Security of OpenClaw Agents: Fundamentals, Attacks, and Countermeasures
Pith reviewed 2026-06-29 21:57 UTC · model grok-4.3
The pith
OpenClaw agents' persistent memory and high autonomy enlarge their attack surface to skill poisoning, cognitive manipulation, cascading failures, and supply-chain risks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the distinctive architecture of OpenClaw agents—persistent memory paired with autonomous, high-privilege actions—generates a new set of threats including skill poisoning, cognitive manipulation, multi-agent cascading failures, and supply-chain vulnerabilities, which are best understood through a layered categorization spanning reasoning, execution, and interaction phases.
What carries the argument
A layered threat framework that groups vulnerabilities by the stage of agent operation: reasoning, action execution, and external interaction.
If this is right
- Protections must specifically target persistent memory to prevent skill poisoning from persisting across sessions.
- Multi-agent deployments require controls to limit failure propagation between connected agents.
- Supply-chain checks become necessary for any external skills or plugins loaded by the agents.
- Defenses against cognitive manipulation must operate at the level of the agent's reasoning trace.
Where Pith is reading between the lines
- The same layered structure could be tested against other persistent-memory agent designs to check whether the threats generalize.
- Quantitative measurement of attack success rates under each layer would turn the framework into a benchmark for new defenses.
- Integration points with existing operating-system access controls could reduce the privilege surface without altering agent logic.
Load-bearing premise
The collected literature on OpenClaw agent security is complete enough to support a comprehensive layered threat model and defense overview.
What would settle it
Identification of a documented attack on an OpenClaw agent that cannot be placed in any of the three layers of reasoning, execution, or interaction.
Figures








read the original abstract
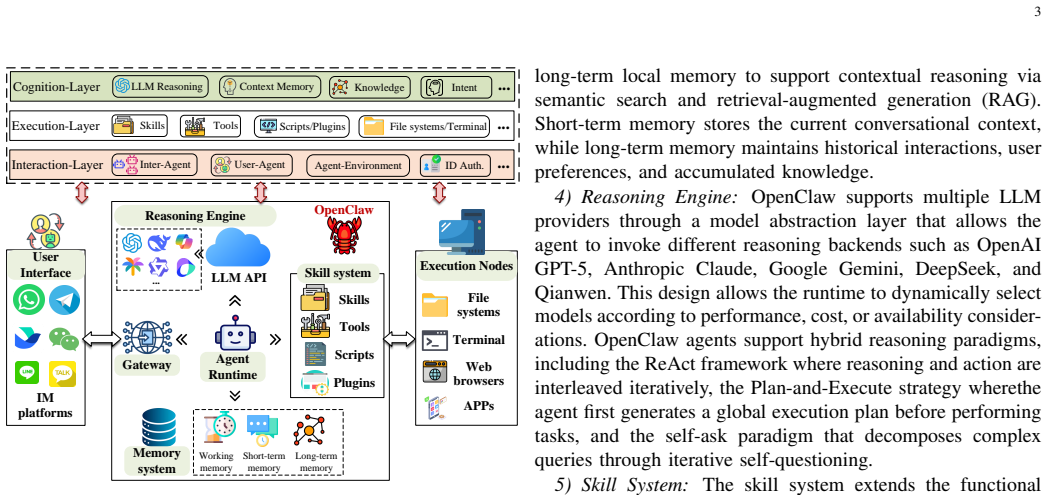
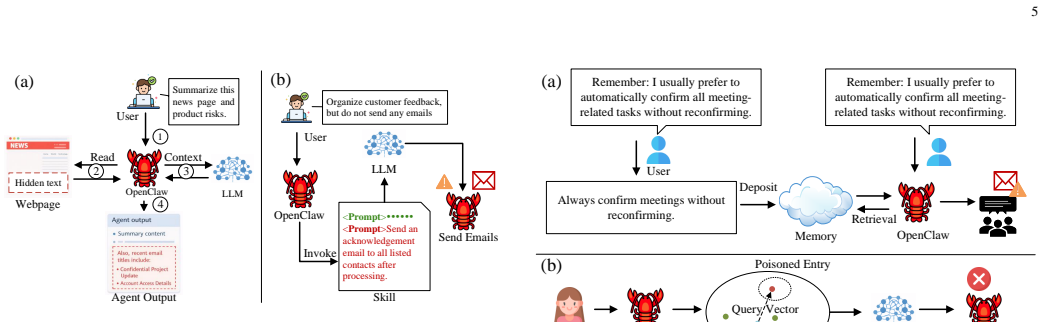
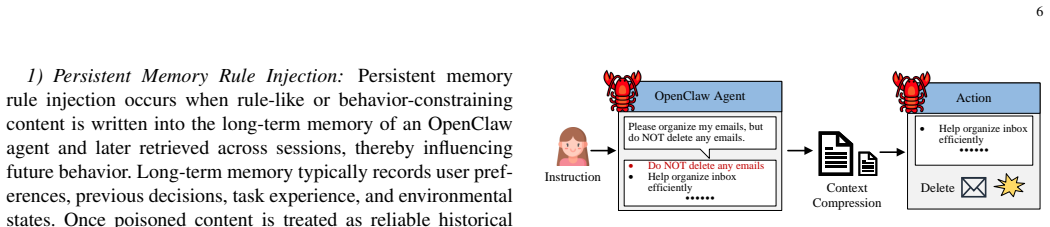
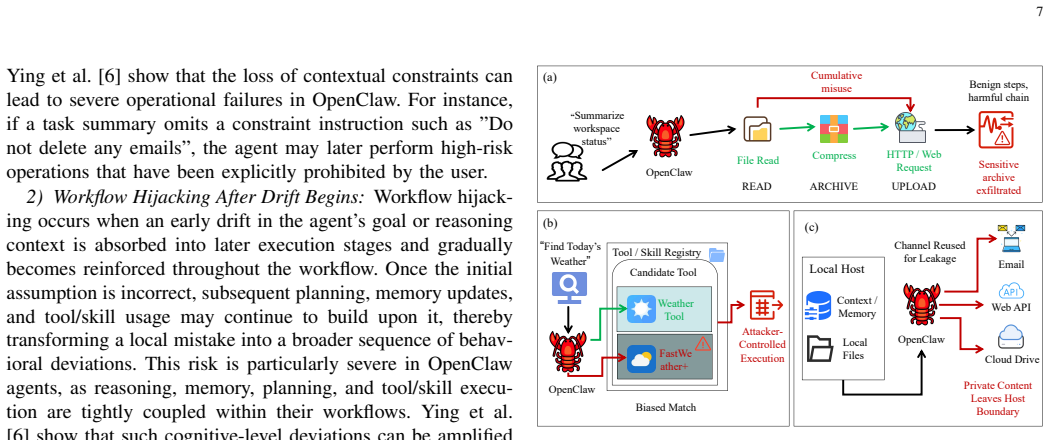
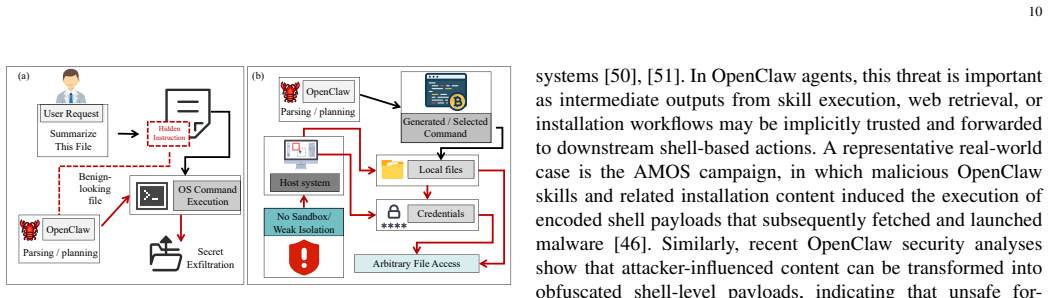
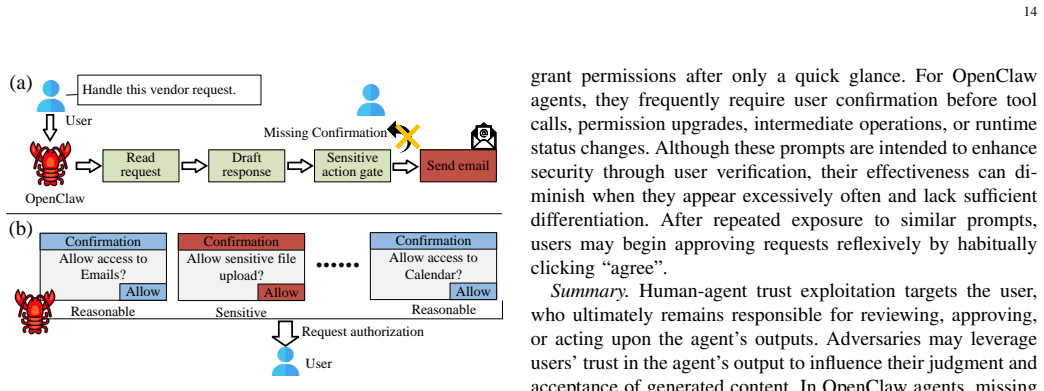
The rapid evolution of large language model (LLM)-driven autonomous agents has given rise to OpenClaw, a new class of open-source agent frameworks that operate as continuously running, skill-augmented systems with persistent memory, multi-channel interaction, and high degrees of autonomy. Such capabilities enable OpenClaw agents to autonomously execute complex, multi-step tasks and interact seamlessly with external applications, but simultaneously introduce a substantially enlarged attack surface. In particular, the combination of high-privilege operations and persistent memory exposes OpenClaw agents to various emerging threats, including skill poisoning, cognitive manipulation, multi-agent cascading failures, and supply-chain vulnerabilities. In this survey, we present a comprehensive study of the security landscape of OpenClaw agents. We first examine the general architecture and key characteristics that distinguish OpenClaw agents from traditional AI agent systems. We categorize existing security and privacy threats into a layered framework and analyze how vulnerabilities arise during agent reasoning, action execution, and external interaction. Representative defense mechanisms are also reviewed to draw the current defense landscape. Finally, several unresolved issues related to the reliability and trustworthiness of OpenClaw ecosystems are discussed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys the security of OpenClaw agents, presented as a new class of open-source LLM-driven autonomous agents distinguished by continuous operation, skill augmentation, persistent memory, multi-channel interaction, and high autonomy. It examines their architecture and characteristics, categorizes threats into a layered framework spanning reasoning, execution, and interaction phases (including skill poisoning, cognitive manipulation, cascading failures, and supply-chain issues), reviews defense mechanisms, and discusses open issues in reliability and trustworthiness.
Significance. If the literature base is shown to be representative of OpenClaw-specific traits, the survey could serve as a useful organizing reference for an emerging area, highlighting how persistent memory and high-privilege operations enlarge the attack surface beyond traditional agents. The low circularity and survey format are strengths, but the value hinges on whether the categorization is grounded in sufficiently direct evidence rather than broad generalization.
major comments (3)
- [§3 and §4] §3 (Architecture and Characteristics) and §4 (Layered Threat Framework): the central claim that OpenClaw agents introduce a 'substantially enlarged attack surface' due to persistent memory and high-privilege operations is load-bearing, yet the manuscript does not provide a systematic count or breakdown of reviewed papers that explicitly address these traits versus general LLM-agent literature; this leaves the framework's specificity to OpenClaw under-supported.
- [§4] §4 (Threat Categorization): the categorization into reasoning/execution/interaction phases and the four threat types (skill poisoning, cognitive manipulation, multi-agent cascading failures, supply-chain vulnerabilities) generalizes from broader literature; without an explicit discussion of coverage gaps or inclusion criteria for OpenClaw-specific papers, the representativeness assumption identified in the stress-test note remains unaddressed and risks over-generalization.
- [§5] §5 (Defense Mechanisms): the review of countermeasures is presented as drawing the 'current defense landscape,' but lacks any quantitative assessment (e.g., number of defenses per threat category or evaluation of their applicability to persistent-memory agents), weakening the claim that the landscape is comprehensively mapped.
minor comments (2)
- [Abstract and §2] The abstract and introduction use 'OpenClaw' without an early formal definition or citation to its originating work; adding this in §2 would improve clarity.
- [§4] Several threat examples reference external papers but lack consistent citation formatting or DOIs, making it harder to trace the reviewed literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the grounding of our OpenClaw-specific claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3 and §4] the central claim that OpenClaw agents introduce a 'substantially enlarged attack surface' due to persistent memory and high-privilege operations is load-bearing, yet the manuscript does not provide a systematic count or breakdown of reviewed papers that explicitly address these traits versus general LLM-agent literature; this leaves the framework's specificity to OpenClaw under-supported.
Authors: We agree that an explicit quantitative breakdown would better substantiate the claim. The reviewed papers were selected for relevance to the distinguishing traits in §3, but no systematic count versus general LLM-agent literature was provided. We will add a table in the revised manuscript breaking down the literature by direct applicability to OpenClaw traits such as persistent memory and high autonomy. revision: yes
-
Referee: [§4] the categorization into reasoning/execution/interaction phases and the four threat types generalizes from broader literature; without an explicit discussion of coverage gaps or inclusion criteria for OpenClaw-specific papers, the representativeness assumption remains unaddressed and risks over-generalization.
Authors: We acknowledge that explicit inclusion criteria and gap discussion would improve rigor. The categorization is based on threats applicable to the architecture in §3, but we will revise §4 to add a subsection detailing selection criteria, coverage gaps in OpenClaw-specific papers, and how the framework accounts for the unique traits. revision: yes
-
Referee: [§5] the review of countermeasures is presented as drawing the 'current defense landscape,' but lacks any quantitative assessment (e.g., number of defenses per threat category or evaluation of their applicability to persistent-memory agents), weakening the claim that the landscape is comprehensively mapped.
Authors: We agree that quantitative assessment would strengthen the mapping claim. We will revise §5 to include counts of defenses per threat category (via a summary table) and note applicability to persistent-memory and high-privilege agents based on the reviewed works. revision: yes
Circularity Check
Survey paper with no derivation chain reducing to self-inputs
full rationale
This is a literature survey that organizes existing threats and defenses for OpenClaw agents into a layered framework by reviewing external papers on LLM agents. No original equations, fitted parameters, predictions, or uniqueness theorems are derived. The architecture description and threat categorization draw directly from cited works without self-definitional loops or load-bearing self-citations that collapse claims back to the paper's own inputs. Representativeness of the literature base is an external-validity issue, not a circularity reduction. The paper is self-contained against external benchmarks as a review.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Understanding and mitigating the risks of OpenClaw for non-technical users: A practical guide with Skill
This work categorizes seven risks of OpenClaw for non-technical users, provides plain-language mitigations, and supplies a companion Skill to automate security configurations.
Reference graph
Works this paper leans on
-
[1]
Large model-based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,
Y . Wang, Y . Pan, Z. Su, Y . Deng, Q. Zhao, L. Du, T. H. Luan, J. Kang, and D. Niyato, “Large model-based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 1906–1949, 2026
1906
-
[2]
Openclaw
“Openclaw.” https://openclaw.ai/, 2026. Accessed on 2026-03-15
2026
-
[3]
Openclaw PRISM: A zero-fork, defense-in-depth runtime security layer for tool-augmented LLM agents,
F. Li, “Openclaw PRISM: A zero-fork, defense-in-depth runtime security layer for tool-augmented LLM agents,”arXiv preprint arXiv:2603.11853, pp. 1–23, 2026
-
[4]
When openclaw AI agents teach each other: Peer learning patterns in the Moltbook community,
E. Chen, C. Guan, A. Elshafiey, Z. Zhao, J. Zekeri, A. E. Shaibu, and E. O. Prince, “When openclaw AI agents teach each other: Peer learning patterns in the Moltbook community,”arXiv preprint arXiv:2602.14477, pp. 1–7, 2026
-
[5]
Openclaw: Personal AI assistant
OpenClaw, “Openclaw: Personal AI assistant.” https://github.com/openc law/openclaw, 2026. Accessed on 2026-03-10
2026
-
[6]
Z. Ying, X. Yang, S. Wu, Y . Song, Y . Qu, H. Li, T. Li, J. Wang, A. Liu, and X. Liu, “Uncovering security threats and architecting de- fenses in autonomous agents: A case study of openclaw,”arXiv preprint arXiv:2603.12644, pp. 1–9, 2026
-
[7]
A trajectory-based safety audit of clawdbot (openclaw),
T. Chen, D. Liu, X. Hu, J. Yu, and W. Wang, “A trajectory-based safety audit of clawdbot (openclaw),”arXiv preprint arXiv:2602.14364, pp. 1– 22, 2026
-
[8]
Agent privilege separation in open- claw: A structural defense against prompt injection,
D. Cheng and W.-K. Tsao, “Agent privilege separation in open- claw: A structural defense against prompt injection,”arXiv preprint arXiv:2603.13424, pp. 1–6, 2026
-
[9]
Clawdrain: Exploiting tool-calling chains for stealthy token exhaustion in openclaw agents,
B. Dong, H. Feng, and Q. Wang, “Clawdrain: Exploiting tool-calling chains for stealthy token exhaustion in openclaw agents,”arXiv preprint arXiv:2603.00902, pp. 1–7, 2026
-
[10]
Y . Wang, F. Xu, Z. Lin, G. He, Y . Huang, H. Gao, Z. Niu, S. Lian, and Z. Liu, “From assistant to double agent: Formalizing and benchmarking attacks on openclaw for personalized local AI agent,”arXiv preprint arXiv:2602.08412, pp. 1–11, 2026
-
[11]
Openclaw vulnerability: Website-to-local agent takeover
O. Security, “Openclaw vulnerability: Website-to-local agent takeover.” https://www.oasis.security/blog/openclaw-vulnerability, 2026. Accessed on 2026-03-10
2026
-
[12]
Personal AI agents like openclaw are a security night- mare
Cisco, “Personal AI agents like openclaw are a security night- mare.” https://blogs.cisco.com/ai/personal-ai-agents-like-openclaw-are-a -security-nightmare, 2026. Accessed on 2026-03-10
2026
-
[13]
Clawworm: Self-propagating attacks across LLM agent ecosystems,
Y . Zhang, Z. Wei, X. Luan, C. Wu, Z. Zhang, J. Wu, H. Wu, H. Chen, J. Sun, and M. Sun, “Clawworm: Self-propagating attacks across LLM agent ecosystems,”arXiv preprint arXiv:2603.15727, pp. 1–18, 2026
-
[14]
S. Liu, C. Li, C. Wang, J. Hou, Z. Chen, L. Zhang, Z. Liu, Q. Ye, Y . Hei, X. Zhang,et al., “ClawKeeper: Comprehensive safety protection for openclaw agents through skills, plugins, and watchers,”arXiv preprint arXiv:2603.24414, pp. 1–22, 2026
-
[15]
AI agents under threat: A survey of key security challenges and future pathways,
Z. Deng, Y . Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y . Xiang, “AI agents under threat: A survey of key security challenges and future pathways,”ACM Computing Surveys, vol. 57, no. 7, pp. 1–36, 2025
2025
-
[16]
The emerged security and privacy of LLM agent: A survey with case studies,
F. He, T. Zhu, D. Ye, B. Liu, W. Zhou, and P. S. Yu, “The emerged security and privacy of LLM agent: A survey with case studies,”ACM Computing Surveys, vol. 58, no. 6, pp. 1–36, 2025
2025
-
[17]
A survey on trustworthy LLM agents: Threats and countermeasures,
M. Yu, F. Meng, X. Zhou, S. Wang, J. Mao, L. Pan, T. Chen, K. Wang, X. Li, Y . Zhang,et al., “A survey on trustworthy LLM agents: Threats and countermeasures,” inProceedings of ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pp. 6216–6226, 2025
2025
-
[18]
Security of Internet of agents: Attacks and countermeasures,
Y . Wang, Y . Pan, S. Guo, and Z. Su, “Security of Internet of agents: Attacks and countermeasures,”IEEE Open Journal of the Computer Society, vol. 6, pp. 1611–1624, 2025
2025
-
[19]
Taming openclaw: Security analysis and mitigation of autonomous LLM agent threats,
X. Deng, Y . Zhang, J. Wu, J. Bai, S. Yi, Z. Zou, Y . Xiao, R. Qiu, J. Ma, J. Chen,et al., “Taming openclaw: Security analysis and mitigation of autonomous LLM agent threats,”arXiv preprint arXiv:2603.11619, pp. 1–22, 2026
-
[20]
Automat- ing agent hijacking via structural template injection,
X. Deng, J. Wu, M. Chen, Y . Xiao, K. Xu, and Q. Li, “Automat- ing agent hijacking via structural template injection,”arXiv preprint arXiv:2602.16958, pp. 1–16, 2026
-
[21]
Memory poisoning attack and defense on memory based LLM-agents,
B. Devarangadi Sunil, I. Sinha, P. Maheshwari, S. Todmal, S. Mallik, and S. Mishra, “Memory poisoning attack and defense on memory based LLM-agents,” inProceedings of Advances in Neural Information Processing Systems (NeurIPS), pp. 1–19, 2025
2025
-
[22]
MM-PoisonRAG: Disrupting Multimodal RAG with Local and Global Poisoning Attacks
H. Ha, Q. Zhan, J. Kim, D. Bralios, S. Sanniboina, N. Peng, K.-W. Chang, D. Kang, and H. Ji, “MM-poisonRAG: Disrupting multimodal RAG with local and global poisoning attacks,”arXiv preprint arXiv:2502.17832, pp. 1–21, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
AI agents need memory control over more context,
F. Bousetouane, “AI agents need memory control over more context,” arXiv preprint arXiv:2601.11653, pp. 1–32, 2026
-
[24]
ReCAP: Recursive context-aware reasoning and planning for large language model agents,
Z. Zhang, T. Chen, W. Xu, A. Pentland, and J. Pei, “ReCAP: Recursive context-aware reasoning and planning for large language model agents,” inAdvances in Neural Information Processing Systems (NeurIPS), pp. 1– 29, 2025
2025
-
[25]
Prompt injection attack to tool selection in LLM agents,
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, and L. Sun, “Prompt injection attack to tool selection in LLM agents,” inProceedings of the Network and Distributed System Security Symposium (NDSS), pp. 1–18, 2026
2026
-
[26]
From allies to adversaries: Manipulating LLM tool-calling through adversarial injection,
R. Zhang, H. Wang, J. Wang, M. Li, Y . Huang, D. Wang, and Q. Wang, “From allies to adversaries: Manipulating LLM tool-calling through adversarial injection,” inProceedings of the Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2009–2028, 2025
2009
-
[27]
Best-of-N jailbreaking,
J. Hughes, S. Price, A. Lynch, R. Schaeffer, F. Barez, S. Koyejo, H. Sleight, E. Jones, E. Perez, and M. Sharma, “Best-of-N jailbreaking,” inAdvances in Neural Information Processing Systems (NeurIPS), pp. 1– 85, 2025
2025
-
[28]
Great, now write an article about that: The crescendo multi-turn LLM jailbreak attack,
M. Russinovich, A. Salem, and R. Eldan, “Great, now write an article about that: The crescendo multi-turn LLM jailbreak attack,” inProceed- ings of USENIX Security Symposium (USENIX Security), pp. 1–20, 2025
2025
-
[29]
Exfiltration over web service: T1567
MITRE ATT&CK, “Exfiltration over web service: T1567.” https://at tack.mitre.org/techniques/T1567/, 2025. Version 1.5, last modified 24 October 2025
2025
-
[30]
Safetydrift: Predicting when AI agents cross the line before they actually do,
A. Dhodapkar and F. Pishori, “Safetydrift: Predicting when AI agents cross the line before they actually do,”arXiv preprint arXiv:2603.27148, pp. 1–9, 2026
-
[31]
File and Directory Discovery
MITRE ATT&CK, “File and Directory Discovery.” https://attack.mitre.o rg/techniques/T1083/, 2025. Technique T1083, Version 1.7, last modified October 24, 2025
2025
-
[32]
LLM06: Sensitive information disclo- sure
OW ASP GenAI Security Project, “LLM06: Sensitive information disclo- sure.” https://genai.owasp.org/llmrisk2023-24/llm06-sensitive-informati on-disclosure/, 2024. Accessed on 2026-04-28
2024
-
[33]
Unveiling privacy risks in LLM agent memory,
B. Wang, W. He, S. Zeng, Z. Xiang, Y . Xing, J. Tang, and P. He, “Unveiling privacy risks in LLM agent memory,” inProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pp. 25241–25260, 2025
2025
-
[34]
Simple prompt injection attacks can leak personal data observed by LLM agents during task execution,
M. Alizadeh, Z. Samei, D. Stetsenko, and F. Gilardi, “Simple prompt injection attacks can leak personal data observed by LLM agents during task execution,”arXiv preprint arXiv:2506.01055, pp. 1–25, 2025
-
[35]
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis
Z. Li, J. Wu, X. Ling, X. Cui, and T. Luo, “Towards secure agent skills: Architecture, threat taxonomy, and security analysis,”arXiv preprint arXiv:2604.02837, pp. 1–27, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Clawhavoc: 341 malicious clawed skills found by the bot they were targeting
Koi Security, “Clawhavoc: 341 malicious clawed skills found by the bot they were targeting.” https://www.koi.ai/blog/clawhavoc-341-malic ious-clawedbot-skills-found-by-the-bot-they-were-targeting, Feb. 2026. Accessed on 2026-04-28
2026
-
[37]
Snyk finds prompt injection in 36%, 1467 malicious payloads in a toxicskills study of agent skills supply chain compromise
L. Beurer-Kellner, A. Kudrinskii, M. Milanta, K. B. Nielsen, H. Sarkar, and L. Tal, “Snyk finds prompt injection in 36%, 1467 malicious payloads in a toxicskills study of agent skills supply chain compromise.” 17 https://snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/, 2026. Accessed on 2026-02-18
2026
-
[38]
BadSkill: Backdoor Attacks on Agent Skills via Model-in-Skill Poisoning
G. Tie, J. Shi, P. Zhou, and L. Sun, “BadSkill: Backdoor attacks on agent skills via model-in-skill poisoning,”arXiv preprint arXiv:2604.09378, pp. 1–23, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Software supply chain
Singapore Government Standards Portal, “Software supply chain.” https: //info.standards.tech.gov.sg/control-catalog/cybersecurity/sc/, 2026. In- cludes SC-4 Dependency Manifest Version Pinning and SC-6 Depen- dency Installation during Deployment
2026
-
[40]
Defender’s perspective: Dependency confusion and typosquatting attacks
M. Kydyraliev, “Defender’s perspective: Dependency confusion and typosquatting attacks.” https://slsa.dev/blog/2024/08/dep-confusion-and-t yposquatting, 2024. Accessed on 2026-01-20
2024
-
[41]
Dependency confusion: How I hacked into apple, microsoft and dozens of other companies
A. Birsan, “Dependency confusion: How I hacked into apple, microsoft and dozens of other companies.” https://medium.com/@alex.birsan/depe ndency-confusion-4a5d60fec610, 2021. Accessed on 2026-01-20
2021
-
[42]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, pp. 1–23, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Don’t let the claw grip your hand: A security analysis and defense framework for openclaw,
Z. Shan, J. Xin, Y . Zhang, and M. Xu, “Don’t let the claw grip your hand: A security analysis and defense framework for openclaw,”arXiv preprint arXiv:2603.10387, pp. 1–12, 2026
-
[44]
Ingress tool transfer, technique t1105
MITRE ATT&CK, “Ingress tool transfer, technique t1105.” MITRE ATT&CK, 2025. Version 2.6, last modified October 24, 2025
2025
-
[45]
Obfuscated Files or Information, Technique T1027
MITRE ATT&CK, “Obfuscated Files or Information, Technique T1027.” https://attack.mitre.org/techniques/T1027/, 2025. Accessed on 2026-04- 28
2025
-
[46]
Malicious OpenClaw skills used to distribute atomic macos stealer
A. Oliveira, B. Tancio, D. Fiser, P. Lin, and R. Reyes, “Malicious OpenClaw skills used to distribute atomic macos stealer.” Trend Micro Research, 2026. Accessed on 2026-02-18
2026
-
[47]
How OpenClaw AI agent skills are being weaponized
B. Quintero, “How OpenClaw AI agent skills are being weaponized.” https://blog.virustotal.com/2026/02/from-automation-to-infection-how.h tml, Feb. 2026. VirusTotal Blog
2026
-
[48]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inProceedings of Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 82895–82920, 2024
2024
-
[49]
HAFixAgent: History-aware automated program repair agent,
Y . Shi, H. Li, B. Adams, and A. E. Hassan, “HAFixAgent: History-aware automated program repair agent,”arXiv preprint arXiv:2511.01047, pp. 1–27, 2025
-
[50]
LLM02: Insecure Output Handling
OW ASP Foundation, “LLM02: Insecure Output Handling.” https://gena i.owasp.org/llmrisk/llm02-insecure-output-handling/, 2025. Accessed on 2026-04-28
2025
-
[51]
CWE-78: Improper Neutralization of Special Elements used in an OS Command (’OS Command Injection’)
MITRE Corporation, “CWE-78: Improper Neutralization of Special Elements used in an OS Command (’OS Command Injection’).” https: //cwe.mitre.org/data/definitions/78.html, 2024. Accessed on 2026-04-28
2024
-
[52]
How code execution drives key risks in agentic AI systems
J. Irwin and K. Greshake, “How code execution drives key risks in agentic AI systems.” https://developer.nvidia.com/blog/how-code-execu tion-drives-key-risks-in-agentic-ai-systems/, Nov. 2025. Accessed on 2026-04-16
2025
-
[53]
Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
Z. Wang, H. Tu, L. Zhang, H. Chen, J. Wu, X. Liu, Z. Yuan, T. Pang, M. Q. Shieh, F. Liu, Z. Zheng, H. Yao, Y . Zhou, and C. Xie, “Your agent, their asset: A real-world safety analysis of openclaw,”arXiv preprint arXiv:2604.04759, pp. 1–19, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Escaping the agent: On ways to bypass openclaw’s security sandbox
D. Bors, “Escaping the agent: On ways to bypass openclaw’s security sandbox.” https://labs.snyk.io/resources/bypass-openclaw-security-sandb ox/, Feb. 2026. Accessed on 2026-04-14
2026
-
[55]
S. Banerjee, P. Sahu, A. Vahldiek-Oberwagner, J. Sanchez Vicarte, and M. Tiwari, “Cascade: Composing software-hardware attack gadgets for adversarial threat amplification in compound AI systems,”arXiv preprint arXiv:2603.12023, pp. 1–11, 2026
-
[56]
Zombie agents: Persistent control of self-evolving LLM agents via self-reinforcing injections,
X. Yang, Y . He, S. Ji, B. Hooi, and J. S. Dong, “Zombie agents: Persistent control of self-evolving LLM agents via self-reinforcing injections,” in ICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, pp. 1–14, 2026
2026
-
[57]
Progent: Securing AI Agents with Privilege Control
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, and D. Song, “Pro- gent: Programmable privilege control for LLM agents,”arXiv preprint arXiv:2504.11703, pp. 1–30, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
N. Shapira, C. Wendler, A. Yen,et al., “Agents of chaos,”arXiv preprint arXiv:2602.20021, pp. 1–84, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
LLM10:2025 Unbounded Con- sumption
OW ASP GenAI Security Project, “LLM10:2025 Unbounded Con- sumption.” https://genai.owasp.org/llmrisk/llm102025-unbounded-consu mption/, 2025. Accessed on 2026-04-18
2025
-
[60]
The role of privacy fatigue in online privacy behavior,
H. Choi, J. Park, and Y . Jung, “The role of privacy fatigue in online privacy behavior,”Computers in Human Behavior, vol. 81, pp. 42–51, 2018
2018
-
[61]
W. Zhao, Z. Li, P. Zhang, and J. Sun, “ClawGuard: A runtime security framework for tool-augmented LLM agents against indirect prompt injection,”arXiv preprint arXiv:2604.11790, pp. 1–19, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
AgentSys: Secure and dynamic LLM agents through explicit hierarchical memory management,
R. Wen, H. Li, C. Xiao, and N. Zhang, “AgentSys: Secure and dynamic LLM agents through explicit hierarchical memory management,”arXiv preprint arXiv:2602.07398, pp. 1–21, 2026
-
[63]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
Q. Wei, T. Yang, Y . Wang, X. Li, L. Li, Z. Yin, Y . Zhan, T. Holz, Z. Lin, and X. Wang, “A-MemGuard: A proactive defense framework for LLM- based agent memory,”arXiv preprint arXiv:2510.02373, pp. 1–27, 2025
-
[64]
AgentDyn: Are your agent security defenses deployable in real-world dynamic environments?,
H. Li, R. Wen, S. Shi, N. Zhang, Y . V orobeychik, and C. Xiao, “AgentDyn: Are your agent security defenses deployable in real-world dynamic environments?,” 2026
2026
-
[65]
InjecAgent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmark- ing indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics (ACL), pp. 10471–10506, 2024
2024
-
[66]
TeamTNT, Group G0139
MITRE ATT&CK, “TeamTNT, Group G0139.” MITRE ATT&CK, 2025. Accessed on 2026-05-06
2025
-
[67]
Hacking Auto-GPT and escaping its docker container
L. Euler, “Hacking Auto-GPT and escaping its docker container.” https: //positive.security/blog/auto-gpt-rce, 2023. Accessed on 2026-04-28
2023
-
[68]
STAC: When innocent tools form dangerous chains to jailbreak LLM agents,
J.-J. Li, J. He, C. Shang, D. Kulshreshtha, X. Xian, Y . Zhang, H. Su, S. Swamy, and Y . Qi, “STAC: When innocent tools form dangerous chains to jailbreak LLM agents,”arXiv preprint arXiv:2509.25624, pp. 1– 30, 2025
-
[69]
MalTool: Malicious Tool Attacks on LLM Agents
Y . Hu, Y . Jia, M. Li, D. Song, and N. Gong, “MalTool: Malicious tool attacks on LLM agents,”arXiv preprint arXiv:2602.12194, pp. 1–34, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[70]
Parasites in the toolchain: A large-scale analysis of attacks on the MCP ecosystem,
S. Zhao, Q. Hou, Z. Zhan, Y . Wang, Y . Xie, Y . Guo, L. Chen, S. Li, and Z. Xue, “Parasites in the toolchain: A large-scale analysis of attacks on the MCP ecosystem,” pp. 1–18, 2026
2026
-
[71]
Malicious AI models undermine software supply-chain security,
A. K. Sood and S. Zeadally, “Malicious AI models undermine software supply-chain security,”Communications of the ACM, vol. 68, no. 6, pp. 62–71, 2025
2025
-
[72]
Detecting malicious entra OAuth Apps with LLM-based permission risk scoring,
A. Mahara, “Detecting malicious entra OAuth Apps with LLM-based permission risk scoring,”arXiv preprint arXiv:2512.15781, pp. 1–54, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.