – 2026
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems2023,36, 74952–74965
Turpin, M.; Michael, J.; Perez, E.; Bowman, S. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems2023,36, 74952–74965
-
[9]
A comprehensive evaluation of cognitive biases in LLMs
Malberg, S.; Poletukhin, R.; Schuster, C.; Groh, G.G. A comprehensive evaluation of cognitive biases in LLMs. In Proceedings of the Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities, 2025, pp. 578–613
2025
-
[10]
An Integrated Theory of the Mind.Psychological Review2004,111, 1036–1060
Anderson, J.R.; Bothell, D.; Byrne, M.D.; Douglass, S.; Lebiere, C.; Qin, Y. An Integrated Theory of the Mind.Psychological Review2004,111, 1036–1060. https://doi.org/10.1037/0033-295X.111. 4.1036
-
[11]
Evans, J.S.B.T.Hypothetical Thinking: Dual Processes in Reasoning and Judgement; Essays in Cognitive Psychology, Psychology Press: Hove, 2007
2007
-
[12]
Prospect Theory: An Analysis of Decision under Risk.Econometrica 1979,47, 263–292
Kahneman, D.; Tversky, A. Prospect Theory: An Analysis of Decision under Risk.Econometrica 1979,47, 263–292. https://doi.org/10.2307/1914185
-
[13]
Gigerenzer, G.; Selten, R.Bounded Rationality: The Adaptive Toolbox; MIT Press: Cambridge, MA, 2001
2001
-
[14]
A foundation model to predict and capture human cognition
Binz, M.; Akata, E.; Bethge, M.; Brändle, F.; Callaway, F.; Coda-Forno, J.; Dayan, P .; Demircan, C.; Eckstein, M.K.; Éltet˝ o, N.; et al. A foundation model to predict and capture human cognition. Nature2025, pp. 1–8
-
[15]
A cognitive theory of reasoning and choice
Bordalo, P .; Gennaioli, N.; Lanzani, G.; Shleifer, A. A cognitive theory of reasoning and choice. Technical report, National Bureau of Economic Research, 2025
2025
-
[16]
Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems2022,35, 24824–24837
Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V .; Zhou, D.; et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems2022,35, 24824–24837
-
[17]
Large language models are zero-shot reasoners.Advances in neural information processing systems2022,35, 22199–22213
Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners.Advances in neural information processing systems2022,35, 22199–22213
-
[18]
Paul, D.; West, R.; Bosselut, A.; Faltings, B. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning.arXiv preprint arXiv:2402.139502024
-
[19]
Kumar, P .; Mishra, S. Robustness in Large Language Models: A Survey of Mitigation Strategies and Evaluation Metrics.arXiv preprint arXiv:2505.186582025
-
[20]
Robustness of llms to perturbations in text.arXiv preprint arXiv:2407.089892024
Singh, A.; Singh, N.; Vatsal, S. Robustness of llms to perturbations in text.arXiv preprint arXiv:2407.089892024
-
[21]
Bogavelli, T.; Bamgbose, O.; Melançon, G.G.; Riols, F.; Sharma, R. Evaluating Robustness of Large Language Models in Enterprise Applications: Benchmarks for Perturbation Consistency Across Formats and Languages.arXiv preprint arXiv:2601.063412026
-
[22]
Are Your LLMs Capable of Stable Reasoning? In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2025, 2025, pp
Liu, J.; Liu, H.; Xiao, L.; Wang, Z.; Liu, K.; Gao, S.; Zhang, W.; Zhang, S.; Chen, K. Are Your LLMs Capable of Stable Reasoning? In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 17594–17632
2025
-
[23]
Mondorf, P .; Plank, B. Beyond accuracy: evaluating the reasoning behavior of large Language models–A survey.arXiv preprint arXiv:2404.018692024
-
[24]
LogicAsker: Evaluating and Improving the Logical Reasoning Ability of Large Language Models
Wan, Y.; Wang, W.; Yang, Y.; Yuan, Y.; Huang, J.t.; He, P .; Jiao, W.; Lyu, M. LogicAsker: Evaluating and Improving the Logical Reasoning Ability of Large Language Models. In Proceedings of the Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing; Al- Onaizan, Y.; Bansal, M.; Chen, Y.N., Eds., Miami, Florida, USA, Novembe...
-
[25]
Faithful chain-of-thought reasoning
Lyu, Q.; Havaldar, S.; Stein, A.; Zhang, L.; Rao, D.; Wong, E.; Apidianaki, M.; Callison-Burch, C. Faithful chain-of-thought reasoning. In Proceedings of the Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Lo...
2023
-
[26]
Yang, S.; Chiang, W.L.; Zheng, L.; Gonzalez, J.E.; Stoica, I. Rethinking benchmark and con- tamination for language models with rephrased samples.arXiv preprint arXiv:2311.04850 2023
-
[27]
Multi-Dimensional Evaluation of Auto-Generated Chain-of-Thought Traces in Reasoning Models.AI2026,7, 35
Becerra-Monsalve, L.F.; Sanchez-Torres, G.; Branch-Bedoya, J.W. Multi-Dimensional Evaluation of Auto-Generated Chain-of-Thought Traces in Reasoning Models.AI2026,7, 35. 14 Measuring Reasoning Quality in LLMs ¸ Senol, Agrawal, Liu – 2026
2026
-
[28]
Training Verifiers to Solve Math Word Problems
Cobbe, K.; Kosaraju, V .; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems, 2021, [arXiv:cs.LG/2110.14168]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Measuring Massive Multitask Language Understanding.Proceedings of the International Conference on Learning Representations (ICLR)2021
Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding.Proceedings of the International Conference on Learning Representations (ICLR)2021
2021
-
[30]
Anderson, J.R.The Adaptive Character of Thought; Lawrence Erlbaum Associates: Hillsdale, NJ, 1990
1990
-
[31]
Oaksford, M.; Chater, N.Bayesian Rationality: The Probabilistic Approach to Human Reasoning; Oxford Cognitive Science Series, Oxford University Press: Oxford, 2007
2007
-
[32]
Geva, M.; Khashabi, D.; Segal, E.; Khot, T.; Roth, D.; Berant, J. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies.Transactions of the Association for Computational Linguistics2021,9, 346–361. https://doi.org/10.1162/tacl_a_00370. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.