READER: Reasoning-Enhanced AI-Generated Text Detection
Pith reviewed 2026-06-30 11:02 UTC · model grok-4.3
The pith
A 1.5B-parameter model that reasons before deciding beats much larger LLMs at spotting AI text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
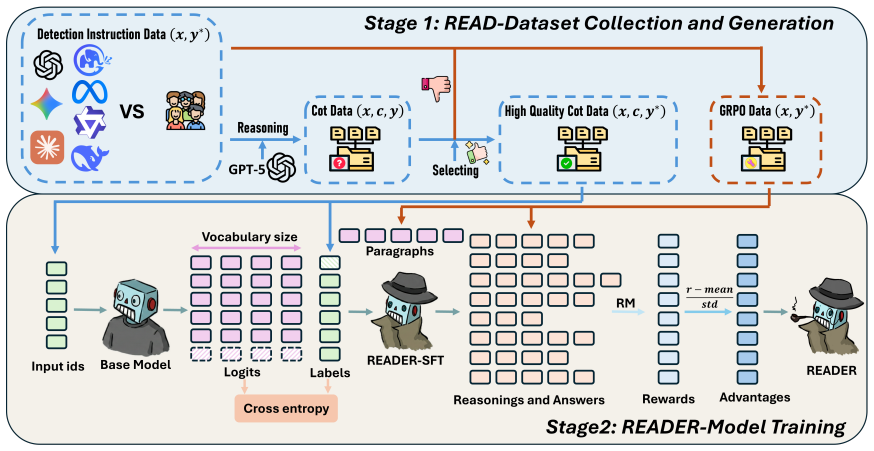
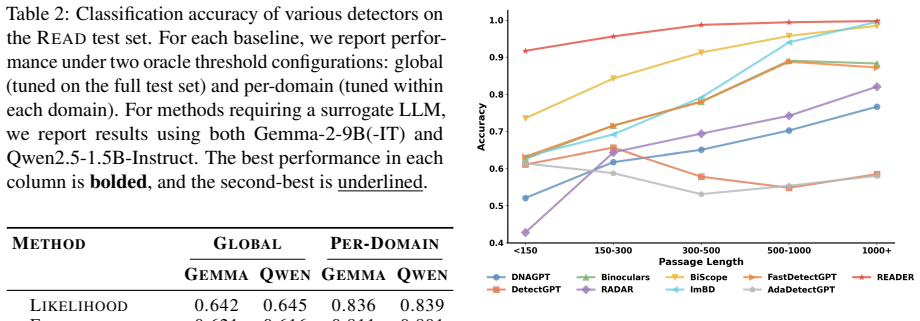
READER is obtained by fine-tuning a 1.5B parameter LLM on the READ supervision set of rationales paired with verdicts. At inference the model first generates a structured rationale describing the evidence and then outputs a human or AI label. The resulting detector outperforms both conventional AI-text detectors and prompted versions of much larger models such as GPT-5.2, Gemini-3-Pro, and DeepSeek-V3.2 across in-distribution and shifted test conditions.
What carries the argument
The READ curated supervision set of rationales and verdicts that trains the model to reason step-by-step before producing a verdict.
If this is right
- Reasoning before classification improves robustness when the source of generated text changes.
- A model two to three orders of magnitude smaller can exceed the detection accuracy of prompted larger models.
- Outputting an accompanying rationale makes the detector's decisions more inspectable.
Where Pith is reading between the lines
- The same rationale-supervision approach could be tested on other binary classification tasks that suffer from distribution shift.
- If the rationales capture transferable features of human versus machine writing, the method might reduce the need to retrain detectors from scratch for each new generator.
Load-bearing premise
The rationales and verdicts in the READ set are high-quality and representative enough that training on them produces a reasoning step that improves generalization under distribution shift.
What would settle it
If READER shows no accuracy gain over a standard fine-tuned 1.5B model without rationale supervision when tested on text from new generators absent from READ, the benefit of the reasoning component would be falsified.
Figures







read the original abstract
Recent advances in large language models (LLMs) have made it increasingly difficult to distinguish human-written text from AI-generated content. Many existing detectors train supervised neural classifiers that achieve strong in-distribution performance but are often opaque and can degrade substantially under distribution shift. We present READER, a reasoning-enhanced AI text detector that outputs both a human/AI label and a structured rationale describing the evidence for its decision. A key component of our approach is READ, a curated supervision set of rationales and verdicts. We fine-tune an LLM on READ to build READER, which reasons before detecting at inference time. Despite having only 1.5B parameters, READER consistently outperforms existing detectors as well as prompted, high-capacity LLM baselines (GPT-5.2, Gemini-3-Pro, and DeepSeek-V3.2), which are 100 to 1000 times larger in scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces READER, a 1.5B-parameter LLM fine-tuned on the READ supervision set of structured rationales and verdicts. At inference the model produces both a human/AI verdict and an accompanying rationale. The central empirical claim is that this reasoning-enhanced 1.5B model consistently outperforms existing supervised detectors as well as prompted frontier LLMs (GPT-5.2, Gemini-3-Pro, DeepSeek-V3.2) that are 100–1000× larger, while also generalizing better under distribution shift.
Significance. If the reported gains are reproducible and the contribution of the rationales is isolated, the result would indicate that curated reasoning supervision can produce compact, interpretable detectors that surpass scale-based prompting approaches, directly addressing opacity and brittleness under shift.
major comments (2)
- [Experiments section] Experiments section: the manuscript reports no ablation that compares the full READER (fine-tuned on rationales + verdicts) against an otherwise identical 1.5B model fine-tuned only on the verdicts from the same READ set. This control is required to attribute outperformance and improved OOD generalization to the reasoning step rather than to standard supervised fine-tuning on the verdict labels alone.
- [Abstract and §1] Abstract and §1: the claim of 'consistent outperformance' is stated without reference to any specific metrics, datasets, baselines, or statistical tests, preventing immediate evaluation of effect sizes or controls.
minor comments (2)
- [§3 (READ Dataset)] The description of how the READ rationales were curated, validated, and ensured to be representative could be expanded with concrete examples and inter-annotator statistics.
- [§4 (Model and Training)] Notation for the rationale format and the exact inference-time prompting template should be formalized (e.g., as a boxed equation or pseudocode) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We address each major point below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the manuscript reports no ablation that compares the full READER (fine-tuned on rationales + verdicts) against an otherwise identical 1.5B model fine-tuned only on the verdicts from the same READ set. This control is required to attribute outperformance and improved OOD generalization to the reasoning step rather than to standard supervised fine-tuning on the verdict labels alone.
Authors: We agree this ablation is necessary to isolate the contribution of the rationales. We will train an identical 1.5B model on the READ verdicts alone (without rationales) and report its in-distribution and OOD performance alongside READER in the revised Experiments section, including direct comparisons on the same metrics and datasets. revision: yes
-
Referee: [Abstract and §1] Abstract and §1: the claim of 'consistent outperformance' is stated without reference to any specific metrics, datasets, baselines, or statistical tests, preventing immediate evaluation of effect sizes or controls.
Authors: We acknowledge the abstract and introduction state the claim at a high level. In revision we will update both to explicitly name the primary metrics (accuracy, F1), the evaluation datasets, the three prompted baselines, and reference to statistical tests reported in the experiments. The detailed results remain in §4; the front matter will now point to them directly. revision: yes
Circularity Check
No circularity: purely empirical fine-tuning with no derivation chain
full rationale
The paper presents an empirical method: curate READ dataset of rationales+verdicts, fine-tune 1.5B LLM to produce READER that outputs label+rationale. Abstract and description contain no equations, no fitted parameters renamed as predictions, no self-citation load-bearing uniqueness theorems, and no ansatz smuggled via prior work. Performance claims rest on experimental comparisons, not on any reduction of outputs to inputs by construction. This matches the default expectation of no significant circularity for non-derivational empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scixgen: A scientific paper dataset for context- aware text generation.Preprint, arXiv:2110.10774. Jiaqi Chen, Xiaoye Zhu, Tianyang Liu, Ying Chen, Chen Xinhui, Yiwen Yuan, Chak Tou Leong, Zuchao Li, Long Tang, Lei Zhang, and 1 others. 2025a. Imi- tate before detect: Aligning machine stylistic prefer- ence for machine-revised text detection. InProceed- in...
-
[2]
InProceedings of the 41st International Conference on Machine Learning
Spotting LLMs with binoculars: zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning. Wei Hao, Ran Li, Weiliang Zhao, Junfeng Yang, and Chengzhi Mao. 2025. Learning to rewrite: General- ized LLM-generated text detection. InProceedings of the 63rd Annual Meeting of the Association for Computat...
2025
-
[3]
Daphne Ippolito, Daniel Duckworth, Chris Callison- Burch, and Douglas Eck
Token-specific watermarking with enhanced detectability and semantic coherence for large lan- guage models.arXiv preprint arXiv:2402.18059. Daphne Ippolito, Daniel Duckworth, Chris Callison- Burch, and Douglas Eck. 2020. Automatic detection of generated text is easiest when humans are fooled. InProceedings of the 58th Annual Meeting of the As- sociation f...
-
[4]
Maurice Jakesch, Jeffrey T Hancock, and Mor Naaman
Association for Computational Linguistics. Maurice Jakesch, Jeffrey T Hancock, and Mor Naaman
-
[5]
Human heuristics for ai-generated language are flawed.Proceedings of the National Academy of Sciences, 120(11):e2208839120. Jiazhou Ji, Ruizhe Li, Shujun Li, Jie Guo, Weidong Qiu, Zheng Huang, Chiyu Chen, Xiaoyu Jiang, and Xinru Lu. 2025a. Detecting machine-generated texts: Not just "ai vs humans" and explainability is complicated. Preprint, arXiv:2406.18...
-
[6]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense, 2023
Outfox: LLM-generated essay detection through in-context learning with adversarially gen- erated examples. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 38, pages 21258–21266. Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. 2023. Paraphras- ing evades detectors of ai-generated text, but re- triev...
-
[7]
ChatGPT or human? Detect and explain
ChatGPT or human? detect and explain. ex- plaining decisions of machine learning model for de- tecting short ChatGPT-generated text.arXiv preprint arXiv:2301.13852. Sandra Mitrovi´c, Davide Andreoletti, and Omran Ay- oub. 2023. Chatgpt or human? detect and explain. explaining decisions of machine learning model for detecting short chatgpt-generated text.P...
-
[8]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412
DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412. As- sociation for Computational Linguistics. Jingtao Sun and Zhanglong Lv. 2025. Zero-shot detec- tion of llm-generated text via text reorder.Neurocom- puting, 631:129829....
2023
-
[9]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Dire for diffusion-generated image detection. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 22445–22455. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint arXiv:2201.11903. Laura Weidinger...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Survey on ai-generated media detection: From non-mllm to mllm.Preprint, arXiv:2502.05240. 13 A Related Work AIGT detection aims to determine whether a pas- sage was authored by a human or an LLM. Recent surveys provide a broad view of this rapidly evolv- ing area (e.g., Ji et al., 2025b; Wu et al., 2025; Yang et al., 2024b; Zou et al., 2025). Their comple...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.