PennySynth: RAG-Driven Data Synthesis for Automated Quantum Code Generation
Pith reviewed 2026-06-29 21:35 UTC · model grok-4.3
The pith
Retrieval from 13,389 PennyLane examples raises LLM pass rates on quantum coding challenges by 25 to 28 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
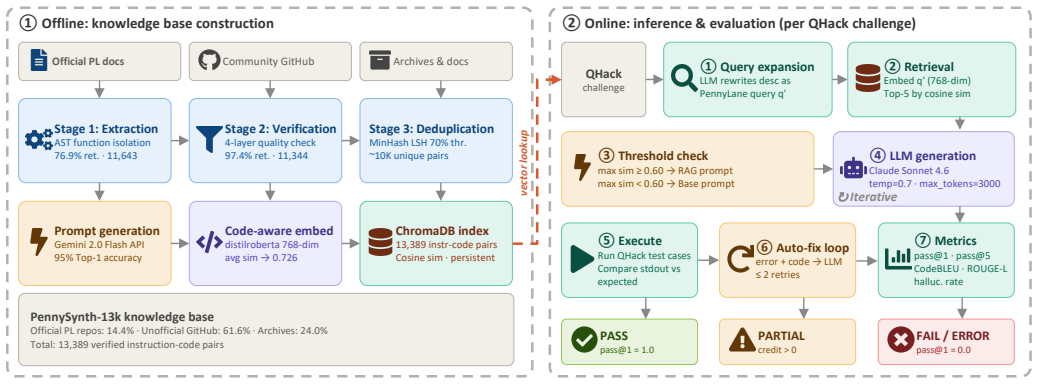
PennySynth builds a knowledge base of 13,389 verified instruction-code pairs through extraction, verification, and deduplication from PennyLane repositories and QHack archives. It then uses a code-aware embedding model to retrieve the most relevant pairs at inference time and conditions the LLM on those pairs. On 74 held-out QHack challenges the system records pass@5 scores of 64 percent, 68 percent, and 52 percent for the 2022, 2023, and 2024 editions, each more than 25 points above the no-retrieval baseline. A quantum-adapted CodeBLEU metric confirms that the retrieved examples improve both token-level structural fidelity and functional correctness, and ablations isolate the embedding choi
What carries the argument
The code-aware embedding model (st-codesearch-distilroberta-base) that retrieves natural-language-to-code matches from the curated set of 13,389 PennyLane instruction-code pairs.
If this is right
- LLMs can generate structurally valid PennyLane circuits for competition-level tasks when guided by retrieved examples.
- Code-aware embeddings outperform general-purpose embeddings for retrieving quantum code, raising average cosine similarity from 0.45 to 0.726.
- Dataset expansion improves results only after retrieval precision is already high.
- Structural similarity and functional correctness measure different qualities and both must be tracked separately.
- The same retrieval pipeline can be rebuilt for any quantum framework that supplies public code repositories.
Where Pith is reading between the lines
- The method may extend to other specialized programming domains where general models hallucinate domain-specific syntax.
- Real-world user queries outside competition settings could reveal whether the current knowledge base covers typical practitioner needs.
- Combining PennySynth-style retrieval with newer base models could produce additive gains beyond the reported improvements.
Load-bearing premise
The 13,389 extracted pairs reflect the distribution of real user queries and contain no overlap with the 74 test challenges.
What would settle it
Running PennySynth on a fresh collection of quantum coding problems drawn from sources never used to build the knowledge base and measuring whether the 25-point gains persist.
Figures


read the original abstract
The growing complexity of quantum programming frameworks has exposed a critical limitation in existing large language model (LLM)-based code assistants: general-purpose models hallucinate PennyLane-specific gate names, misplace device configurations, and produce structurally invalid circuits when faced with specialized quantum coding challenges. We present PennySynth, a retrieval-augmented generation framework that addresses this gap by conditioning LLM inference on a curated knowledge base of 13,389 PennyLane instruction-code pairs, built via a three-stage extraction, verification, and deduplication pipeline over official PennyLane repositories, community GitHub sources, and QHack competition archives. PennySynth introduces a code-aware embedding strategy using st-codesearch-distilroberta-base, trained for natural-language-to-code retrieval, increasing average retrieval cosine similarity from 0.45 to 0.726 compared to a general-purpose baseline. Evaluated across 74 challenges spanning three years of the QHack competition (2022, 2023, 2024), PennySynth achieves 64%, 68%, and 52% pass@5 on QHack 2022, 2023, and 2024, respectively, improving over Claude Sonnet 4.6 without retrieval by +28, +25, and +28 percentage points. We further introduce a quantum-adapted CodeBLEU metric that upweights qml.* token patterns and show that structural code similarity and functional correctness capture distinct aspects of quantum code quality. Controlled ablations reveal that code-aware embeddings are the primary driver of retrieval performance, while dataset expansion and source composition provide additional gains when retrieval quality is sufficiently precise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PennySynth, a retrieval-augmented generation framework for PennyLane quantum code that constructs a KB of 13,389 instruction-code pairs from PennyLane repositories, community GitHub, and QHack archives via a three-stage extraction/verification/deduplication pipeline. It employs a code-aware embedding model (st-codesearch-distilroberta-base) that raises average retrieval cosine similarity from 0.45 to 0.726. On 74 QHack challenges spanning 2022-2024, PennySynth reports pass@5 scores of 64%, 68%, and 52%, respectively, for gains of +28, +25, and +28 pp over a no-retrieval Claude Sonnet 4.6 baseline. The work also defines a quantum-adapted CodeBLEU metric and presents ablations attributing gains primarily to the code-aware embeddings.
Significance. If the reported gains can be shown to arise from generalization rather than leakage, the result would establish that domain-specific RAG with code-aware retrieval substantially reduces hallucinations on specialized quantum programming tasks, providing a concrete, reproducible path for improving LLM assistants in quantum software. The controlled ablations and quantum-adapted CodeBLEU supply additional methodological value for evaluating structural and functional correctness in this domain.
major comments (2)
- [Abstract] Abstract: the KB is explicitly built from 'QHack competition archives' while the test set consists of the 74 QHack 2022/2023/2024 challenges. No description is supplied of temporal hold-out, solution exclusion, or deduplication steps that isolate the test challenges from the KB. Without such isolation the +25–28 pp gains over the no-retrieval baseline cannot be attributed to RAG generalization rather than retrieval of memorized test solutions; this directly undermines the central performance claim.
- [Abstract] Abstract (evaluation description): the concrete pass@5 numbers and ablation outcomes are presented without any mention of test-set contamination checks, the precise definition and implementation of pass@5 (e.g., number of samples, temperature, success criterion), or statistical significance testing. These omissions leave the primary empirical result only partially verifiable.
minor comments (2)
- [Abstract] Abstract: the split of the 74 challenges across the three years is not stated, which would aid interpretation of the per-year scores.
- The abstract refers to 'controlled ablations' but does not indicate where in the manuscript the ablation tables or figures appear.
Simulated Author's Rebuttal
We thank the referee for highlighting critical issues around potential test-set contamination and evaluation transparency. These points are essential for validating the generalization claims. We address each comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the KB is explicitly built from 'QHack competition archives' while the test set consists of the 74 QHack 2022/2023/2024 challenges. No description is supplied of temporal hold-out, solution exclusion, or deduplication steps that isolate the test challenges from the KB. Without such isolation the +25–28 pp gains over the no-retrieval baseline cannot be attributed to RAG generalization rather than retrieval of memorized test solutions; this directly undermines the central performance claim.
Authors: We agree that the absence of explicit isolation details leaves the generalization claim open to the interpretation of leakage. The three-stage pipeline incorporates deduplication across sources, but the manuscript does not describe targeted exclusion of the 2022–2024 QHack test challenges. In the revision we will add a new subsection under the KB construction section that details: (i) temporal hold-out (all solutions associated with the 74 evaluation challenges were removed prior to KB finalization), (ii) exact deduplication criteria applied to QHack archives, and (iii) post-construction verification that no test challenge appears in the retrieved contexts during evaluation. This documentation will allow readers to confirm that reported gains reflect RAG-driven generalization. revision: yes
-
Referee: [Abstract] Abstract (evaluation description): the concrete pass@5 numbers and ablation outcomes are presented without any mention of test-set contamination checks, the precise definition and implementation of pass@5 (e.g., number of samples, temperature, success criterion), or statistical significance testing. These omissions leave the primary empirical result only partially verifiable.
Authors: We accept that the current abstract and evaluation section omit key reproducibility details. The revised manuscript will expand the evaluation subsection to include: (1) explicit statement of the contamination checks now documented in the KB section, (2) precise pass@5 protocol (5 samples per challenge at temperature 0.7, success defined by passing all provided unit tests), and (3) statistical significance results (bootstrap 95% confidence intervals and paired tests against the no-retrieval baseline). These additions will render the primary results fully verifiable while preserving the reported numbers. revision: yes
Circularity Check
No circularity; claims rest on external QHack benchmarks and separate embedding model
full rationale
The paper describes an empirical RAG pipeline whose central performance numbers (pass@5 on 74 QHack challenges) are measured against an external competition benchmark. The KB construction, three-stage pipeline, and use of st-codesearch-distilroberta-base are presented as independent inputs; no equations exist, no fitted parameters are renamed as predictions, and no self-citation chain reduces the reported gains to quantities defined inside the paper. Deduplication is asserted but the evaluation design does not reduce to the authors' own fitted values by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Embedding model choice (st-codesearch-distilroberta-base)
- Dataset construction thresholds (extraction, verification, deduplication)
axioms (1)
- domain assumption Providing retrieved domain-specific code examples improves LLM generation quality for PennyLane tasks
Reference graph
Works this paper leans on
-
[1]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholm, J. Izaac, M. Schuld, C. Gogolin, and N. Killoran, “PennyLane: Automatic differentiation of hybrid quantum-classical computations,”arXiv preprint arXiv:1811.04968, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Crosset al., “Quantum computing with qiskit,”arXiv preprint arXiv:2405.08810, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
A survey on quantum machine learning: Current trends, challenges, opportunities, and the road ahead,
K. Zaman, A. Marchisio, M. A. Hanif, and M. Shafique, “A survey on quantum machine learning: Current trends, challenges, opportunities, and the road ahead,”arXiv preprint arXiv:2310.10315, 2023
-
[4]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
StarCoder 2 and The Stack v2: The Next Generation
A. Lozhkov, R. Li, L. B. Allalet al., “StarCoder 2 and the stack v2: The next generation,”arXiv preprint arXiv:2402.19173, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Qiskit code assistant: Training LLMs for generating quantum computing code,
N. Dupuis, L. Buratti, S. Vishwakarmaet al., “Qiskit code assistant: Training LLMs for generating quantum computing code,” IBM Quantum Computing Blog, 2024
2024
-
[7]
Qiskit HumanEval: An evaluation benchmark for quantum code generative models,
S. Vishwakarma, F. Harkins, S. Golechaet al., “Qiskit HumanEval: An evaluation benchmark for quantum code generative models,”arXiv preprint arXiv:2406.14712, 2024
-
[8]
Quanbench: Benchmarking quan- tum code generation with large language models,
X. Guo, M. Wang, and J. Zhao, “Quanbench: Benchmarking quan- tum code generation with large language models,”arXiv preprint arXiv:2510.16779, 2025
-
[9]
A PennyLane-Centric Dataset to Enhance LLM-based Quantum Code Generation using RAG
A. Basit, N. Innan, M. H. Asif, M. Shao, M. Kashif, A. Marchisio, and M. Shafique, “A pennylane-centric dataset to enhance llm-based quantum code generation using rag,”arXiv preprint arXiv:2503.02497, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
PennyCoder: Efficient domain-specific llms for pennylane- based quantum code generation,
A. Basit, M. Shao, M. H. Asif, N. Innan, M. Kashif, A. Marchisio, and M. Shafique, “PennyCoder: Efficient domain-specific llms for pennylane- based quantum code generation,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 2. IEEE, 2025, pp. 229–234
2025
-
[11]
QHackBench: Benchmarking large language models for quantum code generation using pennylane hackathon challenges,
A. Basit, M. Shao, M. H. Asif, N. Innan, M. Kashif, A. Marchisio, and M. Shafique, “QHackBench: Benchmarking large language models for quantum code generation using pennylane hackathon challenges,” in 2025 IEEE International Conference on Quantum Artificial Intelligence (QAI). IEEE, 2025, pp. 316–322
2025
-
[12]
Accelerate quantum software development on Amazon Braket with Claude-3,
Y . Kharkov, Z. Mohammad, M. Beach, and E. Kessler, “Accelerate quantum software development on Amazon Braket with Claude-3,” AWS Quantum Technologies Blog, 2024
2024
-
[13]
Retrieval- augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 9459–9474
2020
-
[14]
Query2doc: Query expansion with large language models,
L. Wang, N. Yang, and F. Wei, “Query2doc: Query expansion with large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 9414–9423
2023
-
[15]
R. Nogueira and K. Cho, “Passage re-ranking with BERT,”arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[16]
Retrieval augmented code generation and summarization,
M. R. Parvez, W. U. Ahmad, S. Chakraborty, B. Ray, and K.-W. Chang, “Retrieval augmented code generation and summarization,”arXiv preprint arXiv:2108.11601, 2021
-
[17]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson, “From local to global: A graph RAG approach to query-focused summarization,”arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
BLEU: A method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” inProceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), 2002, pp. 311–318
2002
-
[19]
ROUGE: A package for automatic evaluation of summaries,
C.-Y . Lin, “ROUGE: A package for automatic evaluation of summaries,” inText Summarization Branches Out, 2004, pp. 74–81
2004
-
[20]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma, “CodeBLEU: A method for automatic evaluation of code synthesis,”arXiv preprint arXiv:2009.10297, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[21]
Leskovec, A
J. Leskovec, A. Rajaraman, and J. D. Ullman,Mining of massive data sets. Cambridge university press, 2020
2020
-
[22]
Claude Sonnet 4.6 model card,
Anthropic, “Claude Sonnet 4.6 model card,” Anthropic Technical Report, 2024
2024
-
[23]
GPT-5.5 system card,
OpenAI, “GPT-5.5 system card,” OpenAI Technical Report, 2024
2024
-
[24]
Gemini 2.5 Pro technical report,
Google DeepMind, “Gemini 2.5 Pro technical report,” Google DeepMind Technical Report, 2024
2024
-
[25]
Qwen Team, “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
GLM-5.1: General language model technical report,
Zhipu AI, “GLM-5.1: General language model technical report,” Zhipu AI Technical Report, 2024
2024
-
[27]
DeepSeek AI, “DeepSeek-V3 technical report,” arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.