Acting on the Unseen: Communication-Free Collaborative Filtering for Decentralized Multi-Robot Task Allocation
Pith reviewed 2026-06-29 21:50 UTC · model grok-4.3
The pith
Each robot can act well on unseen tasks by running online low-rank collaborative filtering over broadcasted teammate outcomes without communication or prior models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In Zero-Knowledge MRTA a robot team with no prior knowledge, no communication, and only a partial privately-noisy view of a public stream of teammates' outcomes can still allocate tasks effectively because a hidden low-rank structure governs robot-task suitability. Each robot runs online low-rank collaborative filtering over the broadcast (SwarmCF) to act well on tasks it never attempted and to onboard new tasks. This delivers matching per-robot sample complexity Ω(d) versus Ω(n), an anytime cumulative-reward separation under task scarcity, and a deterministic condition under which decentralized recovery from the masked broadcast is exact.
What carries the argument
SwarmCF: online low-rank collaborative filtering run independently by each robot on the broadcasted masked outcomes to generalize to unseen (robot, task) pairs.
If this is right
- Per-robot unseen-pair skill rises with team size.
- The method recovers about 80 percent of centralized full-communication earned skill.
- Performance holds under capacity-1 contention and in robotics-grounded sensing instances.
- Anytime separation under task scarcity is stronger than other low-rank methods.
Where Pith is reading between the lines
- Broadcasting outcomes could enable similar generalization in other decentralized multi-agent systems whose interactions admit low-rank structure.
- The scaling law implies that adding agents improves individual performance on novel tasks even when agents never interact directly.
- The anytime property could support extensions to settings with streaming tasks or changing team membership.
- The exact-recovery condition may apply to other distributed matrix-completion problems where each agent sees only a masked subset.
Load-bearing premise
A hidden low-rank structure governs which robot suits which task.
What would settle it
If the suitability matrix is randomized to destroy low-rank structure, performance on unseen pairs should fall to the prior-mean error floor with no categorical advantage remaining.
Figures






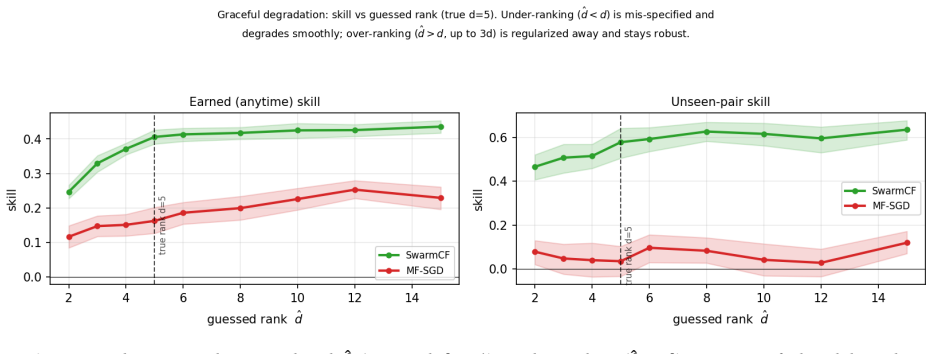





read the original abstract
Multi-robot task allocation usually assumes some combination of communication, known task models, or a coordinator. We study the opposite extreme, a regime common in practice but overlooked in theory, which we name Zero-Knowledge MRTA (ZK-MRTA): a robot team with no prior knowledge (no task models, not even the latent rank), no communication (no messages, no parameter sharing, no coordinator), and only a partial and privately-noisy view of a public stream of teammates' outcomes. A hidden low-rank structure governs which robot suits which task, and there are far more tasks than rounds, so most (robot, task) pairs are never attempted. Yet each robot can act well on tasks it never attempted, and onboard new tasks, by running online low-rank collaborative filtering over the broadcast (SwarmCF). The advantage over any structure-free learner is categorical, not a constant factor: a structure-free learner is provably at the prior-mean error floor on unseen pairs. We prove a matching per-robot sample complexity ({\Theta}(d) versus {\Theta}(n), in the rank d and the task count n), an anytime (cumulative-reward) separation under task scarcity, and a deterministic condition under which decentralized recovery from the masked broadcast is exact (validated empirically). Experiments quantify the value of the broadcast, a positive scaling law (per-robot unseen-pair skill rises with team size), and the strongest masking-robustness and anytime profile among low-rank methods, recovering most (about 80% on earned skill) of a centralized full-communication ceiling, and holding under capacity-1 contention and in a robotics-grounded sensing instance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Zero-Knowledge Multi-Robot Task Allocation (ZK-MRTA), a regime with no prior task models, no communication or parameter sharing, and only partial privately-noisy observations of a public stream of teammate outcomes. It proposes SwarmCF, an online low-rank collaborative filtering algorithm that exploits an assumed hidden low-rank structure in the robot-task suitability matrix to enable robots to act on unseen tasks. The central claims are a matching per-robot sample complexity of Θ(d) versus Θ(n) for structure-free learners, an anytime cumulative-reward separation under task scarcity, and a deterministic condition for exact decentralized recovery from the masked broadcast, with empirical validation showing positive scaling with team size and recovery of ~80% of a centralized ceiling.
Significance. If the low-rank assumption holds and the stated bounds and recovery condition are correctly derived, the work supplies a communication-free mechanism for decentralized MRTA that achieves a categorical (not merely constant-factor) advantage over structure-free methods on unseen pairs, together with matching sample-complexity guarantees and an anytime profile. These elements, if substantiated, would be a substantive contribution to scalable multi-robot systems operating under severe communication and knowledge constraints.
major comments (1)
- Abstract: the claim of 'matching per-robot sample complexity (Θ(d) versus Θ(n))' and the 'deterministic condition under which decentralized recovery ... is exact' are load-bearing for the categorical separation result; the manuscript must state the precise theorem statements, including all assumptions on the low-rank matrix and the masking process, in a dedicated theorem environment so that the matching and exactness can be verified directly.
minor comments (2)
- Abstract, paragraph 2: the phrase 'a hidden low-rank structure governs which robot suits which task' should be accompanied by the explicit matrix factorization model (e.g., suitability ≈ U V^T with rank d) at first use.
- The empirical claim of 'strongest masking-robustness ... among low-rank methods' requires an explicit list of the compared baselines and the precise metric (e.g., earned skill under 80% masking) in the abstract or a table caption.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on improving the verifiability of our central claims. We address it point by point below.
read point-by-point responses
-
Referee: [—] Abstract: the claim of 'matching per-robot sample complexity (Θ(d) versus Θ(n))' and the 'deterministic condition under which decentralized recovery ... is exact' are load-bearing for the categorical separation result; the manuscript must state the precise theorem statements, including all assumptions on the low-rank matrix and the masking process, in a dedicated theorem environment so that the matching and exactness can be verified directly.
Authors: We agree that the load-bearing claims require explicit formal statements for direct verification. The current manuscript states the results in prose in the abstract and introduction but does not isolate them as numbered theorems with complete assumption lists. In the revised version we will add two dedicated theorem environments (likely in the analysis section following the algorithm description): Theorem 1 will state the per-robot sample complexity bound of Θ(d) for unseen pairs under the low-rank model, and Theorem 2 will state the deterministic exact-recovery condition from the masked broadcast. Both will enumerate all assumptions on the low-rank matrix (rank d, incoherence parameter, minimum singular-value gap) and on the masking process (broadcast observation model, private noise distribution). This change directly addresses the referee's request without altering any proofs or results. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's derivation begins from the explicit modeling assumption of an approximately low-rank robot-task suitability matrix and derives all performance guarantees (categorical separation from structure-free learners, Θ(d) per-robot sample complexity, anytime cumulative-reward bounds, and deterministic exact decentralized recovery) as mathematical consequences of that assumption together with the masked-broadcast observation model. No claimed prediction is obtained by fitting a parameter to the same data and renaming the fit, no load-bearing uniqueness theorem is imported via self-citation, and no ansatz is smuggled through prior work. The low-rank structure is presented as an external premise rather than an internally derived or self-referential quantity, rendering the central claims self-contained under the stated hypothesis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption There exists a hidden low-rank structure governing robot-task suitability
invented entities (1)
-
SwarmCF
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The impact of diversity on optimal control policies for heterogeneous robot swarms
Prorok A, Hsieh MA, Kumar V. The impact of diversity on optimal control policies for heterogeneous robot swarms. IEEE Transactions on Robotics. 2017 Jan 16;33(2):346 -58
2017
-
[2]
Learning task requirements and agent capabilities for multi -agent task allocation
Fu B, Smith W, Rizzo D, Castanier M, Ghaffari M, Barton K. Learning task requirements and agent capabilities for multi -agent task allocation. arXiv preprint arXiv:2211.03286. 2022 Nov 7
-
[3]
Personality traits and the marriage market
Dupuy A, Galichon A. Personality traits and the marriage market. Journal of Political Economy. 2014 Dec 1;122(6):1271 -319. 20
2014
-
[4]
Schilling, F., Schiano, F., & Floreano, D. (2021). Vision -based drone flocking in outdoor environments. IEEE Robotics and Automation Letters , 6(2), 2954 -2961
2021
-
[5]
& Gao, F
Zhou, X., Wen, X., Wang, Z., Gao, Y., Li, H., Wang, Q., ... & Gao, F. (2022). Swarm of micro flying robots in the wild. Science robotics , 7(66), eabm5954
2022
-
[6]
& Arkin, R
Hudson, N., Talbot, F., Cox, M., Williams, J., Hines, T., Pitt, A., ... & Arkin, R. C. (2022). Heterogeneous ground and air platforms, homogeneous sensing: Team CSIRO Data61's approach to the DARPA subterranean challenge. Field Robotics , 2, 595-636
2022
-
[7]
& Alexis, K
Tranzatto, M., Dharmadhikari, M., Bernreiter, L., Camurri, M., Khattak, S., Mascarich, F., ... & Alexis, K. (2024). Team cerberus wins the darpa subterranean challenge: Technical overview and lessons learned. Field Robotics , 4, 349-312
2024
-
[8]
Brambilla, M., Ferrante, E., Birattari, M., & Dorigo, M. (1935). Swarm robotics: a review from the swarm engineering perspective. Swarm Intell. 7 (1), 1 –41 (2013)
1935
-
[9]
(2004, July)
Şahin, E. (2004, July). Swarm robotics: From sources of inspiration to domains of application. In International workshop on swarm robotics (pp. 10-20). Berlin, Heidelberg: Springer Berlin Heidelberg
2004
-
[10]
Cortes, J., Martinez, S., Karatas, T., & Bullo, F. (2004). Coverage control for mobile sensing networks. IEEE Transactions on robotics and Automation , 20(2), 243 -255
2004
-
[11]
P., & Matarić, M
Gerkey, B. P., & Matarić, M. J. (2004). A formal analysis and taxonomy of task allocation in multi -robot systems. The International journal of robotics research , 23(9), 939 -954
2004
-
[12]
A., Stentz, A., & Dias, M
Korsah, G. A., Stentz, A., & Dias, M. B. (2013). A comprehensive taxonomy for multi -robot task allocation. The International journal of robotics research , 32(12), 1495 -1512
2013
-
[13]
Nunes, E., Manner, M., Mitiche, H., & Gini, M. (2017). A taxonomy for task allocation problems with temporal and ordering constraints. Robotics and Autonomous Systems , 90, 55-70
2017
-
[14]
B., Zlot, R., Kalra, N., & Stentz, A
Dias, M. B., Zlot, R., Kalra, N., & Stentz, A. (2006). Market -based multirobot coordination: A survey and analysis. Proceedings of the IEEE , 94(7), 1257 -1270
2006
-
[15]
L., Brunet, L., & How, J
Choi, H. L., Brunet, L., & How, J. P. (2009). Consensus -based decentralized auctions for robust task allocation. IEEE transactions on robotics , 25(4), 912 -926
2009
-
[16]
Khamis, A., Hussein, A., & Elmogy, A. (2015). Multi -robot task allocation: A review of the state -of-the- art. Cooperative robots and sensor networks 2015 , 31-51
2015
-
[17]
J., & Sofge, D
Otte, M., Kuhlman, M. J., & Sofge, D. (2020). Auctions for multi -robot task allocation in communication limited environments. Autonomous robots , 44(3), 547 -584
2020
-
[18]
Gielis, J., Shankar, A., & Prorok, A. (2022). A critical review of communications in multi -robot systems. Current robotics reports , 3(4), 213 -225
2022
-
[19]
(2019, June)
Notomista, G., Mayya, S., Hutchinson, S., & Egerstedt, M. (2019, June). An optimal task allocation strategy for heterogeneous multi-robot systems. In 2019 18th European control conference (ECC) (pp. 2071-2076). IEEE
2019
-
[20]
Ravichandar, H., Shaw, K., & Chernova, S. (2020). STRATA: unified framework for task assignments in large teams of heterogeneous agents. Autonomous Agents and Multi -Agent Systems , 34(2), 38
2020
-
[21]
KA, A., & Subramaniam, U. (2024). A systematic literature review on multi -robot task allocation. ACM Computing Surveys , 57(3), 1-28
2024
-
[22]
(2016, June)
Rosenski, J., Shamir, O., & Szlak, L. (2016, June). Multi -player bandits –a musical chairs approach. In International Conference on Machine Learning (pp. 155 -163). PMLR
2016
-
[23]
Boursier, E., & Perchet, V. (2019). SIC-MMAB: Synchronisation involves communication in multiplayer multi-armed bandits. Advances in Neural Information Processing Systems , 32
2019
-
[24]
Bistritz, I., & Leshem, A. (2018). Distributed multi-player bandits-a game of thrones approach. Advances in Neural Information Processing Systems , 31
2018
-
[25]
Yu, C., Velu, A., Vinitsky, E., Gao, J., Wang, Y., Bayen, A., & Wu, Y. (2022). The surprising effectiveness of ppo in cooperative multi -agent games. Advances in neural information processing systems , 35, 24611- 24624
2022
-
[26]
S., Farquhar, G., Foerster, J., & Whiteson, S
Rashid, T., Samvelyan, M., De Witt, C. S., Farquhar, G., Foerster, J., & Whiteson, S. (2020). Monotonic value function factorisation for deep multi -agent reinforcement learning. Journal of Machine Learning Research , 21(178), 1 -51. 21
2020
-
[27]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zambaldi, V., Jaderberg, M., ... & Graepel, T. (2017). Value-decomposition networks for cooperative multi -agent learning. arXiv preprint arXiv:1706.05296
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
I., Tamar, A., Harb, J., Pieter Abbeel, O., & Mordatch, I
Lowe, R., Wu, Y. I., Tamar, A., Harb, J., Pieter Abbeel, O., & Mordatch, I. (2017). Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems , 30
2017
-
[29]
Sukhbaatar, S., & Fergus, R. (2016). Learning multiagent communication with backpropagation. Advances in neural information processing systems , 29
2016
-
[30]
(2019, May)
Das, A., Gervet, T., Romoff, J., Batra, D., Parikh, D., Rabbat, M., & Pineau, J. (2019, May). Tarmac: Targeted multi-agent communication. In International Conference on machine learning (pp. 1538 -1546). PMLR
2019
-
[31]
A., De Freitas, N., & Whiteson, S
Foerster, J., Assael, I. A., De Freitas, N., & Whiteson, S. (2016). Learning to communicate with deep multi- agent reinforcement learning. Advances in neural information processing systems , 29
2016
-
[32]
Goarin, M., & Loianno, G. (2024). Graph neural network for decentralized multi -robot goal assignment. IEEE Robotics and Automation Letters , 9(5), 4051 -4058
2024
-
[33]
Wang, Z., & Gombolay, M. (2020). Learning scheduling policies for multi -robot coordination with graph attention networks. IEEE Robotics and Automation Letters , 5(3), 4509 -4516
2020
-
[34]
Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System
Ammad-Ud-Din, M., Ivannikova, E., Khan, S. A., Oyomno, W., Fu, Q., Tan, K. E., & Flanagan, A. (2019). Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv preprint arXiv:1901.09888
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017, April). Communication - efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics (pp. 1273- 1282). Pmlr
2017
-
[36]
S., Givan, R., Immerman, N., & Zilberstein, S
Bernstein, D. S., Givan, R., Immerman, N., & Zilberstein, S. (2002). The complexity of decentralized control of Markov decision processes. Mathematics of operations research , 27(4), 819 -840
2002
-
[37]
Candes, E., & Recht, B. (2012). Exact matrix completion via convex optimization. Communications of the ACM, 55(6), 111 -119
2012
-
[38]
H., Montanari, A., & Oh, S
Keshavan, R. H., Montanari, A., & Oh, S. (2010). Matrix completion from a few entries. IEEE transactions on information theory , 56(6), 2980 -2998
2010
-
[39]
Recht, B. (2011). A simpler approach to matrix completion. Journal of Machine Learning Research, 12(12)
2011
-
[40]
(2013, June)
Jain, P., Netrapalli, P., & Sanghavi, S. (2013, June). Low-rank matrix completion using alternating minimization. In Proceedings of the forty -fifth annual ACM symposium on Theory of computing (pp. 665- 674)
2013
-
[41]
Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37
2009
- [42]
-
[43]
Mazumder, R., Hastie, T., & Tibshirani, R. (2010). Spectral regularization algorithms for learning large incomplete matrices. The Journal of Machine Learning Research , 11, 2287-2322
2010
-
[44]
(2008, December)
Hu, Y., Koren, Y., & Volinsky, C. (2008, December). Collaborative filtering for implicit feedback datasets. In 2008 Eighth IEEE international conference on data mining (pp. 263 -272). Ieee
2008
-
[45]
Rendle, S., Freudenthaler, C., Gantner, Z., & Schmidt -Thieme, L. (2012). BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[46]
J., & Lee, T
Kang, Y., Hsieh, C. J., & Lee, T. C. M. (2022). Efficient frameworks for generalized low-rank matrix bandit problems. Advances in Neural Information Processing Systems , 35, 19971-19983
2022
-
[47]
S., Willett, R., Wright, S., & Nowak, R
Jun, K. S., Willett, R., Wright, S., & Nowak, R. (2019, May). Bilinear bandits with low -rank structure. In International Conference on Machine Learning (pp. 3163 -3172). PMLR
2019
-
[48]
(2021, March)
Lu, Y., Meisami, A., & Tewari, A. (2021, March). Low-rank generalized linear bandit problems. In International conference on artificial intelligence and statistics (pp. 460 -468). PMLR
2021
-
[49]
(2014, June)
Gentile, C., Li, S., & Zappella, G. (2014, June). Online clustering of bandits. In International conference on machine learning (pp. 757 -765). PMLR
2014
-
[50]
(2012, March)
Ling, Q., Xu, Y., Yin, W., & Wen, Z. (2012, March). Decentralized low -rank matrix completion. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2925 -2928). IEEE. 22
2012
-
[51]
Murphy, A. H. (1988). Skill scores based on the mean square error and their relationships to the correlation coefficient. Monthly weather review , 116(12), 2417 -2424
1988
-
[52]
(2002, December)
Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2002, December). Incremental singular value decomposition algorithms for highly scalable recommender systems. In Fifth international conference on computer and information science (Vol. 1, No. 012002, pp. 27 -8)
2002
-
[53]
Auer, P., Cesa -Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine learning , 47(2), 235 -256
2002
-
[54]
Kuhn, H. W. (1955). The Hungarian method for the assignment problem. Naval research logistics quarterly , 2(1‐2), 83 -97. Appendix A. Proofs of the main results We give proofs of the main results below (full for Proposition 1, Lemma 1, Theorem 1, and Theorem 2; Theorem 3 follows as a corollary of Theorem 2), each closed by a short remark on the proof tech...
1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.