Beyond Query Memorization: Large Language Model Routing with Query Decomposition and Historical Matching
Pith reviewed 2026-06-29 21:50 UTC · model grok-4.3
The pith
DecoR routes LLMs by decomposing queries into capabilities and matching them against historical logs instead of surface features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
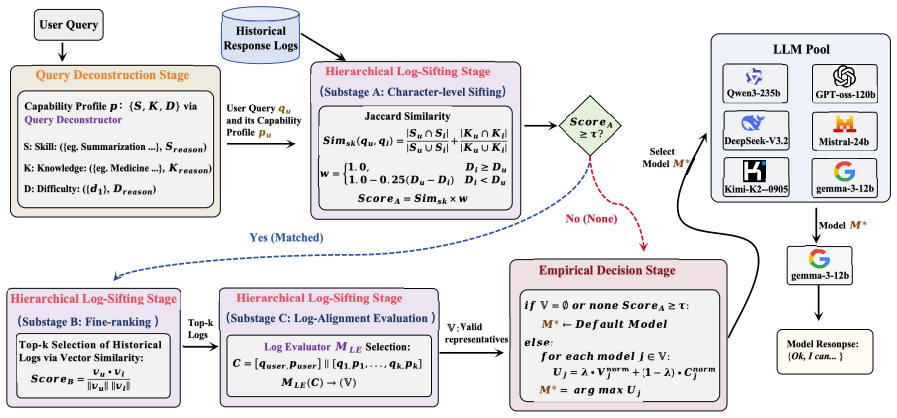
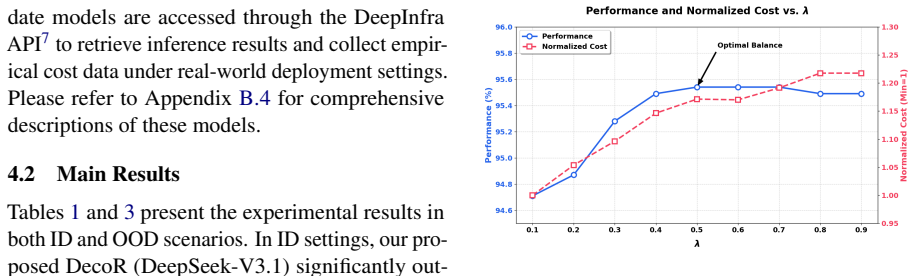
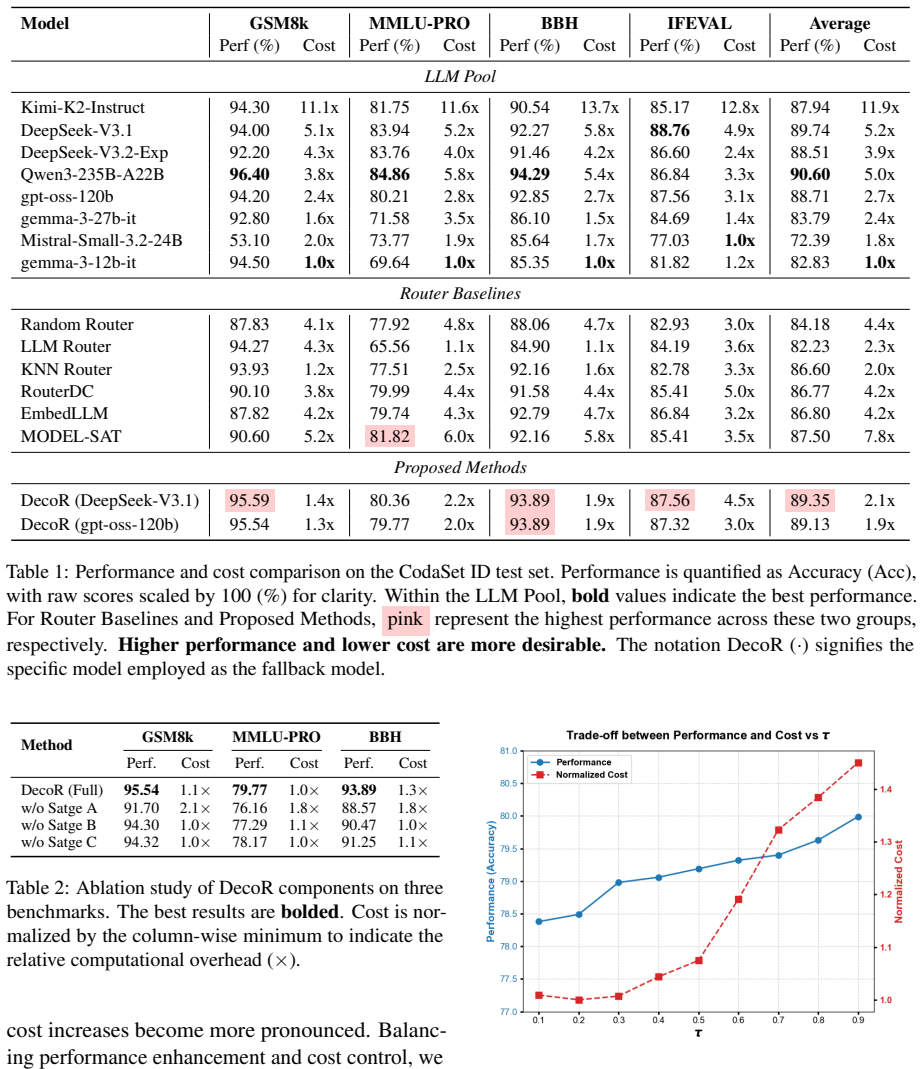
DecoR recasts the routing task as a matching process of sifting similar queries from historical logs after query capability deconstruction. The deconstruction decouples linguistic surface forms from task-intrinsic requirements and directs matching toward capability dimensions to ground decisions in essential task attributes. On the CodaSet benchmark this yields superior accuracy at substantially lower inference costs for both in-distribution and out-of-distribution queries.
What carries the argument
Query capability deconstruction that separates linguistic surface forms from task-intrinsic requirements so that historical matching operates on capability dimensions rather than wording.
If this is right
- Superior accuracy holds on both in-distribution and out-of-distribution queries.
- Inference costs drop substantially compared with direct mapping routers.
- Generalization improves because the memorization trap is avoided.
- Historical logs become the primary source for routing decisions.
Where Pith is reading between the lines
- The method may allow smaller log sizes to suffice once decomposition is stable.
- Similar decomposition-plus-matching could apply to example selection in few-shot prompting.
- Production systems might replace large model pools with a single router plus growing logs.
Load-bearing premise
Decoupling surface language from task requirements through decomposition will produce matches that generalize reliably to new queries.
What would settle it
A collection of test queries whose task requirements are missed or distorted by the decomposition step, with accuracy then measured against a surface-feature baseline.
Figures

read the original abstract
Optimizing the trade-off among predictive performance and computational cost is a central focus in the deployment of Large Language Models (LLMs). Current routing methods primarily rely on direct mapping from queries to models based on surface-level features, making them susceptible to the memorization trap and leading to poor generalizability on out-of-distribution (OOD) data. In this paper, we propose DecoR, a novel routing framework that recasts the routing task as a matching process of sifting similar queries from historical logs, effectively mitigating the memorization trap. To enhance matching accuracy, we introduce a query capability deconstruction method that decouples linguistic surface forms from task-intrinsic requirements, directing matching toward capability dimensions to ground decisions in essential task attributes. Furthermore, we develop CodaSet, a comprehensive benchmark for assessing routing generalization, where experimental results demonstrate that DecoR maintains superior accuracy while substantially lowering inference costs across both in-distribution and OOD settings. All the codes and data are available at https://github.com/lvbotenbest/DecoR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DecoR, an LLM routing framework that recasts routing as historical query matching after decomposing queries into capability dimensions (decoupling surface forms from task-intrinsic requirements). It introduces the CodaSet benchmark and claims that this yields superior accuracy and lower inference costs versus prior methods on both in-distribution and OOD queries while avoiding the memorization trap of surface-level routing.
Significance. If the central empirical claims hold, the work would provide a practical alternative to direct query-to-model mapping that improves generalization and cost-efficiency in LLM serving. The public release of code and data at the cited GitHub repository is a clear strength supporting reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: the central claim of maintained superior accuracy on OOD queries while lowering costs is asserted without any quantitative results, baseline comparisons, statistical tests, OOD construction details, or error bars; this prevents verification of the claimed advantage over memorization-based routers.
- [Abstract / §3] The query capability deconstruction step (described in the abstract and presumably §3) is load-bearing for the OOD generalization claim, yet the manuscript provides no implementation details (e.g., LLM-based extraction vs. rules), no ablations on its sensitivity to novel capabilities, and no evidence that it avoids per-domain tuning or new failure modes on OOD queries.
minor comments (1)
- [Abstract] Abstract: 'All the codes and data' should be rephrased to 'The code and data' for standard English usage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for clarification and strengthening, particularly around the abstract and the query deconstruction component. We have revised the manuscript accordingly and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of maintained superior accuracy on OOD queries while lowering costs is asserted without any quantitative results, baseline comparisons, statistical tests, OOD construction details, or error bars; this prevents verification of the claimed advantage over memorization-based routers.
Authors: We agree that the abstract should provide more concrete support for the central claims. In the revised version we have updated the abstract to include specific quantitative results (e.g., accuracy gains and cost reductions relative to the strongest baselines on both in-distribution and OOD splits of CodaSet), a brief description of the OOD construction protocol, and explicit mention of the primary baselines. Detailed tables with error bars, statistical significance tests, and full OOD construction details remain in the experimental section due to length constraints, but the abstract now supplies the key numbers needed for immediate verification. revision: yes
-
Referee: [Abstract / §3] The query capability deconstruction step (described in the abstract and presumably §3) is load-bearing for the OOD generalization claim, yet the manuscript provides no implementation details (e.g., LLM-based extraction vs. rules), no ablations on its sensitivity to novel capabilities, and no evidence that it avoids per-domain tuning or new failure modes on OOD queries.
Authors: We accept that additional implementation details and supporting experiments are warranted. Section 3 has been expanded with the exact LLM prompt template used for capability extraction, the model employed, and the output schema. We have added a new ablation subsection that (i) compares LLM-based versus rule-based decomposition, (ii) measures sensitivity when novel capability dimensions appear in OOD queries, and (iii) reports performance across the diverse domains in CodaSet without any per-domain fine-tuning or prompt adaptation. Analysis of observed failure modes on OOD queries is also included, showing that the capability-level matching reduces surface-form memorization errors. revision: yes
Circularity Check
No significant circularity; empirical framework with external evaluation
full rationale
The paper presents DecoR as an empirical routing framework relying on query capability deconstruction and historical matching, evaluated on the introduced CodaSet benchmark. No equations, derivations, or self-citation chains are described that reduce performance claims to fitted parameters or inputs by construction. The central claims rest on experimental results across in-distribution and OOD settings rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. https://arxiv.org/abs/2108.07732 Program synthesis with large language models . Preprint, arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024 a . https://arxiv.org/abs/2402.03216 Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . Preprint, arXiv:2402.03216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Kwok, and Yu Zhang
Shuhao Chen, Weisen Jiang, Baijiong Lin, James T. Kwok, and Yu Zhang. 2024 b . RouterDC : Query-based router by dual contrastive learning for assembling large language models. In Neural Information Processing Systems
2024
-
[4]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
DeepSeek-AI. 2024. https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, and 245 others. 2025. https://arxiv.org/abs/2512.02556 Deepseek-v3.2: Pushing the frontier of open large language models ....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. 2024. Hybrid llm: Cost-efficient and quality-aware query routing. In The Twelfth International Conference on Learning Representations
2024
-
[8]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024. Routerbench: A benchmark for multi-llm routing system. arXiv preprint arXiv: 2403.12031
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. arXiv preprint arXiv:2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Keming Lu, Hongyi Yuan, Runji Lin, Junyang Lin, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. https://doi.org/10.18653/v1/2024.naacl-long.109 Routing to the expert: Efficient reward-guided ensemble of large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langua...
-
[11]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. 2024. https://arxiv.org/abs/2406.18665 Routellm: Learning to route llms with preference data . Preprint, arXiv:2406.18665
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
OpenAI. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, , and Jason Wei. 2022. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025 a . https://arxiv.org/abs/2503.19...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, and 150 others. 2025 b . https://arxiv.org/abs/2507.20534 Kimi k2: Open agentic intelligence . Preprint, arXiv:2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [18]
-
[19]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, and 1 others. 2024. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. arXiv preprint arXiv:2406.01574
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/91f18a1287b398d378ef22505bf41832-Paper-Datasets_and_Benchmarks.pdf Judging llm-as-a-judge with mt-bench and chatbot ...
2023
-
[23]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. https://arxiv.org/abs/2311.07911 Instruction-following evaluation for large language models . Preprint, arXiv:2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Richard Zhuang, Tianhao Wu, Zhaojin Wen, Andrew Li, Jiantao Jiao, and Kannan Ramchandran. 2025. https://openreview.net/forum?id=Fs9EabmQrJ Embed LLM : Learning compact representations of large language models . In The Thirteenth International Conference on Learning Representations
2025
-
[25]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[26]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.