QuoVLA: Quotient Space for Vision-Language-Action Models
Pith reviewed 2026-06-30 12:07 UTC · model grok-4.3
The pith
Pretrained VLM latents already contain the information needed for robot control but remain overcomplete by distinguishing equivalent prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
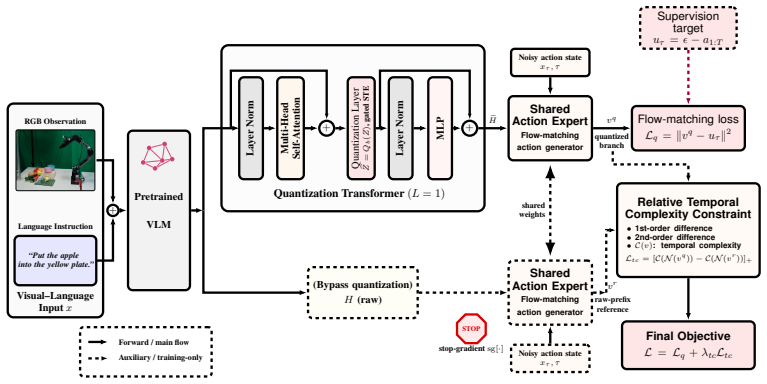
The Quotient Theory for VLA states that pretrained VLM latents are not action-insufficient but action-sufficient: they already contain the information needed for control, yet remain overcomplete by distinguishing prompt-level variations that induce the same optimal action behavior. QuoVLA operationalizes the theory by compressing these latents into action-sufficient representations via a quantization module and dual-branch design with relative temporal-complexity regularization, preserving action-relevant information while removing prompt-level redundancy.
What carries the argument
Quotient-space framework that maps overcomplete VLM latents to action-sufficient representations by collapsing prompt variations that share the same optimal action, implemented via quantization module plus dual-branch design with temporal regularization.
If this is right
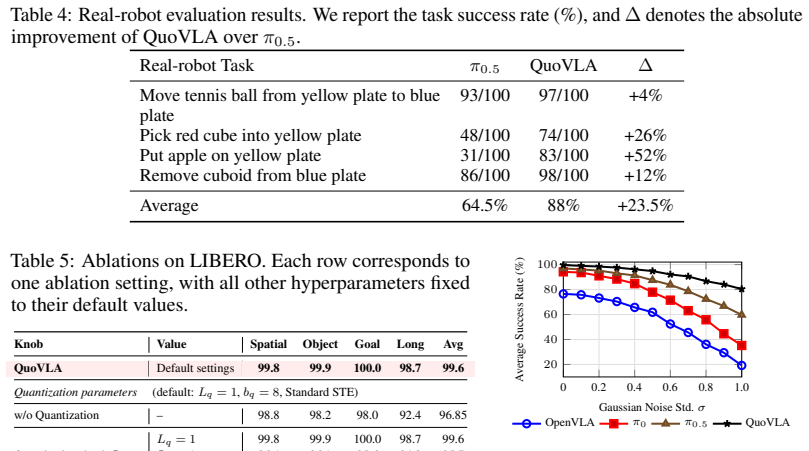
- QuoVLA achieves strong performance across multiple VLA benchmarks.
- Particularly notable improvements appear in generalization under visual, linguistic, and environmental distribution shifts.
- Action-relevant information is preserved while prompt-level redundancy is removed.
- VLM latents can receive action-learning signals directly without shielding.
Where Pith is reading between the lines
- The same quotient construction could be tested on other multimodal control settings where input variations do not change the required output.
- If the premise holds, training pipelines might shift emphasis toward identifying action-invariant equivalence classes rather than expanding model capacity.
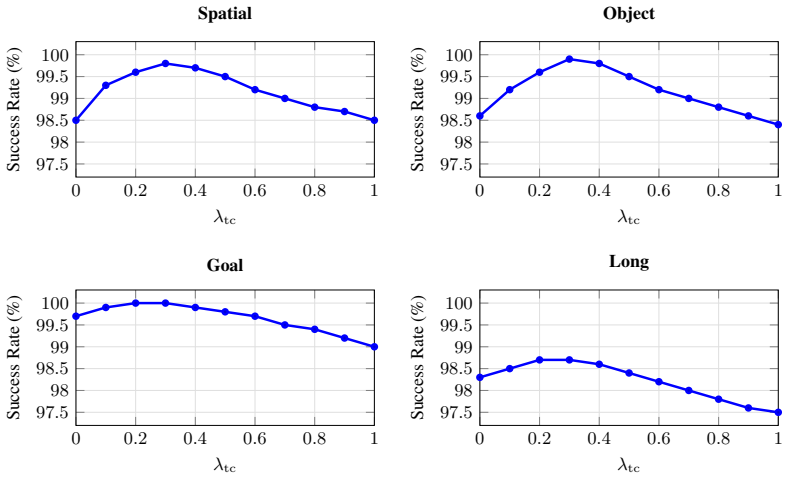
- Long-horizon tasks with accumulating temporal complexity could serve as a natural stress test for the regularization term.
Load-bearing premise
Overcompleteness in VLM latents stems mainly from prompt variations that map to identical optimal actions, and the quantization-plus-dual-branch procedure isolates the action components without discarding control-critical information.
What would settle it
A controlled ablation in which the quantization and dual-branch components are removed yet performance and generalization under distribution shifts remain unchanged or improve would falsify the claim that the quotient compression is required.
Figures

read the original abstract
Vision-Language-Action (VLA) models commonly adapt pretrained Vision-Language Models (VLMs) to robot control by mapping visual observations and language instructions to continuous actions. Existing approaches typically take an action-insufficiency view, assuming that pretrained VLM latents either lack directly usable action information or should be shielded from action-learning signals. Against this view, our \textit{Quotient Theory for VLA} shows that pretrained VLM latents are not action-insufficient but action-sufficient: they already contain the information needed for control, yet remain overcomplete by distinguishing prompt-level variations that induce the same optimal action behavior. To operationalize this theory, we propose QuoVLA, a quotient-space framework for VLA that compresses pretrained VLM latents into action-sufficient representations. Specifically, QuoVLA instantiates this principle with a quantization module and a dual-branch design with relative temporal-complexity regularization, preserving action-relevant information while removing prompt-level redundancy. Extensive experiments across multiple benchmarks demonstrate that QuoVLA achieves strong performance, with particularly notable improvements in generalization under visual, linguistic, and environmental distribution shifts. Our code will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper challenges the prevailing action-insufficiency view of pretrained VLM latents in Vision-Language-Action models. It advances a Quotient Theory asserting that these latents are already action-sufficient yet overcomplete because they distinguish prompt-level variations that map to identical optimal actions. To operationalize the theory, QuoVLA introduces a quantization module together with a dual-branch architecture regularized by relative temporal-complexity terms that compresses the latents into action-relevant representations while discarding prompt redundancy. The manuscript claims that this yields strong performance and improved generalization under visual, linguistic, and environmental shifts across multiple benchmarks, with code to be released.
Significance. If the central claim and experimental results hold, the work supplies a concrete alternative theoretical framing for VLA design that could reduce the need to shield VLM features from action gradients and improve sample efficiency and robustness. The explicit commitment to public code release is a positive contribution to reproducibility.
minor comments (1)
- Abstract: the statement that 'extensive experiments... demonstrate that QuoVLA achieves strong performance, with particularly notable improvements in generalization' is unsupported by any numerical results, baselines, ablation tables, or error bars, preventing assessment of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for their review and for providing an accurate summary of the manuscript's core contribution and claims. The positive remarks on potential impact and code release are appreciated. No specific major comments were enumerated in the report, so we have no point-by-point items to address. We remain available to supply additional details or clarifications that might resolve the uncertain recommendation.
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The abstract articulates a quotient-space theory positing that VLM latents are action-sufficient yet overcomplete due to prompt variations, operationalized via quantization and dual-branch regularization. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim is framed as an alternative view supported by experiments on generalization benchmarks, with no reduction of any prediction to a quantity defined by the method itself. The derivation remains independent of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[6]
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1.arXiv preprint arXiv:1602.02830, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulat- ing vision-language-action models: Train fast, run fast, generalize better.arXiv preprint arXiv:2505.23705, 2025
-
[8]
Yiyang Du, Zhanqiu Guo, Xin Ye, Liu Ren, and Chenyan Xiong. Embodiedmidtrain: Bridging the gap between vision-language models and vision-language-action models via mid-training. arXiv preprint arXiv:2604.20012, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language- action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi0.5 : a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. pi0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Contrastive Representation Regularization for Vision-Language-Action Models
Taeyoung Kim, Jimin Lee, Myungkyu Koo, Dongyoung Kim, Kyungmin Lee, Changyeon Kim, Younggyo Seo, and Jinwoo Shin. Contrastive representation regularization for vision-language- action models.arXiv preprint arXiv:2510.01711, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Zhixuan Liang, Yizhuo Li, Tianshuo Yang, Chengyue Wu, Sitong Mao, Tian Nian, Liuao Pei, Shunbo Zhou, Xiaokang Yang, Jiangmiao Pang, et al. Discrete diffusion vla: Bring- ing discrete diffusion to action decoding in vision-language-action policies.arXiv preprint arXiv:2508.20072, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Juyi Lin, Amir Taherin, Arash Akbari, Arman Akbari, Lei Lu, Guangyu Chen, Taskin Padir, Xiaomeng Yang, Weiwei Chen, Yiqian Li, et al. V ote: vision-language-action optimization with trajectory ensemble voting.arXiv preprint arXiv:2507.05116, 2025
-
[17]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[18]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
- [19]
-
[20]
Simvla: A simple vla baseline for robotic manipulation.arXiv preprint arXiv:2602.18224, 2026
Yuankai Luo, Woping Chen, Tong Liang, Baiqiao Wang, and Zhenguo Li. Simvla: A simple vla baseline for robotic manipulation.arXiv preprint arXiv:2602.18224, 2026
-
[21]
Language models are injective and hence invertible
Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, Andrea Santilli, Yannis Panagakis, and Emanuele Rodolà. Language models are injective and hence invertible. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[22]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[24]
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies.arXiv preprint arXiv:2509.04996, 2025
-
[25]
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision- language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. Vla-jepa: Enhancing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098, 2026
-
[27]
Sheng Wang. Roboflamingo-plus: Fusion of depth and rgb perception with vision-language models for enhanced robotic manipulation.arXiv preprint arXiv:2503.19510, 2025
-
[28]
Vla-adapter: An effective paradigm for tiny-scale vision-language-action model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, et al. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model. InProceedings of the AAAI conference on artificial intelligence, volume 40, pages 18638–18646, 2026
2026
-
[29]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[30]
Shuai Yang, Hao Li, Bin Wang, Yilun Chen, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, and Jiangmiao Pang. Instructvla: Vision-language-action instruction tuning from understanding to manipulation.arXiv preprint arXiv:2507.17520, 2025
-
[31]
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Jinhui Ye, Fangjing Wang, Ning Gao, Junqiu Yu, Yangkun Zhu, Bin Wang, Jinyu Zhang, Weiyang Jin, Yanwei Fu, Feng Zheng, et al. St4vla: Spatially guided training for vision- language-action models.arXiv preprint arXiv:2602.10109, 2026
-
[33]
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. Vlm4vla: Revisiting vision-language-models in vision-language-action models.arXiv preprint arXiv:2601.03309, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[35]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
Xueyang Zhou, Yangming Xu, Guiyao Tie, Yongchao Chen, Guowen Zhang, Duanfeng Chu, Pan Zhou, and Lichao Sun. Libero-pro: Towards robust and fair evaluation of vision-language- action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 12 A Appendix A.1 Simulation Benchmark Details We evaluate QuoVLA on four simulation b...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.