Investigating the Interplay between Contextual and Parametric Chain-of-Thought Faithfulness under Optimization
Pith reviewed 2026-06-30 12:14 UTC · model grok-4.3
The pith
Optimizing parametric chain-of-thought faithfulness produces consistent gains across both contextual and parametric paradigms while contextual optimization does not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
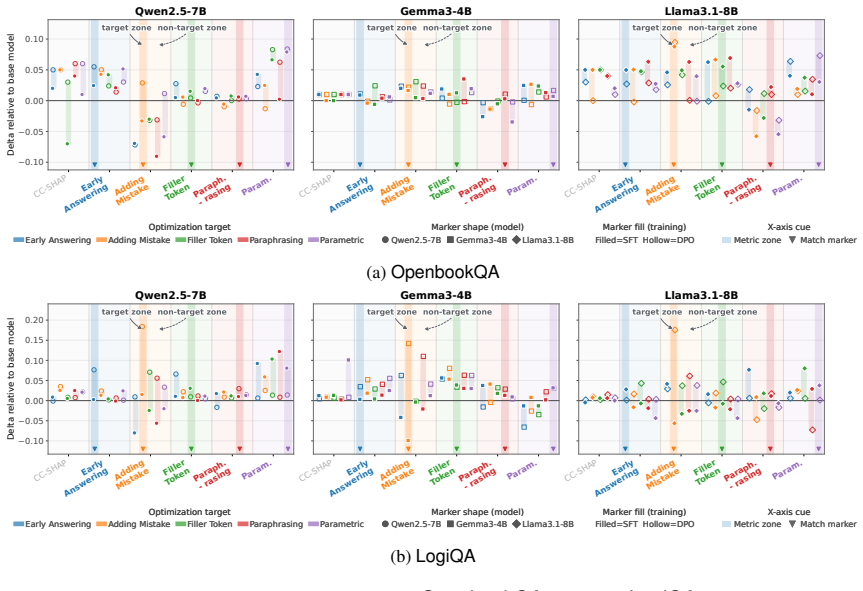
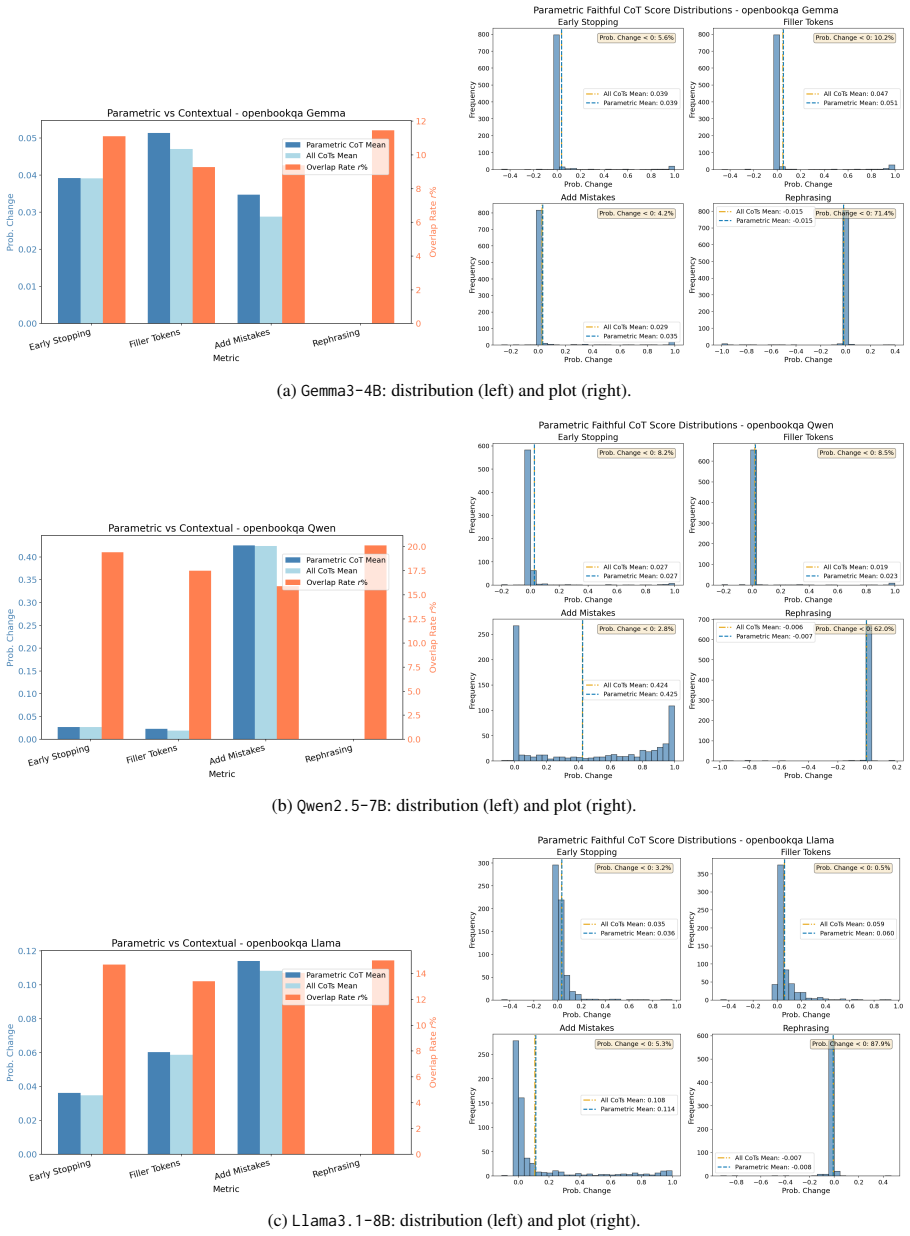
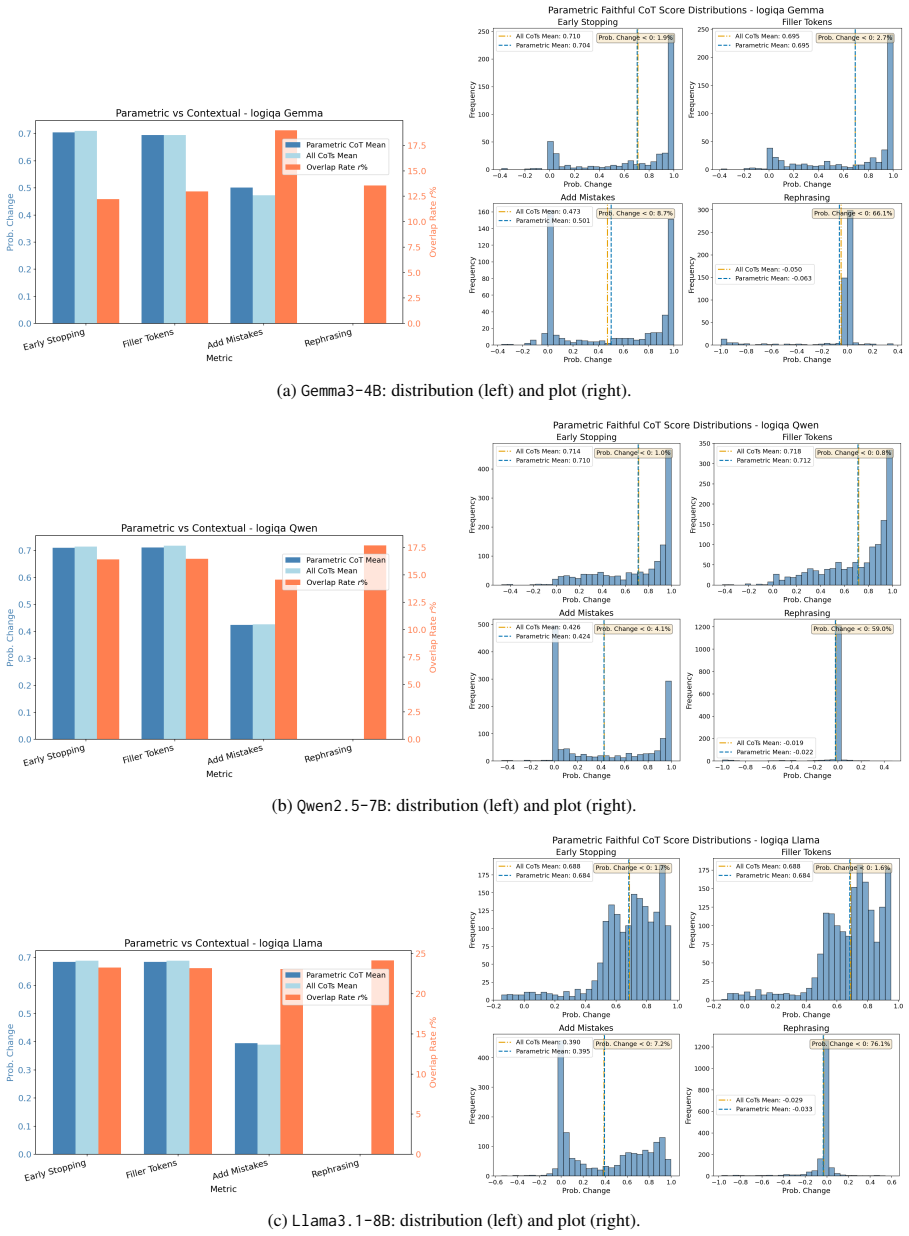
Across three models, two datasets, and six faithfulness metrics, the two paradigms are positively coupled, yet asymmetric: optimizing towards parametric faithfulness yields consistent gains across both paradigms, whereas the contextual counterpart delivers more variable gains. Within the contextual paradigm, faithfulness gains on one metric do not consistently transfer to others, implying that existing contextual metrics capture disjoint facets of faithfulness and exposing inherent trade-offs. These findings imply that CoT faithfulness is not a monolithic objective and therefore requires multifaceted optimization and evaluation.
What carries the argument
FaithMate, a unified preference-alignment interface that directs optimization toward either the contextual or parametric faithfulness paradigm in isolation.
If this is right
- Parametric faithfulness optimization can serve as a more stable route to broad improvements in chain-of-thought alignment.
- Contextual faithfulness cannot be improved in isolation without accepting variability across different perturbation-based metrics.
- CoT faithfulness evaluation must combine multiple metrics because single-metric gains do not indicate overall progress.
- The observed asymmetry suggests that interventions on parametric knowledge affect reasoning behavior more broadly than input perturbations do.
Where Pith is reading between the lines
- Joint optimization that balances both paradigms in one training run could reduce the variability seen when targeting contextual faithfulness alone.
- The same optimization interface might reveal similar asymmetries when applied to other model behaviors such as calibration or safety alignment.
- Developers auditing explanations may obtain more reliable coverage by first strengthening parametric faithfulness checks.
Load-bearing premise
That the preference-alignment training procedure can be aimed at one faithfulness paradigm without side effects that change measurements in the other paradigm or across metrics.
What would settle it
An experiment in which models optimized for parametric faithfulness show no measurable improvement on any contextual faithfulness metric, or in which gains on one contextual metric reliably appear on the others.
Figures


read the original abstract
Chain-of-Thought (CoT) faithfulness, i.e., whether CoTs genuinely reflect large language models' (LLM) underlying behavior, is typically evaluated under two disjoint paradigms: contextual faithfulness, measured by perturbing the input or CoT trace, and parametric faithfulness, assessed by intervening on a model's parametric knowledge. Yet prior work compares them only descriptively. We fill this gap by proposing FaithMate, a unified preference-alignment interface for optimizing models towards either faithfulness paradigm. It enables us to investigate the interplay between the two paradigms, examining whether and to what extent faithfulness gains generalize within and across paradigms. Across three models, two datasets, and six faithfulness metrics, we find that the two paradigms are positively coupled, yet asymmetric: optimizing towards parametric faithfulness yields consistent gains across both paradigms, whereas the contextual counterpart delivers more variable gains. Within the contextual paradigm, faithfulness gains on one metric do not consistently transfer to others, implying that existing contextual metrics capture disjoint facets of faithfulness and exposing inherent trade-offs. These findings imply that CoT faithfulness is not a monolithic objective and therefore requires multifaceted optimization and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FaithMate, a unified preference-alignment interface to optimize LLMs toward either contextual or parametric CoT faithfulness. Using experiments across three models, two datasets, and six metrics, it claims the paradigms are positively coupled yet asymmetric: parametric optimization produces consistent gains in both paradigms, contextual optimization yields more variable gains, and within-contextual gains fail to transfer across metrics, implying faithfulness is not monolithic and requires multifaceted optimization and evaluation.
Significance. If the asymmetry and non-transfer results hold after verification, the work provides the first optimization-based comparison of the two faithfulness paradigms, highlighting that CoT faithfulness involves trade-offs rather than a single objective. This could guide more targeted training and evaluation protocols for reliable LLM reasoning.
major comments (1)
- [Methods (FaithMate description)] The central asymmetry claim depends on FaithMate's ability to target one faithfulness paradigm in isolation. The abstract provides no implementation details on preference-pair construction, gradient updates, or controls for cross-paradigm correlations induced by the training process itself (see reader's weakest assumption and skeptic note). Without these, it is impossible to rule out that observed differences are artifacts of the optimization procedure rather than intrinsic properties of the paradigms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for clearer methodological details to substantiate the asymmetry claims. We address the major comment below and will revise the manuscript to improve clarity.
read point-by-point responses
-
Referee: [Methods (FaithMate description)] The central asymmetry claim depends on FaithMate's ability to target one faithfulness paradigm in isolation. The abstract provides no implementation details on preference-pair construction, gradient updates, or controls for cross-paradigm correlations induced by the training process itself (see reader's weakest assumption and skeptic note). Without these, it is impossible to rule out that observed differences are artifacts of the optimization procedure rather than intrinsic properties of the paradigms.
Authors: We agree the abstract is too concise on these points and will revise it to include a one-sentence overview of FaithMate. The full manuscript (Section 3) details the method: FaithMate is a DPO-based preference alignment framework. Preference pairs are constructed independently per paradigm—contextual pairs use input/CoT perturbations to create preferred faithful vs. unfaithful responses, while parametric pairs use knowledge interventions on model parameters. Standard DPO loss and gradient updates are applied separately for each target paradigm. To control for cross-paradigm correlations, we include (i) single-paradigm optimization ablations, (ii) joint optimization baselines, and (iii) random-pair controls, with results showing the asymmetry persists (Sections 4.2–4.3 and Appendix C). These elements support that the observed differences reflect paradigm properties rather than optimization artifacts. revision: yes
Circularity Check
No circularity: empirical optimization study with independent measurements
full rationale
The work is an empirical comparison of FaithMate optimization outcomes on contextual vs. parametric faithfulness across models, datasets, and metrics. Claims rest on observed experimental results rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations are present in the provided abstract or described methodology. The central findings (positive coupling with asymmetry) are falsifiable via the reported runs and do not rely on renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (1)
- FaithMate optimization hyperparameters
axioms (1)
- domain assumption Existing contextual and parametric faithfulness metrics accurately capture the intended notion of faithfulness without substantial measurement error or bias.
Reference graph
Works this paper leans on
-
[1]
Aligning What LLMs Do and Say: Towards Self-Consistent Explanations
Aligning What LLMs Do and Say: Towards Self-Consistent Explanations.Preprint, arXiv:2506.07523. Chirag Agarwal, Sree Harsha Tanneru, and Himabindu Lakkaraju
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
plausibility: On the (un) reliability of explanations from large language models , author=
Faithfulness vs. Plausibility: On the (Un)Reliability of Explanations from Large Lan- guage Models.Preprint, arXiv:2402.04614. Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy
-
[3]
Reasoning Models Don't Always Say What They Think
Reason- ing Models Don’t Always Say What They Think. Preprint, arXiv:2505.05410. James Chua and Owain Evans
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Are DeepSeek R1 And Other Reasoning Models More Faithful? Preprint, arXiv:2501.08156. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, Archie Sravankumar, Artem K...
-
[5]
The Llama 3 Herd of Models.Preprint, arXiv:2407.21783. Max Henning Höth, Kristian Kersting, Björn Deis- eroth, and Letitia Parcalabescu
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InICLR 2026 Workshop on Logical Reasoning of Large Language Models
AtManRL: Towards Faithful Reasoning via Differentiable Atten- tion Saliency. InICLR 2026 Workshop on Logical Reasoning of Large Language Models. Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Worts- man, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi
2026
-
[7]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring Faithful- ness in Chain-of-Thought Reasoning.arXiv preprint arXiv:2307.13702. Jiachun Li, Pengfei Cao, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, and Jun Zhao
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 10747–10765, Vienna, Austria
Towards Better Chain-of-Thought: A Reflection on Effectiveness and Faithfulness. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 10747–10765, Vienna, Austria. Association for Computational Linguistics. Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang
2025
-
[9]
InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium
Can a Suit of Armor Conduct Elec- tricity? A New Dataset for Open Book Question An- swering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, Brussels, Belgium. Association for Computational Linguistics. Letitia Parcalabescu and Anette Frank
2018
-
[10]
InFindings of the Association for Com- putational Linguistics: EMNLP 2024, pages 15012– 15032, Miami, Florida, USA
Making Reasoning Matter: Measur- ing and Improving Faithfulness of Chain-of-Thought Reasoning. InFindings of the Association for Com- putational Linguistics: EMNLP 2024, pages 15012– 15032, Miami, Florida, USA. Association for Com- putational Linguistics. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn
2024
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathemat- ical Reasoning in Open Language Models.Preprint, arXiv:2402.03300. Mingyang Song and Mao Zheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Model Merg- ing in the Era of Large Language Models: Meth- ods, Applications, and Future Directions.Preprint, arXiv:2603.09938. Anand Swaroop, Akshat Nallani, Saksham Uboweja, Adiliia Uzdenova, Michael Nguyen, Kevin Zhu, Sun- ishchal Dev, Ashwinee Panda, Vasu Sharma, and Maheep Chaudhary
-
[13]
Gemma 3 Technical Report. Preprint, arXiv:2503.19786. Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 9946–9971, Suzhou, China
Measuring Chain-of-Thought Faithfulness by Unlearning Rea- soning Steps. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 9946–9971, Suzhou, China. Association for Computational Linguistics. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou
2025
-
[15]
Qwen2.5 Technical Report.Preprint, arXiv:2412.15115. Richard J. Young
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Kerem Zaman and Shashank Srivastava
Measuring Faithfulness De- pends on How You Measure: Classifier Sensitivity in LLM Chain-of-Thought Evaluation.arXiv preprint arXiv:2603.20172. Kerem Zaman and Shashank Srivastava
-
[17]
InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29413–29437, Suzhou, China
A Causal Lens for Evaluating Faithfulness Metrics. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29413–29437, Suzhou, China. Association for Computational Lin- guistics. Kerem Zaman and Shashank Srivastava
2025
-
[18]
Is Chain- of-Thought Really Not Explainability? Chain-of- Thought Can Be Faithful without Hint Verbalization. Preprint, arXiv:2512.23032. A Training Paradigm A.1 Supervised Fine-Tuning The standard supervised fine-tuning loss is the neg- ative log-likelihood over the target tokens, where x denotes the input, yw = (s1, ...sT ) the preferred CoT, andθthe mo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
by minimizing the following loss, where σ(·) is the sigmoid function: LR(ϕ) =−E (xi,yiw,yi l )∼DDPO h logσ rϕ(xi, yi w)−r ϕ(xi, yi l) i (8) Policy Optimization.The policy πθ is then op- timized to maximize expected rewards guided by the reward functionr ϕ: J(θ) = max θ E xi∼DDPO y∼πθ(y|xi) rϕ(xi, y)−βlog πθ(y|xi) πref(y|xi) (9) where β denotes the weighti...
1951
-
[20]
{CoT Text}
D.2 Parametric Faithfulness Implementation For the parametric faithfulness metric, we fol- low Tutek et al. (2025) and implement FUR with NPO+KL unlearning. We segment each generated CoT into reasoning steps, unlearn one step at a time with KL regularization on a retain set sampled from other CoT steps in the same dataset, and then measure whether the mod...
2025
-
[21]
the coloration of fur is an inherited characteristic
Early An- swering and Filler Token is generally the optimal combination, which outperforms individual com- ponents and the base model on most contextual faithfulness metrics, but underperforms even the base model on Paraphrasing. H.2 Similarity Analysis To better understand the relationships among the task vectors produced by different faithfulness ob- je...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.