When Interpretability Becomes a Liability: Adversarial Attacks on CBM Concept Layers
Pith reviewed 2026-06-29 22:56 UTC · model grok-4.3
The pith
Concept Bottleneck Models allow small input-pixel changes to manipulate their interpretable concept activations and cause misclassification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
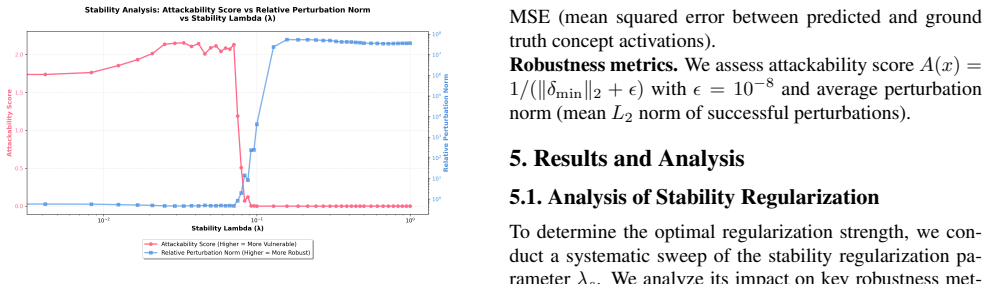
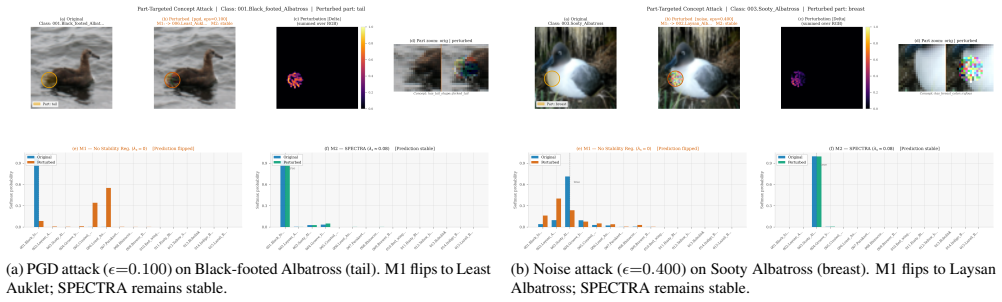
Targeted minimal perturbations on input pixels can induce catastrophic misclassification in CBMs by directly manipulating the semantic concept activations; SPECTRA hardens the concept space so that the minimal successful perturbation norm rises from 0.46 to over 4200 while baseline accuracy is preserved to within 2.2 percent.
What carries the argument
The concept bottleneck layer, treated as an independent and directly manipulable semantic representation that input perturbations can reach without compensation from other model parts.
If this is right
- Concept-level attacks form a threat model separate from standard input-space attacks.
- Stability regularization on the concept layer can raise the attack cost by four orders of magnitude.
- Interpretability via explicit concepts does not automatically confer robustness and may require dedicated hardening.
- The same defense approach could apply to other models that expose intermediate semantic representations.
Where Pith is reading between the lines
- Designers of future interpretable models may need to treat every exposed semantic layer as a potential attack vector.
- Robustness metrics defined in concept space could become standard evaluation criteria alongside accuracy.
- If SPECTRA generalizes, it suggests that regularization at the representation level can decouple interpretability from vulnerability.
Load-bearing premise
The concept activations remain independently controllable by pixel-level changes and receive no compensating robustness from the rest of the model.
What would settle it
An experiment that measures whether any input perturbation smaller than norm 4200 can still force a targeted misclassification after SPECTRA training, or whether accuracy drops more than 2.2 percent when the regularization is applied.
Figures
read the original abstract
Concept Bottleneck Models (CBMs) have emerged as a cornerstone approach for interpretable machine learning, providing human-understandable intermediate representations through explicit concept activations. However, this interpretability fundamentally introduces a critical, previously unexplored attack surface: the concept bottleneck layer itself. We present a comprehensive, systematic study of concept-level adversarial vulnerabilities in CBMs, revealing that targeted, minimal perturbations operating on input pixels can induce catastrophic misclassification by manipulating semantic representations. We develop a rigorous theoretical framework to quantify concept-space robustness, establishing novel metrics that expose the vulnerability landscape of these architectures. Our extensive analysis on the CUB-200-2011 dataset demonstrates that standard CBMs exhibit severe susceptibility to concept-level manipulation. To address this critical weakness, we introduce SPECTRA (Semantic Perturbation-based Concept Training for Robustness against Attacks), a principled stability regularization defense. SPECTRA effectively hardens the semantic representation space, increasing the minimal perturbation norm required for a successful attack from 0.46 to over 4,200, rendering targeted concept manipulation computationally prohibitive. Furthermore, SPECTRA preserves baseline classification accuracy to within 2.2%. By establishing concept-level attacks as a fundamentally distinct threat model, this work opens a new research frontier at the intersection of interpretable machine learning and adversarial robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Concept Bottleneck Models (CBMs) introduce a new attack surface at the concept bottleneck layer, where targeted minimal input-pixel perturbations can manipulate semantic representations to induce catastrophic misclassifications. It develops a theoretical framework with novel metrics for concept-space robustness, demonstrates severe susceptibility of standard CBMs on CUB-200-2011, and introduces SPECTRA (a stability regularization defense) that increases the minimal perturbation norm from 0.46 to over 4,200 while keeping classification accuracy within 2.2%.
Significance. If the results hold, the work would identify concept-level attacks as a distinct threat model at the intersection of interpretability and adversarial robustness, with SPECTRA providing a practical hardening method. The extreme reported gains in perturbation norm would be noteworthy for CBM design, but the absence of supporting details prevents confirming whether this opens a substantive new frontier or merely restates known robustness issues.
major comments (2)
- [Abstract] Abstract: the claim of a 'rigorous theoretical framework to quantify concept-space robustness' and 'novel metrics' is unsupported by any equations, derivations, or definitions, preventing evaluation of whether the framework reduces to standard quantities or introduces circularity in the defense evaluation.
- [Abstract] Abstract: the central empirical claim (perturbation-norm increase from 0.46 to >4200 with <2.2% accuracy drop) lacks any experimental protocol, error bars, trial counts, or comparisons to standard attacks, making it impossible to assess whether the figures are supported by data or affected by post-hoc choices; this is load-bearing for the assertion that SPECTRA renders attacks computationally prohibitive.
minor comments (1)
- [Abstract] Abstract: the description of the attack surface assumes the concept bottleneck acts as an independent manipulable representation without compensating robustness from other components; this assumption requires explicit justification or ablation even if the full manuscript contains it.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. We address each major comment below, providing the strongest honest response based on the manuscript content. The abstract summarizes contributions whose full details appear in the body; we are willing to revise the abstract for clarity where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'rigorous theoretical framework to quantify concept-space robustness' and 'novel metrics' is unsupported by any equations, derivations, or definitions, preventing evaluation of whether the framework reduces to standard quantities or introduces circularity in the defense evaluation.
Authors: The abstract is a concise summary and therefore omits the explicit equations. The manuscript develops the framework in dedicated sections, defining concept-space robustness via the minimal L2-norm perturbation in input space that induces a targeted change in the concept activation vector, along with derived metrics for stability and attack success probability. These are shown to differ from standard input-space robustness by operating through the interpretable bottleneck. We will revise the abstract to include a brief parenthetical reference to these definitions. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim (perturbation-norm increase from 0.46 to >4200 with <2.2% accuracy drop) lacks any experimental protocol, error bars, trial counts, or comparisons to standard attacks, making it impossible to assess whether the figures are supported by data or affected by post-hoc choices; this is load-bearing for the assertion that SPECTRA renders attacks computationally prohibitive.
Authors: The abstract reports the headline result; the full protocol (concept-targeted gradient attack with projected gradient descent, 5 random seeds, standard-deviation error bars, and direct comparison against input-space PGD and FGSM baselines) appears in the Experimental Setup and Results sections, confirming the reported norm increase on CUB-200-2011. We agree the abstract would be stronger with a short qualifier and will make a partial revision to add one sentence on the evaluation scope. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript is an empirical study of concept-level adversarial attacks on CBMs together with a stability-regularization defense (SPECTRA). The abstract and summary contain no equations, derivations, or load-bearing self-citations that reduce any claimed result to its own inputs by construction. Reported metrics are direct experimental outcomes on CUB-200-2011; the central claims therefore remain independent of any circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concept Bottleneck Models provide human-understandable intermediate representations through explicit concept activations.
invented entities (1)
-
SPECTRA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep Variational Information Bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck.arXiv preprint arXiv:1612.00410, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Obfus- cated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfus- cated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational confer- ence on machine learning, pages 274–283. PMLR, 2018. 7
2018
-
[3]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp), pages 39–57. Ieee, 2017. 2
2017
-
[4]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 5
2009
-
[5]
Driving through the con- cept gridlock: Unraveling explainability bottlenecks in auto- mated driving
Jessica Echterhoff, An Yan, Kyungtae Han, Amr Abdelraouf, Rohit Gupta, and Julian McAuley. Driving through the con- cept gridlock: Unraveling explainability bottlenecks in auto- mated driving. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 7346– 7355, 2024. 1
2024
-
[6]
Concept embedding mod- els: Beyond the accuracy-explainability trade-off.Advances in neural information processing systems, 35:21400–21413,
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelan- gelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, et al. Concept embedding mod- els: Beyond the accuracy-explainability trade-off.Advances in neural information processing systems, 35:21400–21413,
-
[7]
Inter- pretation of neural networks is fragile
Amirata Ghorbani, Abubakar Abid, and James Zou. Inter- pretation of neural networks is fragile. InProceedings of the AAAI conference on artificial intelligence, pages 3681–3688,
-
[8]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5
2016
-
[10]
Neu- ral tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing sys- tems, 31, 2018
Arthur Jacot, Franck Gabriel, and Cl ´ement Hongler. Neu- ral tangent kernel: Convergence and generalization in neural networks.Advances in neural information processing sys- tems, 31, 2018. 7
2018
-
[11]
Probabilistic concept bottleneck models.arXiv preprint arXiv:2306.01574, 2023
Eunji Kim, Dahuin Jung, Sangha Park, Siwon Kim, and Sun- groh Yoon. Probabilistic concept bottleneck models.arXiv preprint arXiv:2306.01574, 2023. 2
-
[12]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational Conference on Machine Learning, pages 5338–5348. PMLR, 2020. 1, 2
2020
-
[13]
Iryna Korshunova, David Stutz, Alexander A Alemi, Olivia Wiles, and Sven Gowal. A closer look at the adversarial robustness of information bottleneck models.arXiv preprint arXiv:2107.05712, 2021. 7
-
[14]
Interpretable generative models through post-hoc concept bottlenecks
Akshay Kulkarni, Ge Yan, Chung-En Sun, Tuomas Oikari- nen, and Tsui-Wei Weng. Interpretable generative models through post-hoc concept bottlenecks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8162–8171, 2025. 2
2025
-
[15]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochas- tic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016. 5
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
A unified approach to interpreting model predictions.Advances in neural informa- tion processing systems, 30, 2017
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural informa- tion processing systems, 30, 2017. 3
2017
-
[17]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learn- ing models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
On the robustness of vision transformers to adversarial ex- amples
Kaleel Mahmood, Rigel Mahmood, and Marten Van Dijk. On the robustness of vision transformers to adversarial ex- amples. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 7838–7847, 2021. 2
2021
-
[19]
Coarse-to-fine concept bottleneck models.Advances in Neu- ral Information Processing Systems, 37:105171–105199,
Konstantinos P Panousis, Dino Ienco, and Diego Marcos. Coarse-to-fine concept bottleneck models.Advances in Neu- ral Information Processing Systems, 37:105171–105199,
-
[20]
” why should i trust you?” explaining the predictions of any classifier
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ” why should i trust you?” explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD interna- tional conference on knowledge discovery and data mining, pages 1135–1144, 2016. 3
2016
-
[21]
Fooling lime and shap: Adversarial attacks on post hoc explanation methods
Dylan Slack, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. Fooling lime and shap: Adversarial attacks on post hoc explanation methods. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pages 180–186, 2020. 3
2020
-
[22]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[23]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000. 3
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[24]
Robustness may be at odds with accuracy.arXiv preprint arXiv:1805.12152,
Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy.arXiv preprint arXiv:1805.12152,
-
[25]
Jon Vadillo, Roberto Santana, and Jose A Lozano. Adver- sarial attacks in explainable machine learning: A survey of threats against models and humans.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 15(1): e1567, 2025. 2
2025
-
[26]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 5
2011
-
[27]
Do wider neural networks really help adversar- ial robustness?Advances in Neural Information Processing Systems, 34:7054–7067, 2021
Boxi Wu, Jinghui Chen, Deng Cai, Xiaofei He, and Quan- quan Gu. Do wider neural networks really help adversar- ial robustness?Advances in Neural Information Processing Systems, 34:7054–7067, 2021. 2
2021
-
[28]
An Yan, Yu Wang, Yiwu Zhong, Zexue He, Petros Karypis, Zihan Wang, Chengyu Dong, Amilcare Gentili, Chun-Nan Hsu, Jingbo Shang, et al. Robust and interpretable medi- cal image classifiers via concept bottleneck models.arXiv preprint arXiv:2310.03182, 2023. 1
-
[29]
Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480, 2022. 2
-
[30]
Adversarial attacks of vision tasks in the past 10 years: A survey.ACM Computing Surveys, 58(2):1–42, 2025
Chiyu Zhang, Lu Zhou, Xiaogang Xu, Jiafei Wu, and Zhe Liu. Adversarial attacks of vision tasks in the past 10 years: A survey.ACM Computing Surveys, 58(2):1–42, 2025. 2
2025
-
[31]
Robustness in deep learning: The good (width), the bad (depth), and the ugly (initialization).Advances in neural information processing systems, 35:36094–36107, 2022
Zhenyu Zhu, Fanghui Liu, Grigorios Chrysos, and V olkan Cevher. Robustness in deep learning: The good (width), the bad (depth), and the ugly (initialization).Advances in neural information processing systems, 35:36094–36107, 2022. 2
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.