Prior Policy Guided Dual-Agent Coordinated Manipulation Planning of Spacecraft-Manipulator System
Pith reviewed 2026-06-29 22:05 UTC · model grok-4.3
The pith
Dual-agent reinforcement learning coordinates high-precision manipulator positioning with spacecraft attitude stabilization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
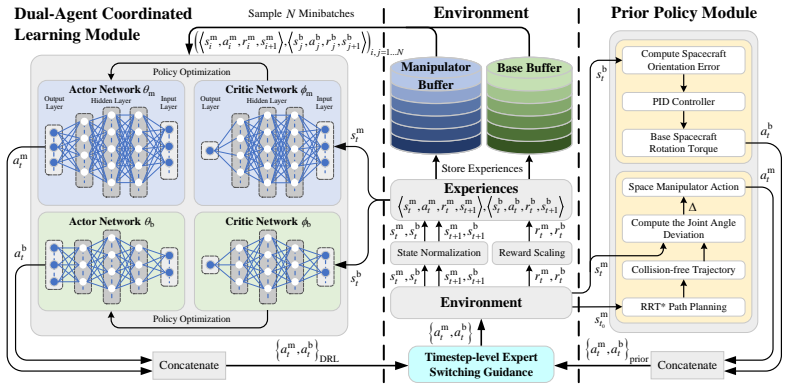
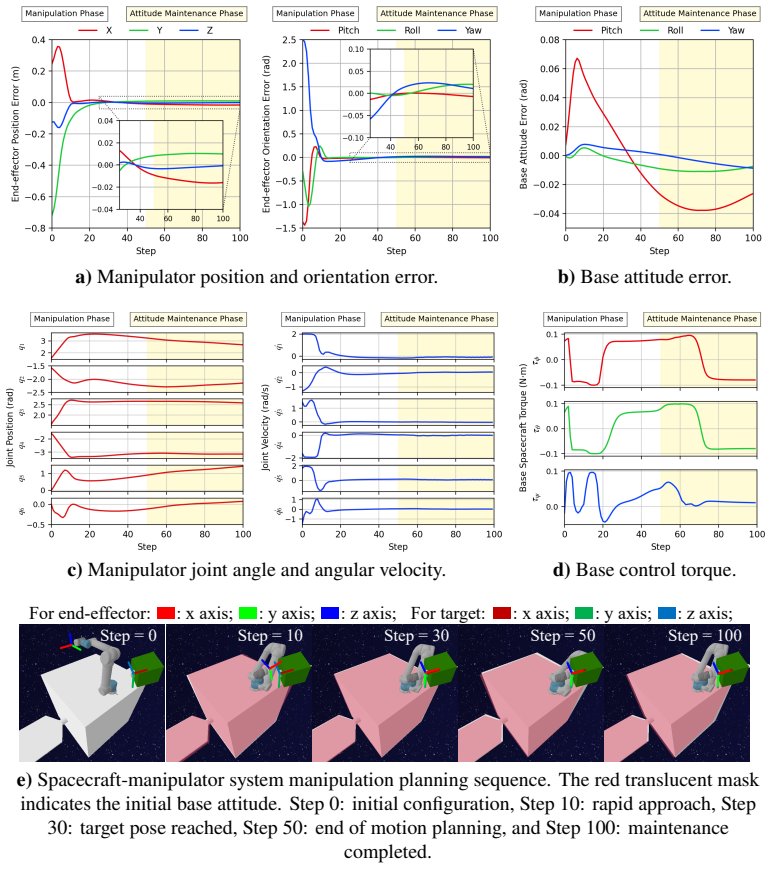
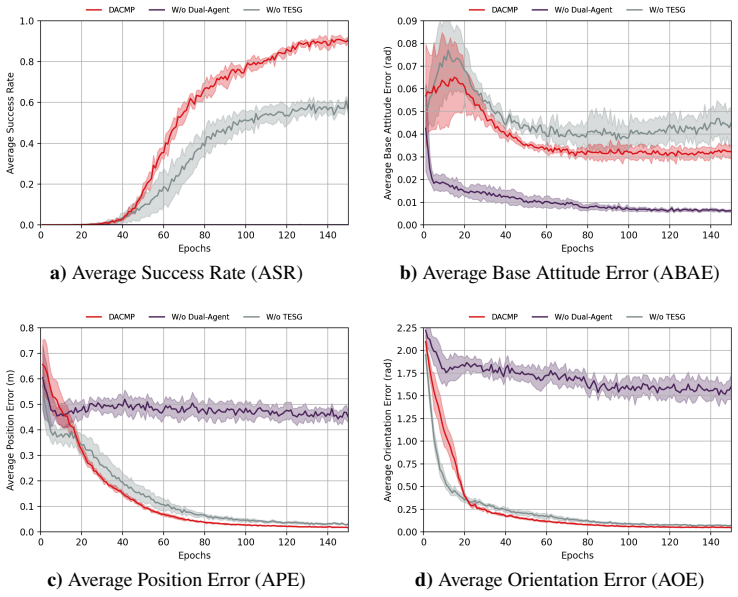
The DACMP framework simultaneously achieves high-precision end-effector pose reaching for a 6-DoF space manipulator and attitude stabilization of the base spacecraft by employing a prior policy-guided Deep Reinforcement Learning algorithm that incorporates the Timestep-level Expert Switching Guidance mechanism.
What carries the argument
Dual-Agent Coordinated Manipulation Planning (DACMP) framework that assigns one agent to end-effector control and another to base attitude control, trained with prior-policy guidance and Timestep-level Expert Switching Guidance.
Load-bearing premise
The simulation environments used for training and testing accurately represent the real-world dynamics, constraints, disturbances, and perception uncertainties of a physical 6-DoF spacecraft-manipulator system.
What would settle it
Running the learned policy on physical hardware of a 6-DoF spacecraft-manipulator system and comparing measured end-effector error and attitude deviation against the simulation results under identical target poses and disturbances.
Figures






read the original abstract
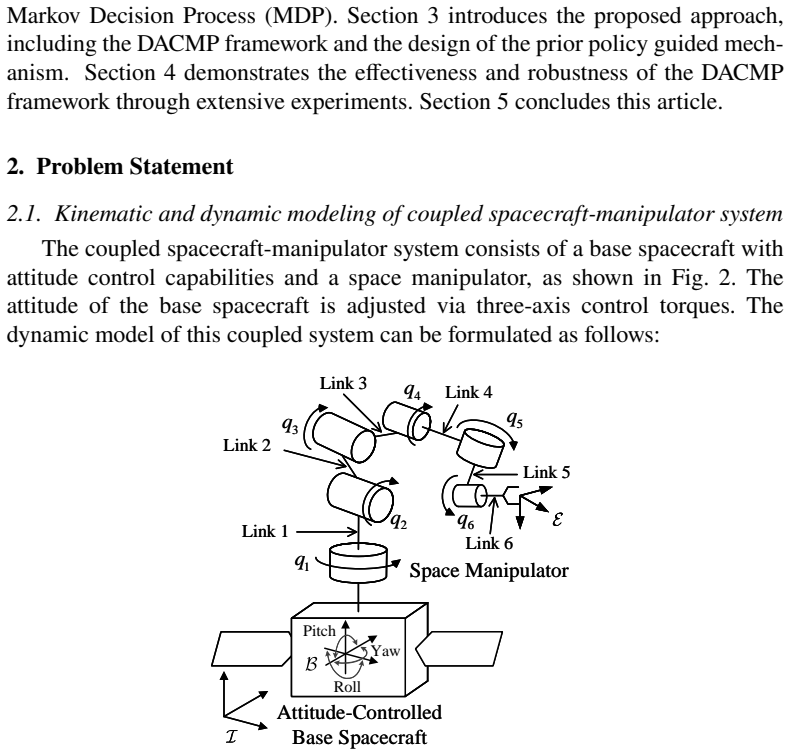
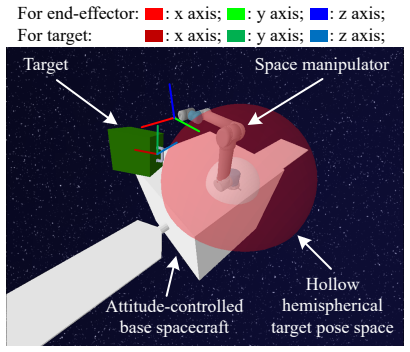
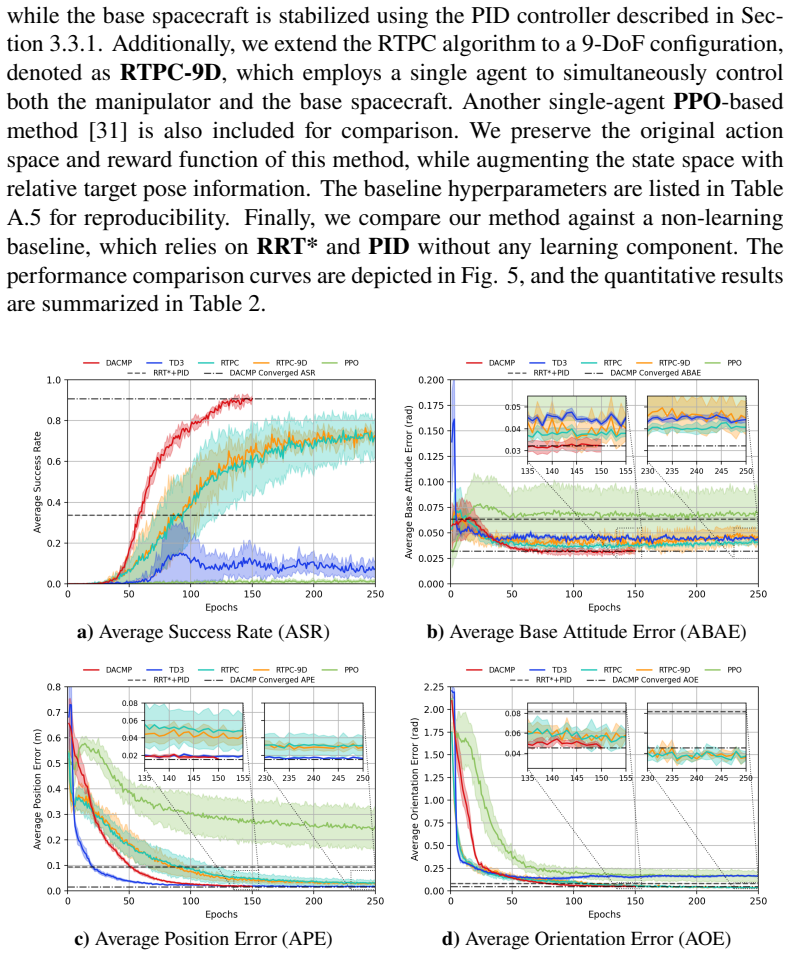
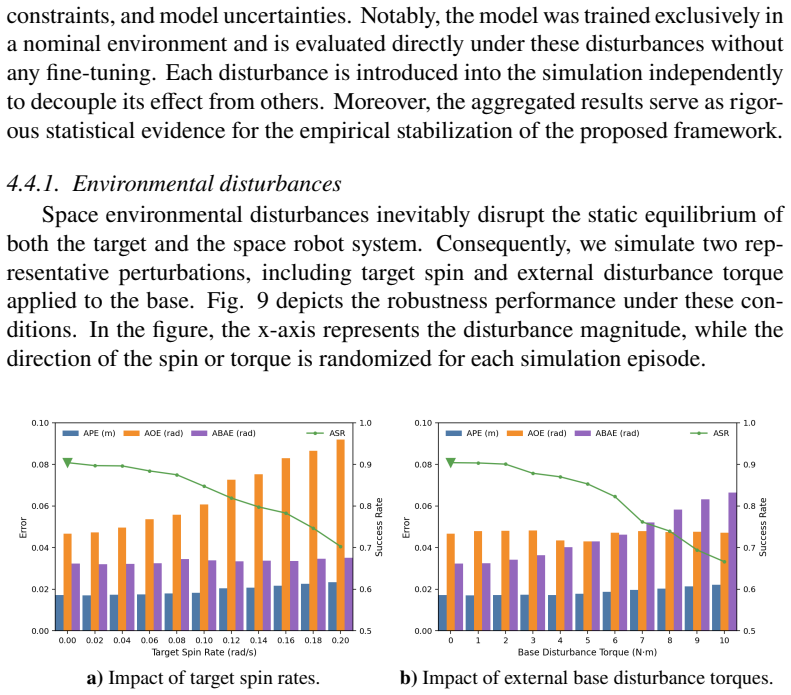
The strong dynamic coupling between the manipulator and the base poses a significant challenge to maintaining spacecraft attitude stability, potentially compromising mission safety. In this paper, we propose a Dual-Agent Coordinated Manipulation Planning (DACMP) framework that simultaneously achieves high-precision end-effector pose reaching for a 6-DoF space manipulator and attitude stabilization of the base spacecraft. To enhance learning efficiency, we present a prior policy-guided Deep Reinforcement Learning algorithm incorporating the Timestep-level Expert Switching Guidance (TESG) mechanism, thereby promoting global convergence and improving task success rates. Extensive experiments demonstrate that DACMP significantly outperforms baseline DRL algorithms in terms of task success rate and control precision. Furthermore, the robustness of DACMP is validated under various challenging scenarios, including system constraints, environmental disturbances, and perception uncertainties. The code and simulation configurations are available on GitHub: https://github.com/HIT-YuhuiHu/DACMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Dual-Agent Coordinated Manipulation Planning (DACMP) framework for a 6-DoF spacecraft-manipulator system. It introduces a prior policy-guided Deep Reinforcement Learning algorithm with a Timestep-level Expert Switching Guidance (TESG) mechanism to simultaneously achieve high-precision end-effector pose reaching and base attitude stabilization. The paper claims that DACMP significantly outperforms baseline DRL algorithms in task success rate and control precision, and validates robustness in simulation under system constraints, environmental disturbances, and perception uncertainties. Code and simulation configurations are released on GitHub.
Significance. If the reported simulation results hold, the work addresses a practically relevant challenge in space robotics by coordinating manipulator and base dynamics via a dual-agent DRL approach. The public availability of code and simulation configurations is a clear strength that supports reproducibility.
major comments (1)
- [Abstract and experimental results section] Abstract and experimental results section: all quantitative claims (success rate, control precision, robustness to disturbances and perception uncertainty) are obtained exclusively inside the training simulator. No hardware experiments, domain-randomization ablations, or quantitative sim-to-real metrics are reported. This is load-bearing for the central robustness claim because unmodeled effects (joint stiction, propellant slosh, actuator delays, realistic sensor noise) can alter both the learned policy and the closed-loop margins that TESG is asserted to improve.
minor comments (1)
- [Method and Experiments] The description of the baseline DRL algorithms and the precise definition of the performance metrics (e.g., success-rate threshold, precision tolerance) should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the scope of our evaluations. We address the concern regarding simulation-only results below and will make targeted revisions to clarify the claims.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: all quantitative claims (success rate, control precision, robustness to disturbances and perception uncertainty) are obtained exclusively inside the training simulator. No hardware experiments, domain-randomization ablations, or quantitative sim-to-real metrics are reported. This is load-bearing for the central robustness claim because unmodeled effects (joint stiction, propellant slosh, actuator delays, realistic sensor noise) can alter both the learned policy and the closed-loop margins that TESG is asserted to improve.
Authors: We agree that all quantitative results, including success rates, control precision, and robustness under constraints, disturbances, and perception uncertainties, are obtained exclusively within the training simulator as described in Section V. The manuscript does not report hardware experiments, domain-randomization ablations, or quantitative sim-to-real metrics. This is a factual limitation of the current work. The robustness claims in the abstract and experiments are scoped to the simulated environments, which incorporate modeled dynamics, disturbances, and uncertainties. We will revise the abstract to explicitly qualify results as 'in simulation' and add a limitations paragraph in the discussion section acknowledging unmodeled real-world effects (such as joint stiction, propellant slosh, actuator delays, and realistic sensor noise) and the absence of sim-to-real validation. The open-source release of code and simulation configurations supports community efforts toward further validation. We do not claim hardware validation or sim-to-real transfer. revision: yes
- Providing hardware experiments or quantitative sim-to-real metrics, as these require access to physical spacecraft-manipulator hardware which is not available for this study.
Circularity Check
No circularity: empirical RL framework evaluated against external baselines
full rationale
The paper introduces an algorithmic Dual-Agent Coordinated Manipulation Planning (DACMP) method using prior-policy-guided DRL with TESG, then reports simulation-based performance metrics (success rate, precision) against baseline DRL algorithms under varied conditions. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains appear in the provided text. All claims rest on external empirical comparisons within the simulator rather than any reduction of results to the method's own inputs by construction. The work is therefore self-contained as a standard empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- DRL hyperparameters including learning rates and network sizes
axioms (1)
- domain assumption The spacecraft-manipulator dynamics can be faithfully reproduced in simulation for the purpose of training and evaluating control policies.
Reference graph
Works this paper leans on
-
[1]
Jahanshahi, Z
H. Jahanshahi, Z. H. Zhu, Review of machine learning in robotic grasping control in space application, Acta Astronautica 220 (2024) 37–61
2024
-
[2]
W. Lei, T. Zhao, G. Sun, Image based target capture of free floating space manipulatorunderunknowndynamics, AdvancesinSpaceResearch72(11) (2023) 4923–4933
2023
-
[3]
A. A. Ali, B. Beigomi, Z. H. Zhu, Development of 6dof hardware-in-the- loopgroundtestbedforautonomousroboticspacedebrisremoval,Aerospace 11 (11) (2024) 877
2024
-
[4]
M. Li, Y. Liu, W. Feng, B. Cao, Z. Xie, Y. Xie, C. Li, C. Guo, Optimization methodforoperationconfigurationofspacemanipulatorforon-orbitassem- bly,in: Proceedingsofthe20244thInternationalConferenceonControland Intelligent Robotics, 2024, pp. 14–20
2024
-
[5]
R. R. Santos, D. A. Rade, I. M. da Fonseca, A machine learning strategy foroptimalpathplanningofspaceroboticmanipulatorinon-orbitservicing, Acta Astronautica 191 (2022) 41–54
2022
-
[6]
N.Fallahiarezoodar,Z.H.Zhu,Reviewofautonomousspaceroboticmanip- ulators for on-orbit servicing and active debris removal, Space: Science & Technology 5 (2025) 0291
2025
-
[7]
thesis, Tohoku University (1989)
Y.Umetani,K.Yoshida,Resolvedmotionratecontrolofspacemanipulators with generalized jacobian matrix, Ph.D. thesis, Tohoku University (1989)
1989
-
[8]
H. Zhou, H. Zhuang, Q. Shen, V. Y. Razoumny, Y. N. Razoumny, S. Wu, Saturated output feedback control of free-floating space manipulator with fragility-avoidance prescribed performance, Acta Astronautica 228 (2025) 972–984. 32
2025
-
[9]
M. Wang, J. Luo, J. Fang, J. Yuan, Optimal trajectory planning of free- floating space manipulator using differential evolution algorithm, Advances in Space Research 61 (6) (2018) 1525–1536
2018
-
[10]
M. Wang, J. Luo, J. Yuan, U. Walter, Coordinated trajectory planning of dual-arm space robot using constrained particle swarm optimization, Acta Astronautica 146 (2018) 259–272
2018
-
[11]
R.Liu,J.Guo,E.Gill,Motionplanningoffree-floatingspacerobotsthrough multi-layer optimization using the rrt* algorithm, Acta Astronautica 228 (2025) 940–956
2025
-
[12]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D. Wierstra, Continuous control with deep reinforcement learning, arXiv preprint arXiv:1509.02971 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
1079–1082
X.Hu,X.Huang,T.Hu,Z.Shi,J.Hui,Mrddpgalgorithmsforpathplanning of free-floating space robot, in: 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), IEEE, 2018, pp. 1079–1082
2018
-
[14]
D. Du, Q. Zhou, N. Qi, X. Wang, Y. Liu, Learning to control a free-floating space robot using deep reinforcement learning, in: 2019 IEEE International Conference on Unmanned Systems (ICUS), IEEE, 2019, pp. 519–523
2019
-
[15]
Y. Li, D. Li, W. Zhu, J. Sun, X. Zhang, S. Li, Constrained motion planning of 7-dof space manipulator via deep reinforcement learning combined with artificial potential field, Aerospace 9 (3) (2022) 163
2022
-
[16]
J.Zhang,C.Bai,C.P.Yue,J.Guo,Deepmarl-basedresilientmotionplanning fordecentralizedspacemanipulator,Space: Science&Technology4(2024) 0145
2024
-
[17]
S.Wang,Y.Cao,X.Zheng,T.Zhang,Alearningsystemformotionplanning of free-float dual-arm space manipulator towards non-cooperative object, Aerospace Science and Technology 131 (2022) 107980
2022
- [18]
-
[19]
Blaise, M
J. Blaise, M. C. Bazzocchi, Space manipulator collision avoidance using a deep reinforcement learning control, Aerospace 10 (9) (2023) 778
2023
-
[20]
Y. Wei, X. Bai, H. Lu, Trajectory planning of free-floating space robot for non-cooperative tumbling target capture based on deep reinforcement learning, Robotica 43 (7) (2025) 2674–2692
2025
-
[21]
Zhuang, H
H. Zhuang, H. Zhou, Q. Shen, S. Wu, V. Y. Razoumny, Y. N. Razoumny, Optimal robust online tracking control for space manipulator in task space using off-policy reinforcement learning, Aerospace Science and Technology 153 (2024) 109446
2024
-
[22]
Zhuang, W
H. Zhuang, W. Lu, Q. Shen, S. Wu, V. Y. Razoumny, Y. N. Razoumny, Off-policy reinforcement learning control for space manipulators based on object detection via convolutional neural networks, Aerospace Science and Technology (2025) 110914
2025
-
[23]
H.Zhuang,J.Hou,Q.Shen,S.Wu,V.Y.Razoumny,Y.N.Razoumny,Event- triggeredimage-spacetrackingcontrolofspacemanipulatorsusingoff-policy reinforcement learning with disturbance observers, IEEE Transactions on Aerospace and Electronic Systems (2025)
2025
-
[24]
D’Ambrosio, L
M. D’Ambrosio, L. Capra, A. Brandonisio, S. Silvestrini, M. Lavagna, Re- dundant space manipulator autonomous guidance for in-orbit servicing via deep reinforcement learning, Aerospace 11 (5) (2024) 341
2024
-
[25]
J. Liu, B. Xu, C. Li, M. Li, Lifetime extension of ultra low-altitude lunar spacecraft with low-thrust propulsion system, Aerospace 9 (6) (2022) 305
2022
-
[26]
Al Ali, J.-F
A. Al Ali, J.-F. Shi, Z. H. Zhu, Path planning of 6-dof free-floating space robotic manipulators using reinforcement learning, Acta Astronautica 224 (2024) 367–378
2024
-
[27]
Ponche, A
A. Ponche, A. Marcos, T. Ott, R. Geshnizjani, J. Loehr, Guidance for au- tonomous spacecraft repointing under attitude constraints and actuator limi- tations, Acta Astronautica 207 (2023) 340–352
2023
-
[28]
X. Shao, Q. Hu, Z. H. Zhu, Y. Zhang, Fault-tolerant reduced-attitude con- trol for spacecraft constrained boresight reorientation, Journal of Guidance, Control, and Dynamics 45 (8) (2022) 1481–1495. 34
2022
-
[29]
D. N. Nenchev, K. Yoshida, P. Vichitkulsawat, M. Uchiyama, Reaction null- spacecontrolofflexiblestructuremountedmanipulatorsystems,IEEETrans- actions on Robotics and Automation 15 (6) (2002) 1011–1023
2002
-
[30]
X.Shao,W.Yao,X.Li,G.Sun,L.Wu,Directtrajectoryoptimizationoffree- floating space manipulator for reducing spacecraft variation, IEEE Robotics and Automation Letters 7 (2) (2022) 2795–2802
2022
-
[31]
Srivastava, R
R. Srivastava, R. Lima, R. Sah, K. Das, Deep reinforcement learning based controlofrotationfloatingspacerobotsforproximityoperationsinpybullet, in: 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, 2023, pp. 1224–1229
2023
-
[32]
Y. Cao, S. Wang, X. Zheng, W. Ma, X. Xie, L. Liu, Reinforcement learning with prior policy guidance for motion planning of dual-arm free-floating space robot, Aerospace Science and Technology 136 (2023) 108098
2023
-
[33]
Y. Hu, D. Zhou, W. Yao, X. Shao, G. Sun, Deep reinforcement learning- basedtrajectoryplanningwithcontinuousposerepresentationfor6-doffree- floating space robot, Aerospace Science and Technology (2025) 110540
2025
-
[34]
De Munter, High-precision pointing performance of small spacecraft: Dual-stage control approaches for optical instruments, Phd dissertation, KU Leuven, Leuven, Belgium (2024)
W. De Munter, High-precision pointing performance of small spacecraft: Dual-stage control approaches for optical instruments, Phd dissertation, KU Leuven, Leuven, Belgium (2024)
2024
-
[35]
E. Qi, T. Zhang, L. Zhao, F. Han, J. Ge, Y. Qi, Y. Qi, Research on robotic arm path planning method based on two-stage rrt* optimization algorithm, Engineering Research Express 7 (3) (2025) 035416
2025
-
[36]
Nakhaei, A
M. Nakhaei, A. Scannell, J. Pajarinen, Residual learning and context en- coding for adaptive offline-to-online reinforcement learning, in: 6th Annual LearningforDynamics&ControlConference,PMLR,2024,pp.1107–1121
2024
-
[37]
B.Y.Song,J.Q.Li,X.Y.Liu,G.L.Wang,Atrajectoryplanningmethodfor captureoperationofspaceroboticarmbasedondeepreinforcementlearning, JournalofComputingandInformationScienceinEngineering24(9)(2024) 091003
2024
-
[38]
J. Wang, Z. Yu, D. Zhou, J. Shi, R. Deng, Vision-based deep reinforcement learningofunmannedaerialvehicle(uav)autonomousnavigationusingpriv- ileged information, Drones 8 (12) (2024) 782. 35
2024
-
[39]
Sampath, J
S. Sampath, J. Feng, Intelligent and robust control of space manipulator for sustainable removal of space debris, Acta astronautica 220 (2024) 108–117. 36
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.