Quaternion Self-Attention with Shared Scores
Pith reviewed 2026-06-30 12:04 UTC · model grok-4.3
The pith
When quaternion linear projections pre-mix components, shared attention scores span the same interaction subspace as independent component-wise scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
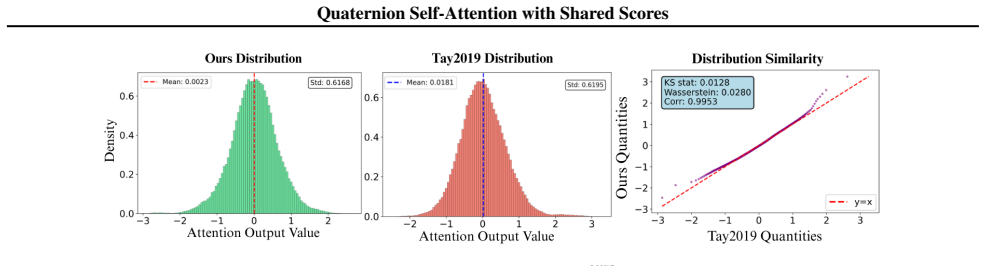
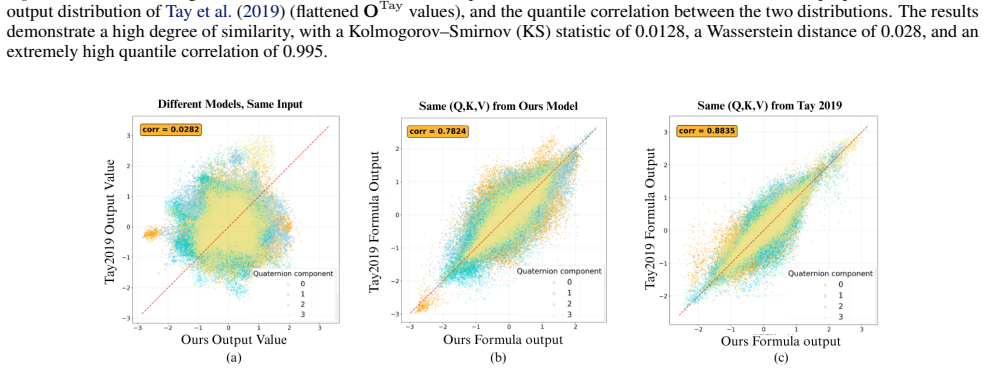
When queries and keys are produced by quaternion linear projections that induce component pre-mixing, the component-wise and shared scores lie in the same interaction subspace, indicating that independent component-wise attention primarily re-parameterizes the same interactions rather than expanding the feature interaction space.
What carries the argument
The shared-score mechanism that computes a single real-valued score using the quaternion inner product and shares the resulting attention distribution across components.
If this is right
- Score computation multiplications are reduced by 75%.
- Softmax operations drop from four to one.
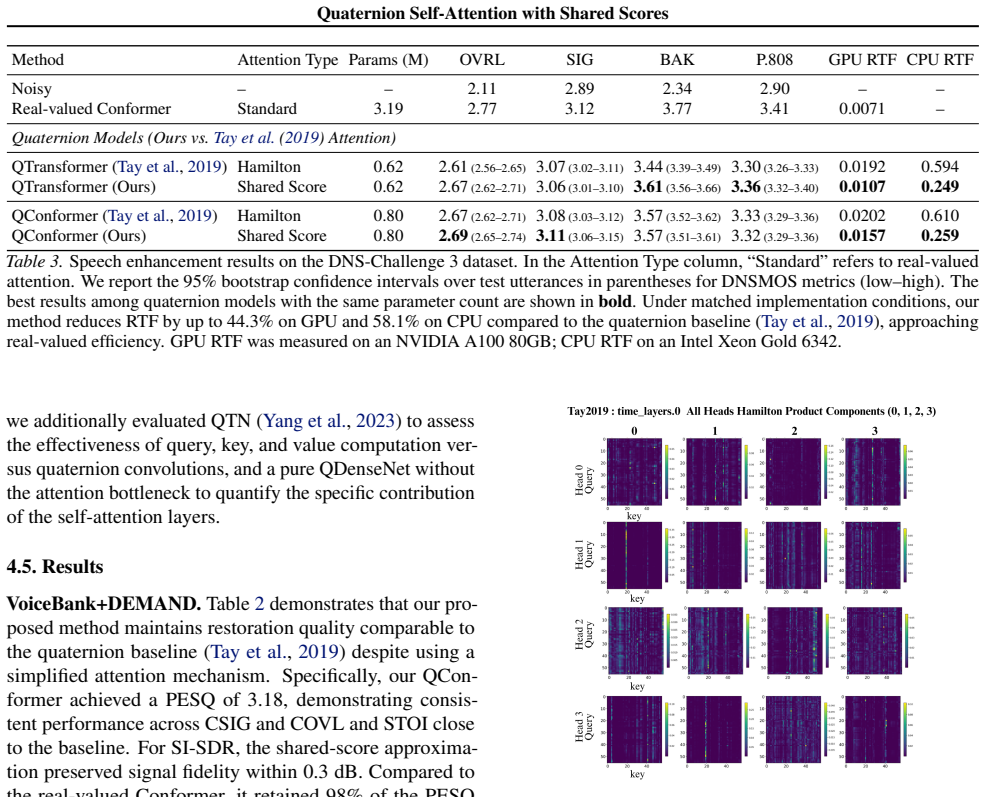
- Inference time is reduced by up to 44.3% on GPU and 58.1% on CPU in speech enhancement without quality loss.
- Similar efficiency gains appear in vision and natural language processing tasks.
Where Pith is reading between the lines
- Practitioners can adopt the shared-score version for efficiency gains when the pre-mixing condition holds without loss of interaction capacity.
- The pre-mixing property of quaternion projections could be checked in other models to confirm the equivalence.
- Shared scoring ideas may apply to other multi-dimensional neural network components.
- These reductions could support scaling quaternion models to larger sizes or lower-resource hardware.
Load-bearing premise
The quaternion linear projections for queries and keys induce component pre-mixing.
What would settle it
Finding quaternion linear projections that do not induce component pre-mixing yet produce different spanned subspaces for shared versus component-wise scores.
Figures


read the original abstract
Quaternion neural networks are parameter-efficient and model multidimensional dependencies by representing four related features as a single entity. However, existing quaternion self-attention computes component-wise scores and applies independent softmax operations to each component, which increases the computational cost and allows attention distributions to diverge across components. We propose a shared-score quaternion self-attention mechanism that computes a single real-valued score using the quaternion inner product and applies a shared attention distribution across all components. This reduces score-computation multiplications by 75% and the number of softmax operations from four to one. We prove that, when queries and keys are produced by quaternion linear projections that induce component pre-mixing, the component-wise and shared scores lie in the same interaction subspace, indicating that independent component-wise attention primarily re-parameterizes the same interactions rather than expanding the feature interaction space. In speech enhancement, our method reduces inference time by up to 44.3% on a GPU and 58.1% on a CPU while maintaining quality, with consistent trends across vision and natural language processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a shared-score quaternion self-attention mechanism that replaces component-wise scores and independent softmaxes with a single real-valued score computed via the quaternion inner product. This yields a 75% reduction in score-computation multiplications and reduces softmax operations from four to one. Under the stated condition that queries and keys arise from quaternion linear projections inducing component pre-mixing, the authors prove that component-wise and shared scores occupy the same interaction subspace, implying that independent component-wise attention largely re-parameterizes rather than expands the interaction space. Experiments report inference-time reductions of up to 44.3% (GPU) and 58.1% (CPU) on speech enhancement while preserving quality, with analogous trends shown for vision and NLP tasks.
Significance. If the conditional subspace result holds, the work supplies both a concrete efficiency improvement for quaternion networks and a theoretical clarification of the representational capacity of component-wise versus shared attention. The explicit proof of subspace equivalence (when the pre-mixing premise is met) and the reproducible efficiency measurements constitute clear strengths.
major comments (1)
- [Abstract / proof section] Abstract and the proof section: the subspace-equivalence claim is explicitly conditional on quaternion linear projections inducing component pre-mixing, yet the manuscript provides no explicit verification procedure, numerical check, or experimental confirmation that this condition holds for the projections used in the reported models; because the claim that independent attention 'primarily re-parameterizes the same interactions' rests on this premise, its verification details are load-bearing.
minor comments (2)
- [Abstract] The abstract states the 75% multiplication reduction and the four-to-one softmax reduction; these figures should be cross-referenced to the precise operation counts in the complexity analysis section for immediate verification.
- [Method section] Notation for the quaternion inner product and the resulting real-valued score should be introduced with a single displayed equation early in the method section to avoid repeated inline definitions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the conditional nature of the subspace-equivalence result. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract / proof section] Abstract and the proof section: the subspace-equivalence claim is explicitly conditional on quaternion linear projections inducing component pre-mixing, yet the manuscript provides no explicit verification procedure, numerical check, or experimental confirmation that this condition holds for the projections used in the reported models; because the claim that independent attention 'primarily re-parameterizes the same interactions' rests on this premise, its verification details are load-bearing.
Authors: We agree that the manuscript does not supply an explicit verification procedure or numerical check confirming that the quaternion linear projections in the reported models induce component pre-mixing. The theoretical claim is therefore presented conditionally, and the absence of such a check leaves the practical applicability of the subspace result less firmly established than it could be. In the revised version we will add a short subsection (placed after the proof) that (i) states a concrete, reproducible verification procedure based on inspecting the effective mixing induced by the quaternion weight matrices and (ii) reports a numerical check on the actual projection layers used in the speech-enhancement, vision, and NLP experiments. This addition will make the load-bearing premise verifiable without altering the existing proof or experimental results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a new shared-score quaternion self-attention via the quaternion inner product (a direct algorithmic change) and states a conditional mathematical proof that, under quaternion linear projections inducing component pre-mixing, component-wise and shared scores occupy the same interaction subspace. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, ansatz smuggled via citation, or renaming of a known result. The proof is presented as an independent mathematical claim conditional on an explicitly stated premise; the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
CMGAN : Conformer-based metric gan for speech enhancement
Cao, R., Abdulatif, S., and Bin, Y. CMGAN : Conformer-based metric gan for speech enhancement. pp.\ 936--940, 09 2022. doi:10.21437/Interspeech.2022-517
-
[3]
Chao, R., Cheng, W.-H., Quatra, M. L., Siniscalchi, S. M., Yang, C.-H. H., Fu, S.-W., and Tsao, Y. An investigation of incorporating mamba for speech enhancement. In 2024 IEEE Spoken Language Technology Workshop (SLT), pp.\ 302--308, 2024. doi:10.1109/SLT61566.2024.10832332
-
[4]
Learning to rotate: Quaternion transformer for complicated periodical time series forecasting
Chen, W., Wang, W., Peng, B., Wen, Q., Zhou, T., and Sun, L. Learning to rotate: Quaternion transformer for complicated periodical time series forecasting. KDD '22, pp.\ 146^^e2^^80^^93156, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450393850. doi:10.1145/3534678.3539234
-
[5]
Y., Ermon, S., Rudra, A., and R\' e , C
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and R\' e , C. Flashattention: fast and memory-efficient exact attention with io-awareness. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[6]
MetricGAN+ : An improved version of MetricGAN for speech enhancement
Fu, S.-W., Yu, C., Hsieh, T.-A., Plantinga, P., Ravanelli, M., Lu, X., and Tsao, Y. MetricGAN+ : An improved version of MetricGAN for speech enhancement. In Interspeech, pp.\ 201--205, 2021. doi:10.21437/Interspeech.2021-599
-
[7]
Gaudet, C. and Maida, A. Deep quaternion networks. pp.\ 1--8, 07 2018. doi:10.1109/IJCNN.2018.8489651
-
[8]
Grant, B. and Wang, P. Quaternion approximation networks for enhanced image classification and oriented object detection, 2025. URL https://arxiv.org/abs/2509.05512
-
[9]
Conformer: Convolution-augmented transformer for speech recognition
Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., and Pang, R. Conformer: Convolution-augmented transformer for speech recognition. In Proc. Interspeech, pp.\ 5036--5040, 2020
2020
-
[10]
u rlebeck, K., Habetha, K., and Spr \
G \"u rlebeck, K., Habetha, K., and Spr \"o ig, W. Holomorphic functions in the plane and n-dimensional space. 2007. URL https://api.semanticscholar.org/CorpusID:117407172
2007
-
[11]
Hamilton, W. R. S. On quaternions, or on a new system of imaginaries in algebra. 1847
-
[12]
Hashim, H. F. B. and Ogawa, T. Estimation of forearm motion based on emg using quaternion neural network. Journal of Advanced Computational Intelligence and Intelligent Informatics, 26 0 (3): 0 269--278, 2022. doi:10.20965/jaciii.2022.p0269
-
[13]
Hu, Y. and Loizou, P. C. Evaluation of objective quality measures for speech enhancement. IEEE Transactions on Audio, Speech, and Language Processing, 16 0 (1): 0 229--238, 2008. doi:10.1109/TASL.2007.911054
-
[14]
DCCRN : Deep complex convolution recurrent network for phase-aware speech enhancement
Hu, Y., Liu, Y., Lv, S., Xing, M., Zhang, S., Fu, Y., Wu, J., Zhang, B., and Xie, L. DCCRN : Deep complex convolution recurrent network for phase-aware speech enhancement. In Interspeech, pp.\ 2472--2476, 2020. doi:10.21437/Interspeech.2020-2537
-
[15]
Quaternion neural network and its application
Isokawa, T., Kusakabe, T., Matsui, N., and Peper, F. Quaternion neural network and its application. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, pp.\ 318--324. Springer, 2003
2003
-
[16]
Quaternionic neural networks: Fundamental properties and applications
Isokawa, T., Matsui, N., and Nishimura, H. Quaternionic neural networks: Fundamental properties and applications. In Complex-Valued Neural Networks: Utilizing High-Dimensional Parameters, pp.\ 411--439. 2009
2009
-
[17]
Kim, E. and Seo, H. Se-conformer: Time-domain speech enhancement using conformer. pp.\ 2736--2740, 08 2021. doi:10.21437/Interspeech.2021-2207
-
[18]
End-to-end multi-task denoising for joint sdr and pesq optimization
Kim, J., El-Khamy, M., and Lee, J. End-to-end multi-task denoising for joint sdr and pesq optimization. ArXiv, abs/1901.09146, 2019. URL https://api.semanticscholar.org/CorpusID:59316572
-
[19]
Learning multiple layers of features from tiny images
Krizhevsky, A. Learning multiple layers of features from tiny images. pp.\ 32--33, 2009. URL https://www.cs.toronto.edu/ kriz/learning-features-2009-TR.pdf
2009
-
[20]
Le Roux, J., Wisdom, S., Erdogan, H., and Hershey, J. R. SDR -- Half-Baked or Well Done? In IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp.\ 626--630, 2019. doi:10.1109/ICASSP.2019.8683855
-
[21]
A si-sdr loss function based monaural source separation
Li, S., Liu, H., Zhou, Y., and Luo, Z. A si-sdr loss function based monaural source separation. In 2020 15th IEEE International Conference on Signal Processing (ICSP), volume 1, pp.\ 356--360, 2020. doi:10.1109/ICSP48669.2020.9321080
-
[22]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[23]
B., Tiwari, N., and Mishra, S
Mukhopadhyay, A., Joshi, R. B., Tiwari, N., and Mishra, S. Transformers at a fraction. In Northern Lights Deep Learning Conference 2025, 2024. URL https://openreview.net/forum?id=1U0kkt7ymn
2025
-
[24]
Muppidi, A. and Radfar, M. Speech emotion recognition using quaternion convolutional neural networks. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 6309--6313, 2021. doi:10.1109/ICASSP39728.2021.9414248
-
[25]
A quaternary version of the back-propagation algorithm
Nitta, T. A quaternary version of the back-propagation algorithm. In Proceedings of ICNN'95 - International Conference on Neural Networks, volume 5, pp.\ 2753--2756, 1995. doi:10.1109/ICNN.1995.488166
-
[26]
Quaternion convolutional neural networks for end-to-end automatic speech recognition
Parcollet, T., Zhang, Y., Morchid, M., Trabelsi, C., Linar^^c3^^a8s, G., De Mori, R., and Bengio, Y. Quaternion convolutional neural networks for end-to-end automatic speech recognition. 06 2018. doi:10.21437/Interspeech.2018-1898
-
[27]
Segan: Speech enhancement generative adversarial network
Pascual, S., Bonafonte, A., and Serr^^c3^^a0, J. Segan: Speech enhancement generative adversarial network. pp.\ 3642--3646, 08 2017. doi:10.21437/Interspeech.2017-1428
-
[28]
Reddy, C. K. A., Dubey, H., Gopal, V., Cutler, R., Braun, S., Gamper, H., Aichner, R., and Srinivasan, S. Icassp 2021 deep noise suppression challenge. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 6623--6627, 2021 a . doi:10.1109/ICASSP39728.2021.9415105
-
[29]
Reddy, C. K. A., Gopal, V., and Cutler, R. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 6493--6497, 2021 b . doi:10.1109/ICASSP39728.2021.9414878
-
[30]
Rix, A. W., Beerends, J. G., Hollier, M. P., and Hekstra, A. P. Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs. In 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 2, pp.\ 749--752, 2001. doi:10.1109/ICASSP.2001.941023
-
[31]
Saleem, N., Gunawan, T. S., Kartiwi, M., Nugroho, B. S., and Wijayanto, I. Nse-catnet: Deep neural speech enhancement using convolutional attention transformer network. IEEE Access, 11: 0 66979--66994, 2023. doi:10.1109/ACCESS.2023.3290908
-
[32]
Universal Score-based Speech Enhancement with High Content Preservation
Scheibler, R., Fujita, Y., Shirahata, Y., and Komatsu, T. Universal Score-based Speech Enhancement with High Content Preservation . In Interspeech 2024 , pp.\ 1165--1169, 2024. doi:10.21437/Interspeech.2024-138
-
[33]
N., Rosenkranz, T., and Maier, A
Schr \"o ter, H., Escalante-B., A. N., Rosenkranz, T., and Maier, A. DeepFilterNet : Perceptually motivated real-time speech enhancement. In Interspeech 2023, pp.\ 2008--2009, 2023. URL https://www.isca-archive.org/interspeech_2023/schroter23b_interspeech.html
2023
-
[34]
D., Ng, A., and Potts, C
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., and Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp.\ 1631--1642, Seattle, Washington, USA, October 2013. Association for Computational Linguistics. UR...
2013
-
[35]
Taal, C. H., Hendriks, R. C., Heusdens, R., and Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, pp.\ 4214--4217, 2010. doi:10.1109/ICASSP.2010.5495701
-
[36]
T., Rao, J., Zhang, S., Wang, S., Fu, J., and Hui, S
Tay, Y., Zhang, A., Luu, A. T., Rao, J., Zhang, S., Wang, S., Fu, J., and Hui, S. C. Lightweight and efficient neural natural language processing with quaternion networks. In Korhonen, A., Traum, D., and M \`a rquez, L. (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp.\ 1494--1503, Florence, Italy, July 2...
-
[37]
The diverse environments multi-channel acoustic noise database ( DEMAND ): A database of multichannel environmental noise recordings
Thiemann, J., Ito, N., and Vincent, E. The diverse environments multi-channel acoustic noise database ( DEMAND ): A database of multichannel environmental noise recordings. In Proceedings of Meetings on Acoustics, volume 19, pp.\ 035081. Acoustical Society of America, 2013
2013
-
[38]
Investigating rnn-based speech enhancement methods for noise-robust text-to-speech
Valentini-Botinhao, C., Wang, X., Takaki, S., and Yamagishi, J. Investigating rnn-based speech enhancement methods for noise-robust text-to-speech. In 9th ISCA Workshop on Speech Synthesis Workshop (SSW 9), pp.\ 146--152, 2016. doi:10.21437/SSW.2016-24
-
[39]
Wavenet: A generative model for raw audio
van den Oord , A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. In 9th ISCA Workshop on Speech Synthesis Workshop (SSW 9), pp.\ 125, 2016
2016
-
[40]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[41]
The voice bank corpus: Design, collection and data analysis of a large regional accent speech database
Veaux, C., Yamagishi, J., and King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proc. Int. Conf. Oriental COCOSDA, November 2013
2013
-
[42]
TSTNN : Two-stage transformer based neural network for speech enhancement in the time domain
Wang, K., He, B., and Zhu, W.-P. TSTNN : Two-stage transformer based neural network for speech enhancement in the time domain. In ICASSP, pp.\ 7098--7102, 2021
2021
-
[43]
Yamamoto, R., Song, E., and Kim, J.-M. Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 6199--6203, 2020. doi:10.1109/ICASSP40776.2020.9053795
-
[44]
Yamauchi, S., Nitta, T., and Ohnishi, T. Learning characteristics of reverse quaternion neural network. In 2025 International Joint Conference on Neural Networks (IJCNN), pp.\ 1--8, 2025. doi:10.1109/IJCNN64981.2025.11228907
-
[45]
PDMX: A large-scale public domain MusicXML dataset for symbolic music processing
Yan, H., Zhang, J., Fan, C., Zhou, Y., and Liu, P. Lisennet: Lightweight sub-band and dual-path modeling for real-time speech enhancement. In ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5, 2025. doi:10.1109/ICASSP49660.2025.10888272
-
[46]
Qtn: Quaternion transformer network for hyperspectral image classification
Yang, X., Cao, W., Lu, Y., and Zhou, Y. Qtn: Quaternion transformer network for hyperspectral image classification. IEEE Transactions on Circuits and Systems for Video Technology, 33 0 (12): 0 7370--7384, 2023. doi:10.1109/TCSVT.2023.3283289
-
[47]
Qean: quaternion-enhanced attention network for visual dance generation
Zhou, Z., Huo, Y., Huang, G., Zeng, A., Chen, X., Huang, L., and Li, Z. Qean: quaternion-enhanced attention network for visual dance generation. Vis. Comput., 41 0 (2): 0 961^^e2^^80^^93973, April 2024. ISSN 0178-2789. doi:10.1007/s00371-024-03376-5
-
[48]
Quaternion convolutional neural networks
Zhu, X., Xu, Y., Xu, H., and Chen, C. Quaternion convolutional neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), September 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.