A multilevel sketch-and-solve method for overdetermined least squares problems
Pith reviewed 2026-06-29 20:31 UTC · model grok-4.3
The pith
A multilevel sketch-and-solve estimator for least squares reduces correction variance faster than simple averaging but increases overall computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The multilevel estimator decomposes into coarse sketch-and-solve samples plus correction terms whose variances decrease faster than those of the basic averaged estimator, yet the framework requires slightly more computation than simple averaging of independent sketch-and-solve solutions.
What carries the argument
The multilevel estimator formed by combining coarse sketch-and-solve samples with correction terms drawn from successively larger sketches.
If this is right
- The variance of correction terms on each level decreases faster than the variance of the simple SAS estimator.
- The overall computational cost of the multilevel framework exceeds that of the simple average estimator.
- A naive multilevel combination therefore appears unattractive for least squares problems.
Where Pith is reading between the lines
- The observed variance trend may depend on the specific random sketch distribution chosen at each level.
- Control-variate or importance-sampling corrections could be inserted at the same levels to test whether the cost gap narrows.
- The cost comparison might shift for problems whose condition number grows with dimension.
Load-bearing premise
The variance of the multilevel estimator decomposes into independent contributions from the coarse samples and the correction terms, and those correction variances decrease at a predictable rate independent of problem conditioning or sketch details.
What would settle it
Running both the multilevel estimator and the simple averaged sketch-and-solve estimator on the same large overdetermined system while measuring achieved variance per unit of wall-clock time would reveal whether the claimed cost penalty holds.
Figures

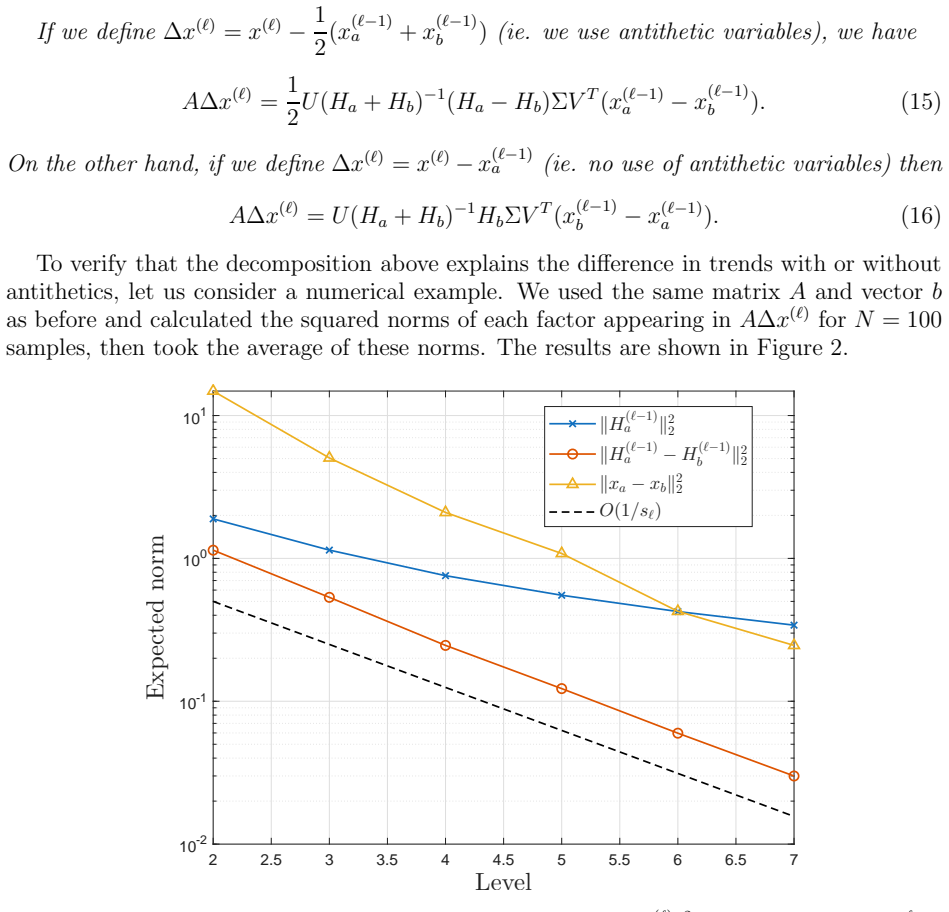
read the original abstract
Sketch-and-solve (SAS) is a very successful method to efficiently estimate the solution of heavily overdetermined large linear least squares problems. It uses random sketching to reduce the size of the problem, hence reducing the computational cost. Several authors have shown that averaging several solutions from SAS further improves the accuracy, which is measured by the residual associated to the approximate solution. Going further, we combine solutions from sketch-and-solve in a multilevel manner, such that the approximate solution is a combination of SAS samples obtained from small sketches and more accurate correction terms obtained from larger sketches. We first consider the variance of the estimator, which depends on the variance of the coarse samples and the correction terms. We show that the variance of the correction terms on each level follows a trend and decreases faster than the variance of the simple SAS estimator. However, we then show that the overall computational cost of our multilevel framework is slightly higher than that of the simple average estimator, so a naive application of multilevel methods appears unattractive for least squares problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multilevel extension of the sketch-and-solve (SAS) method for overdetermined least squares problems. Coarse solutions obtained from small random sketches are combined with correction terms computed from larger sketches. The authors analyze the variance of this multilevel estimator, claiming that the variances of the correction terms on successive levels follow a decreasing trend that is faster than the variance decay of the simple averaged SAS estimator. They then compare computational costs and conclude that the overall flop count of the multilevel framework exceeds that of simple averaging, rendering naive multilevel extensions unattractive for least squares problems.
Significance. If the cost comparison is rigorously established, the paper supplies a useful negative result that cautions against direct transfer of multilevel variance-reduction ideas to the SAS setting without further algorithmic refinement. By quantifying both the variance benefit and the cost penalty, the work contributes to the literature on randomized linear-algebra algorithms by clarifying when multilevel constructions fail to improve the accuracy-cost trade-off.
minor comments (2)
- The abstract asserts that 'the variance of the correction terms on each level follows a trend and decreases faster' and that 'the overall computational cost … is slightly higher,' yet supplies neither the explicit variance expressions nor the flop-count formulas that support these statements. Adding a brief derivation outline or reference to the relevant theorem in the introduction would improve readability.
- Notation for the multilevel estimator, the coarse samples, and the correction terms is introduced only in the abstract; a short notational table or consistent definition in §2 would help readers track the decomposition of variance into independent contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying our contribution as a useful negative result on the limitations of multilevel extensions to sketch-and-solve. The recommendation of minor revision is noted, and we will make any requested editorial adjustments in the revised version.
Circularity Check
No significant circularity identified
full rationale
The paper presents two sequential analytical results: a variance decomposition showing faster decay for multilevel correction terms than plain SAS averaging, followed by a direct flop-count comparison establishing that total cost exceeds that of simple averaging. Neither step reduces to a self-defined quantity, fitted parameter renamed as prediction, or load-bearing self-citation; the negative headline conclusion follows from the independent cost comparison rather than from any internal redefinition of inputs. The derivation chain is therefore self-contained against external benchmarks of sketching variance and arithmetic complexity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A probabilistic linear solver based on a multilevel Monte Carlo method
Juan A Acebr´ on. A probabilistic linear solver based on a multilevel Monte Carlo method. Journal of Scientific Computing , 82(3):65, 2020. 17
2020
-
[2]
Distributed sketching methods fo r privacy preserving regression
Burak Bartan and Mert Pilanci. Distributed sketching methods fo r privacy preserving regression. arXiv preprint arXiv:2002.06538 , 2020
-
[3]
Distributed sketching for random ized optimization: Exact characterization, concentration, and lower bounds
Burak Bartan and Mert Pilanci. Distributed sketching for random ized optimization: Exact characterization, concentration, and lower bounds. IEEE Transactions on Infor- mation Theory , 69(6):3850–3879, 2023
2023
-
[4]
Fast approximation of matrix coherence and statistical leverage
Petros Drineas, Malik Magdon-Ismail, Michael W Mahoney, and Dav id P Woodruff. Fast approximation of matrix coherence and statistical leverage. The Journal of Machine Learning Research, 13(1):3475–3506, 2012
2012
-
[5]
Petros Drineas and Michael W. Mahoney. RandNLA: randomized n umerical linear algebra. Commun. ACM , 59(6):80–90, May 2016
2016
-
[6]
Mahoney, and S
Petros Drineas, Michael W. Mahoney, and S. Muthukrishnan. Sa mpling algorithms for l2 regression and applications. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm , SODA ’06, page 1127–1136, USA, 2006. Society for Industrial and Applied Mathematics
2006
-
[7]
Faster least squares approximation
Petros Drineas, Michael W Mahoney, Shan Muthukrishnan, and T am´ as Sarl´ os. Faster least squares approximation. Numerische Mathematik , 117(2):219–249, 2011
2011
-
[8]
Ethan N. Epperly. Note to self: Sketch-and-solve with a Gaussia n embedding. https://www.ethanepperly.com/index.php/2024/11/19/note-to-self-sketch-and-solve-with November 2024. Accessed: 2025-08-21
2024
-
[9]
Distributed least squares in small space via sketching and bias reduction, 2024
Sachin Garg, Kevin Tan, and Micha/suppress l Derezi´ nski. Distributed least squares in small space via sketching and bias reduction, 2024
2024
-
[10]
Multilevel Monte Carlo path simulation
Michael B Giles. Multilevel Monte Carlo path simulation. Operations research , 56(3):607–617, 2008
2008
-
[11]
Multilevel Monte Carlo methods
Michael B Giles. Multilevel Monte Carlo methods. Acta Numerica, 24:259–328, 2015
2015
-
[12]
Antithetic multilevel Monte C arlo estimation for multi-dimensional sdes without l´ evy area simulation.The Annals of Applied Probability , 24(4):1585–1620, 2014
Michael B Giles and Lukasz Szpruch. Antithetic multilevel Monte C arlo estimation for multi-dimensional sdes without l´ evy area simulation.The Annals of Applied Probability , 24(4):1585–1620, 2014
2014
-
[13]
Matrix computations
Gene H Golub and Charles F Van Loan. Matrix computations . JHU press, 2013
2013
-
[14]
Subapsnap: Solving par ameter-dependent linear systems with a snapshot and subsampling
Eleanor Jones and Yuji Nakatsukasa. Subapsnap: Solving par ameter-dependent linear systems with a snapshot and subsampling. arXiv preprint arXiv:2510.04825 , 2025
-
[15]
Mahoney, and Bin Yu
Ping Ma, Michael W. Mahoney, and Bin Yu. A statistical perspect ive on algorithmic leveraging. Journal of Machine Learning Research , 16(27):861–911, 2015
2015
-
[16]
Randomized algorithms for matrices and dat a
Michael W Mahoney. Randomized algorithms for matrices and dat a. Foundations and Trends® in Machine Learning , 3(2):123–224, 2011. 18
2011
-
[17]
Riley Murray, James Demmel, Michael W Mahoney, N Benjamin Erich son, Maksim Melnichenko, Osman Asif Malik, Laura Grigori, Piotr Luszczek, Micha/suppressl Derezi´ nski, Miles E Lopes, et al. Randomized numerical linear algebra: A perspect ive on the field with an eye to software. arXiv preprint arXiv:2302.11474 , 2023
-
[18]
Fast and accurate rand omized algorithms for linear systems and eigenvalue problems
Yuji Nakatsukasa and Joel A Tropp. Fast and accurate rand omized algorithms for linear systems and eigenvalue problems. SIAM J. Matrix Anal. Appl. , 45(2):1183–1214, 2024
2024
-
[19]
Iterative hessian sketch: Fast and accurate solution approximation for constrained least-squares
Mert Pilanci and Martin J Wainwright. Iterative hessian sketch: Fast and accurate solution approximation for constrained least-squares. Journal of Machine Learning Re- search, 17(53):1–38, 2016
2016
-
[20]
Garvesh Raskutti and Michael W. Mahoney. A statistical pers pective on randomized sketching for ordinary least-squares. Journal of Machine Learning Research , 17(213):1– 31, 2016
2016
-
[21]
Improved approximation algorithms for large mat rices via random pro- jections
Tamas Sarlos. Improved approximation algorithms for large mat rices via random pro- jections. In 2006 47th Annual IEEE Symposium on Foundations of Computer S cience (FOCS’06), pages 143–152, 2006
2006
-
[22]
Improved analysis of the subsampled randomized Hadamard transform
Joel A Tropp. Improved analysis of the subsampled randomized Hadamard transform. Advances in Adaptive Data Analysis , 3(01n02):115–126, 2011
2011
-
[23]
Sketching Meets Random Projection in the Dual: A Provable Recovery Algorithm for Big and High-dimensional Data
Jialei Wang, Jason Lee, Mehrdad Mahdavi, Mladen Kolar, and Nat i Srebro. Sketching Meets Random Projection in the Dual: A Provable Recovery Algorithm for Big and High-dimensional Data. In Aarti Singh and Jerry Zhu, editors, Proceedings of the 20th International Conference on Artificial Intelligence and St atistics, volume 54 of Proceed- ings of Machine Lea...
2017
-
[24]
Shusen Wang, Alex Gittens, and Michael W. Mahoney. Sketched ridge regression: op- timization perspective, statistical perspective, and model avera ging. J. Mach. Learn. Res., 18(1):8039–8088, January 2017
2017
-
[25]
Sketching as a Tool for Numerical Linear Algebra
David P Woodruff. Sketching as a tool for numerical linear algebr a. arXiv preprint arXiv:1411.4357, 2014. 19
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.